360发布全球最强视觉语言对齐模型!榜单全面领先!
360刚刚发布FG-CLIP 2(双语细粒度视觉语言对齐模型)。几乎在所有数据集上,都取得全面领先。360度无死角。FG-CLIP 2的出现,让AI模型第一次在统一的框架内,同时看懂图像细节和理解中英双语。视觉-语言模型旨在让计算机像人一样,看懂图片并理解相关的文字描述。这是一个连接像素世界与语义世界的桥梁,也是实现高级人工智能的关键。过去的模型,尤其是开创性的CLIP,在理解图片大概是什么这件事
360刚刚发布FG-CLIP 2(双语细粒度视觉语言对齐模型)。

几乎在所有数据集上,都取得全面领先。360度无死角。
FG-CLIP 2的出现,让AI模型第一次在统一的框架内,同时看懂图像细节和理解中英双语。
视觉-语言模型旨在让计算机像人一样,看懂图片并理解相关的文字描述。
这是一个连接像素世界与语义世界的桥梁,也是实现高级人工智能的关键。
过去的模型,尤其是开创性的CLIP,在理解图片大概是什么这件事上做得很好,比如能认出图片里有一只猫和一张沙发。
但它看不清细节。
它分不清一只趴在红色沙发上的暹罗猫和一只坐在栗色沙发上的布偶猫之间的微妙差异。这种对物体属性、空间关系和精确语言表达的理解,被称为细粒度能力。
更棘手的是,这些模型大多以英语为母语,在中文世界里水土不服。
为了攻克这些挑战,360 AI Research团队推出了FG-CLIP 2(细粒度CLIP 2)。
它通过一套精心设计的训练策略和丰富的监督数据,让模型不仅能识别全局场景,更能洞察局部细节,并且在中英两个语言频道之间无缝切换。
团队还开创性地提出了一个新的中文多模态评测基准,倒逼和验证模型在中文环境下的真实细粒度理解能力。
在横跨8个任务、29个数据集的严苛测试中,FG-CLIP 2全面超越了现有模型,为双语细粒度视觉理解设定了新的标杆。
AI视觉理解的进化之路
2021年,OpenAI发布的CLIP模型,是视觉-语言对齐领域的一座里程碑。它的思路简单粗暴却极其有效:用4亿个从互联网上爬取的图片-文字对,进行对比学习。
