彻底搞懂LLM应用架构!从Prompt到Multi-Agent,看这篇就够了!
自 ChatGPT 问世以来,业内对AI产生了极大的关注,所以有了各种探索,试图挖掘LLM的智能,将LLM落地到应用场景中。总得来说,当下LLM的探索经历了三个阶段
自 ChatGPT 问世以来,业内对AI产生了极大的关注,所以有了各种探索,试图挖掘LLM的智能,将LLM落地到应用场景中。总得来说,当下LLM的探索经历了三个阶段:
- 第一阶段是挖掘LLM智能,主要是prompt工程。通过设计不同的提示词去激活LLM的智能,在这个阶段的代表作是角色扮演提示词以及Function Call。
- 第二阶段是chain流程编排阶段:此阶段是为了增强LLM能力而提出的。主要原理是:通过编排固定的流程,将AI能力嵌入特殊任务处理的流程中,实现“+AI”。其中的代表是采用了文档检索增强生成(RAG)技术构建的聊天应用。
- 第三阶段是Agent阶段。它的重点是LLM自行进行规划,利用工具完成目标。
本文的重点将会是:
- prompt、chain和Agent的演进过程;
- Agent介绍;
- 简单讲讲如何从代码层面实现一个Agent。
通过上述流程,你可以完成LLM应用演进过程的了解,以及最后的Agent从诞生到落地的整个生命周期的一窥。
接下来,在详细介绍演进过程前,我们可以先了解一下LLM最流行的应用架构Agent的定义,然后,我们再从Agent的诞生中引申出来LLM的架构的演进过程。
01 Agent是什么?
在大语言模型领域中,Agent是指一种能够自主理解、规划决策、执行复杂任务的智能体。它具备感知、记忆、规划和使用工具的能力,能够在无人干预的情况下,根据环境信息自主决策和控制行为。
而在技术角度来看,Agent是一种增强大模型能力的技术方案路径。它使LLM能够在特定任务或领域中高智能、稳定、自主地进行学习、改进和完成目标。
在基本了解了Agent的概念后,我们进一步了解Agent的由来,理解它的出现解决了什么问题。
02 为什么会有Agent出现?
Agent是随着LLM应用研究的探索而发展起来的。它的出现是为了提高LLM在应用场景中的能力,最主要的体现是在于智能化以及自动化能力的提升。为了具体说明,目前我们可以依据自动化的程度,对LLM应用进行4个层级的划分:
- prompt阶段:人类手动补充相关上下文,书写提示词进行提问,来获取llm的回答;
- chain编排阶段:通过固定的流程编排,让LLM可以和多种工具组合起来,按流水线执行逻辑流程,从而处理特定的任务;
- Agent阶段:通过设定好提示词,准备好工具,由Agent自动化规划流程,完成目标。
- Multi-Agent阶段:Multi-Agent实际上算是Agent的一个子集,它用于处理单Agent工作量过重,导致容易陷入幻觉、死循环等问题;
大概了解Agent的自动化能力分层以后,我们再进一步的讲解,每一个阶段都做了什么,又有什么问题。
2.1 Prompt阶段
这个阶段是人类直接书写提示词提问,获取回答。这是LLM应用最原始的用法,此时prompt是一个“编程语言”,大家都在想办法学会这门语言,从而激活LLM更强的智能。这个阶段的代表作是角色扮演类提示词。但是,这个阶段只是停留在了更好地对话的阶段,最终的效果是沉淀了chat类应用的“说明书”。
简单来说,这一阶段可以用以下6点概括:
- 目标:挖掘LLM的智能;
- 原理:提示词可以引导LLM激活特定参数(概率分布),使其在特定领域上的智能可以被更充分的发挥出来。
- 核心流程:人 --> 提示词 (每一个任务得写一份提示词)
- 优点:让LLM充分发挥自身在训练阶段获取的知识;
- 缺点:仅仅停留在更好地和LLM对话的领域中,无法和其他领域结合;
- 应用:各种提示词角色应用市场,以及开源项目,如:GPTs(https://github.com/linexjlin/GPTs)
