AI技术(三):RAG及简单示例
本文介绍了RAG(检索增强生成)技术的实现流程,通过构建知识库和查询两个核心步骤,让AI模型能够像"开卷考试"一样结合外部知识回答问题。
目录
前言
简单来说,RAG(检索增强生成)就像是让AI模型进行一场“开卷考试”。当AI回答你的问题时,它不再仅仅依靠自己的记忆,而是会先去“翻书”(检索外部知识库),找到相关的资料,再结合这些资料组织成一个准确的答案。下面通过一个表格来做对比:
|
没有RAG的AI |
拥有RAG的AI |
|
|---|---|---|
|
工作方式 |
像“闭卷考试”,只依赖模型训练时学到的知识 |
像“开卷考试”,先查外部资料再回答 |
|
知识时效性 |
知识停留在训练数据截止日期,可能过时 |
知识库可随时更新,能获取最新信息 |
|
答案准确性 |
容易产生“幻觉”,即一本正经地胡说八道 |
答案基于权威资料,更准确可靠 |
|
定制化能力 |
难以针对特定领域(如公司内部文件)深度定制 |
可轻松接入专属知识库,提供个性化回答 |
RAG构建流程
1、构建知识库
(1)embedding(向量化):将收集到的资源进行向量化。
(2)存储:将资源和向量对应存到向量数据库。
2、查询
(1)embedding(向量化):将用户的问题进行向量化。
(2)查询:在向量数据库中检索与问题相近的片段。
(3)生成:将问题和查询到的内容拼接,输入大语言模型生成最终答案。
下面通过代码来理解一下这两个过程。(此代码学习来源于b站UP主:隔壁的程序员老王,视频链接:从零写AI RAG 个人知识库)
准备工作
1、大模型:向量模型,大语言模型,这里我用的豆包的Doubao-Seed-1.6大语言模型和Doubao-embedding向量模型。
2、AI编程工具:trae。
3、文章和代码等内容可通过原视频获取。
创建步骤
1、构建知识库
(1)准备好文章内容,并进行切片,代码存放在chunk.py文件里面。

#chunk.py
def read_date() -> str: #读取文件内容
with open('data.md', 'r', encoding='utf-8') as f:
return f.read()
def get_chunks() -> list[str]: #拆分文章内容
content = read_date()
chunks = content.split('\n\n')
header = ''
res = []
for chunk in chunks:
if chunk.startswith('#'):
header += f"{chunk}\n"
else:
res.append(header + chunk)
header = ''
return res
if __name__ == '__main__':
chunks = get_chunks()
for chunk in chunks:
print(chunk)
print("-----------------------")
(2)创建embed.py,里面主要包含向量化操作、建立向量数据库操作及查询操作。这里用的向量数据库是chromadb,比较简洁,适合理论研究。
1)将内容转化为向量。
def embed(key,content): #content为传入的原文内容
client = Ark(api_key=key) #接口调用可查看火山引擎的API调用文档
resp = client.embeddings.create(
model=embedding_model,
input=content,
encoding_format="float",
)
return resp2)内容和向量一一对应,存入向量数据库。
def create_db():
for idx, content in enumerate(chunk.get_chunks()): #调用chunk.py里面的方法
print(f"Process:{content}")
embedding = embed(ARK_API_KEY,content) #调用embedding
chromadb_collection.upsert( #chromadb数据库的使用方法
ids = str(idx),
documents=content, #content为原文内容
embeddings=embedding.data[0].embedding #根据火山引擎的api文档,embedding.data[0].embedding为生成的向量
)至此,构建知识库的环节已完成。
2、查询
(1)将用户的问题向量化,并在向量数据库中检索与问题相近的片段。
def query_db(question):
question_embedding = embed(ARK_API_KEY,question) #调用embedding将问题向量化
results = chromadb_collection.query( #在向量数据库中查询比对
query_embeddings=question_embedding.data[0].embedding,
n_results=5
)
return results['documents'](2)将问题和查询到的内容拼接,输入大语言模型生成最终答案。
question = "令狐冲领悟到了什么样的魔法"
results = query_db(question)
prompt = "请根据内容回答用户的问题\n"
prompt += f"问题:{question}\n"
prompt += f"内容:\n"
for each in results[0]:
prompt += f"{each}\n"
prompt += '---------------------'
res = client.chat.completions.create( #这里是火山引擎大语言模型的接口
model=llm_model,
messages=[
{"role": "user", "content": prompt}
],
temperature=0.5,
max_tokens=1024,
top_p=0.5,
presence_penalty=0.0,
frequency_penalty=0.0,
)
print(res.choices[0].message.content)(3)看一下效果
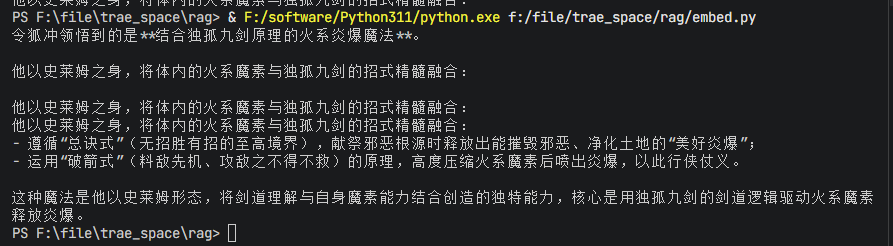
(4)embed.py完整代码
#embed.py
import chunk
import chromadb
from volcenginesdkarkruntime import Ark
ARK_API_KEY = 'your own key'
llm_model = 'doubao-seed-1-6-251015'
embedding_model = 'doubao-embedding-text-240715'
chroma_client = chromadb.PersistentClient(path="./chroma_db")
chromadb_collection = chroma_client.get_or_create_collection(name="linghuchong")
client = Ark(api_key=ARK_API_KEY)
def embed(key,content):
client = Ark(api_key=key)
resp = client.embeddings.create(
model=embedding_model,
input=content,
encoding_format="float",
)
return resp
def create_db():
for idx, content in enumerate(chunk.get_chunks()):
print(f"Process:{content}")
embedding = embed(ARK_API_KEY,content)
chromadb_collection.upsert(
ids = str(idx),
documents=content,
embeddings=embedding.data[0].embedding
)
def query_db(question):
question_embedding = embed(ARK_API_KEY,question)
results = chromadb_collection.query(
query_embeddings=question_embedding.data[0].embedding,
n_results=5
)
return results['documents']
if __name__ == '__main__':
# chunks = chunk.get_chunks()
# #chunk是原文,每个chunk对应一个resp.data[0].embedding
# for chunk in chunks:
# resp = embed(ARK_API_KEY,chunk)
# print(resp.data[0].embedding)
# create_db()
question = "令狐冲领悟到了什么样的魔法"
results = query_db(question)
prompt = "请根据内容回答用户的问题\n"
prompt += f"问题:{question}\n"
prompt += f"内容:\n"
for each in results[0]:
prompt += f"{each}\n"
prompt += '---------------------'
res = client.chat.completions.create(
model=llm_model,
messages=[
{"role": "user", "content": prompt}
],
temperature=0.5,
max_tokens=1024,
top_p=0.5,
presence_penalty=0.0,
frequency_penalty=0.0,
)
print(res.choices[0].message.content)
结语
重点理解原理,不同的模型得出来的结果可能不一样,但是原理大致如此。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)