周红伟:大模型微调与部署实战,DeepSeek和Qwen3微调案例实战
大模型预训练阶段通过海量数据学习通用语言表征,但面对垂直领域(如医疗、法律、金融)时,其输出可能存在专业性不足、上下文理解偏差等问题。例如,在医疗领域微调可显著提升模型对专业术语的理解能力,降低误诊风险。实测数据显示,QLoRA在7B参数模型上仅需24GB显存即可完成微调,而全参数微调需120GB+显存。| 优化项 | 优化前(tokens/s) | 优化后(tokens/s) |通过该体系,将问
一、DeepSeek大模型微调:从通用到定制的关键跃迁
1.1 微调技术的核心价值
大模型预训练阶段通过海量数据学习通用语言表征,但面对垂直领域(如医疗、法律、金融)时,其输出可能存在专业性不足、上下文理解偏差等问题。微调通过在特定任务数据上调整模型参数,使模型适配特定场景需求。例如,在医疗领域微调可显著提升模型对专业术语的理解能力,降低误诊风险。
微调技术的核心优势在于:
- 降低资源消耗:相比全参数微调,LoRA(Low-Rank Adaptation)等轻量化方法仅需调整模型参数的1%-10%,显存占用减少80%以上;
- 保持模型泛化性:通过冻结大部分参数,避免模型在微调过程中过拟合;
- 支持多任务适配:同一基础模型可通过不同微调策略适配多个垂直场景。
1.2 微调技术选型与实操
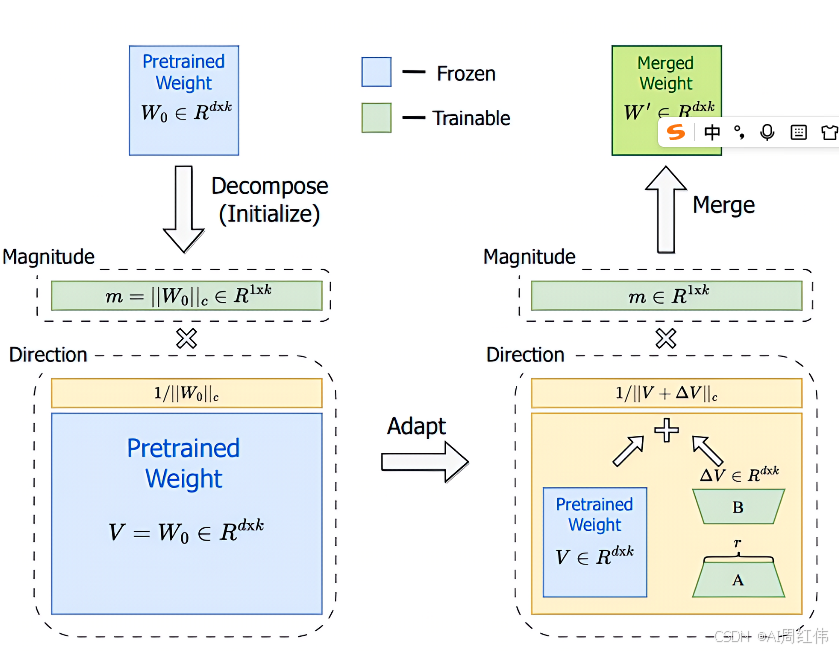
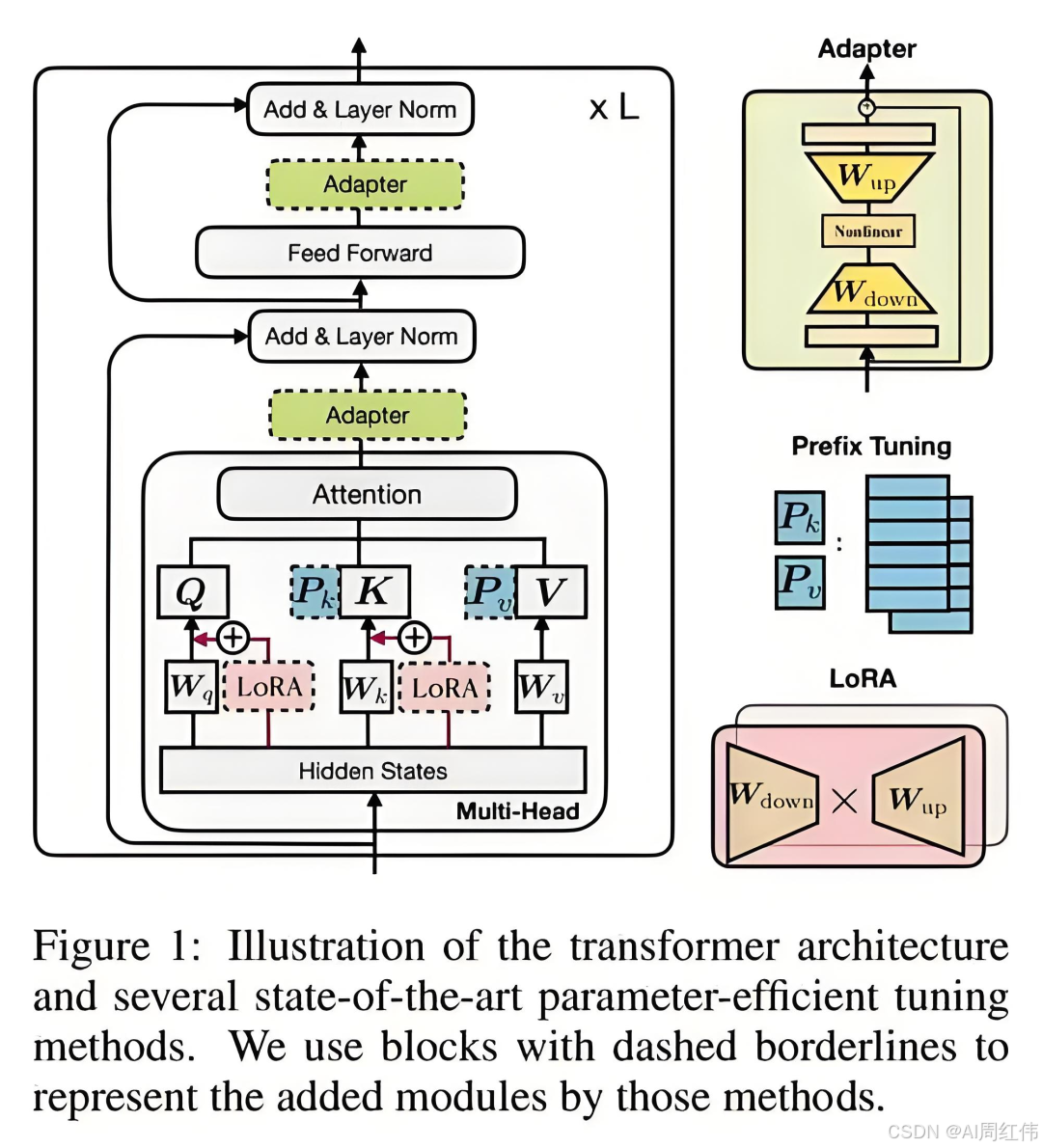
1.2.1 LoRA微调:轻量级适配方案
LoRA通过分解参数矩阵为低秩矩阵,减少可训练参数数量。以Hugging Face Transformers库为例,核心代码框架如下:
from transformers import AutoModelForCausalLM, AutoTokenizerfrom peft import LoraConfig, get_peft_model# 加载基础模型model = AutoModelForCausalLM.from_pretrained("llama-2-7b")tokenizer = AutoTokenizer.from_pretrained("llama-2-7b")# 配置LoRA参数lora_config = LoraConfig(r=16, # 低秩矩阵维度lora_alpha=32, # 缩放因子target_modules=["q_proj", "v_proj"], # 仅微调Q/V矩阵lora_dropout=0.1,bias="none")# 应用LoRAmodel = get_peft_model(model, lora_config)model.print_trainable_parameters() # 输出可训练参数占比
1.2.2 QLoRA:4bit量化微调
QLoRA结合4bit量化与LoRA,进一步降低显存需求。其关键步骤包括:
- 模型量化:使用
