目标检测算法之YOLO(YOLOv8)
其中卷积模块是使用了类似于ELAN的CSPlayer_2conv,分类头采用了解耦结构并使用了anchor-free的方法,损失函数中引入了VFL损失,标签分配采取了类似于yolov6的TAL方法,训练策略是采用最后10个epoch关闭Mosaic数据增强的方式。DFL的思想是基于回归任务预测的唯一性导致模型难以精确的回归到目标值上,转而通过求概率分布的方式,使预测值在目标出取得较大的概率,从而实
YOLO算法理解
- YOLOv8
-
- CSPLayer_2Conv(c2f)
- DFL
- TAL标签分配
- Conclusion
YOLOv8
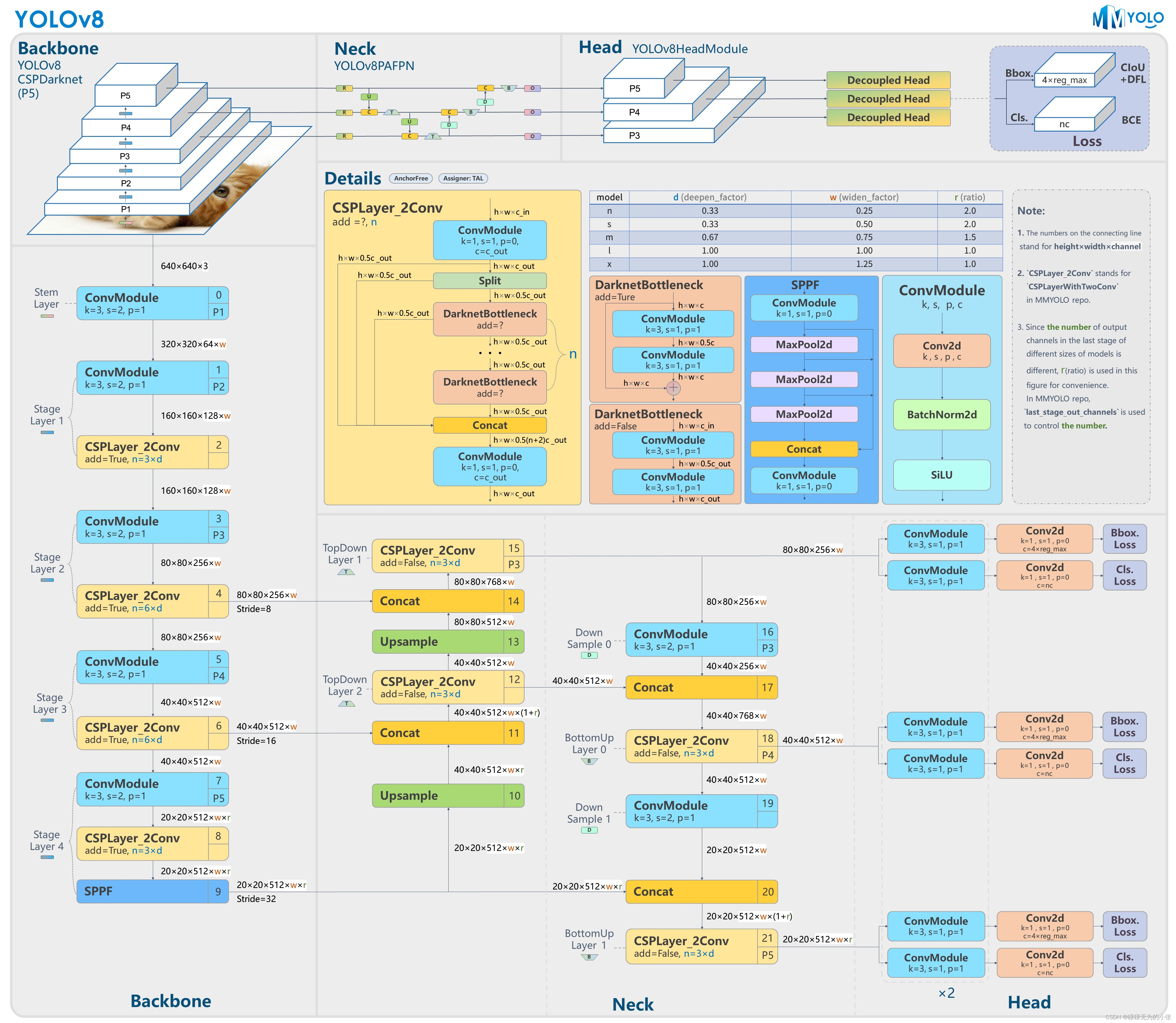
从上图可以看出,yolov8的基本结构是backbone+neck+head的形式,跟以往的yolo结构类似。Backbone和Neck部分新增了一个CSPLayer_2Conv模块,head部分采用了decoupled head(解耦头)的方式(与yolov6类似),比较特别的点是取消了objectness。最后输出Bbox和cls,其中bbox用了CIOU+DFL的损失函数,cls则是使用二值交叉损失熵。
Yolov8的创新在卷积模块、Neck、损失函数、标签分配和训练策略上都做了改进。其中卷积模块是使用了类似于ELAN的CSPlayer_2conv,分类头采用了解耦结构并使用了anchor-free的方法,损失函数中引入了dfl损失,标签分配采取了类似于yolov6的TAL方法,训练策略是采用最后10个epoch关闭Mosaic数据增强的方式。接下来具体分析一下新的卷积模块c2f、损失函数dfl。
CSPLayer_2Conv(c2f)
c2f模块的结构图如下,c2f是用于替换yolov5中的c3模块。可以发现c2f模块应用了csp的方式之外还应用了类似于ELAN网络的思想,引入了多条梯度流。在yolov7中这个方式被验证有效,所以这个模块也采用类似的方式。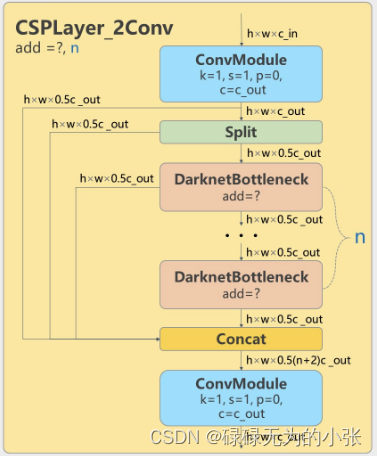
class C2f(nn.Module):
"""Faster Implementation of CSP Bottleneck with 2 convolutions."""
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):
"""Initialize CSP bottleneck layer with two convolutions with arguments ch_in, ch_out, number, shortcut, groups,
expansion.
"""
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
def forward(self, x):
"""Forward pass through C2f layer."""
y = list(self.cv1(x).chunk(2, 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
def forward_split(self, x):
"""Forward pass using split() instead of chunk()."""
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
结合结构图和论文代码,分析一下维度的变换。模块输入为 h × w × c _ i n h\times w\times c\_in h×w×c_in,经过了 1 × 1 1\times1 1×1的卷积层,将维度变换为 c _ o u t c\_out c_out。从代码中可以得知,后续是经过 s p l i t split split模块,将卷积的channel分为俩半,它们都会被直接输出至最后进行concat,其中一个还需要复制一份经过DarknetBottleneck。结构图中的流程展示得不太清晰,所以结合代码分析会比较容易理解。然后通过 n n n个DarknetBottleneck模块,每个模块的输出都会直接输出至最后,然后进行concat,这样就有 2 2 2个split的 x x x+ n n n个DarknetBottleneck的输出。所以输出 h × w × ( 2 + n ) ∗ c _ o u t h\times w\times (2+n)*c\_out h×w×(2+n)∗c_out,最后再通过 1 × 1 1\times 1 1×1卷积就可以输出 h × w × c _ o u t h\times w\times c\_out h×w×c_out。
