向量数据库简介
向量数据库摘要 向量数据库是一种专门用于存储和检索向量嵌入(Vector Embedding)的非结构化数据数据库系统。它将文本、图像、音频等数据通过机器学习技术转换为高维数值向量,这些向量能够捕捉数据的语义特征。与传统数据库不同,向量数据库支持高效的相似性搜索、聚类和分类操作,广泛应用于推荐系统、搜索引擎等领域。例如,照片可以转换为向量后按视觉特征检索,文本数据也能通过语义匹配实现精准搜索,克服
向量数据库简介
什么是向量数据库
首先,我们必须注意到矢量数据库并不是新鲜事物。事实上,向量数据库已经存在了相当长一段时间。甚至在它最近变得广泛流行之前,我们几乎每天都在间接地与它们互动。例如,推荐系统和搜索引擎等应用程序。简单来说,向量数据库以向量嵌入(Vector Embedding)的形式存储非结构化数据(文本、图像、音频、视频等)。
向量嵌入(Vector Embedding)
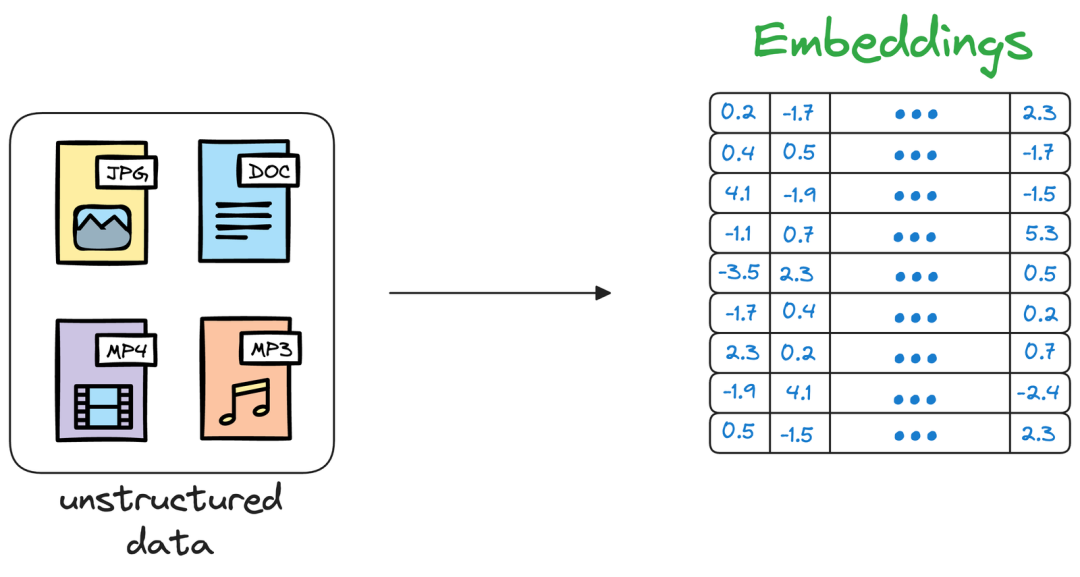
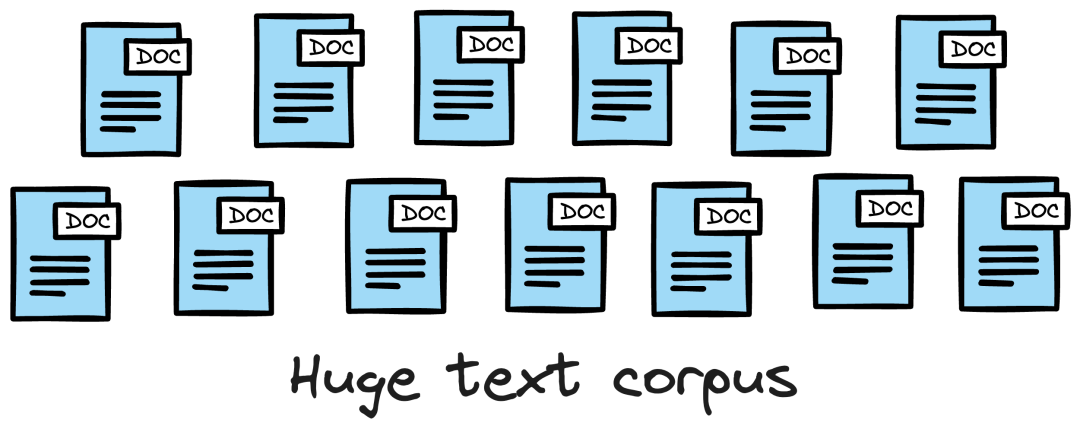
每个数据点,无论是单词、文档、图像还是任何其他实体,都使用 ML 技术(我们将在后面看到)转换为数字向量。这个数值向量被称为**嵌入(Embedding),**模型经过训练,这些向量可以捕捉底层数据的基本特征和特性。例如下图所示,考虑词嵌入,我们可能会发现在嵌入空间中,水果的嵌入彼此靠近,哪些城市形成另一个集群,等等。这表明嵌入可以学习它们所代表的实体的语义特征(前提是它们经过适当的训练)。一旦存储在矢量数据库中,我们就可以检索与我们希望在非结构化数据上运行的查询类似的原始对象。
为什么需要需要向量数据库
对非结构化数据进行编码使我们能够运行许多复杂的操作,例如相似性搜索、聚类和分类,而这些操作对于传统数据库来说很困难。举例来说,当电子商务网站提供类似商品的推荐或根据输入查询搜索产品时,我们(在大多数情况下)在后台与矢量数据库进行交互。
我们以两个举例的例子进行说明。
示例 1
假设我们收集了多年来在各个假期拍摄的照片。每张照片都捕捉了不同的场景,例如海滩、山脉、城市和森林。

