yolo地裂缝(wsl+ubuntu)
一、环境
环境配置
YOLOv12保姆级教程(win系统和ubuntu系统均可使用)_yolov12代码-CSDN博客
git clone 代码
v12/yolo12n-seg.yaml的下载(也可以不写)
ultralytics/ultralytics/cfg/models/12 at main · ultralytics/ultralytics
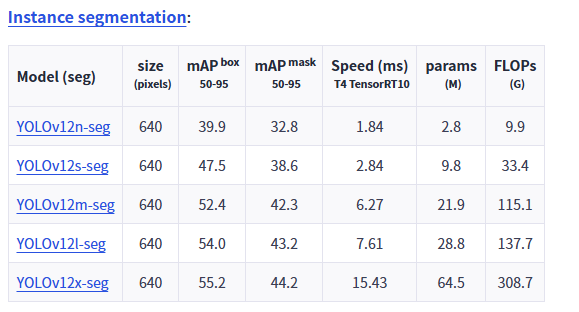
权重下载: 此处直接选择权重文件【YOLO12n-seg】下载即可
wget https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.3/flash_attn-2.7.3+cu11torch2.2cxx11abiFALSE-cp311-cp311-linux_x86_64.whl
conda create -n yolov12 python=3.11
conda activate yolov12
在pycharm中添加解释器


pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
----------安装requirements.txt文件,后面加清华的镜像源效果更好。
pip install -e .
先检查下torch的版本以及cuda是否可用
搭建YOLOv8实现裂缝缺陷识别全流程教程:从源码下载到模型测试_python 3.12.3 yolo8-CSDN博客
根目录创建一个py文件,名为cuda检查.py,放置如下代码并且执行:
import torch
import numpy as np
# 检查GPU、Cuda
print("numpy版本:"+np.__version__)
print("CUDA是否可用=>", torch.cuda.is_available())
print("pytorch版本=>"+torch.__version__)
print("是否支持CUDA=>"+str(torch.cuda.is_available()))
# 如果有 GPU 可用,打印 GPU 数量和名称
if torch.cuda.is_available():
print("GPU设备数量=>", torch.cuda.device_count())
print("当前使用GPU=>", torch.cuda.get_device_name(torch.cuda.current_device()))
else:
print("没有GPU可用,当前将运行在CPU上")如果没问题,会显示如下

如果你的pytorch显示cpu版本的,且numpy提示报错了,看博客解决
二、数据集
搭建YOLOv8实现裂缝缺陷识别全流程教程:从源码下载到模型测试_python 3.12.3 yolo8-CSDN博客
我选择第二个链接的数据集,下载splitata,换成下图的结构

想将 project_old目录移动到 /home/username/workspace/目录下,并重命名为 project_new。
mv project_old /home/username/workspace/project_new
mv /home/你的用户名/package.tar.gz /mnt/d/Downloads/
mv /home/你的用户名/data/* /mnt/c/Users/QQ342/Downloads(复制,不会带data目录)
复制文件夹下的文件到另一个文件夹
cp -r datasets/crack-seg/images/train/* datasets/crack-seg-721/total-image
/yolov12/datasets$ tar -zcvf crack-seg-721_split.tar.gz crack-seg-721_split
删除windows下以 "noncrack" 开头的 .jpg 图片
ls -r "C:\Users\QQ342\Downloads\crack_segmentation_dataset\masks\noncrack*.jpg"
Remove-Item -Path "C:\Users\QQ342\Downloads\crack_segmentation_dataset\masks\noncrack*.jpg"
压缩这个目录本身以及它包含的所有内容
tar -cvzf crack_segmentation_dataset.tar.gz /home/qsl/3dgs-code/yolov12/datasets/crack_segmentation_dataset
解压
tar -xzvf crack_segmentation_dataset.tar.gz
查看生成的 .tar.gz文件内部包含了哪些文件和路径结构
tar -tzvf crack_segmentation_dataset.tar.gz
压缩文件夹(排除一些文件)
# 在 yolov12 目录下执行
tar -zcvf splitData_3.tar.gz --exclude='splitData(3)/box_labels' --exclude='splitData(3)/splitData' --exclude='splitData(3)/crack_segmentation.yaml' 'splitData(3)'
mv splitData_3.tar.gz /mnt/c/Users/QQ342/Downloads/crack_segmentation.yaml

# 数据集路径
path: /home/qsl/3dgs-code/yolov12/splitData(3) # 数据集根目录
train: images/train # 训练集图像相对路径
val: images/val # 验证集图像相对路径
test: images/test # 测试集图像相对路径 (可选)
# 类别信息
names:
0: crack # 类别名称,索引从0开始
制作数据集
一篇文章快速认识 YOLO11 | 实例分割 | 模型训练 | 自定义数据集_yolo11实例分割-CSDN博客
修改输出标注信息的路径是和images同级的labels文件夹。最好取消同时保存图像数据按钮,并点击自动保存按钮。
三、运行
train.py
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO('/home/qsl/3dgs-code/yolov12/ultralytics/cfg/models/v12/yolov12n-seg.yaml')
# 代表使用yolov12n的神经网络结构
model.load('/home/qsl/3dgs-code/yolov12/yolov12n-seg.pt')
# 代表使用yolov12n的预训练权重
model.train(data='/home/qsl/3dgs-code/yolov12/splitData(3)/splitData/crack_segmentation.yaml', # 数据集yaml路径
imgsz=640, # 输入图像的尺寸为 640x640 像素
epochs=200, # 训练300轮
batch=16, # 每一批样本的数量
workers=8, # 同时32个线程
device="0", #只使用第一张显卡进行训练
project='/home/qsl/3dgs-code/yolov12/train',
name='yolov12n',
)结果分析参考一条视频讲清楚yolo训练结果的含义 - Coding茶水间 - 博客园 - 愿你无忧yyyyyyy - 博客园
cmd打开终端,在终端输入nvidia-smi,回车执行命令就能看到GPU利用率66%:

如果电脑不太好的话,会出现GPU容量不足的情况,尽量调整数据输入量和线程,减少电脑负担,在train文件里调小workers、batch


报错Could not load library libcudnn_cnn_train.so.8
您遇到的错误,核心问题在于环境中的CUDA和cuDNN库版本存在冲突。从您提供的版本信息来看,PyTorch期望使用CUDA 12.1,但系统却错误地加载了来自CUDA 11.8路径下的旧版cuDNN库。
echo $LD_LIBRARY_PATH
echo $CUDA_HOME

- conda activate yolov12
- unset CUDA_HOME
- export LD_LIBRARY_PATH=
更稳妥的做法(每次激活环境自动生效)(可以试试):
- mkdir -p $CONDA_PREFIX/etc/conda/activate.d
- 创建文件 vim $CONDA_PREFIX/etc/conda/activate.d/cuda_clean.sh,内容:
- unset CUDA_HOME
- export LD_LIBRARY_PATH=
验证:
- python -c "import torch, os; print(torch.version, torch.version.cuda); print('CUDA_HOME=', os.environ.get('CUDA_HOME')); print('LD_LIBRARY_PATH=', os.environ.get('LD_LIBRARY_PATH'))"
predict.py
from ultralytics import YOLO
from PIL import Image
import cv2
model = YOLO('train/yolov12n5/weights/best.pt')
results = model.predict(source='splitData(3)/images/test/1-59-_jpg.rf.88757267d8830b549d4b2eadb5febba9.jpg', save=True,save_txt=True, imgsz=640, conf=0.25)#单张图片,source也可以是文件夹
# 结果可视化
for r in results:
# 方法1: 使用Ultralytics内置的plot方法 (快速显示)
im_array = r.plot() # 绘制边界框、分割掩码、标签
im = Image.fromarray(im_array[..., ::-1]) # BGR to RGB
cv2.imshow('result', im_array) # 显示图像
# 等待按键,0表示无限等待直到按键
key = cv2.waitKey(0) # 程序会停在这里等待用户按键
# 关闭所有OpenCV窗口
cv2.destroyAllWindows()
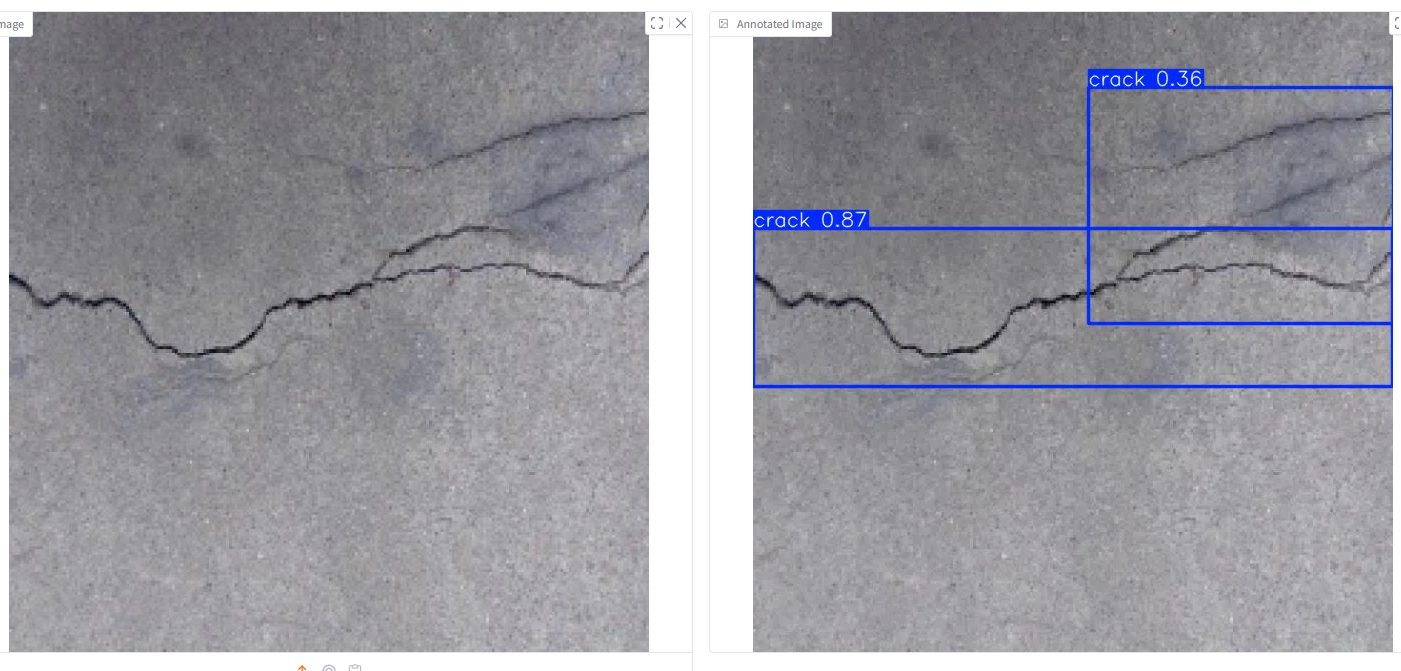
控制台提示识别的结果在runs\detect\predict目录下,发现图中出现多个裂缝时不能准确识别