从整体的结构图可以看出,yolov8的c2f用于backbone和neck部分。这跟其他版本的yolo优化方式比较类似。
DFL
DFL出自于(Generalized Focal Loss: Learning Qualified and Distributed Bounding Boxes for Dense Object Detection)。论文中提出了一种GFL的方法,分别优化目标检测任务中的分类预测和回归预测。yolov8采用了其中的分类改进方法 D F L DFL DFL。DFL的思想是基于回归任务预测的唯一性导致模型难以精确的回归到目标值上,转而通过求概率分布的方式,使预测值在目标出取得较大的概率,从而实现一种通过类似于“模糊”定位的方式提高模型收敛的速度,同时提高检测模型的准确率。
作者将原本的回归任务认为是一种Dirac delta分布 δ ( x − y ) \delta(x-y) δ(x−y), δ ( u ) \delta(u) δ(u)是指除了 u u u之外,函数值都为0,但 ∫ − ∞ + ∞ δ ( u ) d u = 1 \int ^{+\infty}_{-\infty}\delta(u)du=1 ∫−∞+∞δ(u)du=1。所以有 ∫ − ∞ + ∞ δ ( x − y ) d x = 1 \int ^{+\infty}_{-\infty}\delta(x-y)dx=1 ∫−∞+∞δ(x−y)dx=1由于它的一般形式为 ∫ − ∞ + ∞ δ ( x − y ) f ( x ) d x = f ( a ) \int ^{+\infty}_{-\infty}\delta(x-y)f(x)dx=f(a) ∫−∞+∞δ(x−y)f(x)dx=f(a)所以当 f ( x ) = x f(x)=x f(x)=x时有 ∫ − ∞ + ∞ δ ( x − y ) x d x = y \int ^{+\infty}_{-\infty}\delta(x-y)xdx=y ∫−∞+∞δ(x−y)xdx=y这就可以得到预测值 x x x和真实值 y y y的关系。
作者借鉴了这种形式,但设 P ( x ) P(x) P(x)是一般分布,则当 y y y的取值范围为 [ y 0 , y n ] [y_0,y_n] [y0,yn]时,有 y ^ = ∫ − ∞ + ∞ P ( x ) x d x = ∫ y 0 y n P ( x ) x d x \hat{y} = \int ^{+\infty}_{-\infty}P(x)xdx = \int ^{y_n}_{y_0}P(x)xdx y^=∫−∞+∞P(x)xdx=∫y0ynP(x)xdx然后假定 x x x的取值是离散的,则 x ∈ { y 0 , y 1 , ⋯ , y n − 2 , y n − 1 , y n } x\in\{y_0,y_1,\cdots, y_{n-2},y_{n-1},y_n\} x∈{y0,y1,⋯,yn−2,yn−1,yn}(这里的符号注意一下,把它们看成 n + 1 n+1 n+1个离散的数值,且 y 0 < y 1 < ⋯ < y n y_0<y_1<\cdots<y_n y0<y1<⋯<yn)。由于是离散的,则可以将积分转换为连加,即 y ^ = ∫ y 0 y n P ( x ) x d x = ∑ i = 0 n P ( y i ) y i \hat{y} = \int ^{y_n}_{y_0}P(x)xdx = \sum_{i=0}^{n}P(y_i)y_i y^=∫y0ynP(x)xdx=i=0∑nP(yi)yi然后给定了 x x x的取值范围之后, P ( x ) P(x) P(x)就是指其概率分布,在分类预测中,可以将其作为 s o f t m a x softmax softmax函数的输出。