现在,我们希望以一种更容易快速找到相似照片的方式来组织这些照片。传统上,我们可能会按照拍摄日期或拍摄地点来整理它们。

然而,我们可以采取更复杂的方法,将它们编码为向量。更具体地说,我们可以将每张照片表示为一组捕捉图像本质的数字向量,而不是仅仅依靠日期或地点。假设我们使用一种算法,根据照片的色彩组成、突出的形状、纹理、人物等将每张照片转换为矢量。现在,每张照片都表示为多维空间中的一个点,其中维度对应于图像中不同的视觉特征和元素。现在,当我们想要根据输入的文本查询找到相似的照片时,我们将文本查询编码为向量并将其与图像向量进行比较。与查询匹配的照片预计会在这个多维空间中具有靠近的向量。假设我们希望找到山脉的图像。在这种情况下,我们可以通过在矢量数据库中查询接近代表输入查询的矢量的图像来快速找到这样的照片。
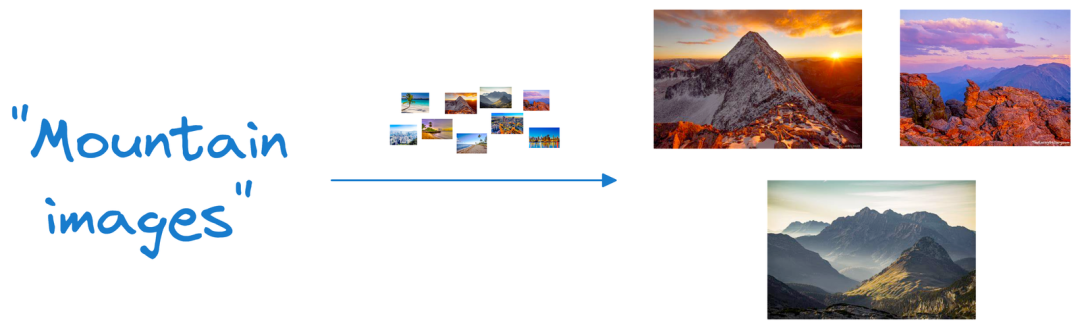
示例 2
在这个例子中,考虑一个全文本非结构化数据,比如数千篇新闻文章,我们希望从这些数据中寻找答案。
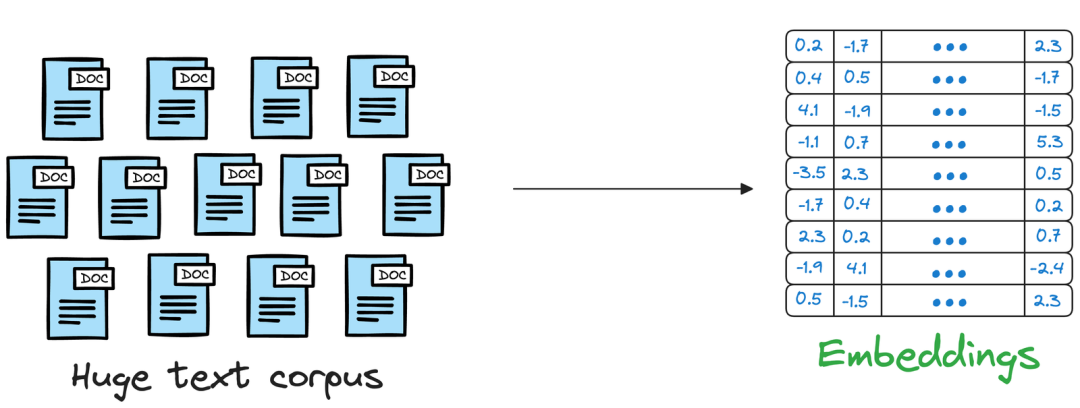
传统的搜索方法依赖于精确的关键字搜索,这完全是一种蛮力方法,并没有考虑文本数据固有的复杂性。换句话说,语言具有极其微妙的差别,每种语言都提供了各种方式来表达相同的想法或提出相同的问题。例如,一个简单的询问“今天天气怎么样?”可以用多种方式表达,例如“今天天气怎么样?”,“外面晴朗吗?”或“现在的天气状况如何?”。这种语言多样性使得传统的基于关键词的搜索方法不够充分。您可能已经猜到了,在这种情况下将这些数据表示为向量也非常有用。我们可以先将文本数据表示在高维向量空间中,然后将其存储在向量数据库中,而不是仅仅依靠关键字并进行强力搜索。当用户提出查询时,矢量数据库可以将查询的矢量表示与文本数据的矢量表示进行比较,即使它们的措辞并不完全相同。
最近这几年,经济形式下行,IT行业面临经济周期波动与AI产业结构调整的双重压力,很多人都迫于无奈,要么被裁,要么被降薪,苦不堪言。但我想说的是一个行业下行那必然会有上行行业,目前AI大模型的趋势就很不错,大家应该也经常听说大模型,也知道这是趋势,但苦于没有入门的契机,现在他来了,我在本平台找到了一个非常适合新手学习大模型的资源。大家想学习和了解大模型的,可以**点击这里前往查看**

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 25
25 0
0- 0



 已为社区贡献43条内容
已为社区贡献43条内容

所有评论(0)