【图像算法 - 14】精准识别路面墙体裂缝:基于YOLO12与OpenCV的实例分割智能检测实战(附完整代码)_crack500数据集宽度测量-CSDN博客
app.py
可选多种模型,但是这是没有经过裂缝数据集训练的权重,直接传入图片的话,输出的图片并不会标注,所以经过修改app.py做了一个可以上传pt权重文件的程序,代码如下demo.py:
demo.py(可上传pt权重文件)
# --------------------------------------------------------
# Based on yolov10
# https://github.com/THU-MIG/yolov10/app.py
# --------------------------------------------------------'
import gradio as gr
import cv2
import tempfile
from ultralytics import YOLO
def yolov12_inference(image, video, model_path, image_size, conf_threshold):
print("model_path: ", model_path)
model = YOLO(model_path)
if image:
results = model.predict(source=image, imgsz=image_size, conf=conf_threshold)
annotated_image = results[0].plot()
return annotated_image[:, :, ::-1], None
else:
video_path = tempfile.mktemp(suffix=".webm")
with open(video_path, "wb") as f:
with open(video, "rb") as g:
f.write(g.read())
cap = cv2.VideoCapture(video_path)
fps = cap.get(cv2.CAP_PROP_FPS)
frame_width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
frame_height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
output_video_path = tempfile.mktemp(suffix=".webm")
out = cv2.VideoWriter(output_video_path, cv2.VideoWriter_fourcc(*'vp80'), fps, (frame_width, frame_height))
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
results = model.predict(source=frame, imgsz=image_size, conf=conf_threshold)
annotated_frame = results[0].plot()
out.write(annotated_frame)
cap.release()
out.release()
return None, output_video_path
def yolov12_inference_for_examples(image, model_path, image_size, conf_threshold):
annotated_image, _ = yolov12_inference(image, None, model_path, image_size, conf_threshold)
return annotated_image
def app():
with gr.Blocks():
with gr.Row():
with gr.Column():
image = gr.Image(type="pil", label="Image", visible=True)
video = gr.Video(label="Video", visible=False)
input_type = gr.Radio(
choices=["Image", "Video"],
value="Image",
label="Input Type",
)
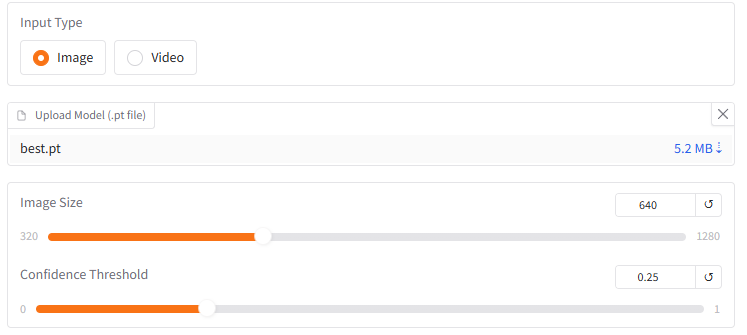
model_file = gr.File(label="Upload Model (.pt file)", file_types=[".pt"])
image_size = gr.Slider(
label="Image Size",
minimum=320,
maximum=1280,
step=32,
value=640,
)
conf_threshold = gr.Slider(
label="Confidence Threshold",
minimum=0.0,
maximum=1.0,
step=0.05,
value=0.25,
)
yolov12_infer = gr.Button(value="Detect Objects")
with gr.Column():
output_image = gr.Image(type="numpy", label="Annotated Image", visible=True)
output_video = gr.Video(label="Annotated Video", visible=False)
def update_visibility(input_type):
image = gr.update(visible=True) if input_type == "Image" else gr.update(visible=False)
video = gr.update(visible=False) if input_type == "Image" else gr.update(visible=True)
output_image = gr.update(visible=True) if input_type == "Image" else gr.update(visible=False)
output_video = gr.update(visible=False) if input_type == "Image" else gr.update(visible=True)
return image, video, output_image, output_video
input_type.change(
fn=update_visibility,
inputs=[input_type],
outputs=[image, video, output_image, output_video],
)
def run_inference(image, video, model_file, image_size, conf_threshold, input_type):
if input_type == "Image":
return yolov12_inference(image, None, model_file, image_size, conf_threshold)
else:
return yolov12_inference(None, video, model_file, image_size, conf_threshold)
yolov12_infer.click(
fn=run_inference,
inputs=[image, video, model_file, image_size, conf_threshold, input_type],
outputs=[output_image, output_video],
)
# gr.Examples(
# examples=[
# [
# "ultralytics/assets/bus.jpg",
# "yolov12s.pt",
# 640,
# 0.25,
# ],
# [
# "ultralytics/assets/zidane.jpg",
# "yolov12x.pt",
# 640,
# 0.25,
# ],
# ],
# fn=yolov12_inference_for_examples,
# inputs=[
# image,
# model_id,
# image_size,
# conf_threshold,
# ],
# outputs=[output_image],
# cache_examples='lazy',
# )
gradio_app = gr.Blocks()
with gradio_app:
gr.HTML(
"""
<h1 style='text-align: center'>
YOLOv12: Attention-Centric Real-Time Object Detectors
</h1>
""")
gr.HTML(
"""
<h3 style='text-align: center'>
<a href='https://arxiv.org/abs/2502.12524' target='_blank'>arXiv</a> | <a href='https://github.com/sunsmarterjie/yolov12' target='_blank'>github</a>
</h3>
""")
with gr.Row():
with gr.Column():
app()
if __name__ == '__main__':
gradio_app.launch()
四、autodl部署
可尝试参考
01 YOLOv12快速复现部署&训练测试_哔哩哔哩_bilibili
选择gpu
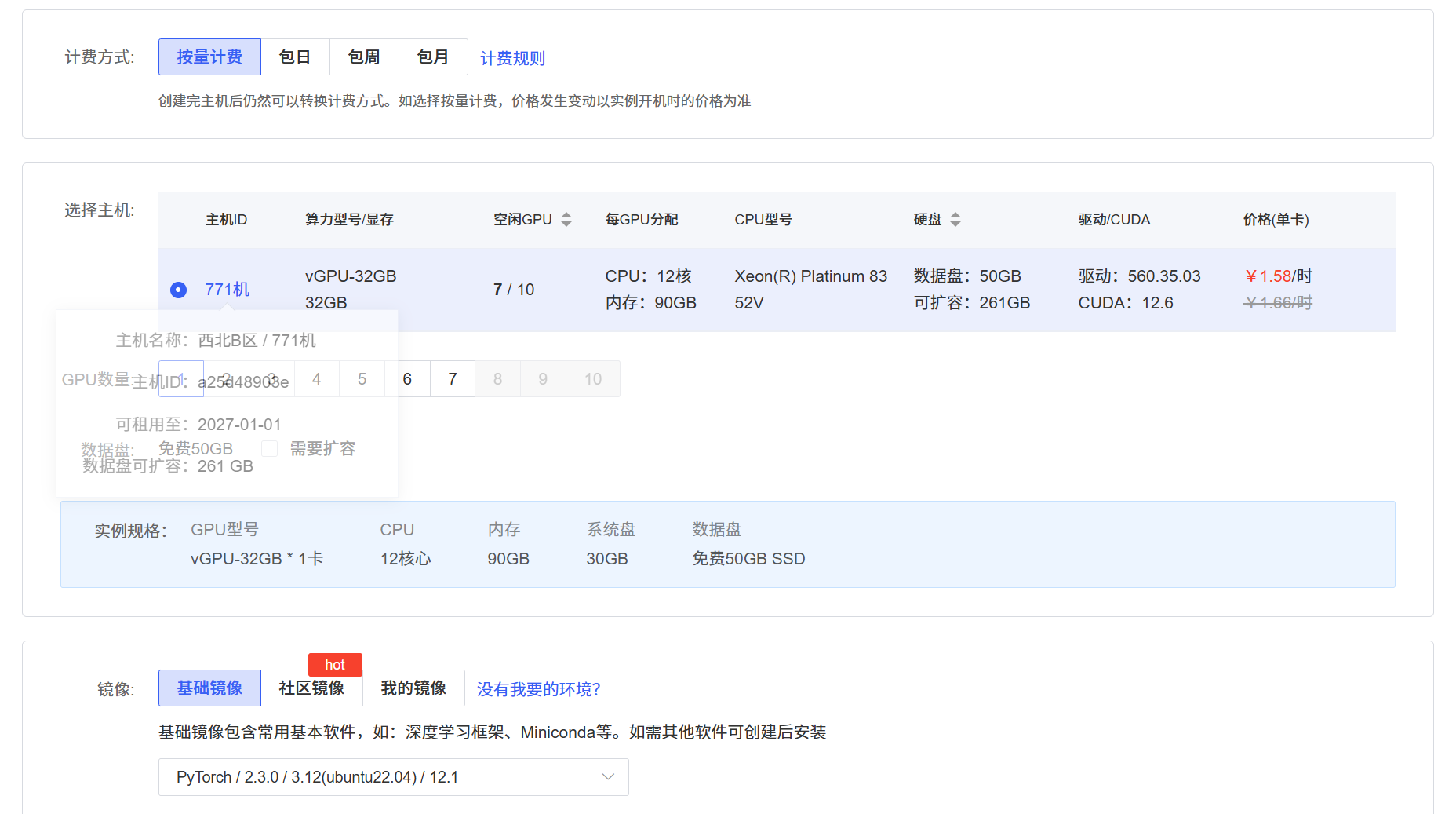
马上关机,无卡模式开机
安装xshell
XShell初始化界面
参考XShell免费版的安装配置教程以及使用教程(超级详细、保姆级)-CSDN博客
安装xftp
可以先传数据集
连接pycharm
【【手把手带你实战YOLOv5-拓展篇】Pycharm基本使用与AutoDL服务器连接】https://www.bilibili.com/video/BV1Ns4y1p7Ry?vd_source=f20f48824daff7c1a90e1d79ca71e468
先在服务器终端安装环境
source /etc/network_turbo
git clone https://github.com/sunsmarterjie/yolov12.git
cd yolov12/
wget https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.3/flash_attn-2.7.3+cu11torch2.2cxx11abiFALSE-cp311-cp311-linux_x86_64.whl
conda create -n yolov12 python=3.11
报错:conda 在读取清华镜像的 repodata.json 失败,指向的 URL 为 pkgs/free/noarch
RuntimeError: Unable to read repodata JSON file 'https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/noarch', error was: repository does not start with an object
`$ /root/miniconda3/bin/conda create -n yolov12 python=3.11`
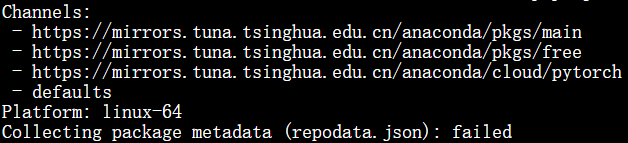
conda config --remove channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda clean -i -y
conda create -n yolov12 python=3.11 -y
conda init
source ~/.bashrc
conda activate yolov12pycharm配置
这一步可以不配,当做检验
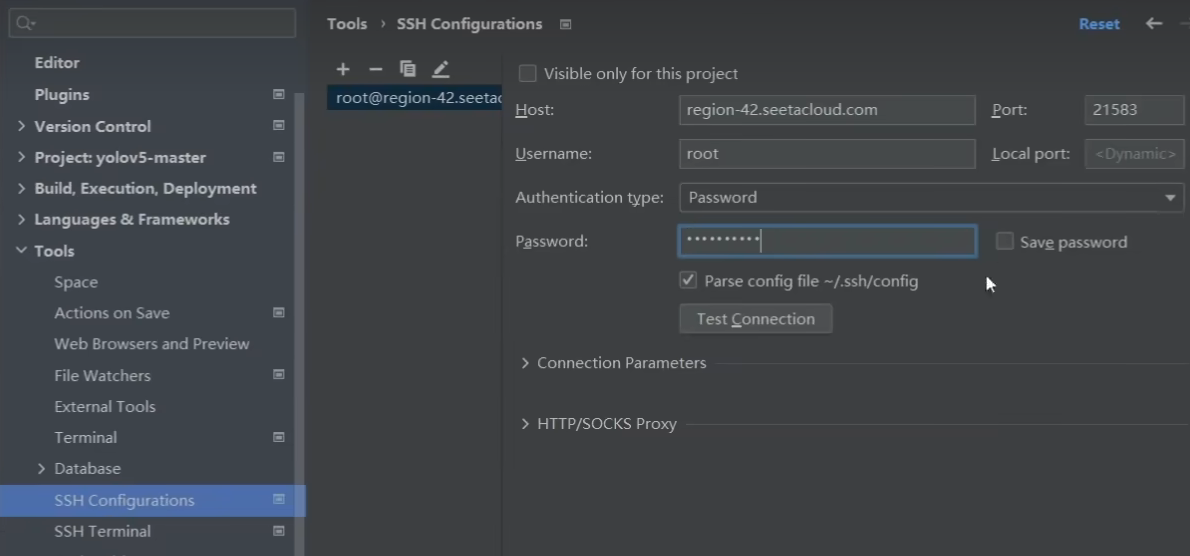
输入ssh配置
大家打开PyCharm专业版(一定是专业版!!!)
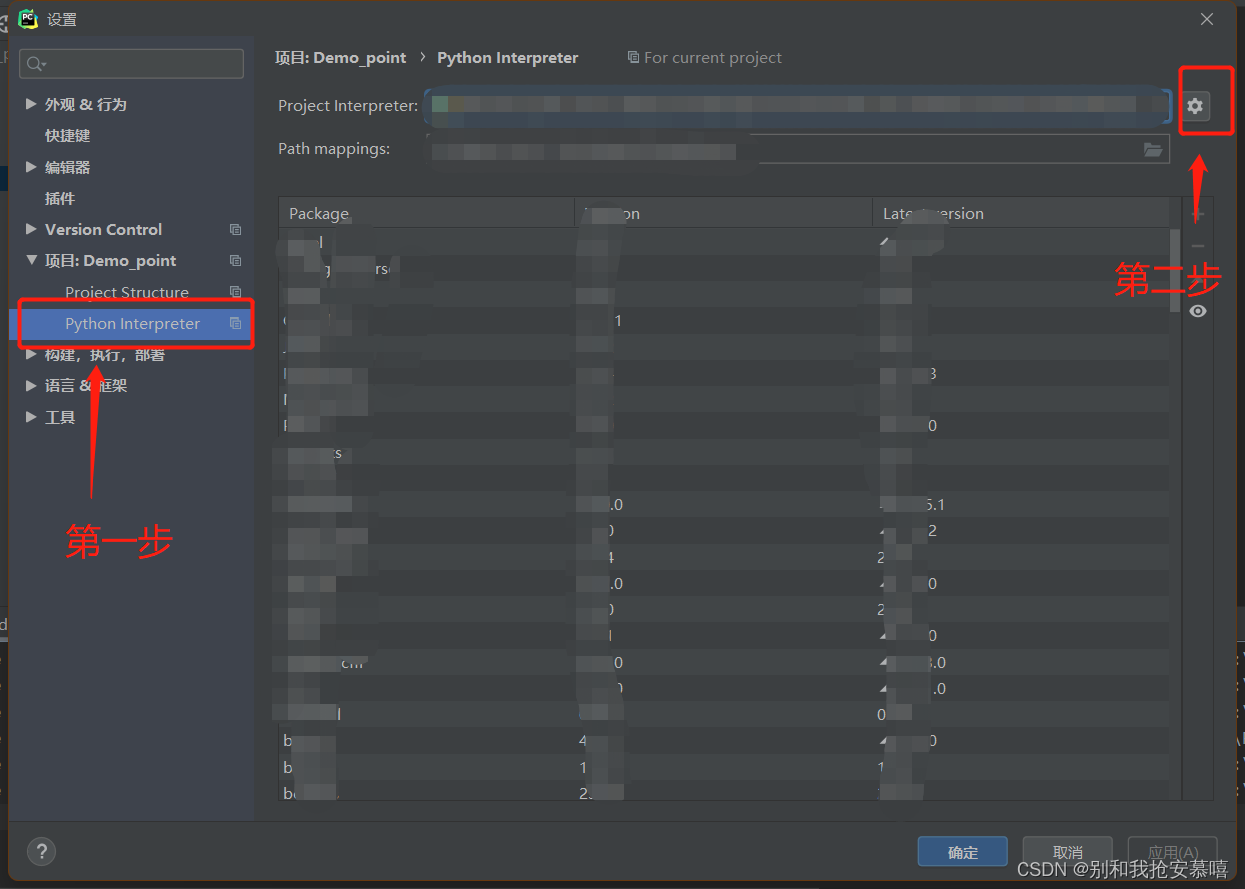
大家点击第二步的时候点击:add...这个选项
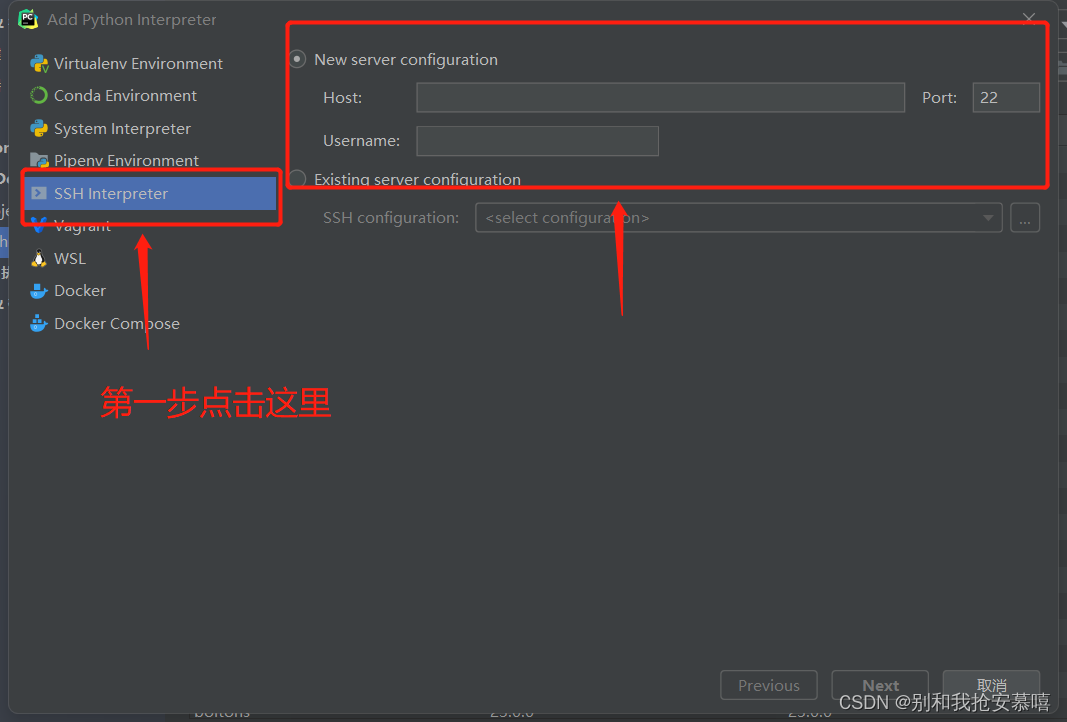
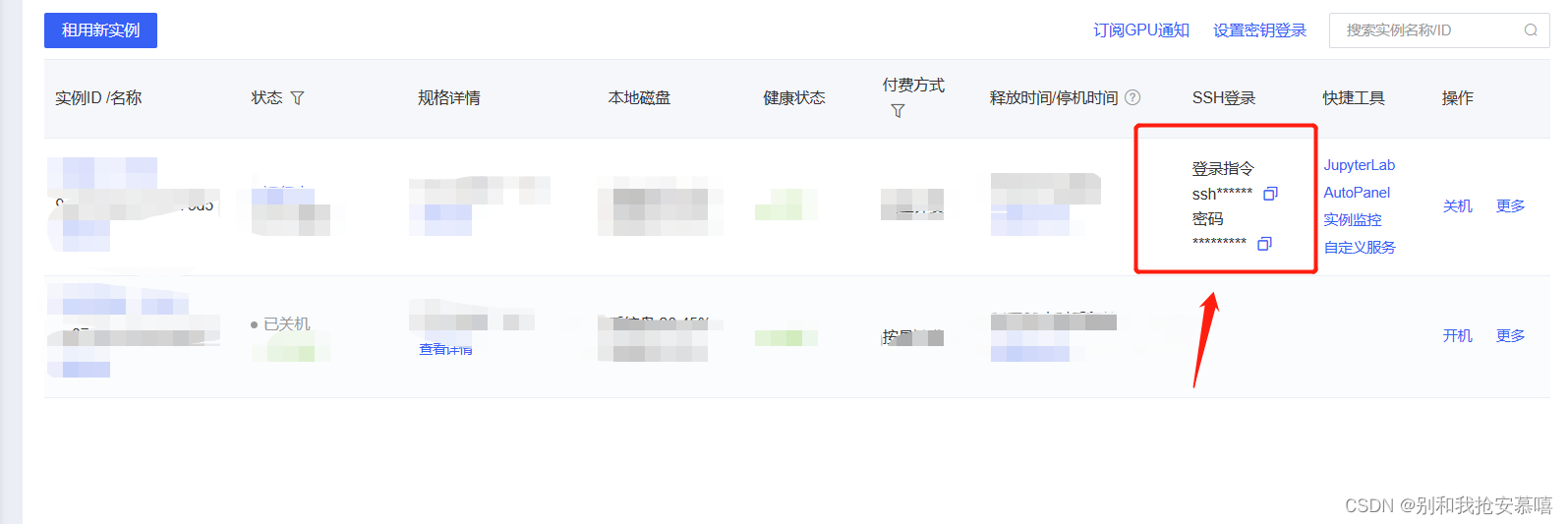
这里的登陆指令复制到上一张图的内容中:
这种形式的:ssh -p xxxx root@xxxxx.com
Host:root@xxxxx.com
Port:我们只要ssh -p后面的数字xxxx
Username:root
接下来会有一个输入密码password,就是上一张图的密码
参考https://blog.csdn.net/weixin_45325693/article/details/130914217?fromshare=blogdetail&sharetype=blogdetail&sharerId=130914217&sharerefer=PC&sharesource=weixin_58247017&sharefrom=from_link
路径选择,一般是root/miniconda3/envs/yolov12/bin/python3.11,也可以查询whereis python
不创建虚拟环境直接用服务器的base环境的话就是/root/miniconda3/bin/python