Prompt阶段让人们意识到了LLM的智能,但是并没有找到应用的场景,直到有人发现了它可以输出规范的json格式。于是,大家开始探索工具和LLM的结合,也就来到了下一阶段Chain编排阶段。
2.2 Chain编排阶段
chain阶段主要是通过固定的流程编排,让LLM可以和多种工具组合起来,按流水线串联执行以处理特定的问题。朴素RAG是典型的例子:它先把用户的问题去向量数据库检索相关的背景,而后一起嵌入到提示词中。此时,不再需要人类手动去拼接问题的背景到提示词了,可以交给流水线去自动化处理。
但是,chain模式下LLM应用基本是固定的流程编排。这样固定的流程有其优势:可以保持程序的稳定性。但是,这也限制了LLM发挥智能的舞台。在这种模型下,LLM能解决的问题都需要穷举出编排流程。下面有两个例子可以说明问题:
-
朴素RAG检索过程中,如果检索回来的答案不佳,此时,LLM本可以思考如何更好的检索出相关文档,如:尝试HYDE等策略再次去进行检索。但是固有的chain编排不走回头路,不管检索好坏,都会去给LLM进行提问。这种固定的程序限制了LLM发挥智能的机会。
-
日志分析chain例子:假设要实现一个日志分析的工作流,由于程序输出的日志可能有很多的编码字符串,是需要解码后LLM才能理解的。所以,可能就产生了这样的chain编排,如下所示:
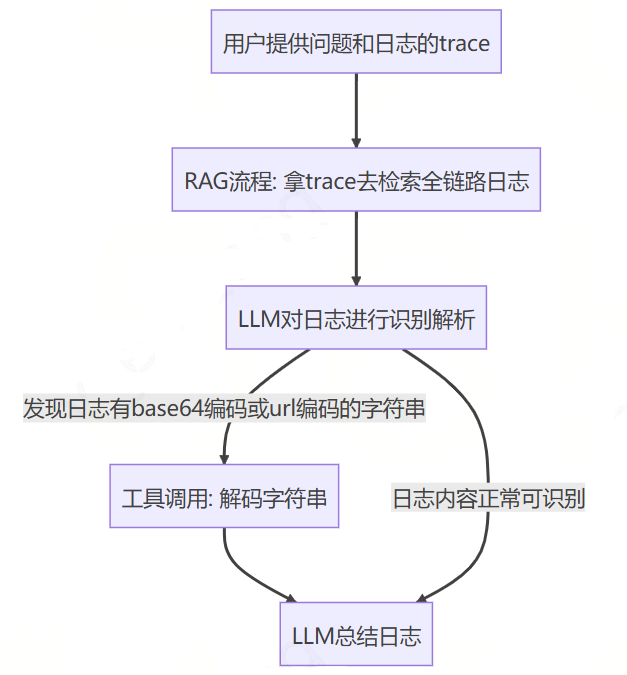
这样的流程看似解决了日志编码问题,可以让LLM对日志进行分析、定位错误。但是,实际线上日志存在字符串被编码过2次的情况,如:前端传入特定字符串的时候会先进行url编码,后台再进行base64编码,最后后台打印出日志。此时,按照上述的chain进行逻辑处理就会发现:只进行一次解码后的字符串并没有达到我们的目标——将需要解码的日志解码为正常的内容。所以,我们又得去修改chain的流程图,兼容这种情况。但是,其实LLM本身就可以调用两种类型的解码工具,理想的情况应该是它自己识别出字符串需要2次解码,然后自行组合工具去完成解码,而不是需要人类去调整流程图。
通过上述的例子,想必你已经看出简单的DAG模式下,chain存在的缺点是:固定的流程编排限制了LLM的能力发挥。
chain阶段总结
总的来说,我们可以将chain阶段概括为以下6个特点:
-
目标:使得LLM可以和工具相结合,拥有“手”和“脚”,不再仅仅是对话模型,而是可以真正做出“行动”,完成任务;
-
原理:通过编排固定的LLM和工具的交互流程,从而使LLM在特定任务上实现一定程度的自动化;
-
核心流程:人 --> 流程编排 (每一个不同流程的任务得写一个新的流程图处理)
-
优点:LLM能力的实际落地:通过流程编排,使得LLM和工具的结合,让LLM拥有了手和脚,不再只是一个对话模型。
-
提效:当前的流程编排过程,基本都可以做成一个可视化界面。通过可视化界面对流程进行编排,大幅提高了开发特定任务流程的效率;
-
稳定性:流程的编排过程中,由于明确知道LLM下一步会做什么,所以可以做很多兜底的策略,去保证系统的稳定性;
-
缺点:固定的流程编排限制了LLM的智能发挥,让他缺少泛化性,一些本可以自己解决的问题,最后没有处理。这一阶段其实还是思维固化在了“编程”中,认为程序一定是一步一步的,每一步都清晰知道会发生什么的。对于这一阶段的LLM应用方式,我们也称其为“+AI”,而不是“AI+”,因为逻辑处理的核心能力还是在编程里。
-
应用: langchain、langIndex等框架;dify、coze以及我们混元一站式的可视化流程编排平台;
综上所述,chain模式虽然限制了LLM的智能,但是其固定编排带来的稳定性,在短期看应该依然是发展可期的。而可视化编排应该是会继续朝着pipeline、低代码平台方向发展,提效永远是一个值得研究的方向。不过预估未来,当前chain模式中对LLM仅仅是一次对话的限制应该会被抛除,而会把Agent能力接入进来。目前Langchain也已经向着LangGraph进行发展了。
2.3 Agent阶段