在这里可能都会奇怪,因为这就是一个加权和,那么可能有 0.5 ∗ 1 + 0.5 ∗ 7 = 1.0 ∗ 4 0.5*1+0.5*7 = 1.0*4 0.5∗1+0.5∗7=1.0∗4这种情况,真实值是4,但是求出的概率分布不接近于它。下图 ( b ) (b) (b)展示了上述情况,图 ( c ) (c) (c)则是我们的理想情况
基于上述的情况,这个函数就有了优化的方向,就是让其分布更接近于图 ( c ) (c) (c)。由于我们假设了 x x x的取值是离散的,但在真实任务中很难在有限的离散值里去取 y y y,只能保证 y y y是在某个范围内。所以这里可以使 x x x的取值的分布在最接近 y y y处的值最大。假设最接近 y y y的值为 y i y_i yi和 y i + 1 y_{i+1} yi+1,即 y i < y < y i + 1 y_i<y<y_{i+1} yi<y<yi+1,然后通过交叉熵使 P ( x ) P(x) P(x)分布更接近我们的理想型。这里可以记 y i y_i yi的softmax值为 S i S_i Si,然后损失函数为 D F L ( S i , S i + 1 ) = − ( ( y i + 1 − y ) log ( S i ) + ( y − y i ) log ( S i + 1 ) ) DFL(S_i,S_{i+1}) = -((y_{i+1}-y)\log(S_{i})+(y-y_{i})\log(S_i+1)) DFL(Si,Si+1)=−((yi+1−y)log(Si)+(y−yi)log(Si+1))分析一下这个损失函数,第一项为 − ( y i + 1 − y ) log ( S i ) -(y_{i+1}-y)\log(S_{i}) −(yi+1−y)log(Si),其中 ( y i + 1 − y ) (y_{i+1}-y) (yi+1−y)是指它的权重,因为越接近 y y y它的权重越大,所以这里用的是 ( y i + 1 − y ) (y_{i+1}-y) (yi+1−y)而不是 ( y − y i ) (y-y_i) (y−yi)。第二项同理。
最理想的值就是分布在 y y y的俩边,且 S i = y i + 1 − y y i + 1 − y i S_i = \frac{y_{i+1}-y}{y_{i+1}-y_{i}} Si=yi+1−yiyi+1−y, S i + 1 = y − y i y i + 1 − y i S_{i+1} = \frac{y-y_{i}}{y_{i+1}-y_{i}} Si+1=yi+1−yiy−yi,此时 ∑ i = 0 n P ( y i ) y i = S i y i + S i + 1 y i + 1 = y \sum_{i=0}^{n}P(y_i)y_i = S_iy_i+S_{i+1}y_{i+1} = y ∑i=0nP(yi)yi=Siyi+Si+1yi+1=y。
在yolov8采用了DFL损失函数,将回归问题转化为了预测概率分布的问题。yolov8代码中先将概率分布转换为偏移,然后根据grid中心点进行偏移,具体如下 o f f s e t = ∑ i = 0 n S ( i ) y i offset = \sum_{i=0}^{n}S(i)y_{i} offset=i=0∑nS(i)yiKaTeX parse error: No such environment: align* at position 7: \begin{̲a̲l̲i̲g̲n̲*̲}̲x_{left} =& cen…
有了上述的理论基础之后,可以具体分析一下其代码。下面的代码来自yolov8
class BboxLoss(nn.Module):
"""Criterion class for computing training losses during training."""
def __init__(self, reg_max, use_dfl=False):
"""Initialize the BboxLoss module with regularization maximum and DFL settings."""
super().__init__()
self.reg_max = reg_max
self.use_dfl = use_dfl