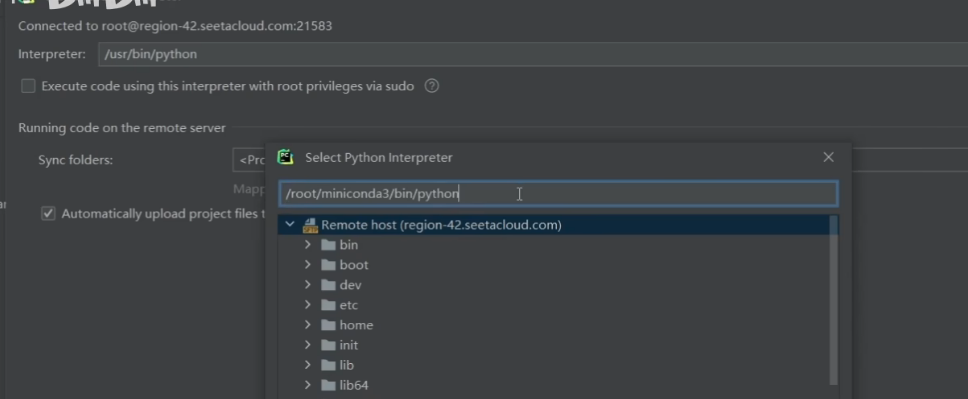
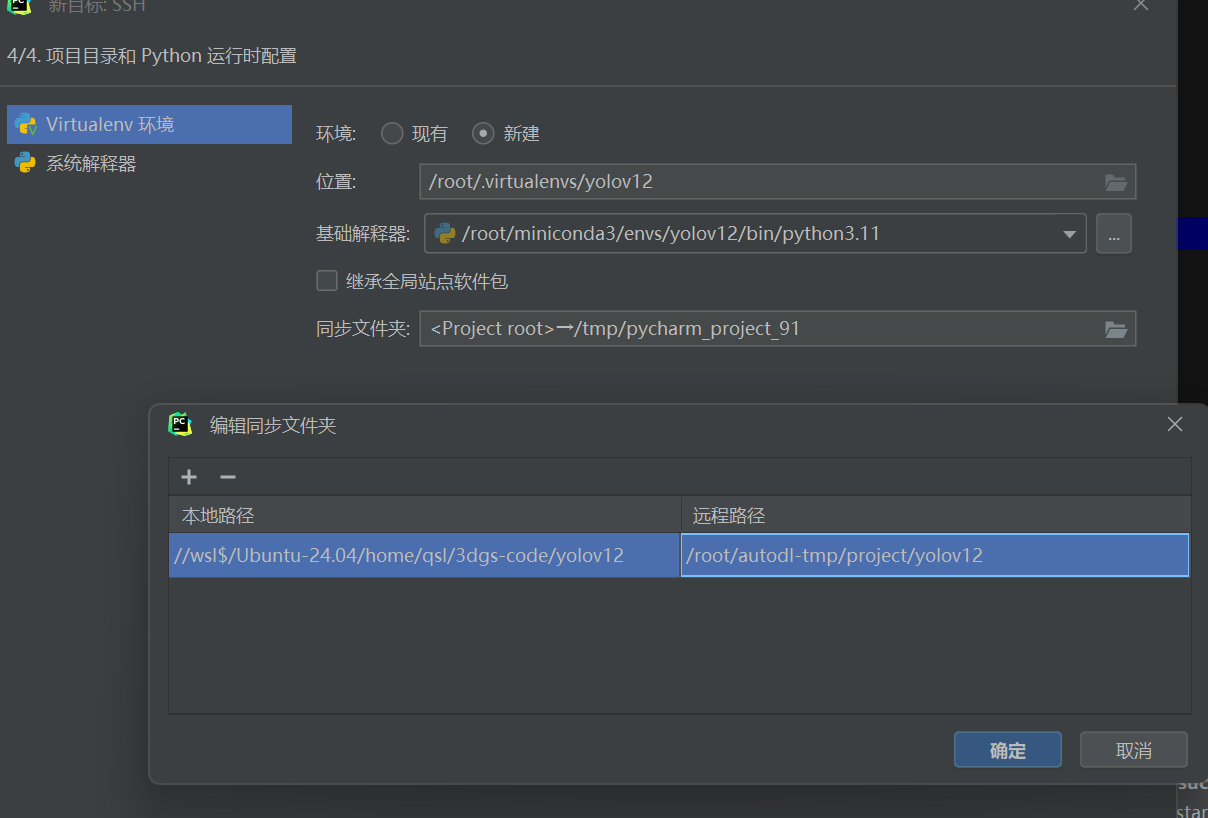
修改项目或者数据集上传到服务器的路径(可以新建)
一般传在(autodl-tmp-(自己的创建存放代码的文件夹))
这就链接成功了,可以在pycharm开启中断继续(当然也可以在JupyterLab终端上继续)