Agent阶段主要目的是充分发挥机器学习模型(如LLM)的规划能力和工具调用能力,使其能够自行思考并设计出路线来完成目标。
在这个阶段,代表性的开源项目是AutoGPT。它设计的执行器+规划器编程范式,使LLM能够持续思考、行动,直到达成目标。在这个阶段,我们不再需要设计固定的流程。只需设定目标并提供工具,AI就能自行思考、规划并调用工具来完成目标。相比于Chain阶段对LLM的应用,这样的方式可以让LLM处理工具组合能解决的几乎任何问题,理论上是可以达到真正人类的水平。到了这个阶段,“编程”的固有模式也已经被剔除了,应用也从“xx程序+AI”变成了“AI+xx工具”,真正进入了“AI+”的阶段。
不过,尽管Agent模式充分发挥了LLM的能力,但它也存在一些缺点。例如,AutoGPT中,一份提示词和一个LLM需要完成感知、记忆、规划和使用工具的所有工作,这无疑增加了模型的负担。程序很容易陷入死循环,导致无法在生产环境真正落地。
agent阶段总结
所以,总的来说,我们可以从6个角度看待Agent阶段:
- 目标:Agent模式的确定,是充分发挥了LLM的规划能力和工具调用能力,它可以多轮次的思考、利用工具,最后达成目标;
- 原理:通过“执行器+规划器”以及“ReAct”的提示词思路,使LLM的一步步思考,每一个想法都可以及时被执行器执行,并且再携带到提示词中,给LLM感知到。这样的设计使LLM拥有了持续思考、观察环境,独立完成任务的能力。
- 核心流程:人 --> 工具 (每一个新能力的出现,得写一个新工具)
- 优点:只要人类给LLM准备好工具,并且构造好“解释器-执行器”架构,LLM理论上就可以解决工具组合能解决的所有问题,不再需要人类对特定任务进行流程编排。
- 缺点:AutoGPT也已经体现出来了,一份提示词和一个LLM需要完成感知、记忆、规划和使用工具的所有工作,无疑是对智能要求依赖太重了,程序非常容易陷入死循环。因此难以在实际生产环境中落地。
- 应用:AutoGPT、AgentGPT、Jarvis、babyAGI等。
2.4 Multi-Agent阶段
终于来到最后一个阶段了——Multi-Agent阶段。Multi-Agent阶段其实是Agent阶段的一个子集,所以不算单独的一个LLM应用的阶段,只是自动化程度的一个演进。
早在1995年,就有类似《群体智能》等书有研究粒子群优化算法。算法的核心理论可以表述为:群体智能大于个人。在上面Prompt阶段就已经表明,一份特定的提示词可以有效激活LLM特定能力的智能。所以,我们采用专业的事情给专业的人做的原则,将单一agent分为多个不同领域的专家agent,它们之间互相合作,从而提高Agent的稳定性和智能。这就是现在的Multi-Agent了。
总得来说,我们可以从以下6个方面了解Multi-Agent:
-
目标:提高Agent的智能程度、稳定性
-
原理:让专业的人完成专业的事情:每一个agent只关注特定任务,只使用特定工具,只关心特定信息,从而降低单agent的智能压力。
-
数据流管道:agents之间如何共享数据将是multi-agent的关键,此时,我们可以结合集群通信原理:单播、广播和组播;或者结合集群网络的拓扑结构:星型、总线和环型等;又或者结合设计模式中的发布订阅模式等。将集群内各种设计方案结合Agent都能够玩出各种花样来,使智能体集群效果不一。
-
核心流程:人 --> agent (每一个新领域的出现,需要新增一个Agent)
-
优点:Agent之间互相思考,发挥群体智能效应,能有效提高智能程度;
-
缺点:多轮的思考,信息的交互,编程实现起来相对复杂,对LLM的响应速度要求高;
-
应用:metaGPT:模拟一家公司,协作完成任务;smallville:西部世界,模拟社交场景;
chatDev:自动化程序员;宝可梦自动化游
2.5 小结
通过上面的介绍,相信你已经对于LLM应用中对自动化能力探索的四个发展阶段:Prompt阶段,Chain编排阶段,Agent阶段和Multi-Agent阶段有所了解了。 概括来说就是:
- Prompt阶段是最初级的阶段,人类直接书写提示词提问,获取LLM的回答。这个阶段主要是激活和挖掘LLM的智能,但只停留在对话的阶段。
- Chain编排阶段是通过固定的流程编排,让LLM可以和多种工具组合起来,按流水线执行逻辑流程,从而处理特定的任务。这个阶段的优点是稳定性和提效,但缺点是固定的流程编排限制了LLM的能力发挥。
- Agent阶段是通过设定好提示词,准备好工具,由Agent自动化规划流程,完成目标。这个阶段的优点是LLM能够自行思考、规划并调用工具来完成目标,但缺点是模型的负担过重,容易陷入死循环。
- Multi-Agent阶段是将单一Agent分为多个不同领域的专家Agent,它们之间互相合作,从而提高Agent的稳定性和智能。这个阶段的优点是能有效提高智能程度,但缺点是多轮的思考,信息的交互,编程实现起来相对复杂,对LLM的响应速度要求高。
总的来说,Agent的出现和发展都是为了提高LLM在应用场景中的能力,包括智能化和自动化能力的提升。了解了Agent的原理以后,接下来我们尝试实现一个Agent吧。
03 Agent要怎么实现?
当前已经有很多的python框架介绍怎么实现一个multi-agent系统了。如:agents、metaGPT等。由于笔者主要是用golang开发,下面用golang演示一下,如何直接手搓一个简单的Agent。
3.1 实现单Agent
实现一个单Agent,主要是要实现一个“规划器+执行器”的结构。采用ReAct的提示词方法,让LLM一步步思考策略,每一步的思考都会被执行器去执行,从实现和环境的交互。具体来说就是
- 提示词约定,让LLM给出每一步的方案,并且携带特殊的格式;
- 执行器解析LLM的方案,因为有特殊的格式要求,所以程序可以理解LLM想调用什么工具;
- 执行器和规划器之间循环交互,直到获取到最终答案,或者最大循环次数到达;
具体实现,大家可以了解langchain-go的实现。下面是作者自己手搓的一个演示代码,作者主要是go语言开发,所以用go写的例子,仅供大家参考:
// BaseAgent 基础agent,设定人设和可以调用的工具,它将会进行思考,解决目标问题
type BaseAgent struct {
// LLM思考和行动的最大轮次
maxIterateTimes int
// 大语言模型
llm *proxy.LLM
// 人设提示词
rolePrompt string
// Tools 是代理可以使用的工具列表。
Tools []Tool
// 思考步骤
steps []AgentStep
}
// NewBaseAgent 单agent构造器
func NewBaseAgent(rolePrompt string, tools []Tool, maxIterateTimes int, llm *proxy.LLM) *BaseAgent {
if rolePrompt == ""{
rolePrompt = planner
}
if maxIterateTimes == 0{
maxIterateTimes = len(tools) + 1 //每个工具都调用过一次后,还没有得出答案,则LLM进行一轮总结
}
return &BaseAgent{maxIterateTimes: maxIterateTimes, llm: llm, rolePrompt: rolePrompt, Tools: tools}
}
// think 规划器:分析问题的情况,规划工具调用,此过程将会和执行器进行循环处理,直到规划器能规划出最终结果
func (agent *BaseAgent)think(ctx context.Context, query string) {
//1. 获取数据
toolList := agent.Tools
llm := agent.llm
//2. 循环推理