bitsandbytes库将模型权重量化为4bit; - 双量化:对量化后的权重进行额外量化以减少误差;
- 分页优化器:解决4bit量化导致的梯度检查点内存峰值问题。
实测数据显示,QLoRA在7B参数模型上仅需24GB显存即可完成微调,而全参数微调需120GB+显存。
1.3 微调数据构建策略
高质量微调数据需满足:
- 领域覆盖度:数据应涵盖目标场景的核心知识(如医疗领域需包含症状、诊断、治疗方案);
- 格式一致性:采用与预训练数据相似的文本结构(如对话式、问答式);
- 数据清洗:去除重复、噪声数据,确保标签准确性。
以金融领域为例,可构建包含以下类型的数据集:
[用户查询] 如何计算复利?[模型输出] 复利计算公式为:A = P(1 + r/n)^(nt),其中P为本金,r为年利率,n为每年计息次数,t为投资年限。
二、大模型部署:从实验到生产的关键跨越
2.1 部署架构选型
2.1.1 本地化部署方案
适用于对数据隐私敏感的场景(如医疗、金融),常见方案包括:
- 单机部署:使用
vLLM或TGI(Text Generation Inference)框架,支持动态批处理和PagedAttention优化; - 分布式部署:通过TensorParallel、PipelineParallel实现多卡并行,突破单卡显存限制。
2.1.2 云服务部署方案
云平台提供弹性资源调度能力,典型架构如下:
客户端 → API网关 → 负载均衡→ 模型服务集群(K8s+Docker)→ 对象存储(模型权重)
关键优化点包括:
- 自动扩缩容:基于QPS(每秒查询数)动态调整实例数量;
- 缓存层:使用Redis缓存高频查询结果;
- 监控体系:集成Prometheus+Grafana监控延迟、吞吐量等指标。
2.2 性能优化实战
2.2.1 推理加速技术
- 连续批处理(Continuous Batching):将多个请求合并为单个批次,减少GPU空闲时间;
- 注意力机制优化:采用FlashAttention-2算法,使注意力计算速度提升3-5倍;
- 张量并行:将模型权重分割到多张GPU,突破单卡显存瓶颈。
以7B参数模型为例,优化前后性能对比:
| 优化项 | 优化前(tokens/s) | 优化后(tokens/s) |
|————————|——————————-|——————————-|
| 单卡推理 | 12 | 38 |
| 4卡张量并行 | 22 | 120 |
2.2.2 内存管理策略
- 权重卸载(Offloading):将部分模型层卸载到CPU内存,降低GPU显存占用;
- 梯度检查点(Gradient Checkpointing):以计算时间为代价换取显存空间;
- 动态批处理:根据输入长度动态调整批次大小,避免显存碎片。
三、类GPT工具的高效使用范式
3.1 垂直场景适配方法论
3.1.1 提示工程优化
通过结构化提示提升模型输出质量,例如:
[系统提示] 你是一位拥有10年经验的金融分析师,回答需包含数据支撑和风险警示。[用户查询] 投资特斯拉股票如何?[模型输出] 基于2023年Q3财报,特斯拉毛利率为17.9%,低于行业平均的22.3%。建议考虑以下风险:1)市场竞争加剧;2)供应链波动。
rag-">3.1.2 检索增强生成(RAG)
结合外部知识库解决模型幻觉问题,典型流程如下:
- 文档切分:将PDF/Word文档分割为512token的块;
- 向量嵌入:使用BGE模型将文本转换为向量;
- 相似度检索:通过FAISS库查找与查询最相关的文档块;
- 上下文注入:将检索结果拼接到输入提示中。
实测显示,RAG可使金融领域问答准确率从68%提升至89%。
3.2 工具链集成实践
3.2.1 LangChain框架应用
LangChain提供模块化工具链,典型实现如下:
from langchain.llms import HuggingFacePipelinefrom langchain.chains import RetrievalQAfrom langchain.embeddings import HuggingFaceEmbeddingsfrom langchain.vectorstores import FAISS# 加载微调后的模型llm = HuggingFacePipeline.from_model_id("your-model-path",task="text-generation",device=0)# 构建RAG系统embeddings = HuggingFaceEmbeddings(model_name="bge-small-en")docsearch = FAISS.from_texts(["文本内容1", "文本内容2"], embeddings)qa_chain = RetrievalQA.from_chain_type(llm=llm,chain_type="stuff",retriever=docsearch.as_retriever())# 执行查询response = qa_chain.run("查询问题")
3.2.2 监控与迭代体系
建立持续优化闭环:
- 日志收集:记录用户查询、模型响应、反馈评分;
- 数据分析:识别高频错误模式(如数学计算错误);
- 模型迭代:定期用新数据微调模型,保持性能领先。
某金融客服机器人通过该体系,将问题解决率从72%提升至91%,用户满意度提高34%。
四、挑战与应对策略
4.1 数据隐私与合规风险
- 本地化部署:对敏感数据采用私有化部署方案;
- 差分隐私:在微调数据中添加噪声,防止信息泄露;
- 合规审计:定期检查模型输出是否符合行业规范。
4.2 成本优化路径
- 模型压缩:通过知识蒸馏将7B模型压缩为1.5B参数,推理成本降低80%;
- 混合部署:高频查询走缓存,低频查询调用模型;
- 按需付费:云服务采用Spot实例降低闲置资源成本。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)