pip install -r requirements.txt
pip install -e .
上传权重以及数据集,数据yaml文件
注意修改数据集的yaml文件以及train.py文件(!!!!路径)
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: /root/autodl-tmp/project/datasets/deep_crack # dataset root dir
train: images/train # train images (relative to 'path') 3717 images
val: images/val # val images (relative to 'path') 112 images
test: images/test # test images (relative to 'path') 200 images
# Classes
names:
0: crack
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO('/root/autodl-tmp/project/yolov12/ultralytics/cfg/models/v12/yolo12n-seg.yaml')
# 代表使用yolov12n的神经网络结构
model.load('/root/autodl-tmp/project/yolov12/yolov12n-seg.pt')
# 代表使用yolov12n的预训练权重
model.train(data='/root/autodl-tmp/project/datasets/deep_crack/crack-seg.yaml', # 数据集yaml路径
imgsz=640, # 输入图像的尺寸为 640x640 像素
epochs=200, # 训练300轮
batch=16, # 每一批样本的数量
workers=8, # 同时32个线程
#copy_paste=0.3,
#patience=50,
device="0", #只使用第一张显卡进行训练
project='/root/autodl-tmp/project/yolov12/train_seg_n',
name='yolov12n-deep_crack',
)关机,重新开机
注意:修改服务器的文件后,pycharm可能不能及时同步导致训练错误,保存服务器上修改的文件,在pycharm端刷新即可
screen
conda activate yolov12
cd autodl-tmp/project/yolov12/
python train.py && /usr/bin/shutdown
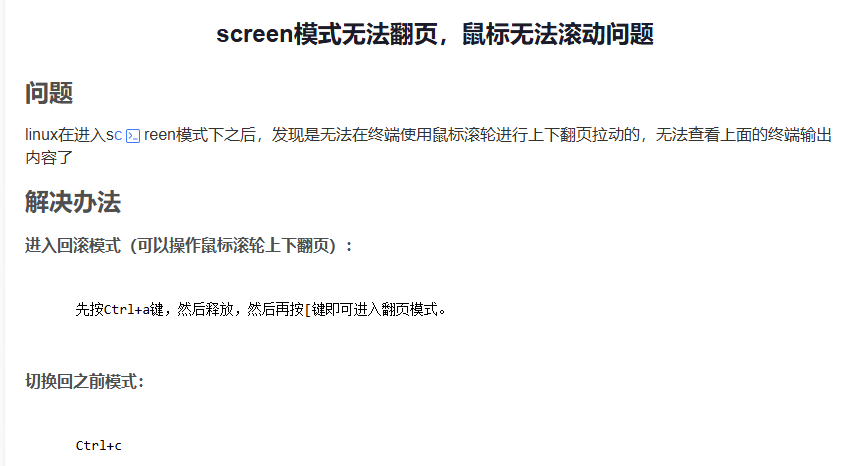
.修改screen的配置文件,添加滚动条
vim ~/.screenrc
termcapinfo xterm* ti@:te@当我在AutoDL(SSH)跑模型时,如何用screen来守护进程,防止因断网导致程序终止_screen守护进程-CSDN博客
程序出现变化会自动上传
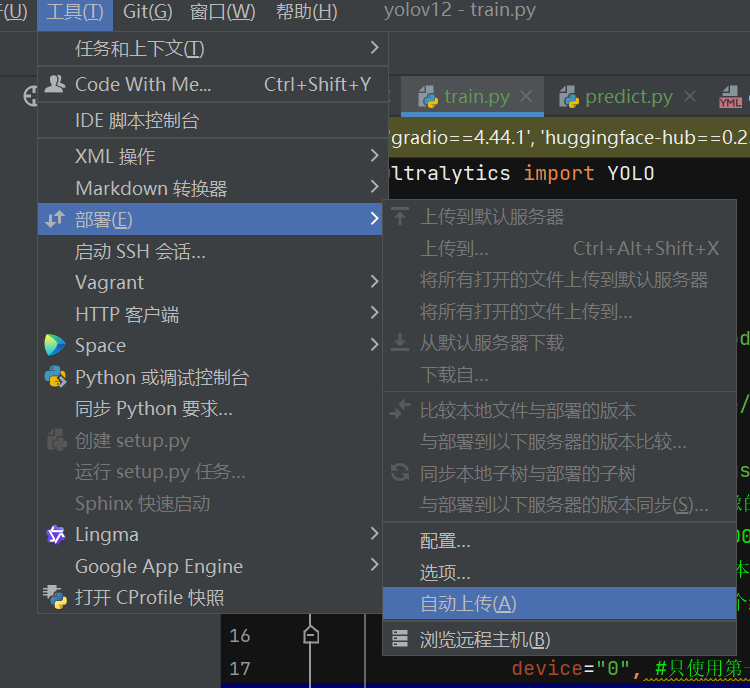
拉取服务器结果,上面的浏览远程主机
新建py文件不想在服务器运行(修改python解释器)
五、代码
ultralytics/models/yolo/model.py
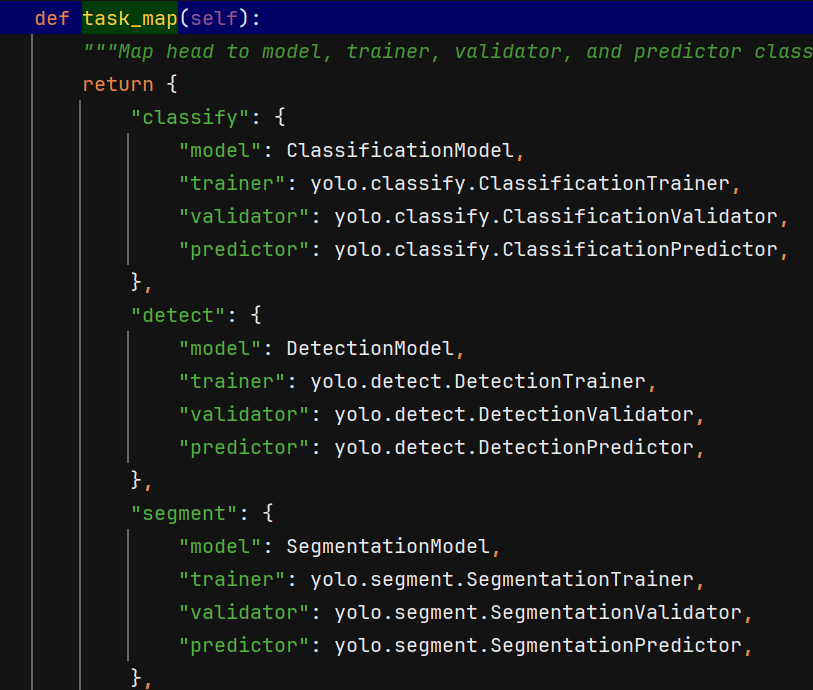
ultralytics/models/yolo/segment/train.py
# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license
from copy import copy
from ultralytics.models import yolo
from ultralytics.nn.tasks import SegmentationModel
from ultralytics.utils import DEFAULT_CFG, RANK
from ultralytics.utils.plotting import plot_images, plot_results
class SegmentationTrainer(yolo.detect.DetectionTrainer):
"""
A class extending the DetectionTrainer class for training based on a segmentation model.
Example:
```python
from ultralytics.models.yolo.segment import SegmentationTrainer
args = dict(model="yolov8n-seg.pt", data="coco8-seg.yaml", epochs=3)
trainer = SegmentationTrainer(overrides=args)
trainer.train()
```
"""
def __init__(self, cfg=DEFAULT_CFG, overrides=None, _callbacks=None):
"""Initialize a SegmentationTrainer object with given arguments."""
if overrides is None:
overrides = {}
overrides["task"] = "segment"
super().__init__(cfg, overrides, _callbacks)
def get_model(self, cfg=None, weights=None, verbose=True):
"""Return SegmentationModel initialized with specified config and weights."""
model = SegmentationModel(cfg, ch=3, nc=self.data["nc"], verbose=verbose and RANK == -1)
if weights:
model.load(weights)
return model
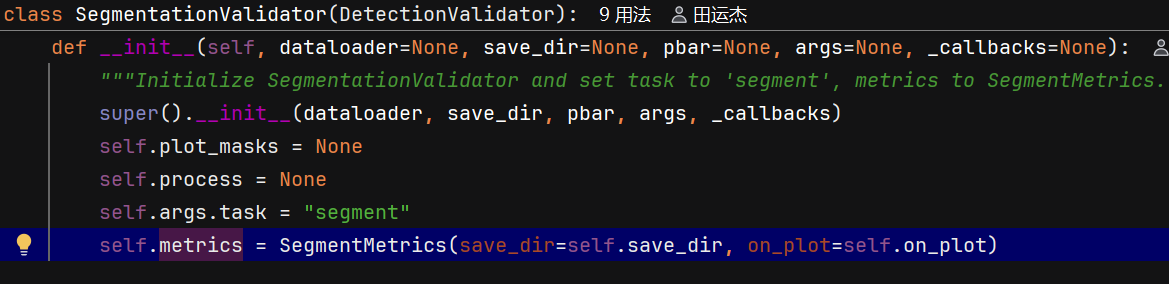
def get_validator(self):
"""Return an instance of SegmentationValidator for validation of YOLO model."""
self.loss_names = "box_loss", "seg_loss", "cls_loss", "dfl_loss"
return yolo.segment.SegmentationValidator(
self.test_loader, save_dir=self.save_dir, args=copy(self.args), _callbacks=self.callbacks
)
def plot_training_samples(self, batch, ni):
"""Creates a plot of training sample images with labels and box coordinates."""
plot_images(
batch["img"],
batch["batch_idx"],
batch["cls"].squeeze(-1),
batch["bboxes"],
masks=batch["masks"],
paths=batch["im_file"],
fname=self.save_dir / f"train_batch{ni}.jpg",
on_plot=self.on_plot,
)
def plot_metrics(self):
"""Plots training/val metrics."""
plot_results(file=self.csv, segment=True, on_plot=self.on_plot) # save results.png
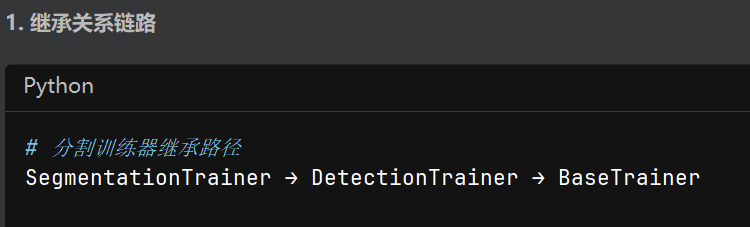