answer := ""
count := 0
for !(answer != "" || agent.maxIterateTimes < count) {
count++ //计数+1
//2.1 生成提示词
fullInputs := make(map[string]string)
fullInputs["agent_scratchpad"] = agent.constructScratchPad() //获取历史记录
fullInputs["role_setting"] = agent.rolePrompt //角色设定
fullInputs["query"] = query //用户提问
plannerLLM := PromptTemplate{
Template: planner, //角色完整提示词
InputVariables: []string{"query", "agent_scratchpad","role_setting"},
PartialVariables: map[string]any{
"tool_names": toolNames(toolList),
"tool_descriptions": toolDescriptions(toolList),
"tool_name": toolList[0].Name(),
},
}
prompt, err := plannerLLM.Format(fullInputs)
if err != nil {
log.ErrorContextf(ctx, "plannerLLM.Format err: %v", err)
return
}
//3. 执行推理
var msgs []*hunyuan.ChatMsg
msgs = append(msgs, &hunyuan.ChatMsg{Role: ChatMessageTypeSystem,
Content: fmt.Sprintf("%s。注意:思考问题的时候,需要得出解决问题的下一步行动规划或者最终答案," +
"并且推理下一步的行动即可,不需要连续推理多步。", agent.rolePrompt)})
msgs = append(msgs, &hunyuan.ChatMsg{Role: ChatMessageTypeUser, Content: prompt})
resp, err := llm.GenerateContent(context.Background(), msgs)
if err != nil {
log.ErrorContextf(ctx, "plannerHandler:llm.GenerateContent err: %v", err)
return
}
choice1 := resp.Choices[0]
output := choice1.GetMessage().GetContent()
log.InfoContextf(ctx, "规划器ai回复: \n%s", output)
//4. 处理LLM的决策,判断是否要执行动作
outputSplits := strings.Split(output, "尝试结论:")
output = outputSplits[0]
if strings.Contains(output, _finalAnswerAction2) {
splits := strings.Split(output, _finalAnswerAction2)
answer = splits[len(splits)-1]
break
} else {
//判断ai规划方向为调用工具
r := regexp.MustCompile(`(?s)行动:\s*(.+)\s*行动输入:\s*(.+)`)
matches := r.FindStringSubmatch(output)
if len(matches) == 0 {
log.InfoContextf(ctx, "解析Action失败!")
