Langfuse 可观测性功能实战
摘要: Langfuse是一个开源LLMOps平台,专注于AI应用全生命周期管理,包括开发、监控、评估与调试。其核心优势包括轻量化部署(支持快速自托管)和实战验证的可观测性方案,可追踪LLM应用的完整执行链路(Trace)、多轮对话(Session)和用户行为(User)。平台提供细粒度追踪(如LLM调用、检索器、工具调用等)和跨服务传播支持(基于OpenTelemetry协议),适用于Java和
简介
Langfuse 是一个开源 LLMOps 工程平台,专注于帮助团队协作完成 AI 应用的全生命周期管理,包括开发、监控、评估及调试。其核心优势在于轻量化部署(可在几分钟内完成自托管)和实战可靠性,已在大量实际场景中得到验证。
- 平台涵盖的主要领域:
- 可观测性(Observability):查看 LLM 运行时发生的情况。追踪成本、发现错误并了解用户如何与您的应用交互。无需再猜测故障原因或 OpenAI 上个月向您收取了多少费用。
- 提示管理(Prompt Management):将所有提示集中存储并进行版本控制,而不是分散在代码库各处。您的团队无需修改生产代码即可测试不同版本。
- 评估(Evaluations):衡量您的学习领导力模型 (LLM) 的性能。设置自动化测试,检查回复是否合理、是否切题或是否符合质量标准。
Observability 简介
Langfuse 的可观测性与可追踪性,核心是为 LLM 应用提供全链路、可视化的运行状态监控方案,解决传统日志无法覆盖的 LLM 专属需求,适配复杂场景的调试与优化。
- 弥补传统日志短板:传统日志仅能记录函数是否运行,无法捕捉 LLM 应用的关键细节(如文档检索是否准确、提示词格式是否合规、哪个中间步骤耗时)。
- 适配复杂架构:针对生产级 RAG 等多步骤场景(文档加载、分块、多检索器、重排、生成),实现全链路无遗漏追踪。
可追踪性的核心价值
- 高效调试:快速定位错误根源(如检索错误、提示词格式问题),替代 “猜测式排查”。
- 性能优化:精准识别 latency 瓶颈(嵌入查询、向量搜索、LLM 调用等环节)。
- 成本管控:实时追踪单个模型调用的具体成本,便于预算管理。
- 评估支撑:为 LLM 应用效果评估提供数据基础。
- 客服提效:通过会话快速还原用户问题场景,节省排查时间。
三大维度
Langfuse 的可观测性能力包含三个层级的追踪体系,实现了从单轮执行到多轮对话再到用户全局行为的全维度覆盖:
- Trace(单轮执行追踪):聚焦单条 LLM 请求的完整执行链路,记录从输入、中间步骤到输出的全量数据,包括层级化执行树、耗时分布、Token 与成本消耗等细节,为单轮问题的根因分析提供颗粒度最细的依据。
- Session(多轮对话追踪):将同一上下文的关联请求(如用户的多轮连续问答)聚合为会话,还原完整对话逻辑,解决 “单轮 Trace 孤立无关联” 的问题,便于复盘用户多轮交互中的行为模式与问题。
- User(用户维度追踪):基于用户唯一 ID 聚合其所有 Session 和 Trace,实现 “用户 - 对话 - 单轮执行” 的三层关联,支持从用户视角全局分析行为特征、问题分布,是面向真实业务场景(如用户留存、个性化优化)的顶层观测维度。
数据类型
Langfuse 的 Observation Types(观测类型) 是对追踪数据的分类标签,核心作用是为 Span(追踪跨度)补充上下文、明确操作属性,同时支持高效筛选,覆盖 AI 应用全链路关键环节。

event(事件) |
追踪链路中 “离散的独立事件”,是最基础的观测单元 | 记录单次、无持续时长的瞬时操作 |
span(跨度) |
追踪 “有持续时长的工作单元”,是链路追踪的核心载体 | 体现操作耗时,串联上下游关联步骤 |
generation(生成记录) |
记录 AI 模型的生成过程 | 包含提示词(prompts)、令牌用量(token usage)、成本(costs)等核心信息 |
agent(代理) |
负责决策应用流程的组件 | 可在 LLM 指导下调用工具,主导复杂任务的执行逻辑 |