模型包含一个图像编码器和一个文本编码器。训练的目标就是,让匹配的图片-文字对在特征空间里尽可能靠近,不匹配的则尽可能远离。
CLIP的强大之处在于其惊人的零样本能力。没经过任何特定任务的训练,它就能在ImageNet图像分类任务上达到76.2%的准确率。这让它成为后续无数多模态模型的基础架构。
但CLIP的弱点同样明显。它关注的是整体画面的语义,像是一个看画只看意境的鉴赏家,却忽略了画中的精妙笔触。
同时,它的语料库几乎全是英文,这为它的全球化应用画上了一个巨大的问号。
后来的Chinese-CLIP,学会了说中文。他们构建了大规模的中文图文对数据集,并训练了多个不同尺寸的模型。
Chinese-CLIP采用两阶段预训练,在多个中文数据集上取得了当时的最佳性能。
尽管如此,Chinese-CLIP和当时的许多中文模型一样,主要解决的是有没有的问题,其任务核心仍然是短标题级别的图像检索,对区域级、细节级的理解能力,依然力不从心。
细粒度理解的探索,当时还基本是英语世界的专属游戏。
今年5月360推出FG-CLIP,是细粒度理解领域的一次重大突破。
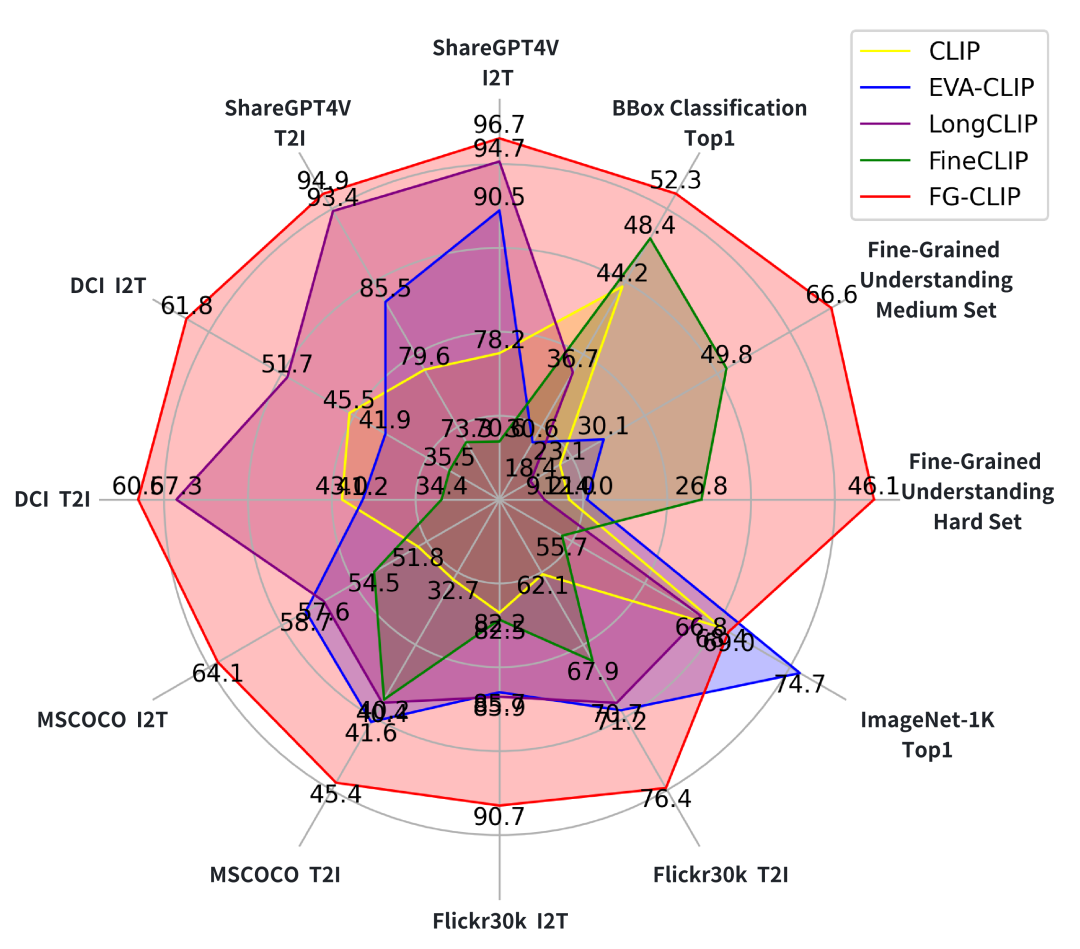
FG-CLIP做了三件大事:
-
用大型多模态模型生成了16亿对长描述-图片数据,让模型学习丰富的全局语义。
-
构建了一个包含4000万个区域边界框-精确描述的高质量数据集,直接告诉模型图片的哪个部分对应哪句话。
-
引入了1000万个细粒度硬负样本,也就是一些与正确描述极其相似但有细微错误的句子。这就像给学生做找不同练习,极大提升了模型的辨别力。
FG-CLIP在各项细粒度任务上远超前辈,证明了这条路的正确性。但它依然是一个英语模型,那道语言的鸿沟仍在。
在FG-CLIP 2问世前,谷歌的SigLIP 2和Meta的Meta CLIP 2也在多语言视觉对齐上取得了进展。
SigLIP 2整合了多种训练技术,并通过去偏见的数据策略,提升了多语言理解和公平性。
