SQL server AlwaysOn故障检测与转移设计
WHERE group_id = (SELECT group_id FROM sys.availability_groups WHERE name = 'AG名');ALTER AVAILABILITY GROUP [AG名] FORCE_FAILOVER_ALLOW_DATA_LOSS;-- 加ALLOW_DATA_LOSS参数,允许数据丢失。(二)故障转移模式:三种场景的 “全流程拆解”。
(一)故障检测:WSFC 驱动的 “三层监控体系”
1. 底层基础:WSFC 群集的心跳与健康检测
- 心跳检测机制(节点存活判断)
- 检测载体:通过 “群集心跳网络”(建议独立私有网卡,带宽≥1Gbps)传输心跳包
- 核心参数:
- 心跳频率:默认 1 秒 / 次(可通过群集属性修改CrossSubnetDelay/SameSubnetDelay,跨子网建议设为 2 秒)
- 故障判定阈值:默认连续 5 次未收到心跳(CrossSubnetThreshold/SameSubnetThreshold),判定节点故障
- 异常处理:心跳中断时,先尝试重连(默认重试 3 次),重连失败则标记节点为 “脱机”
- 群集资源健康检测(AG 组件状态)
- 检测对象:AG 副本、侦听器、虚拟 IP(VIP)等群集资源
- 检测逻辑:
- WSFC 通过 “AG 资源 DLL”(sqlag.dll)定期调用 SQL Server 接口,查询副本状态(如sys.dm_hadr_availability_replica_states)
- 若副本状态连续 3 次(默认)为NOT SYNCHRONIZING/DISCONNECTED,或侦听器 VIP 无法 ping 通,标记资源 “不健康”
- 关键阈值:HealthCheckTimeout(默认 30 秒),超过该时间未获取副本状态,判定资源故障
2. 故障分类:明确 “该触发哪种处理”
|
故障类型 |
表现形式 |
检测主体 |
处理方向 |
|
节点故障 |
服务器断电 / 蓝屏 / 操作系统崩溃 |
WSFC 心跳检测 |
触发副本转移(需其他节点存活) |
|
副本故障 |
SQL Server 服务停止 / 实例崩溃 |
AG 资源检测 |
若节点存活,尝试重启副本;失败则转移 |
|
网络故障 |
主副本与辅助副本断连 / 心跳网络中断 |
心跳 + AG 检测 |
判定 “分区”,需仲裁机制决定哪侧保留 |
|
数据库故障 |
可用性数据库置疑 / 损坏 |
sys.dm_hadr_database_replica_states |
单个库故障不触发转移,需手动修复 |
3. 仲裁机制:故障时的 “决策核心”
- 核心作用:避免 “脑裂”(主副本与辅助副本分区后,两侧均认为自己是主副本),通过 “投票” 决定哪组节点保留 AG 控制权
- 投票逻辑:
- 总票数 = 节点数 + 外部投票源(如文件共享 / 共享磁盘)