tool(工具调用) |
记录外部工具 / API 的调用行为 | 例如调用天气 API、数据库查询工具等 |
chain(链) |
串联应用的不同步骤 | 负责传递上下文(如将检索器结果传递给 LLM 调用),衔接各环节 |
retriever(检索器) |
记录数据检索操作 | 例如调用向量数据库、普通数据库的检索步骤,包含查询语句和返回文档 |
evaluator(评估器) |
评估 LLM 输出的质量 | 聚焦相关性(relevance)、正确性(correctness)、实用性(helpfulness)等维度 |
embedding(嵌入生成) |
记录调用 LLM 生成嵌入向量的操作 | 包含模型信息、令牌用量、成本等数据 |
guardrail(安全护栏) |
防护恶意内容或 “越狱” 攻击的组件 | 保障 AI 应用的输出安全与合规 |
备注:
-
event 是最外层,每一个trace 数据都是一个 event
-
span 是基础类型
-
其他的是特殊场景下的类型
核心参数
Trace上报
name |
Optional[str] | Trace 的名称(标识链路用途) |
user_id |
Optional[str] | 链路关联的用户 ID(用于用户维度分析) |
session_id |
Optional[str] | 会话 ID(用于分组关联的多个 Trace) |
version |
Optional[str] | 应用 / 服务版本(用于版本维度对比) |
input |
Optional[Any] | 整个 Trace 的全局输入数据 |
output |
Optional[Any] | 整个 Trace 的全局输出数据 |
metadata |
Optional[Any] | Trace 的额外元数据(JSON 可序列化) |
tags |
Optional[List[str]] | 用于分类 Trace 的标签列表(如 ["payment", "critical"]) |
public |
Optional[bool] | Trace 是否公开可访问(需平台配置支持) |
Trace更新
input |
Optional[Any] | 操作的输入数据 | Span、Generation 均适用 |
output |
Optional[Any] | 操作的输出数据 | Span、Generation 均适用 |
metadata |
Optional[Any] | 额外元数据(需支持 JSON 序列化) | Span、Generation 均适用 |
version |
Optional[str] | 代码 / 组件的版本标识 | Span、Generation 均适用 |
level |
Optional[SpanLevel] | 严重级别,可选值:"DEBUG"、"DEFAULT"、"WARNING"、"ERROR" | Span、Generation 均适用 |
status_message |
Optional[str] | 状态描述信息,尤其适用于错误场景 | Span、Generation 均适用 |
completion_start_time |
Optional[datetime] | LLM 开始生成响应的时间戳(流式输出场景) | 仅 Generation 适用 |
model |
Optional[str] | 所用 AI 模型的名称 / 标识 | 仅 Generation 适用 |
model_parameters |
Optional[Dict[str, MapValue]] | 模型调用参数(如 temperature、max_tokens 等) | 仅 Generation 适用 |
usage_details |
Optional[Dict[str, int]] | Token 用量信息(示例:{"input_tokens": 10, "output_tokens": 20}) |
仅 Generation 适用 |
cost_details |