Meta CLIP 2则首次在全球网络规模的数据上从零开始训练多语言CLIP,并致力于解决多语言诅咒问题,即多语言模型在英语上的表现反而不如纯英语模型。
它们都极大地推动了多语言视觉模型的发展。但它们处理问题的方式,是将多语言和细粒度视作两个独立的课题来优化。
没有一个模型,能在一个统一的框架里,同时把这两件事都做好。这个空白,正是FG-CLIP 2要填补的。
FG-CLIP 2的架构,用分层学习实现从粗到精
FG-CLIP 2的整体架构建立在SigLIP 2的双编码器之上,但其核心思想在于一个巧妙的两阶段分层学习框架,像教一个孩子画画,先教他构图,再教他描绘细节。
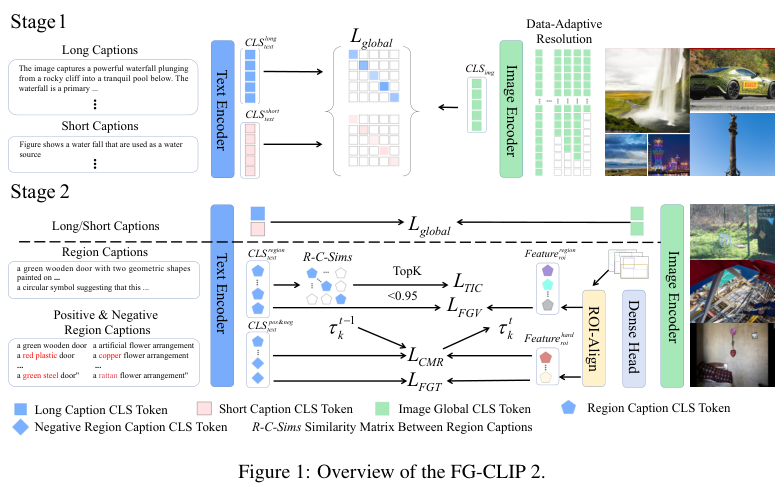
在第一阶段,模型的目标是建立强大的全局语义对齐。训练数据是海量的图片-文字对,但这里的文字很特别,每张图片都配有一段原始的短字幕和一段由大型多模态模型生成的长字幕。
短字幕通常简洁、真实,可能就是网络上的原始标签,充满了多样性。长字幕则像一篇看图说话,详细描述了图片的内容、上下文和氛围。
这种双字幕策略,让模型既能学习到简洁标签的核心语义,又能从详细描述中汲取丰富的上下文信息,为后续的细粒度学习打下坚实的基础。
进入第二阶段,模型开始学习精细活。除了继续优化全局对齐外,还引入了四个全新的学习目标,共同塑造模型的细粒度理解能力。
FG-CLIP 2的架构包含几个关键组件:
-
图像编码器:采用主流的Vision Transformer (ViT)架构,并使用SigLIP 2的权重进行初始化,站在了巨人的肩膀上。
-
文本编码器:同样采用Transformer架构,但最大输入长度扩展到196个词元(token),以处理更长的描述。分词器也换成了支持多语言的Gemma,词汇量高达25.6万。
-
数据自适应分辨率:这是一个聪明的优化。它会根据一批图片中的最大尺寸,动态选择一个最合适的分辨率进行处理,避免了不必要的放大或缩小,让训练和推理更加一致高效。
-
特征聚合:视觉和文本特征最终通过一个掩码注意力池化(Masked Attention Pooling, MAP)头进行融合。