讲了一些BaseTrainer
【25k字】图文解读YOLOv8及实例分割(附python代码)_yolov8实例分割-CSDN博客
loss
ultralytics/nn/tasks.py
class SegmentationModel(DetectionModel):
"""YOLOv8 segmentation model."""
def __init__(self, cfg="yolov8n-seg.yaml", ch=3, nc=None, verbose=True):
"""Initialize YOLOv8 segmentation model with given config and parameters."""
super().__init__(cfg=cfg, ch=ch, nc=nc, verbose=verbose)
def init_criterion(self):
"""Initialize the loss criterion for the SegmentationModel."""
return v8SegmentationLoss(self)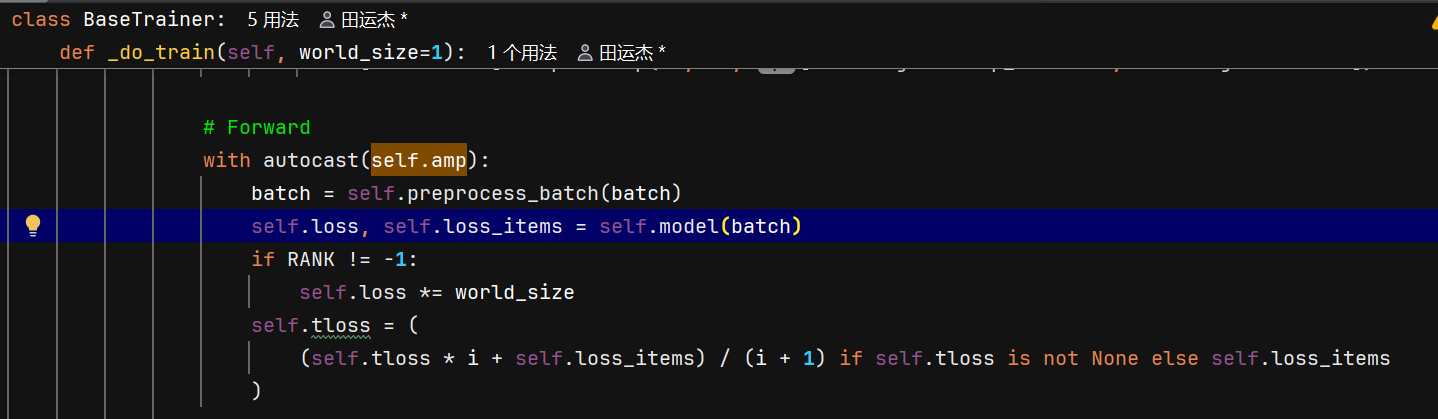
ultralytics/engine/trainer.py中loss,self.model(batch) 调用模型的forward方法
这里的model是SegmentationTrainer 调用的get_model,就是SegmentationModel
(ultralytics/models/yolo/segment/train.py)
loss函数中preds
当创建YOLO实例并选择segment任务时,在yolo/model.py中task_map,segment对应SegmentationModel。然后DetectionModel的初始化parse_model函数会加载yaml配置并解析模型结构(包含backbone(特征提取)、neck(特征融合)和head(分割头)三个主要部分)


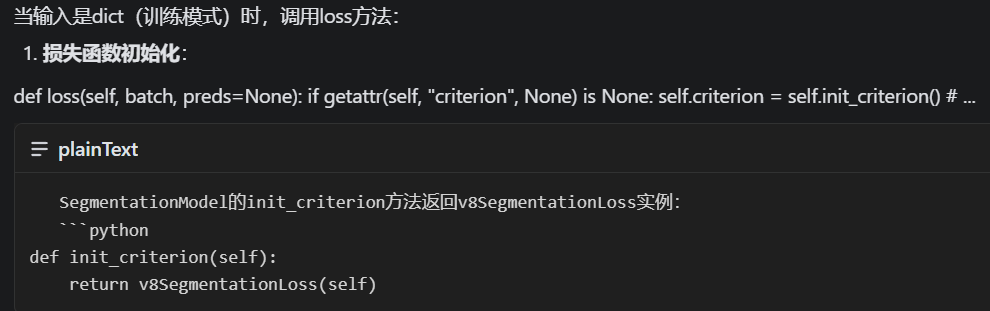
训练模式下,调用loss
1.损失函数初始化
2.获取预测结果:
ultralytics/nn/tasks.py
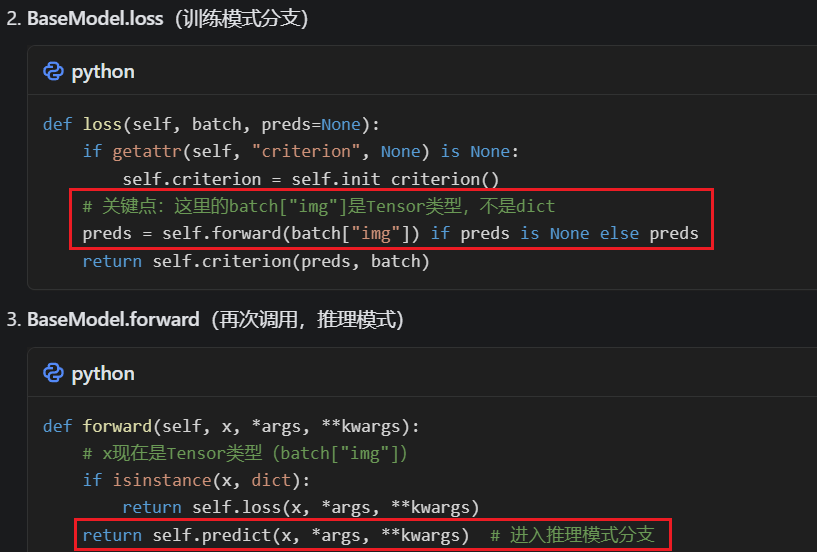
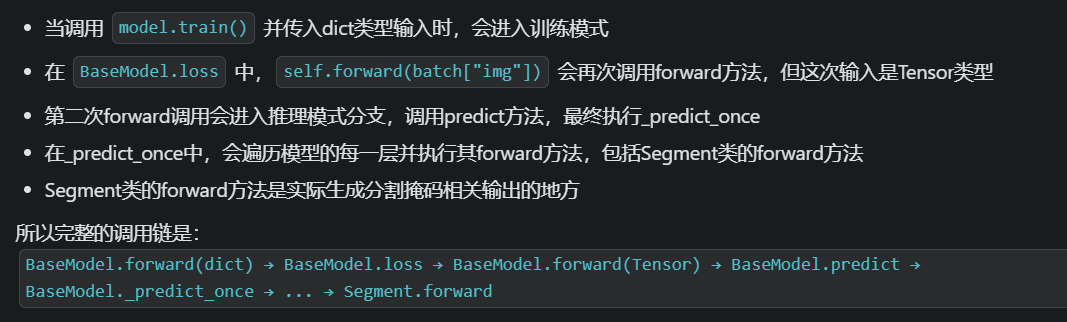
ultralytics/nn/modules/head.py Segment的forward
3.计算loss
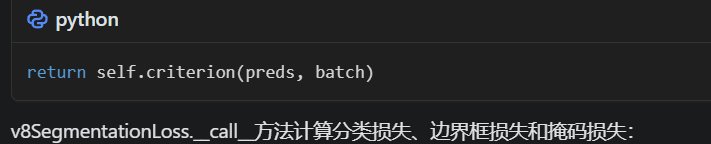
loss在ultralytics/utils/loss.py中的v8SegmentationLoss类
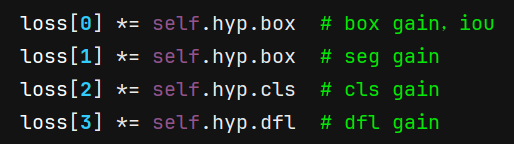
损失包括:
- 分割相关的
损失seg - 继承了目标检测任务的
分类损失cls,和矩形框回归损失(iou loss,DFL loss)
loss对应的权重,在ultralytics/cfg/default.yaml中