Optional[Dict[str, float]] | 成本信息(示例:{"total_cost": 0.0023}) |
仅 Generation 适用 |
prompt |
Optional[PromptClient] | 关联 Langfuse 提示词管理的 PromptClient 对象 |
仅 Generation 适用 |
跨服务传播(基于标准协议)
核心原理:OpenTelemetry- Baggage
Baggage是一种跨信号、跨服务传递上下文信息的机制,本质是与 Context 绑定的键值存储,核心作用是让关键数据能在分布式系统中流转并赋能可观测性分析。
-
核心工作原理:依赖于传播器(Propagator)。在微服务的一次调用中,发起方服务会将Baggage从上下文(Context)中注入(Inject) 到HTTP请求头等载体中;接收方服务则从传入的请求头中提取(Extract) 这些信息到自己的上下文里,从而获取到这些数据-。
-
本质属性:是与 OpenTelemetry Context 绑定的键值存储,和 Context 一起在服务、进程间传递,不属于追踪(Trace)、指标(Metric)、日志(Log)任一单独信号,但能为所有信号提供数据支持。
-
核心价值:解决 “分布式系统中关键信息跨服务传递” 的问题,无需在代码中反复复制数据(如用户 ID、账户标识),就能让这些信息在下游服务的追踪、指标、日志中可用。
-
参考文献:https://opentelemetry.io/docs/concepts/signals/baggage/
使用 Baggage 时需重点关注两个风险:
-
敏感信息泄露风险:Baggage 会随网络请求(如 HTTP 头)自动传播,网络流量中可见,可能被第三方 API 或下游服务扩散到外部网络,因此禁止存储密码、令牌等敏感数据。
-
数据完整性无保障:Baggage 没有内置的完整性校验机制,无法确认数据是否被篡改或是否来自可信来源,读取时需谨慎判断有效性。
实现过程
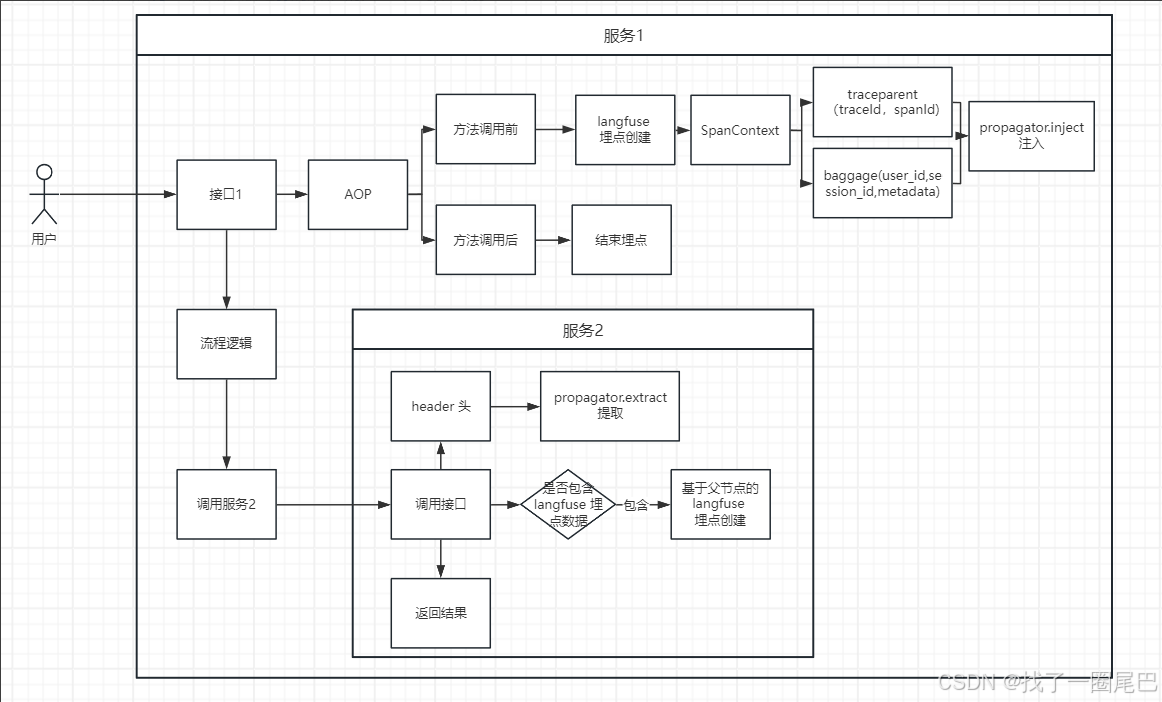
OpenTelemetry 协议标准 Http Header 头注入
-
通过OpenTelemetry创建Span后,TraceID,SpanId 会缓存到SpanContext 上下文中;
- 如果需要额外的透传参数如Session_id,User_id ,OpenTelemetry 建议通过组装Baggage 的方式,先放入上下文对象中。
- 通过OpenTelemetry 传播对象,将上下文对象中的SpanContent 和 Baggage 传入Header 头,此时Header 头中包含两个对象traceparent 和 baggage ;
- traceparent 主要包含TraceId,SpanId,
- baggage 是用户自行组装的内容。
OpenTelemetry 协议标准Http Header 头提取
- 从header 头中,使用 OpenTelemetry 传播对象的extract 方法,提取current_span的span_context,获取TraceId,SpanId
- 使用baggage.getall,获取header 头中的baggage 参数。
跨服务传播实现
- 在创建current_span的时候传递
trace_context={"trace_id": trace_id, "parent_span_id": parent_span_id}
- 通过相同的 trace_id 和确认当前span 的父类Id,parent_span_id,此时即可实现跨服务传播的过程。
Langfuse实现方式(Java)
langfuse 官网提供了 langfuse-java-sdk ,是基于langfuse的openAPI 自动生成的Java
端封装。但是官网有明确说明,Java 端建议使用OpenTelemetry-java-sdk 的方式去接入Langfuse。
基于(langfuse-java-sdk)