FG-CLIP 2的四项独门绝技
第二阶段联合优化的五个目标中,有四个是专门为细粒度理解设计的,它们是FG-CLIP 2能力飞跃的核心。
细粒度视觉学习(Fine-Grained Visual Learning)
为了让模型理解图片的局部区域,FG-CLIP 2不再像传统CLIP那样只输出一个代表整张图片的特征,而是通过额外的自注意力模块生成密集的、覆盖图片每个角落的特征图。
对于数据中标注的每个物体区域(比如一个人的脸,一本书),模型会用RoIAlign技术精确提取该区域的视觉特征。同时,与这个区域对应的文本描述(比如微笑的女孩,一本蓝色的书)也会被编码。
通过区域对比损失,模型被强制要求将匹配的区域特征-文本特征拉近。经过这样的训练,模型就学会了将文字描述精确地锚定到图像的具体位置。
细粒度文本学习(Fine-Grained Textual Learning)
这项技术主要用来对付硬负样本。硬负样本是一些刁钻的错误描述,它们与正确描述在字面上非常接近,只改动了颜色、数量、动作等关键属性。
例如,一张图片的正样本描述是一个穿着红衬衫的男人在跑步,硬负样本可能是一个穿着蓝衬衫的男人在跑步或一个穿着红衬衫的男人在走路。
模型需要在一个正确样本和十个这样的硬负样本中做出选择。这种高强度的辨析训练,极大地增强了模型对文本细微差异的敏感度。
全局阈值同步的跨模态排序损失(Cross-modal Rank Loss with Global Threshold Synchronization)
CMR损失的目标是强化正确样本与硬负样本之间的边界感。它要求模型给正确配对打出的分数,不仅要高于错误配对,还要高出一个动态的阈值。
意思是,图片和错误文本的相似度,与图片和正确文本的相似度之差,必须小于某个阈值,否则就要产生损失。
更关键的是全局阈值同步。在分布式训练中,这个阈值会在所有GPU上进行同步和平均。这确保了无论在哪台机器上训练,模型对于好与坏的判断标准都是一致的,从而让训练过程更稳定。