def forward(self, pred_dist, pred_bboxes, anchor_points, target_bboxes, target_scores, target_scores_sum, fg_mask):
"""IoU loss."""
weight = target_scores.sum(-1)[fg_mask].unsqueeze(-1)
iou = bbox_iou(pred_bboxes[fg_mask], target_bboxes[fg_mask], xywh=False, CIoU=True)
loss_iou = ((1.0 - iou) * weight).sum() / target_scores_sum
# DFL loss
if self.use_dfl:
target_ltrb = bbox2dist(anchor_points, target_bboxes, self.reg_max)
loss_dfl = self._df_loss(pred_dist[fg_mask].view(-1, self.reg_max + 1), target_ltrb[fg_mask]) * weight
loss_dfl = loss_dfl.sum() / target_scores_sum
else:
loss_dfl = torch.tensor(0.0).to(pred_dist.device)
return loss_iou, loss_dfl
@staticmethod
def _df_loss(pred_dist, target):
"""
Return sum of left and right DFL losses.
Distribution Focal Loss (DFL) proposed in Generalized Focal Loss
https://ieeexplore.ieee.org/document/9792391
"""
tl = target.long() # target left
tr = tl + 1 # target right
wl = tr - target # weight left
wr = 1 - wl # weight right
return (
F.cross_entropy(pred_dist, tl.view(-1), reduction="none").view(tl.shape) * wl
+ F.cross_entropy(pred_dist, tr.view(-1), reduction="none").view(tl.shape) * wr
).mean(-1, keepdim=True)
r e g _ m a x reg\_max reg_max是指切分的区间,即 y ( y 0 , y 1 , ⋯ , y n ) y(y_0,y_1,\cdots,y_n) y(y0,y1,⋯,yn)所有可能取的离散值个数为 n + 1 n+1 n+1,yolov8中默认是赋值为15。由于它的bboxloss是由俩部分构成,一部分是IOU损失一部分是dfl损失。这里只分析dfl的损失值。
target_ltrb = bbox2dist(anchor_points, target_bboxes, self.reg_max)
def bbox2dist(anchor_points, bbox, reg_max):
"""Transform bbox(xyxy) to dist(ltrb)."""
x1y1, x2y2 = bbox.chunk(2, -1)
return torch.cat((anchor_points - x1y1, x2y2 - anchor_points), -1).clamp_(0, reg_max - 0.01) # dist (lt, rb)
这段代码是指将真实框转换为偏移,与前文中的计算偏移公式是做了一个逆运算的操作。
loss_dfl = self._df_loss(pred_dist[fg_mask].view(-1, self.reg_max + 1), target_ltrb[fg_mask]) * weight
def _df_loss(pred_dist, target):
"""
Return sum of left and right DFL losses.