- 需获得 “超过半数票数”(如 3 节点需≥2 票,2 节点 + 1 文件共享需≥2 票)才有权限控制 AG
- 动态仲裁适配:节点故障后自动减少总票数(如 3 节点故障 1 个,总票数从 3→2,剩余 2 节点仍满足多数),确保分区场景下仍能决策
(二)故障转移模式:三种场景的 “全流程拆解”
1. 自动故障转移:零人工干预的 “核心保障”
- 触发前提(必须同时满足):
- 主副本与辅助副本均配置AVAILABILITY_MODE = SYNCHRONOUS_COMMIT(同步模式)
- 辅助副本配置FAILOVER_MODE = AUTOMATIC(自动转移模式)
- 主副副本间SESSION_TIMEOUT(默认 10 秒)内未断连,且同步状态为SYNCHRONIZED
- WSFC 群集仲裁正常,无 “脑裂” 风险
- 全流程(约 5-30 秒):
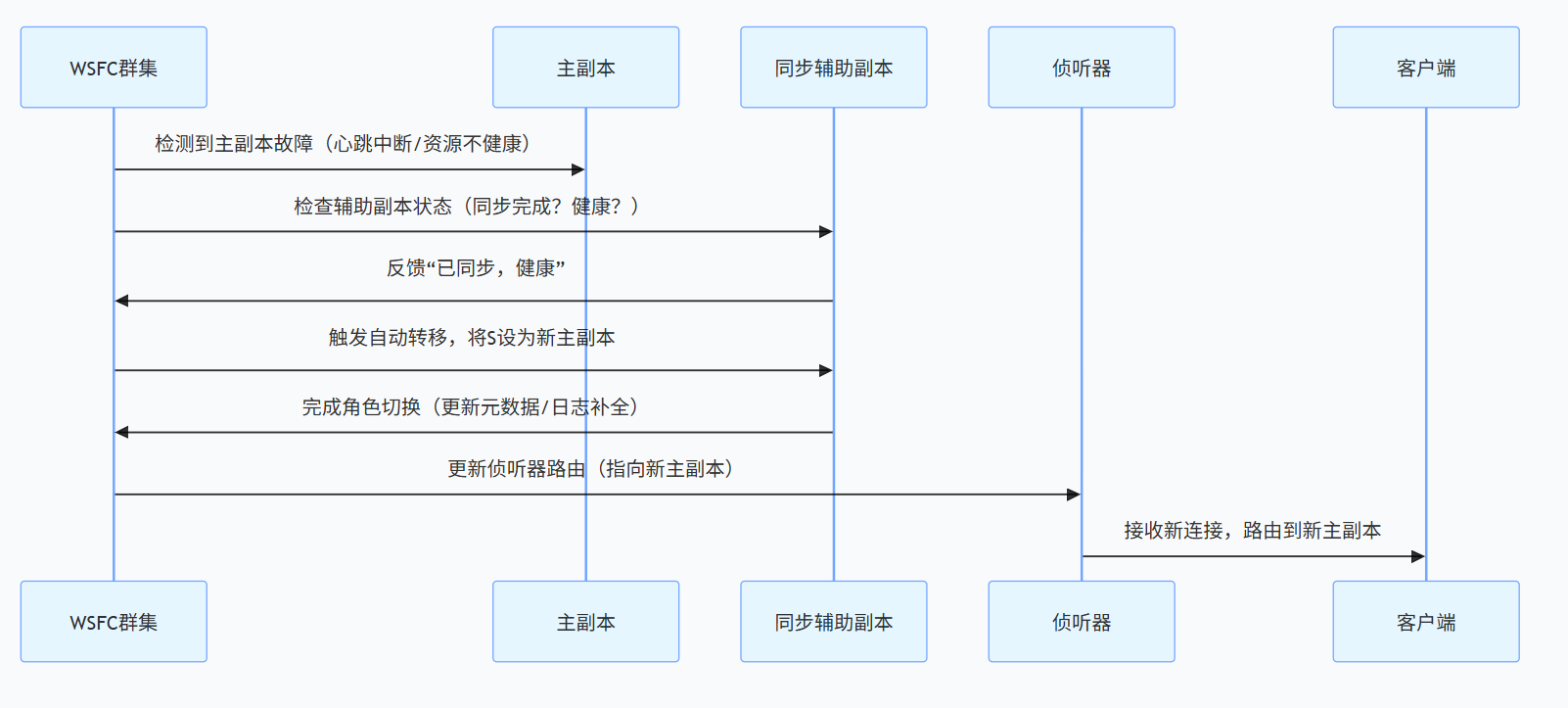
- 关键操作细节:
- 日志补全:新主副本(原辅助副本)会检查 “最后接收的 LSN”,若存在未应用的日志,先完成应用再对外提供服务
- 旧主副本恢复:修复后重新加入 AG,自动转为辅助副本,从新主副本同步缺失日志(需确保无数据分叉)
2. 计划手动转移:可控维护的 “安全操作”
- 适用场景:主节点硬件升级、SQL Server 版本更新、操作系统补丁安装等计划性停机
- 操作步骤(无数据丢失):
- 前置检查:
- 确认主副本与目标辅助副本为同步模式且状态SYNCHRONIZED:
SELECT replica_server_name, synchronization_state_desc
FROM sys.dm_hadr_availability_replica_states
WHERE group_id = (SELECT group_id FROM sys.availability_groups WHERE name = 'AG名');
- 确认 AG 无数据库处于SUSPENDED(暂停)状态
- 触发转移(主副本执行):
ALTER AVAILABILITY GROUP [AG名] FAILOVER; -- 仅同步模式支持
- 执行后,主副本自动降级为辅助副本,目标辅助副本升级为主副本
- 侦听器自动更新路由,无需手动修改
- 后置校验:
- 检查新主副本数据库状态:SELECT name, state_desc FROM sys.databases WHERE database_id IN (SELECT database_id FROM sys.dm_hadr_database_replica_states);
- 验证客户端连接:通过侦听器连接测试读写操作
3. 强制手动转移:应急场景的 “风险选项”
- 触发场景:主副本彻底故障(如服务器报废),且无可用同步辅助副本,需优先恢复业务(允许少量数据丢失)