文本模态内对比损失(Textual Intra-modal Contrastive Loss)
这是FG-CLIP 2的一项重要创新。此前的所有努力都集中在跨模态,即让图像和文本对齐。但团队发现一个问题:文本编码器本身可能分不清那些语义上很接近的描述。
比如,一个戴着红色帽子的男人和一个戴着深红色帽子的男人,它们的文本特征可能非常相似,这会导致模型在定位图像区域时产生混淆。
TIC损失专门解决这个问题。它完全在文本模态内部进行操作。对于一批文本描述,它会找出每个描述最相似的十个其他描述作为硬负样本,然后通过对比学习,强迫模型将它们的文本特征在表示空间中推开。
这个过程就像是在文本世界内部进行了一次找不同的精细化训练,它锐化了文本编码器的表示空间,让其对语义的区分能力大大增强。这对于需要精确定位的下游任务至关重要。
用精心筛选的双语数据造就全面领先
FG-CLIP 2的强大性能,离不开其背后庞大而高质量的训练数据。
英语数据方面,模型使用了增强版的LAION-2B数据集。
原始的网络图文对质量参差不齐,充满了关键词堆砌和无关噪声。
FG-CLIP 2利用大型多模态模型为这些图片生成了高质量的长字幕,同时保留了原始的短字幕。
这种长短结合的数据策略,让模型既能学习真实世界语言的多样性,又能理解语义丰富、逻辑连贯的描述。
中文数据则整合了三个大型数据集:悟道(Wukong,1亿对)、Zero(2.5亿对)以及一个规模达5亿对的内部数据集。
英语的细粒度数据来自FG-CLIP构建的FineHARD数据集,包含了1200万张图片、4000万个带精细描述的边界框,以及1000万个硬负样本。
中文的细粒度数据则来自一个包含1200万张图片的内部数据集。
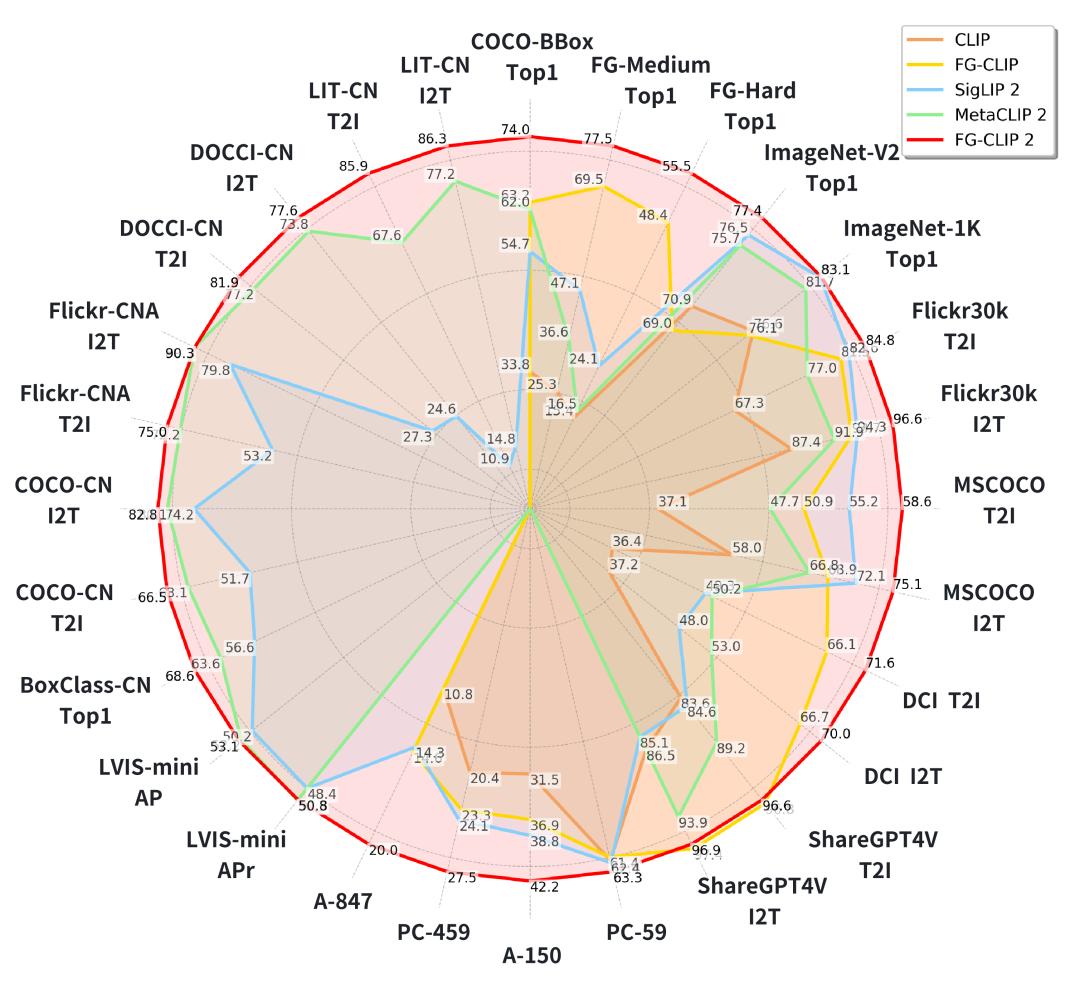
FG-CLIP 2在8个不同类型的视觉-语言任务、共29个数据集上进行了全面评估。无论是在细粒度理解、开放词汇检测,还是在常规的图文检索和分类任务中,它都展现了卓越的性能。