Distribution Focal Loss (DFL) proposed in Generalized Focal Loss
https://ieeexplore.ieee.org/document/9792391
"""
tl = target.long() # target left
tr = tl + 1 # target right
wl = tr - target # weight left
wr = 1 - wl # weight right
return (
F.cross_entropy(pred_dist, tl.view(-1), reduction="none").view(tl.shape) * wl
+ F.cross_entropy(pred_dist, tr.view(-1), reduction="none").view(tl.shape) * wr
).mean(-1, keepdim=True)
这部分就是dfl实现的关键部分了,由于 r e g _ m a x reg\_max reg_max取值为 15 15 15,所以 y y y的值域为 ( 0 , 15 ) (0,15) (0,15),离散的值域为 { 0 , 1 , 2 , ⋯ , 14 , 15 } \{0,1,2,\cdots,14,15\} {0,1,2,⋯,14,15}。这里target的 y y y不一定是整数,所以代码中 t l tl tl为 y t a r g e t y_{target} ytarget的向下取整, t r tr tr为向上取整,从而获取前文论述的最接近 y y y的 y i y_i yi和 y i + 1 y_{i+1} yi+1。然后计算它们的权重,这里的 w l wl wl对应损失函数公式中的 y i + 1 − y y_{i+1}-y yi+1−y, w r wr wr为 y − y i y_-y_{i} y−yi。后就是套公式得出它们的dfl损失。
TAL标签分配
TAL是结合了分类和回归俩个方面的值,即 t = s α + μ β t = s^\alpha+\mu^{\beta} t=sα+μβ,然后根据 t t t进行标签分配。TAL标签分配在yolov6中已经使用过,这里主要分析一下标签分配的实现过程,具体可以看以往博客中的TOOD。在yolov8中实现代码如下
class TaskAlignedAssigner(nn.Module):
"""
A task-aligned assigner for object detection.
This class assigns ground-truth (gt) objects to anchors based on the task-aligned metric, which combines both
classification and localization information.
Attributes:
topk (int): The number of top candidates to consider.
num_classes (int): The number of object classes.
alpha (float): The alpha parameter for the classification component of the task-aligned metric.
beta (float): The beta parameter for the localization component of the task-aligned metric.
eps (float): A small value to prevent division by zero.
"""
def __init__(self, topk=13, num_classes=80, alpha=1.0, beta=6.0, eps=1e-9):
"""Initialize a TaskAlignedAssigner object with customizable hyperparameters."""
super().__init__()
self.topk = topk #筛选匹配t值排前的k个值
self.num_classes = num_classes
self.bg_idx = num_classes
self.alpha = alpha #超惨
self.beta = beta
self.eps = eps
@torch.no_grad()
def forward(self, pd_scores, pd_bboxes, anc_points, gt_labels, gt_bboxes, mask_gt):
"""
Compute the task-aligned assignment. Reference code is available at
https://github.com/Nioolek/PPYOLOE_pytorch/blob/master/ppyoloe/assigner/tal_assigner.py.
Args:
pd_scores (Tensor): shape(bs, num_total_anchors, num_classes)
pd_bboxes (Tensor): shape(bs, num_total_anchors, 4)
anc_points (Tensor): shape(num_total_anchors, 2)
gt_labels (Tensor): shape(bs, n_max_boxes, 1)
gt_bboxes (Tensor): shape(bs, n_max_boxes, 4)
mask_gt (Tensor): shape(bs, n_max_boxes, 1)
Returns:
target_labels (Tensor): shape(bs, num_total_anchors)
target_bboxes (Tensor): shape(bs, num_total_anchors, 4)
target_scores (Tensor): shape(bs, num_total_anchors, num_classes)
fg_mask (Tensor): shape(bs, num_total_anchors)
target_gt_idx (Tensor): shape(bs, num_total_anchors)
"""
#batch_size
self.bs = pd_scores.shape[0]
#真实框的个数
self.n_max_boxes = gt_bboxes.shape[1]