//当前执行器一次执行失败,会移除这段“记忆”,进行重试。
//也可以采用填充反思提示词,让LLM思考错在哪儿,帮助解决问题。
continue
}
//校验工具调用的json是否正确
finalInput, ok := checkJson(matches[2])
if !ok {
continue
}
//工具名称的处理,将返回值和所有工具取交集;
toolName := findTool(ctx, toolList, matches[1])
action := AgentAction{
Tool: strings.TrimSpace(toolName),
ToolInput: strings.TrimSpace(finalInput),
Log: "\n" + output,
}
agent.doAction(ctx, action) //调用执行器,获取“环境”的信息
}
}
}
// doAction 执行器:执行规划器的任务
func (agent *BaseAgent)doAction(ctx context.Context, action AgentAction) {
var nameToTool map[string]Tool
observation := ""
//1. 获取工具
tool, ok := nameToTool[strings.ToUpper(action.Tool)]
if !ok {
observation = fmt.Sprintf("%s 是一个无效的工具,请使用其他工具!", action.Tool)
agent.steps = append(agent.steps, AgentStep{
Action: action,
Observation: observation,
})
return
}
//2. 调用工具
observation, err := tool.Call(ctx, action.ToolInput)
if err != nil {
observation = fmt.Sprintf("%s 执行失败!请检查原因:err = %v", action.Tool, err)
agent.steps = append(agent.steps, AgentStep{
Action: action,
Observation: observation,
})
return
}
log.InfoContextf(ctx, "工具执行结果:\n %s", observation)
agent.steps = append(agent.steps, AgentStep{
Action: action,
Observation: observation,
})
return
}
// constructScratchPad 构造历史记录,将每一步的环境观察结果转化为LLM易于理解的格式
func (agent *BaseAgent) constructScratchPad() string {
var scratchPad string
steps := agent.steps
if len(steps) > 0 {
for i, step := range steps {
scratchPad += fmt.Sprintf("%d. 问题解答尝试:\n", i+1)
scratchPad += step.Action.Log
if strings.HasSuffix(scratchPad, "\n") {
scratchPad += "\n尝试结论:" + step.Observation
} else {
scratchPad += "\n\n尝试结论:" + step.Observation
}
}
if !strings.HasSuffix(scratchPad, "\n") {
scratchPad += "\n"
}
} else {
scratchPad = "该问题暂时没有参考资料!请你自己尝试解答吧。"
}
return scratchPad
}
提示词可以参考下面的关键部分:
你是一个善于使用工具解答问题的专家。
## 工具列表:
下面是你可以使用的工具:
---
{{.tool_descriptions}}
---
## 指南
当你面对问题的时候,请一步步思考:
1. 它是否已经可以从"已知的尝试"中得出最终答案?
2. 如果不能,下一步行动应该使用什么工具解答问题?
3. 如果工具都无法解决问题,则也给出最终结论。
## 要求
1. 经过思考以后,如果你觉得应该采取行动,请按下面格式给出你的行动方案:
---
行动:参考工具列表的说明,选择工具去帮你解决问题。注意!此处直接填写工具名称即可,工具必须是 [ {{.tool_names}} ] 之一,如:{{.tool_name}}。
行动输入:工具的输入,请按工具规范填写。