分割损失计算单张图像的损失再求和平均
def single_mask_loss(
gt_mask: torch.Tensor, pred: torch.Tensor, proto: torch.Tensor, xyxy: torch.Tensor, area: torch.Tensor
) -> torch.Tensor:
"""
Compute the instance segmentation loss for a single image.
计算单张图像的掩码损失
Args:
gt_mask (torch.Tensor): Ground truth mask of shape (n, H, W), where n is the number of objects.
pred (torch.Tensor): Predicted mask coefficients of shape (n, 32).
proto (torch.Tensor): Prototype masks of shape (32, H, W).
xyxy (torch.Tensor): Ground truth bounding boxes in xyxy format, normalized to [0, 1], of shape (n, 4).
area (torch.Tensor): Area of each ground truth bounding box of shape (n,).
Returns:
(torch.Tensor): The calculated mask loss for a single image.
Notes:
The function uses the equation pred_mask = torch.einsum('in,nhw->ihw', pred, proto) to produce the
predicted masks from the prototype masks and predicted mask coefficients.
"""
pred_mask = torch.einsum("in,nhw->ihw", pred, proto) # (n, 32) @ (32, 80, 80) -> (n, 80, 80)
loss = F.binary_cross_entropy_with_logits(pred_mask, gt_mask, reduction="none")
return (crop_mask(loss, xyxy).mean(dim=(1, 2)) / area).sum()
【YOLOv8 代码解读】所有任务Loss损失代码梳理_dfl loss-CSDN博客
best.pt选取
yolov8 选择并保存best.pt的依据 (附带修改记录,) + 设置早停-CSDN博客
在 ultralytics/engine/trainer.py 中,选取 best.pt 的逻辑主要在以下几个地方:
- validate():返回 metrics 和 fitness,(metrics返回一个字典,各种指标以及fitness)并更新 self.best_fitness(当当前 fitness 更好时)。
- 训练主流程(\_do_train):在每个 epoch 验证后调用 self.metrics, self.fitness = self.validate(),随后会调用保存相关逻辑。
- save_model():把当前 checkpoint 写入 last.pt,并在 self.best_fitness == self.fitness 时写入 best.pt。(只有权重出现更好的时才会存入)
- resume_training():从 checkpoint 恢复时会读入并设置 self.best_fitness,以保证继续训练时能正确比较。
- final_eval():在训练结束时会加载并验证 self.best(即 best.pt)。
总结:选 best.pt 是通过 validate() 计算并更新 self.best_fitness,再由 save_model() 在满足条件时写出 best.pt。
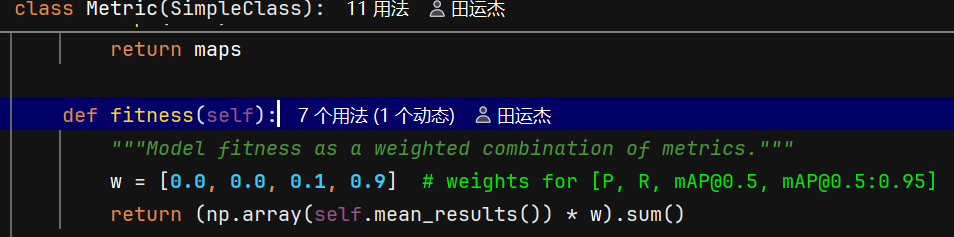
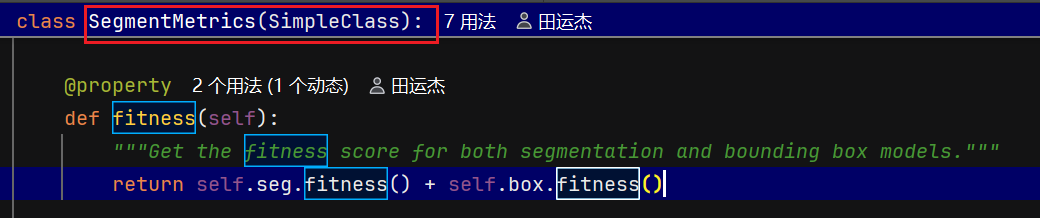
# 若需调整权重,编辑 Metric.fitness 中的 w 列表(例如提高 mask 权重或改变 mAP 权重)
self.metrics, self.fitness = self.validate()
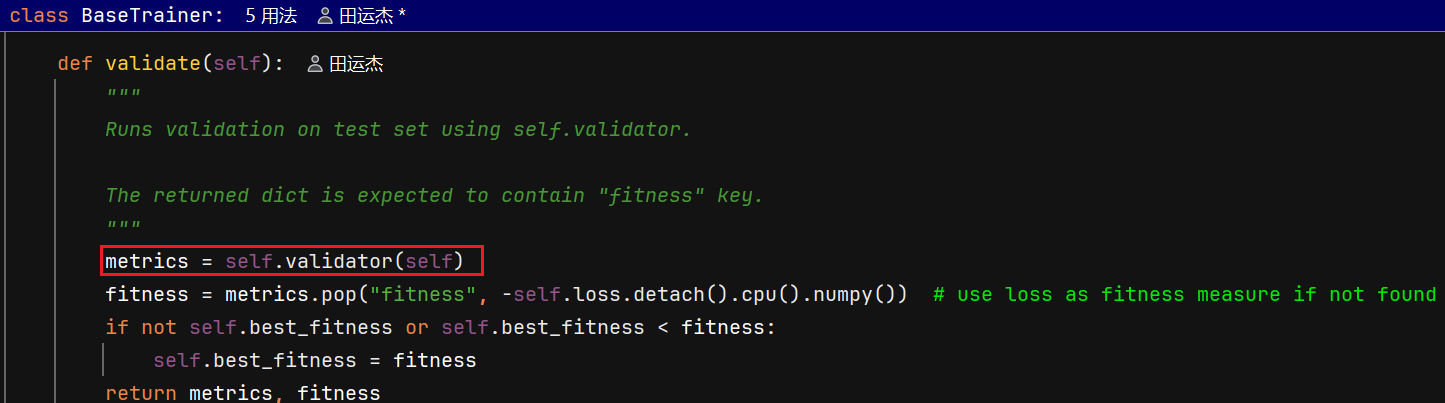
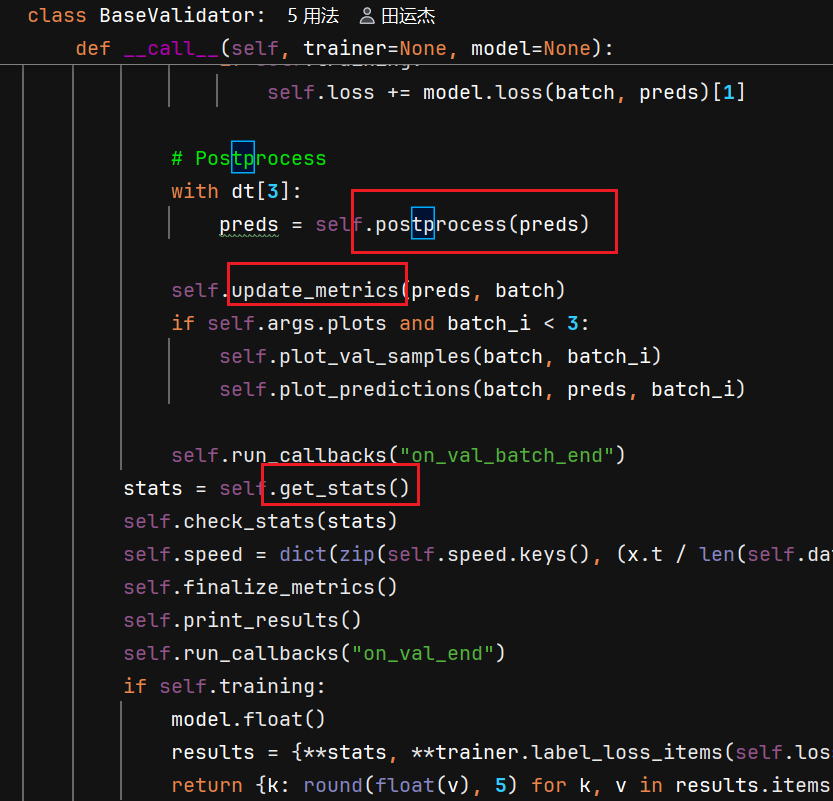
调用 self.validator(self) 会触发其 __call__(BaseValidator 中的调用流程)
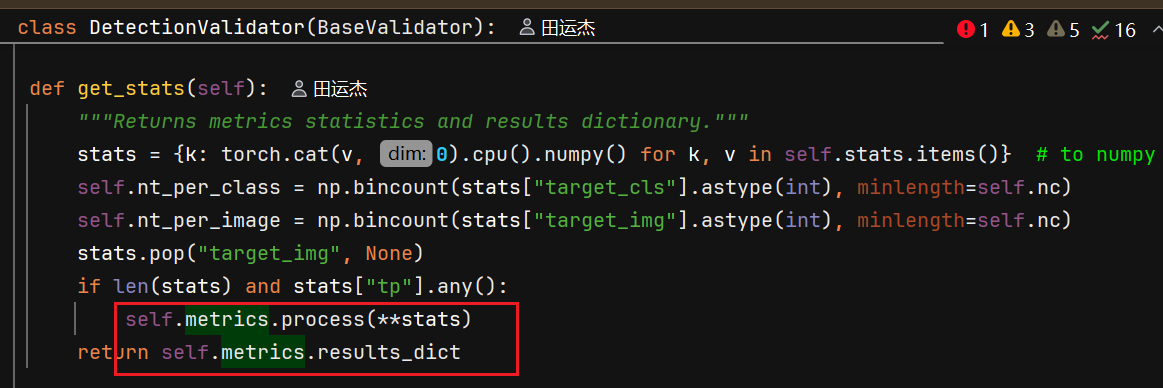
其中一些调用SegmentValidator中的方法
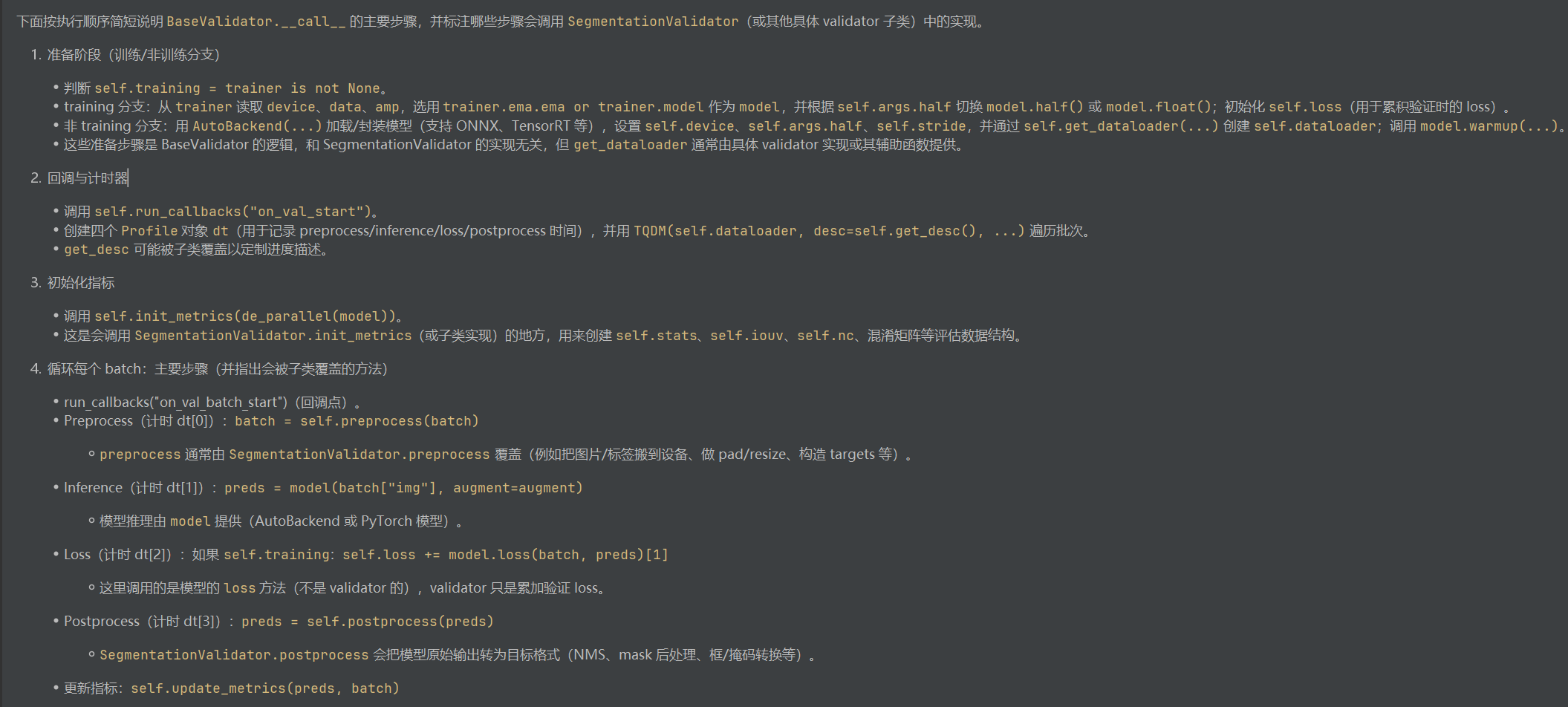
ultralytics/utils/metrics.py
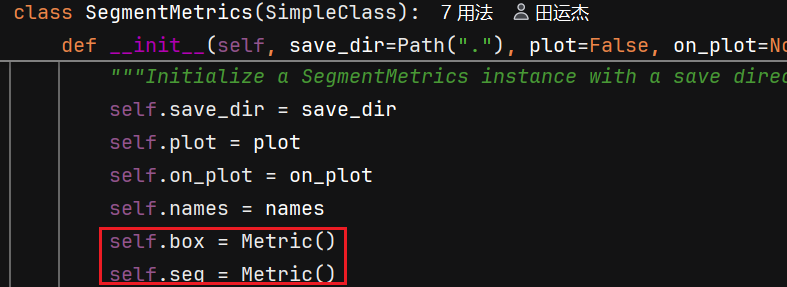
指标解释
ultralytics/utils/metrics.py
不同IoU阈值的意义:较低的IoU阈值(如0.5)更关注检测是否成功("框到了"),而较高的阈值(如0.95)则严格要求定位必须极为精确