#如果没有真实框,那么直接返回
if self.n_max_boxes == 0:
device = gt_bboxes.device
return (
torch.full_like(pd_scores[..., 0], self.bg_idx).to(device),
torch.zeros_like(pd_bboxes).to(device),
torch.zeros_like(pd_scores).to(device),
torch.zeros_like(pd_scores[..., 0]).to(device),
torch.zeros_like(pd_scores[..., 0]).to(device),
)
#pd_scores是指预测值类别分数
#pd_bboxes值预测框的x1y1x2y2,这里是用640x640比例下的框大小
#gt_labels是指真实框的标签
#gt_bboxes是指真实框的x1y1x2y2
#anc_points是指给定的grid中心位置,即20x20,40x40,80x80的grid中心对应真实图像大小(640x640)的中心
#mask_gt是指给定的数据中是真实值的部分,这是由于一个batch中真实框的个数不一样,
#但为了处理方便,所以默认用batch中真实框最多的真实框来处理,那么其余不足的需要pad,这里即将真实值标记为1,pad部分标记为0
#get_pos_mask是用来计算真实框和预测框之间的t值,IOU值和每个样本分配给对应grid的maks矩阵
mask_pos, align_metric, overlaps = self.get_pos_mask(
pd_scores, pd_bboxes, gt_labels, gt_bboxes, anc_points, mask_gt
)
#这里比较重要的点是mask_pos维度为(bs,num_target,num_gridcenter),由于一个grid只能对应一个target,所以这里一个grid对多个target的情况进行处理
target_gt_idx, fg_mask, mask_pos = self.select_highest_overlaps(mask_pos, overlaps, self.n_max_boxes)
# Assigned target
#将真实标签分配到每个grid中去,target_labels为真实标签的label,target_bboxes为真实标签的bboxes,target_scroes为真实标签的onehot编码
target_labels, target_bboxes, target_scores = self.get_targets(gt_labels, gt_bboxes, target_gt_idx, fg_mask)
# Normalize
#计算有效的metric矩阵
align_metric *= mask_pos
#计算每个真实标签对应的最大metrics即max(t)
pos_align_metrics = align_metric.amax(dim=-1, keepdim=True) # b, max_num_obj
#计算每个真实标签对应的最大IOU
pos_overlaps = (overlaps * mask_pos).amax(dim=-1, keepdim=True) # b, max_num_obj
#对align_metric做正则化操作即t*max(iou)/max(t)
norm_align_metric = (align_metric * pos_overlaps / (pos_align_metrics + self.eps)).amax(-2).unsqueeze(-1)
target_scores = target_scores * norm_align_metric
return target_labels, target_bboxes, target_scores, fg_mask.bool(), target_gt_idx
def get_pos_mask(self, pd_scores, pd_bboxes, gt_labels, gt_bboxes, anc_points, mask_gt):
"""Get in_gts mask, (b, max_num_obj, h*w)."""
#根据真实框和给定的grid中心,判断中心是否在框中
mask_in_gts = self.select_candidates_in_gts(anc_points, gt_bboxes)
# Get anchor_align metric, (b, max_num_obj, h*w)
#计算预测框和真实框的IOU(overlaps)和t值(align_metric)
#pd_bboxes是预测的框
#pd_scores是预测的类分数
#gt_labels是真实框对应的标签
#gt_bboxes是指真实框的x1y1x2y2
#mask_in_gts * mask_gt是指中心的在框中且不是pad的部分
align_metric, overlaps = self.get_box_metrics(pd_scores, pd_bboxes, gt_labels, gt_bboxes, mask_in_gts * mask_gt)
# Get topk_metric mask, (b, max_num_obj, h*w)
#根据align_metric获取t值前k个的index,将它们的位置标记出来,记为mask_topk
mask_topk = self.select_topk_candidates(align_metric, topk_mask=mask_gt.expand(-1, -1, self.topk).bool())
# Merge all mask to a final mask, (b, max_num_obj, h*w)
#mask_topk、mask_in_gts和mask_gt取交集,这一步有点多余,topk应该是已经考虑了mask_in_gts * mask_gt
mask_pos = mask_topk * mask_in_gts * mask_gt
return mask_pos, align_metric, overlaps
def get_box_metrics(self, pd_scores, pd_bboxes, gt_labels, gt_bboxes, mask_gt):
"""Compute alignment metric given predicted and ground truth bounding boxes."""