FG-OVD基准测试是一个极具挑战性的细粒度任务。它要求模型在一张图片的特定区域中,从一个正确描述和十个经过精心篡改的错误描述里,选出唯一正确的那个。测试集按难度分为trivial、easy、medium和hard四个等级。
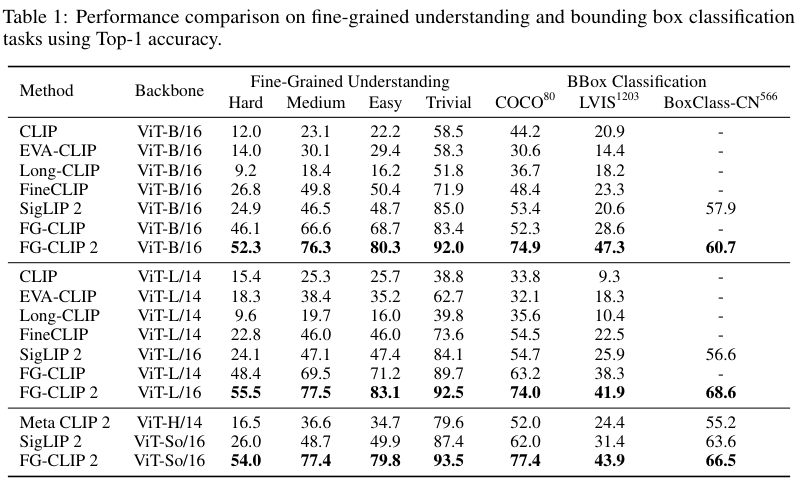
结果一目了然。FG-CLIP 2在所有难度等级上都大幅领先。
特别是在最困难的Hard子集上,它的ViT-L版本比前代最强的FG-CLIP高出7.1个百分点。这证明了FG-CLIP 2在辨别细微视觉-语言差异上的超凡能力。
这项任务评估模型对图片局部区域进行分类的能力。除了在英文的COCO和LVIS数据集上测试,研究团队还使用了他们新构建的中文数据集BoxClass-CN。
FG-CLIP 2再次展现了压倒性优势,无论是在英文还是中文数据集上,都取得了当前最佳性能。这说明其强大的局部内容理解能力可以轻松跨越语言的界限。
开放词汇检测(OVD)要求模型检测出训练时从未见过的物体类别。FG-CLIP 2在这里扮演的是一个增强器的角色。它与一个预训练好的检测器LLMDet相结合,利用其强大的视觉-语言对齐能力来校准和优化检测器的预测结果。
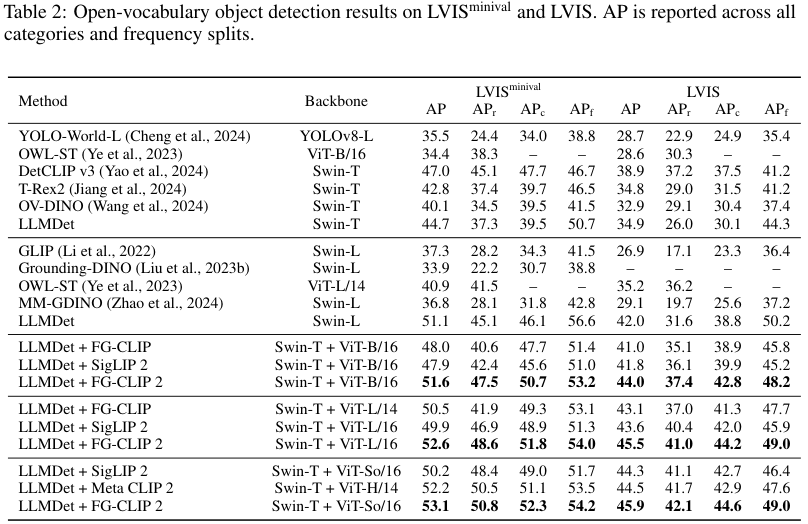
实验表明,与FG-CLIP 2结合后,LLMDet的性能得到了显著提升,在所有开源方法中拔得头筹。这证明了FG-CLIP 2的细粒度能力具有很强的实用价值和泛化能力,能有效赋能下游应用。
图文检索是视觉-语言模型的核心能力。FG-CLIP 2不仅在传统的短字幕检索任务上表现优异,在更考验细粒度理解能力的长字幕检索任务上,更是展现了惊人的实力。
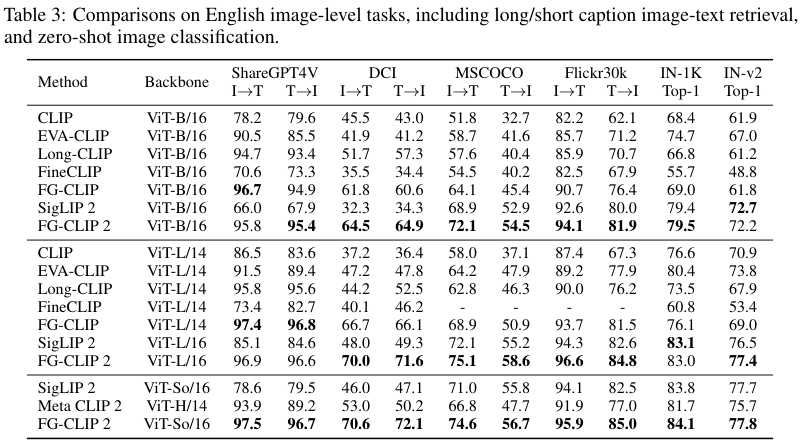
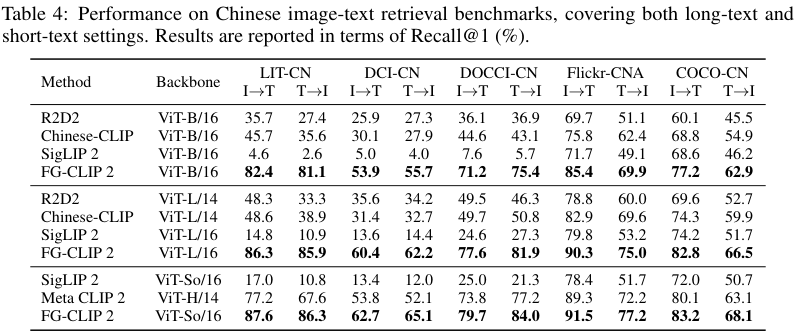
无论是在英文还是中文,长字幕还是短字幕任务上,FG-CLIP 2都取得了最佳或极具竞争力的成绩。特别是在中文长字幕检索任务上,它以碾压性的优势超越了包括Chinese-CLIP和Meta CLIP 2在内的所有模型。
