零基础也能搞定!AI 数字人双平台高效生成 + 人物背景无缝融合指南
本文专为无编程基础的用户打造,详细拆解两大平台 AI 数字人的免费无限次生成流程,分享人物与背景自然融合的核心技巧,同时补充实用工具的操作方法,助力快速实现数字人文案创作、配音及出镜替代等需求。

在数字化内容创作的浪潮中,AI 数字人逐渐成为文案输出、视频出镜的重要助力。很多人渴望拥有专属数字人,却受限于编程知识匮乏,不知如何入门。其实,无需复杂的技术储备,借助两个常用平台就能实现数字人的免费无限次生成,再掌握简单的人物背景合并技巧,就能让数字人适配各类使用场景。
双平台 AI 数字人生成核心流程
两个平台的操作逻辑一致,均无需编程基础,全程可视化操作,适合新手快速上手。
平台 A 的核心优势在于生成速度快,数字人形象风格多样。打开平台后,直接进入数字人生成模块,无需注册登录即可使用基础功能。首先选择数字人类型,涵盖职场、生活、虚拟形象等多种风格,根据后续使用场景挑选即可。接着设置人物的基础参数,包括性别、年龄区间、面部特征等,参数调节无需过于精细,平台会自动优化细节。完成设置后,点击生成按钮,等待 1-3 分钟即可获得初始数字人形象。若对生成结果不满意,可重复生成,无次数限制,直至得到心仪的数字人。
平台 B 则以数字人动作自然度高、语音适配性强为亮点。操作流程与平台 A 类似,进入生成界面后,可选择预设的人物模板,也能上传少量参考图片自定义形象。在参数设置中,重点调节动作库和语音类型,动作库包含站立、讲解、互动等多种场景动作,语音类型覆盖不同音色和语速,满足文案配音、视频出镜等不同需求。生成后的数字人可直接导出,同样支持无限次生成,且导出格式兼容主流剪辑工具,方便后续编辑。

需要注意的是,两个平台的生成原理均基于 AI 粒子流技术,无需担心版权问题,生成的数字人可用于非商业场景的内容创作。若需用于商业用途,建议查看平台的版权说明,避免侵权风险。
人物背景合并关键技巧
生成数字人后,如何让人物与背景自然融合,避免违和感,是提升内容质量的关键。以下三个核心技巧,无需专业剪辑经验就能掌握。
光影统一是基础。数字人与背景的光影方向、亮度必须保持一致,否则会出现 “悬浮感”。若背景为明亮的室内场景,需调节数字人的亮度和对比度,使其整体亮度与背景匹配,同时确保人物阴影方向与背景光源方向一致。可借助平台自带的光影调节工具,或使用简单的图像编辑软件,通过亮度、阴影、高光等参数的微调,实现光影协调。
透视匹配是核心。数字人的比例需与背景透视效果相符,避免出现人物与背景比例失衡的情况。例如,背景为室内场景,人物需符合近大远小的透视原理,若背景是开阔的户外场景,人物比例则需适当调整,使其融入整体环境。操作时,可先确定背景的透视焦点,再通过缩放、旋转数字人,让人物的视线方向、身体角度与背景透视焦点保持一致,增强画面的立体感。
融合精度优化是提升质感的关键。合并后需检查人物边缘是否自然,有无明显的抠图痕迹。若存在边缘生硬的问题,可使用羽化工具对人物边缘进行轻微处理,同时调节人物的透明度,使其与背景过渡更自然。对于复杂背景,可借助平台的 “融合精度模块”,自动优化人物与背景的衔接细节,减少违和感。