#gird数量
na = pd_bboxes.shape[-2]
#真实框的bool值
mask_gt = mask_gt.bool() # b, max_num_obj, h*w
#初始化iou矩阵和分类分数矩阵
overlaps = torch.zeros([self.bs, self.n_max_boxes, na], dtype=pd_bboxes.dtype, device=pd_bboxes.device)
bbox_scores = torch.zeros([self.bs, self.n_max_boxes, na], dtype=pd_scores.dtype, device=pd_scores.device)
#初始化index
ind = torch.zeros([2, self.bs, self.n_max_boxes], dtype=torch.long) # 2, b, max_num_obj
ind[0] = torch.arange(end=self.bs).view(-1, 1).expand(-1, self.n_max_boxes) # b, max_num_obj
ind[1] = gt_labels.squeeze(-1) # b, max_num_obj
# Get the scores of each grid for each gt cls
#获取grid的分类分数
bbox_scores[mask_gt] = pd_scores[ind[0], :, ind[1]][mask_gt] # b, max_num_obj, h*w
# (b, max_num_obj, 1, 4), (b, 1, h*w, 4)
#计算IOU
pd_boxes = pd_bboxes.unsqueeze(1).expand(-1, self.n_max_boxes, -1, -1)[mask_gt]
gt_boxes = gt_bboxes.unsqueeze(2).expand(-1, -1, na, -1)[mask_gt]
overlaps[mask_gt] = self.iou_calculation(gt_boxes, pd_boxes)
#计算t值
align_metric = bbox_scores.pow(self.alpha) * overlaps.pow(self.beta)
return align_metric, overlaps
def iou_calculation(self, gt_bboxes, pd_bboxes):
"""IoU calculation for horizontal bounding boxes."""
return bbox_iou(gt_bboxes, pd_bboxes, xywh=False, CIoU=True).squeeze(-1).clamp_(0)
def select_topk_candidates(self, metrics, largest=True, topk_mask=None):
"""
Select the top-k candidates based on the given metrics.
Args:
metrics (Tensor): A tensor of shape (b, max_num_obj, h*w), where b is the batch size,
max_num_obj is the maximum number of objects, and h*w represents the
total number of anchor points.
largest (bool): If True, select the largest values; otherwise, select the smallest values.
topk_mask (Tensor): An optional boolean tensor of shape (b, max_num_obj, topk), where
topk is the number of top candidates to consider. If not provided,
the top-k values are automatically computed based on the given metrics.
Returns:
(Tensor): A tensor of shape (b, max_num_obj, h*w) containing the selected top-k candidates.
"""
# (b, max_num_obj, topk)
#计算top_k矩阵和tok_k的index
topk_metrics, topk_idxs = torch.topk(metrics, self.topk, dim=-1, largest=largest)
if topk_mask is None:
topk_mask = (topk_metrics.max(-1, keepdim=True)[0] > self.eps).expand_as(topk_idxs)
# (b, max_num_obj, topk)
#去除无效的t
topk_idxs.masked_fill_(~topk_mask, 0)
# (b, max_num_obj, topk, h*w) -> (b, max_num_obj, h*w)
#将top_k映射为原本对应的位置
count_tensor = torch.zeros(metrics.shape, dtype=torch.int8, device=topk_idxs.device)
ones = torch.ones_like(topk_idxs[:, :, :1], dtype=torch.int8, device=topk_idxs.device)
for k in range(self.topk):
# Expand topk_idxs for each value of k and add 1 at the specified positions
count_tensor.scatter_add_(-1, topk_idxs[:, :, k : k + 1], ones)
# count_tensor.scatter_add_(-1, topk_idxs, torch.ones_like(topk_idxs, dtype=torch.int8, device=topk_idxs.device))
# Filter invalid bboxes
count_tensor.masked_fill_(count_tensor > 1, 0)
return count_tensor.to(metrics.dtype)
def get_targets(self, gt_labels, gt_bboxes, target_gt_idx, fg_mask):
"""
Compute target labels, target bounding boxes, and target scores for the positive anchor points.
Args:
gt_labels (Tensor): Ground truth labels of shape (b, max_num_obj, 1), where b is the
batch size and max_num_obj is the maximum number of objects.
gt_bboxes (Tensor): Ground truth bounding boxes of shape (b, max_num_obj, 4).
target_gt_idx (Tensor): Indices of the assigned ground truth objects for positive
anchor points, with shape (b, h*w), where h*w is the total
number of anchor points.
fg_mask (Tensor): A boolean tensor of shape (b, h*w) indicating the positive
(foreground) anchor points.
Returns:
(Tuple[Tensor, Tensor, Tensor]): A tuple containing the following tensors:
- target_labels (Tensor): Shape (b, h*w), containing the target labels for
positive anchor points.
- target_bboxes (Tensor): Shape (b, h*w, 4), containing the target bounding boxes
for positive anchor points.
- target_scores (Tensor): Shape (b, h*w, num_classes), containing the target scores
for positive anchor points, where num_classes is the number
of object classes.