Attributes:
p (list): Precision for each class. Shape: (nc,).
r (list): Recall for each class. Shape: (nc,).
f1 (list): F1 score for each class. Shape: (nc,).
all_ap (list): AP scores for all classes and all IoU thresholds.
Shape: (nc, 10).
存储所有类别在不同IoU阈值([0.5, 0.55, 0.6, 0.65, 0.7, 0.75, 0.8, 0.85, 0.9, 0.95])下的平均精度得分
ap_class_index (list): Index of class for each AP score. Shape: (nc,).
nc (int): Number of classes.
Methods:
ap50(): AP at IoU threshold of 0.5 for all classes. Returns: List of AP scores. Shape: (nc,) or [].存储所有类别在IoU阈值为0.5下的平均精度得分(就是all_ap的第一列)
ap(): AP at IoU thresholds from 0.5 to 0.95 for all classes. Returns: List of AP scores. Shape: (nc,) or [].#对每个类别在所有IoU阈值上取平均,
(AP@0.5 + AP@0.55 + ... + AP@0.95) / 10
mp(): Mean precision of all classes. Returns: Float.
mr(): Mean recall of all classes. Returns: Float.
map50(): Mean AP at IoU threshold of 0.5 for all classes. Returns: Float.
ap50().mean(就是all_ap的第一列的平均数)
map75(): Mean AP at IoU threshold of 0.75 for all classes. Returns: Float.
(就是all_ap的第六列的平均数)
map(): Mean AP at IoU thresholds from 0.5 to 0.95 for all classes. Returns: Float.(就是ap()/类别数)
mean_results(): Mean of results, returns mp, mr, map50, map.
class_result(i): Class-aware result, returns p[i], r[i], ap50[i], ap[i].
maps(): mAP of each class. Returns: Array of mAP scores, shape: (nc,).
fitness(): Model fitness as a weighted combination of metrics. Returns: Float.
update(results): Update metric attributes with new evaluation results.


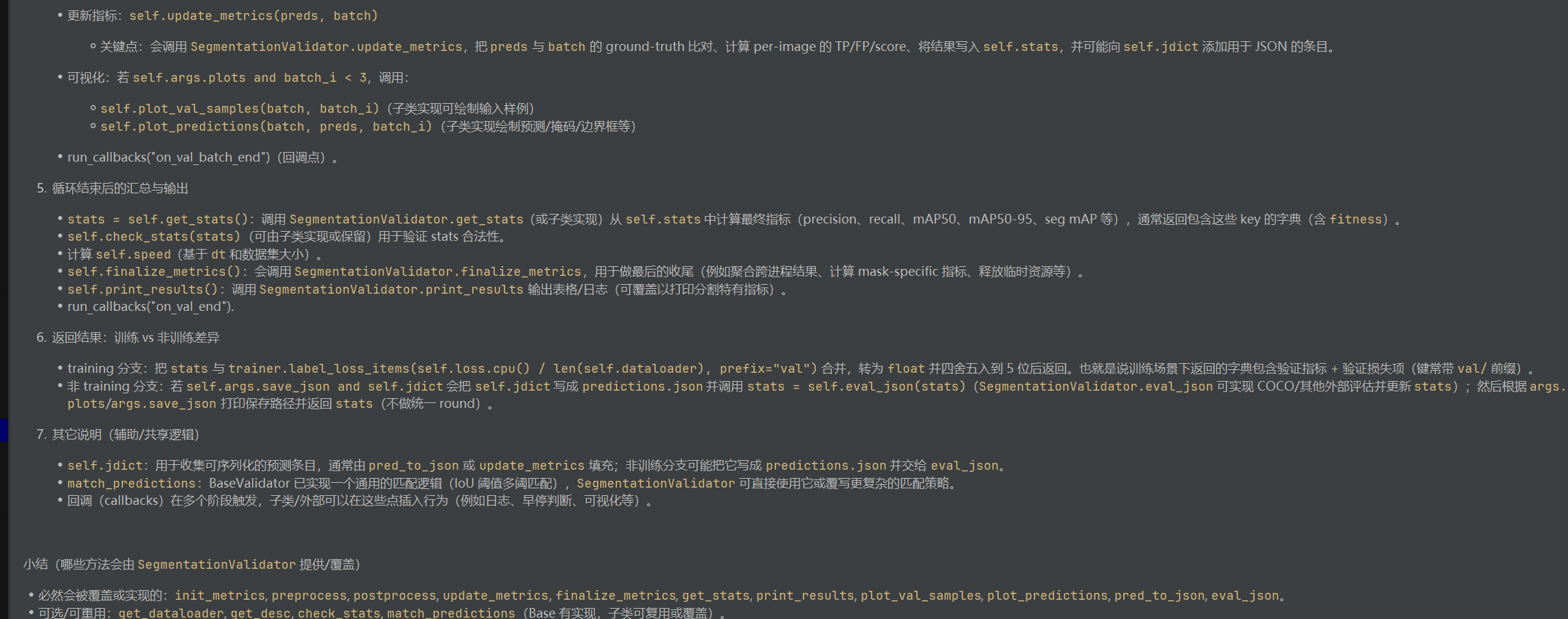
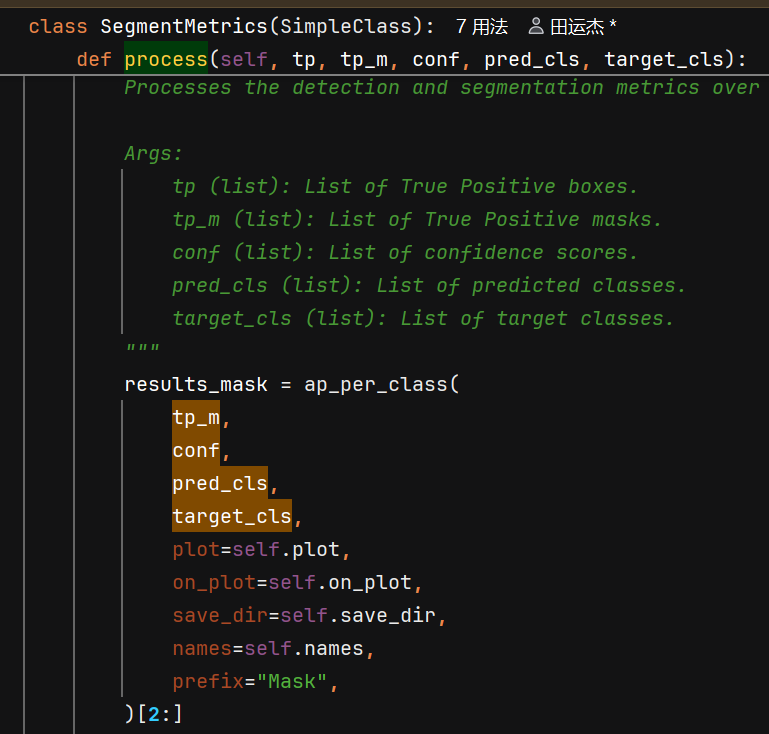
计算ap
先计算tp
像loss中计算preds一样,使用推理模式
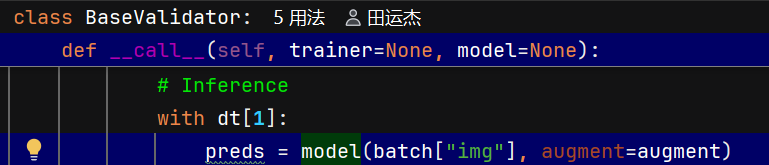
模型输出:每个预测框有一个置信度分数(如0.92、0.85等)。
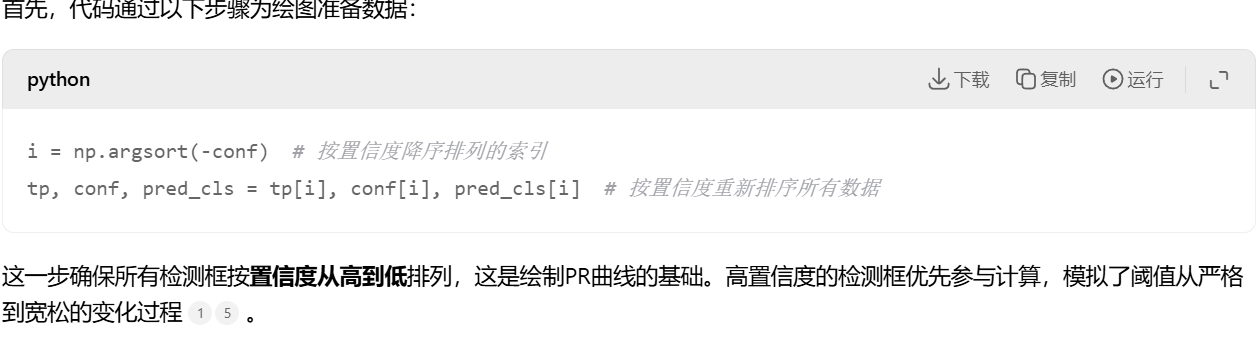
排序:将所有预测框按置信度从高到低排序。
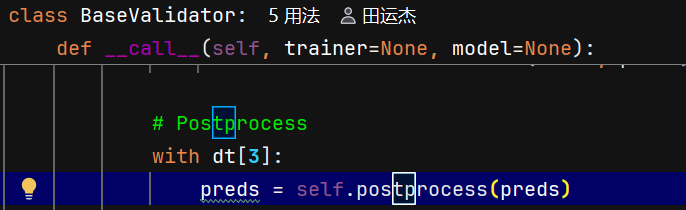
postprocess 方法调用 ops.non_max_suppression,NMS 默认会按置信度降序排列输出的预测框
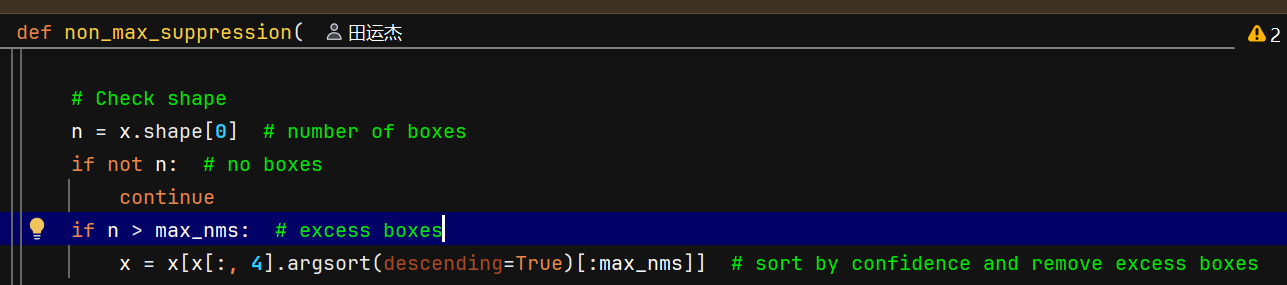
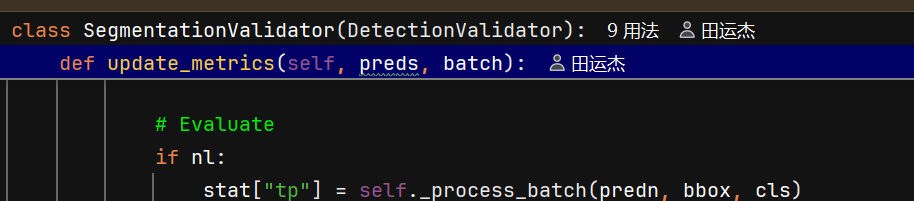
后续匹配:用排序后的预测依次与所有真实框做IoU匹配(设定IoU阈值(如0.5),IoU大于阈值,),能则tp=1,否则tp=0。输出是(检测框的数目,10)
每个真实框最多只能被一个预测框匹配(通常优先分配给置信度最高的预测)
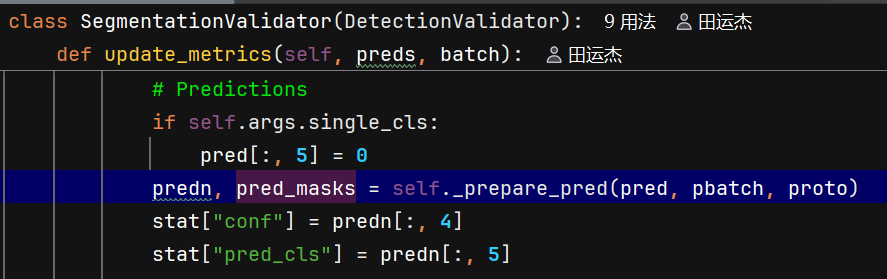
先处理preds,
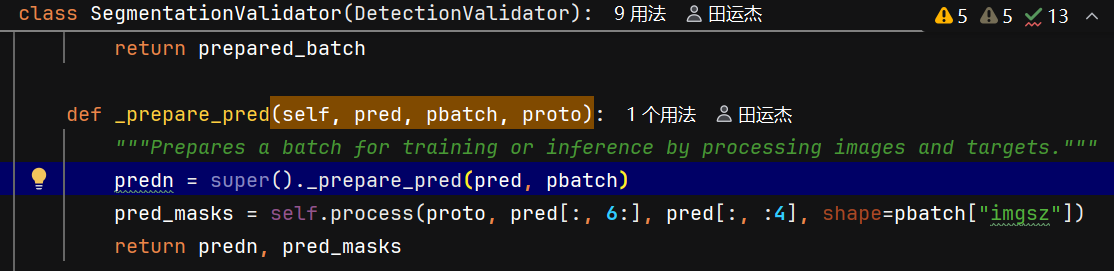
- predn边界框缩放:DetectionValidator的
_prepare_pred方法将预测框从模型输出尺寸缩放到原始图像尺寸 - pred_masks掩码生成:使用掩码原型和掩码系数(pred中),通过矩阵乘法生成初始掩码,再根据边界框裁剪得到最终掩码