---
2. 如果你觉得已经可以得出问题的答案了,请按格式给出你对问题的最终答案:
---
最终答案:你总结的用户提问的最终答案
---
## 用户提问
---
{{.query}}
---
## 已知的尝试
下面是一些已知的尝试,可以参考它们,进行决策:
---
{{.agent_scratchpad}}
---
注意:使用工具的时候,请不要用上面已经尝试过的工具,可以直接参考工具的"尝试结论"。
接下来,请你按照"指南"一步步思考,给出你的答案:
上面是简单演示了一个Agent的实现思路。其实就是利用ReAct提示词去让LLM做选择:“使用工具”或“得出结论”。然后LLM的思考是一步步返回的,每一步思考逻辑返回以后,由程序去解析、执行和反馈给LLM。经过上述LLM和程序的交互,就可以实现LLM调用工具的能力,也就是所谓的Agent。
代码仅供参考,不同模型和提示词会有不同效果,大家可以自行调整提示词以获取更好的效果。
3.2 实现Agent通信,完成Multi-Agent
实现了单agent之后,我们再简单了解一下如何实现一个Multi-Agent。
3.2.1 设计范式
我们先具体讲一下multi-agent的应用设计范式。整体设计架构图(图源自网络)如下:
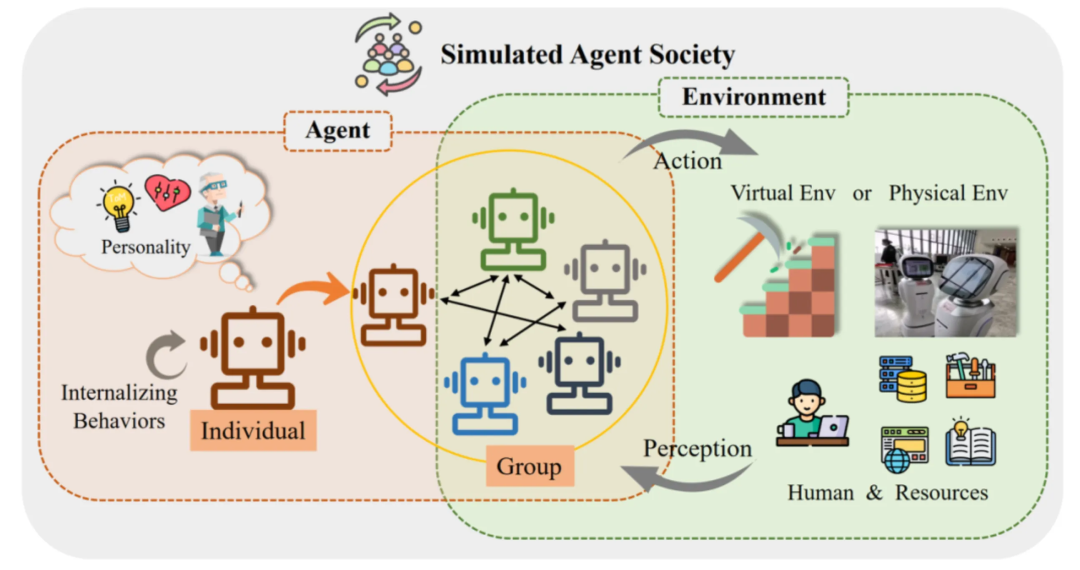
- 左侧部分:是单agent,代理表现出多种内化行为,例如计划、推理和反思。此外,代理还显现出内在的人格特征,涵盖认知、情感和性格三个方面。
- 中间部分:是多agent,单个代理可以与其他代理个体组成群体,共同展现出合作等群体行为,例如协同合作等。
- 右侧部分:是外部环境交互,主要通过开发提供的工具,为agent提供路径,去感知外界反馈。环境的形式可以是虚拟的沙盒环境,也可以是真实的物理世界。环境中的要素包括了人类参与者和各类可用资源。对于单个代理而言,其他代理也属于环境的一部分。
- 整体互动:代理们通过感知外界环境、采取行动,积极参与整个交互过程。
而实现multi-agent,中间部分的agent交互是核心。当前multi-agent主要有两种交互形式:合作型互动、对抗型互动。
- 合作型互动
作为实际应用中部署最为广泛的类型,合作型的代理系统可以有效提高任务效率、共同改进决策。具体来说,根据合作形式的不同,业内又将合作型互动细分为无序合作与有序合作。
-
当所有代理自由地表达自己的观点、看法,以一种没有顺序的方式进行合作时,称为无序合作。这种方式适合于头脑风暴类型的问题处理;
-
当所有代理遵循一定的规则,例如以流水线的形式逐一发表自己的观点时,整个合作过程井然有序,称为有序合作。这种方式适合于固定流程的任务,如基于Agent的RAG场景,前面举例子的日志格式解析场景等。
-
对抗型互动
智能代理以一种针锋相对的方式进行互动。通过竞争、谈判、辩论的形式,代理抛弃原先可能错误的信念,对自己的行为或者推理过程进行有意义的反思,最终带来整个系统响应质量的提升。这种例子有:self-RAG,它是在基础的智能文档场景下,加了一个反思的Agent,判断回答是否和用户问题有关,是否违法等。
了解了multi-agent的类型以后,我们自己实现multi-agent的关键就是实现一个controller模块,去控制agent之间的通信。通常controller模块会和agent有以下交互:
- controller更新当前环境的状态,选择下一时刻行动的agentA。
- agentA与环境交互,更新自身的memory信息。
- agentA开始思考:进行“规划——执行”循环推理,直到获取输出message。
- 将输出message更新到公共环境中。
- controller再次通信路由转发,选择下一时刻行动的agent。
而controller具体的通信路由转发方式也有两类:
- 基于LLM;
- 基于规则;
作者基于状态机实现了一个简单的基于规则类型的Agent。状态机模块(SOP思路)充当controller来确定agent之间交互的推进方式,管理状态的变换,并将相关状态信息变换记录到环境中,以便不同的agent进行各自任务的推进。不过目前代码尚且未完善,大家可以参考开源项目agents进行学习。
04 总结
当前的LLM应用从prompt一路发展到了Agent,也从“+AI”阶段摸索到了“AI+”阶段。能感知到这个过程里,LLM的应用确实越来越自动化、通用化。
而当前主要问题还是在于LLM的智能提升问题。在单Agent纵向提升有限时,Multi-Agent系列方案通过设置合理的算法架构,能通过水平扩展的方式提高智能,为我们打开了新的思路。当前Agent还在持续发展,相信后续会有越来越多的方案去进一步提升agent的智能和实用性,期待agent真正落地出能改变生活的应用,目前发展趋势来看,那一天感觉可能不会太远了。
如何学习大模型 AI ?