一个值得注意的细节是,FG-CLIP 2的ViT-L/16版本(10亿参数)在多项指标上击败了参数量更大的Meta CLIP 2的ViT-H/14版本(18亿参数)。这充分说明了FG-CLIP 2训练范式的高效性。
为中文多模态研究打造一把新标尺
长期以来,中文多模态研究面临一个窘境:缺乏高质量、多样化的评测基准。现有的数据集大多集中在短字幕图文检索,无法有效衡量模型在细粒度、区域级任务上的真实能力。
为了解决这个问题,FG-CLIP 2团队不仅构建了强大的模型,还为社区贡献了一套全新的中文评估基准。
团队通过整合多个数据源、利用LMM生成高质量长描述、以及专业翻译和校验,构建了三个长字幕图文检索数据集。这些数据集的文本描述更长、更复杂,能够更全面地评估模型对丰富语言和复杂场景的理解能力。
BoxClass-CN是首个专注于中文区域级分类的数据集。它通过一个自动化的数据流水线构建,包含了超过6.6万个高质量的图像区域-中文描述对,覆盖566个语义类别。
这个数据集直接考察模型能否将中文短语与其在图像中对应的精确位置对齐,填补了中文细粒度评测的重要空白。
这些新基准的提出,不仅为评估FG-CLIP 2自身提供了严格的舞台,更为未来中文视觉-语言模型的发展提供了一把更精准的标尺。
FG-CLIP 2是视觉-语言对齐领域的一次重要飞跃。
未来,团队计划让模型处理更长的文本输入,并显式地建模物体间的关系,从而实现更深层次的多模态理解。
参考资料:
https://arxiv.org/pdf/2510.10921
https://github.com/360CVGroup/FG-CLIP
https://huggingface.co/collections/qihoo360/fg-clip-2
END

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 6
6 0
0- 0



 已为社区贡献95条内容
已为社区贡献95条内容

所有评论(0)