然后计算ap
ultralytics/engine/validator.py

在每一类中,tpc,fpc,p,r的维度都是(n,10),n为检测框数量

-
动态模拟:通过
cumsum,我们模拟了置信度阈值从高到低变化时,TP和FP的累积过程,得到了一系列(Recall, Precision)数据点。 -
插值:由于这些原始数据点的置信度阈值分布不均匀,直接绘图会不平滑。通过
np.interp将它们映射到1000个均匀分布的召回率点上,生成平滑的曲线。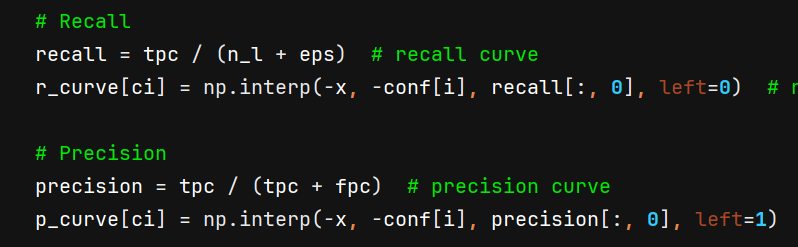
置信度为横坐标(横坐标递增) -
绘图与计算:利用插值后得到的
p_curve和r_curve(均为(nc, 1000)维度的数组),可以绘制出平滑的PR曲线,积分得到AP(Average Precision)。
每个iou都有一个pr图,所以每一类有iou个ap
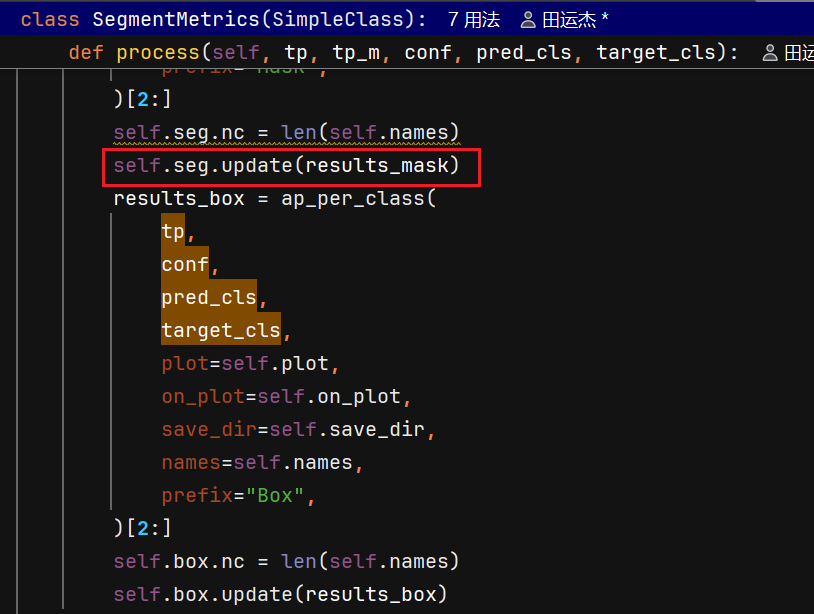
update得到all_ap
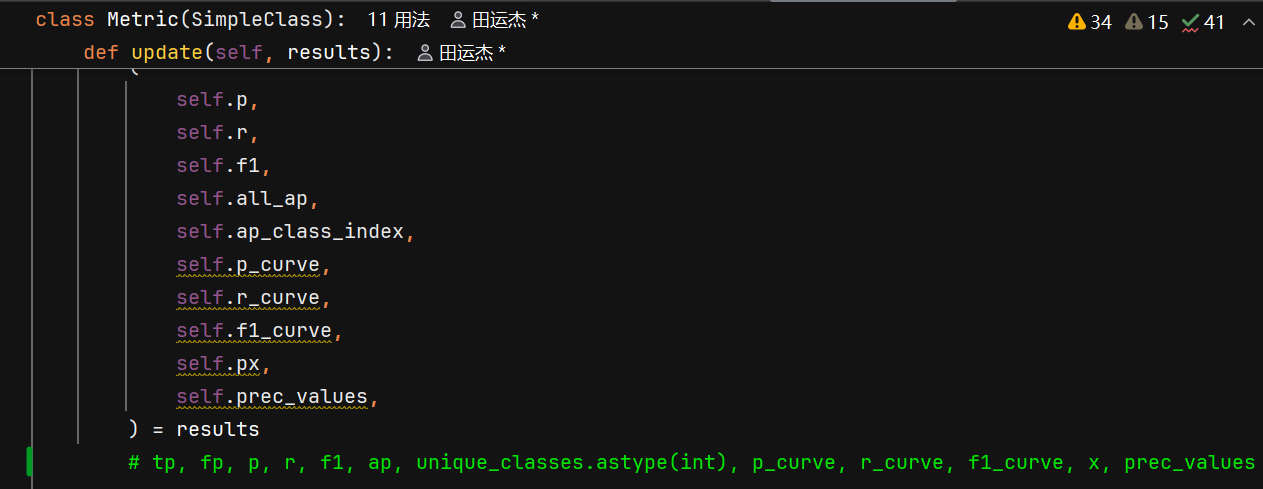
iou和conf
两个iou的解释
1. NMS中IoU阈值的使用
配置文件default.yaml中的iou: 0.7设置用于**非极大值抑制(NMS)**过程:
- 调用位置:在
ultralytics/models/yolo/segment/val.py第73行的postprocess方法中 - 使用方式:
ops.non_max_suppression(preds[0], self.args.conf, self.args.iou, ...) - 作用:当两个预测框的IoU大于0.7时,保留置信度更高的框,过滤重叠的低置信度框
- 参数来源:配置文件中的
iou值通过命令行参数或配置文件加载,存储在self.args.iou中
2. AP计算中的多个IoU阈值
在AP计算中使用了10个IoU阈值,这与NMS的IoU阈值是不同的概念:
- 阈值范围:0.5到0.95,步长0.05(共10个阈值)
- 调用位置:在
ultralytics/utils/metrics.py的ap_per_class函数中 - 作用:计算不同IoU严格程度下的平均精度(AP),用于评估模型在不同检测严格度下的性能
- 结果应用:
mAP50:IoU=0.5时的平均精度mAP50-95:10个IoU阈值下AP的平均值
3. 两者的关系与区别
- 阶段不同:
- NMS的IoU阈值用于推理阶段,过滤重叠预测框
- AP计算的IoU阈值用于评估阶段,衡量模型性能
- 作用不同:
- NMS阈值影响最终输出的预测框数量和质量
- AP阈值影响模型性能指标的计算
- 没有冲突:两者是独立的参数,用于不同的目的,不存在冲突
`conf`参数控制了预测边界框的置信度阈值。默认情况下,只有当预测边界框的置信度高于该阈值时,才会被认为是有效的目标边界框。如果设置较高的`conf`阈值,则会筛除一些低置信度的边界框,从而提高准确性。但是,这也可能导致漏检(即未能检测到真实目标)。相反,如果设置较低的`conf`阈值,则更多的边界框会被保留下来,但其中可能包含一些误检(即将背景等非目标识别为目标)。
请问深度学习yolov8测试验证的时候,参数conf和iou必须用默认值吗,可以自己调让指标升高点吗? - 知乎
mask抠图
使用yolo-seg模型实现自定义自动动态抠图_抠图模型-CSDN博客
其他

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 16
16 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)