实用工具辅助与应用场景拓展
除了双平台的基础功能,搭配一款免费的辅助工具,能进一步提升数字人创作效率。这款工具无需安装,在线即可使用,支持数字人形象优化、背景素材库调用、格式转换等功能。使用时,将双平台生成的数字人导入工具,可对人物的面部细节、动作流畅度进行二次优化;工具内置的背景素材库涵盖职场、户外、虚拟场景等多种类型,可直接选择适配的背景进行合并,无需额外寻找素材;同时支持多种格式导出,满足不同平台的发布需求。
这款数字人制作方案的适用场景十分广泛。对于内容创作者而言,数字人可替代真人出镜,减少拍摄成本和时间成本,尤其适合知识分享、文案朗读类视频创作;对于职场人士,可用于制作产品介绍、会议讲解等视频素材,数字人的专业形象能提升内容的可信度;对于自媒体从业者,数字人可实现多账号内容批量输出,搭配不同的文案和背景,快速生成多样化内容,提升更新频率。
无论是用于个人内容创作,还是职场工作辅助,这套零基础就能掌握的 AI 数字人生成与合并方案,都能有效降低创作门槛,提升内容产出效率。无需复杂的技术学习,跟着步骤操作,就能快速拥有专属数字人,解锁更多数字化创作可能。
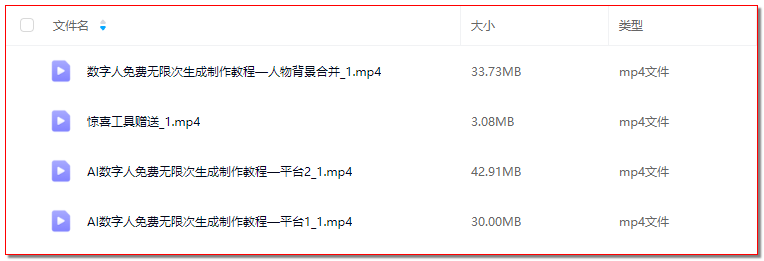
相关的软件教程和工具资源已打包整理在网盘,私信我备注文章标题即可获取完整资料,帮助你更高效地掌握数字人制作技巧。
import cv2
import numpy as np
from PIL import Image, ImageEnhance
def load_images(person_path, background_path):
"""加载数字人图像和背景图像"""
person_img = cv2.imread(person_path, cv2.IMREAD_UNCHANGED)
bg_img = cv2.imread(background_path)
return person_img, bg_img
def adjust_light_and_shadow(person_img, bg_img):
"""统一数字人与背景的光影效果"""
# 转换为HSV空间调整亮度和饱和度
person_hsv = cv2.cvtColor(person_img, cv2.COLOR_BGR2HSV)
bg_hsv = cv2.cvtColor(bg_img, cv2.COLOR_BGR2HSV)
# 计算背景的亮度均值,匹配数字人亮度
bg_brightness = np.mean(bg_hsv[:, :, 2])
person_brightness = np.mean(person_hsv[:, :, 2])
brightness_ratio = bg_brightness / (person_brightness + 1e-5)
# 调整数字人亮度
person_hsv[:, :, 2] = np.clip(person_hsv[:, :, 2] * brightness_ratio, 0, 255)
# 调整饱和度(匹配背景饱和度均值)
bg_saturation = np.mean(bg_hsv[:, :, 1])
person_saturation = np.mean(person_hsv[:, :, 1])
saturation_ratio = bg_saturation / (person_saturation + 1e-5)
person_hsv[:, :, 1] = np.clip(person_hsv[:, :, 1] * saturation_ratio, 0, 255)
return cv2.cvtColor(person_hsv, cv2.COLOR_HSV2BGR)
def adjust_perspective(person_img, bg_img, target_size=(300, 600)):
"""调整数字人透视比例,适配背景"""
# 缩放数字人至目标尺寸(根据背景场景可自定义)
person_resized = cv2.resize(person_img, target_size, interpolation=cv2.INTER_AREA)
# 模拟透视效果(基于背景比例微调)
h, w = person_resized.shape[:2]
pts1 = np.float32([[0, 0], [w, 0], [0, h], [w, h]])
# 透视偏移量(可根据实际背景调整数值)
offset = 15
pts2 = np.float32([[offset, 0], [w - offset, 0], [0, h], [w, h]])
M = cv2.getPerspectiveTransform(pts1, pts2)
person_perspective = cv2.warpPerspective(person_resized, M, (w, h))
return person_perspective
def optimize_edge(person_img, blur_radius=3):
"""优化数字人边缘,减少抠图痕迹"""
# 提取alpha通道(若有)
if person_img.shape[-1] == 4:
b, g, r, a = cv2.split(person_img)
# 边缘模糊处理
a = cv2.GaussianBlur(a, (blur_radius, blur_radius), 0)
# 调整透明度阈值,增强边缘过渡
a = np.where(a > 128, a, 0)
person_img = cv2.merge((b, g, r, a))
else:
# 无alpha通道时,使用阈值分割优化边缘
gray = cv2.cvtColor(person_img, cv2.COLOR_BGR2GRAY)
_, mask = cv2.threshold(gray, 240, 255, cv2.THRESH_BINARY_INV)
mask = cv2.GaussianBlur(mask, (blur_radius, blur_radius), 0)
person_img = cv2.bitwise_and(person_img, person_img, mask=mask)
return person_img
def merge_person_and_background(person_img, bg_img, position=(50, 100)):
"""将处理后的数字人合并到背景指定位置"""
h_person, w_person = person_img.shape[:2]
h_bg, w_bg = bg_img.shape[:2]
x, y = position
# 确保数字人不超出背景边界
if x + w_person > w_bg:
x = w_bg - w_person
if y + h_person > h_bg:
y = h_bg - h_person
# 处理alpha通道(透明融合)
if person_img.shape[-1] == 4:
# 分离通道
person_rgb = person_img[:, :, :3]
alpha = person_img[:, :, 3] / 255.0
# 背景对应区域融合
bg_region = bg_img[y:y+h_person, x:x+w_person]
merged_region = (person_rgb * alpha[:, :, None] + bg_region * (1 - alpha[:, :, None])).astype(np.uint8)
bg_img[y:y+h_person, x:x+w_person] = merged_region
else:
# 无alpha通道时直接叠加
bg_img[y:y+h_person, x:x+w_person] = person_img
return bg_img
def save_result(img, output_path):
"""保存最终融合结果"""
cv2.imwrite(output_path, img)
print(f"结果已保存至:{output_path}")
# 主函数:完整流程执行
if __name__ == "__main__":
# 替换为你的图像路径(相对路径或绝对路径均可)
PERSON_IMAGE_PATH = "person.png" # 数字人图像(建议带alpha通道)
BACKGROUND_IMAGE_PATH = "background.jpg" # 背景图像
OUTPUT_PATH = "merged_result.jpg" # 输出结果路径
# 1. 加载图像
person, background = load_images(PERSON_IMAGE_PATH, BACKGROUND_IMAGE_PATH)
# 2. 核心处理流程
person_light_adjusted = adjust_light_and_shadow(person, background)
person_perspective_adjusted = adjust_perspective(person_light_adjusted, background)
person_edge_optimized = optimize_edge(person_perspective_adjusted)
# 3. 合并并保存
final_result = merge_person_and_background(person_edge_optimized, background)
save_result(final_result, OUTPUT_PATH)
有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 23
23 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)