"""
# Assigned target labels, (b, 1)
#将target_gt_idx中的idx转换为gt_labels铺平后(b*num_obj)对应的idx,分配真实标签
batch_ind = torch.arange(end=self.bs, dtype=torch.int64, device=gt_labels.device)[..., None]
target_gt_idx = target_gt_idx + batch_ind * self.n_max_boxes # (b, h*w)
target_labels = gt_labels.long().flatten()[target_gt_idx] # (b, h*w)
# Assigned target boxes, (b, max_num_obj, 4) -> (b, h*w, 4)
#分配真实boxes
target_bboxes = gt_bboxes.view(-1, gt_bboxes.shape[-1])[target_gt_idx]
# Assigned target scores
target_labels.clamp_(0)
#根据target_labels做one-hot操作
# 10x faster than F.one_hot()
target_scores = torch.zeros(
(target_labels.shape[0], target_labels.shape[1], self.num_classes),
dtype=torch.int64,
device=target_labels.device,
) # (b, h*w, 80)
target_scores.scatter_(2, target_labels.unsqueeze(-1), 1)
fg_scores_mask = fg_mask[:, :, None].repeat(1, 1, self.num_classes) # (b, h*w, 80)
target_scores = torch.where(fg_scores_mask > 0, target_scores, 0)
return target_labels, target_bboxes, target_scores
@staticmethod
def select_candidates_in_gts(xy_centers, gt_bboxes, eps=1e-9):
"""
Select the positive anchor center in gt.
Args:
xy_centers (Tensor): shape(h*w, 2)
gt_bboxes (Tensor): shape(b, n_boxes, 4)
Returns:
(Tensor): shape(b, n_boxes, h*w)
"""
n_anchors = xy_centers.shape[0]
bs, n_boxes, _ = gt_bboxes.shape
lt, rb = gt_bboxes.view(-1, 1, 4).chunk(2, 2) # left-top, right-bottom
bbox_deltas = torch.cat((xy_centers[None] - lt, rb - xy_centers[None]), dim=2).view(bs, n_boxes, n_anchors, -1)
# return (bbox_deltas.min(3)[0] > eps).to(gt_bboxes.dtype)
return bbox_deltas.amin(3).gt_(eps)
@staticmethod
def select_highest_overlaps(mask_pos, overlaps, n_max_boxes):
"""
If an anchor box is assigned to multiple gts, the one with the highest IoU will be selected.
Args:
mask_pos (Tensor): shape(b, n_max_boxes, h*w)
overlaps (Tensor): shape(b, n_max_boxes, h*w)
Returns:
target_gt_idx (Tensor): shape(b, h*w)
fg_mask (Tensor): shape(b, h*w)
mask_pos (Tensor): shape(b, n_max_boxes, h*w)
"""
# (b, n_max_boxes, h*w) -> (b, h*w)
#计算每个grid匹配真实框框的数量
fg_mask = mask_pos.sum(-2)
#判断是否有一个grid对应多个真实框的情况
if fg_mask.max() > 1: # one anchor is assigned to multiple gt_bboxes
#筛选匹配多个真实框的部分
mask_multi_gts = (fg_mask.unsqueeze(1) > 1).expand(-1, n_max_boxes, -1) # (b, n_max_boxes, h*w)
#计算每个grid匹配的最大iou的idx
max_overlaps_idx = overlaps.argmax(1) # (b, h*w)
#将对应多个真实框的转换为对应一个唯一真实框
is_max_overlaps = torch.zeros(mask_pos.shape, dtype=mask_pos.dtype, device=mask_pos.device)
is_max_overlaps.scatter_(1, max_overlaps_idx.unsqueeze(1), 1)
mask_pos = torch.where(mask_multi_gts, is_max_overlaps, mask_pos).float() # (b, n_max_boxes, h*w)
#获取有真实标签对应的mask矩阵
fg_mask = mask_pos.sum(-2)
# Find each grid serve which gt(index)
target_gt_idx = mask_pos.argmax(-2) # (b, h*w)
return target_gt_idx, fg_mask, mask_pos
标签分配部分,要结合TAL的原理去理解,这样就能较好地了解其地运作过程。建议读者可以配合debug分析这一部分代码。
Conclusion
yolov8整体而言创新不大,主要是引入了新的卷积模块和采用了新的损失函数。不过其更多的是使yolo模型兼容于更多的场景,由于本文主要关注于目标检测,所以其他的场景就不具体分析了。yolov8也是做了比较多的工程任务,集成度很高,很适合新手上手。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 30
30 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)