- 操作步骤(需谨慎):
- 风险评估:
- 确认主副本无法恢复(如硬件损坏)
- 评估目标辅助副本(异步模式)的数据丢失量:
-- 辅助副本执行,计算未同步日志大小
SELECT redo_queue_size AS 待还原日志(KB)
FROM sys.dm_hadr_database_replica_states
WHERE database_id = DB_ID('库名') AND is_primary_replica = 0;
- 强制转移(目标辅助副本执行):
-- 加ALLOW_DATA_LOSS参数,允许数据丢失
ALTER AVAILABILITY GROUP [AG名] FORCE_FAILOVER_ALLOW_DATA_LOSS;
- 执行后,目标辅助副本升级为主副本,跳过未同步日志(标记为 “已丢失”)
- 数据修复(可选):
- 若原主副本有备份,可通过 “备份→还原” 补全丢失数据
- 修复后将原主副本作为新辅助副本加入 AG
- 风险规避:
- 仅在 “业务中断损失远大于数据丢失损失” 时使用(如电商秒杀场景)
- 执行前建议备份目标辅助副本日志,便于后续数据恢复
(三)转移后关键保障:确保业务稳定
1. 客户端连接自动恢复
- 侦听器路由更新:WSFC 在转移完成后,自动将侦听器的 VIP 与新主副本绑定(约 2-5 秒),客户端无需修改连接字符串
- 重连机制:客户端需配置 “连接重试逻辑”(如.NET 中设置ConnectRetryCount=3,ConnectRetryInterval=5),避免单次连接失败导致业务中断
2. 数据一致性校验
- 自动校验:新主副本启动后,自动检查所有可用性数据库的database_state_desc,确保处于ONLINE状态
- 手动校验(核心库必做):
- 对比关键表数据量(如订单表总行数):
-- 新主副本执行
SELECT COUNT(*) FROM dbo.Orders;
-- 与历史备份或其他辅助副本对比
- 检查事务日志连续性:DBCC SQLPERF(LOGSPACE),确保日志无损坏
3. 异常处理:转移失败的常见原因与解决
|
转移失败原因 |
现象 |
解决方法 |
|
仲裁丢失 |
WSFC 提示 “无足够投票” |
修复故障节点,或通过Start-ClusterNode -FixQuorum强制启动群集 |
|
副本未同步 |
自动转移时提示 “同步状态异常” |
主副本恢复后先同步数据,再重试转移;或改为强制转移 |
|
侦听器资源故障 |
转移完成但客户端无法连接 |
手动重启侦听器资源:Start-ClusterResource "AG侦听器名" |
|
数据库置疑 |
转移后数据库状态为SUSPECT |
修复置疑数据库(如DBCC CHECKDB),再重新加入 AG |

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)