我国在AI大模型领域面临人才短缺,数量与质量均落后于发达国家。2023年,人才缺口已超百万,凸显培养不足。随着Al技术飞速发展,预计到2025年,这一缺口将急剧扩大至400万,严重制约我国Al产业的创新步伐。加强人才培养,优化教育体系,国际合作并进,是破解困局、推动AI发展的关键。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

2025最新大模型学习路线
明确的学习路线至关重要。它能指引新人起点、规划学习顺序、明确核心知识点。大模型领域涉及的知识点非常广泛,没有明确的学习路线可能会导致新人感到迷茫,不知道应该专注于哪些内容。
对于从来没有接触过AI大模型的同学,我帮大家准备了从零基础到精通学习成长路线图以及学习规划。可以说是最科学最系统的学习路线。

针对以上大模型的学习路线我们也整理了对应的学习视频教程,和配套的学习资料。
大模型经典PDF书籍
新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路!

配套大模型项目实战
所有视频教程所涉及的实战项目和项目源码等
博主介绍+AI项目案例集锦
MoPaaS专注于Al技术能力建设与应用场景开发,与智学优课联合孵化,培养适合未来发展需求的技术性人才和应用型领袖。


这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

为什么要学习大模型?
2025人工智能大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。

适合人群
- 在校学生:包括专科、本科、硕士和博士研究生。学生应具备扎实的编程基础和一定的数学基础,有志于深入AGI大模型行业,希望开展相关的研究和开发工作。
- IT行业从业人员:包括在职或失业者,涵盖开发、测试、运维、产品经理等职务。拥有一定的IT从业经验,至少1年以上的编程工作经验,对大模型技术感兴趣或有业务需求,希望通过课程提升自身在IT领域的竞争力。
- IT管理及技术研究领域人员:包括技术经理、技术负责人、CTO、架构师、研究员等角色。这些人员需要跟随技术发展趋势,主导技术创新,推动大模型技术在企业业务中的应用与改造。
- 传统AI从业人员:包括算法工程师、机器视觉工程师、深度学习工程师等。这些AI技术人才原先从事机器视觉、自然语言处理、推荐系统等领域工作,现需要快速补充大模型技术能力,获得大模型训练微调的实操技能,以适应新的技术发展趋势。

课程精彩瞬间
大模型核心原理与Prompt:掌握大语言模型的核心知识,了解行业应用与趋势;熟练Python编程,提升提示工程技能,为Al应用开发打下坚实基础。

RAG应用开发工程:掌握RAG应用开发全流程,理解前沿技术,提升商业化分析与优化能力,通过实战项目加深理解与应用。 
Agent应用架构进阶实践:掌握大模型Agent技术的核心原理与实践应用,能够独立完成Agent系统的设计与开发,提升多智能体协同与复杂任务处理的能力,为AI产品的创新与优化提供有力支持。

模型微调与私有化大模型:掌握大模型微调与私有化部署技能,提升模型优化与部署能力,为大模型项目落地打下坚实基础。 
顶尖师资,深耕AI大模型前沿技术
实战专家亲授,让你少走弯路
一对一学习规划,职业生涯指导
- 真实商业项目实训
- 大厂绿色直通车
人才库优秀学员参与真实商业项目实训
以商业交付标准作为学习标准,具备真实大模型项目实践操作经验可写入简历,支持项目背调 
大厂绿色直通车,冲击行业高薪岗位

文中涉及到的完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 7
7 0
0- 0



 已为社区贡献132条内容
已为社区贡献132条内容

所有评论(0)