- 创建 Langfuse 客户端
// 创建 Langfuse 客户端
LangfuseClient client = LangfuseClient.builder()
.url("https://localhost:3000") // 本地部署
.credentials("public-key", "private-key") // 替换为您的 API 密钥
.build();- 创建最外层的Trace-event
// 1. 创建 Trace
TraceEvent traceEvent = TraceEvent.builder()
.id(UUID.randomUUID().toString())
.timestamp(timestamp)
.body(TraceBody.builder()
.id(traceId)
.name("LLM Call Trace")
.userId("user-789")
.sessionId("session-101")
.input("User question about capitals")
.environment("production")
.build())
.build();- 创建span
// 2. 创建 Span(数据预处理)
CreateSpanEvent preprocessingSpan = CreateSpanEvent.builder()
.id(UUID.randomUUID().toString())
.timestamp(timestamp)
.body(CreateSpanBody.builder()
.id(UUID.randomUUID().toString())
.traceId(traceId)
.name("Preprocessing")
.input("User question: What is the capital of France?")
.output("Formatted prompt: What is the capital of France?")
.level(ObservationLevel.DEFAULT)
.startTime(OffsetDateTime.now(ZoneOffset.UTC))
.endTime(OffsetDateTime.now(ZoneOffset.UTC).plusSeconds(1))
.build())
.build();- 创建Observation
- 目前Java-SDK-Observation只支持 event,span,Generation(LLM调用) 三种类型
// 3. 创建 Generation(LLM 调用)
String generationId = UUID.randomUUID().toString();
CreateObservationEvent generationEvent = CreateObservationEvent.builder()
.id(UUID.randomUUID().toString())
.timestamp(timestamp)
.body(ObservationBody.builder()
.type(ObservationType.GENERATION) // 必需:设置观察类型
.id(generationId)
.traceId(traceId)
.name("OpenAI GPT-4 Call")
.input("What is the capital of France?")
.output("The capital of France is Paris.")
.model("gpt-4")
.modelParameters(createModelParameters())
.usage(createUsageForObservation())
.completionStartTime(OffsetDateTime.now(ZoneOffset.UTC))
.startTime(OffsetDateTime.now(ZoneOffset.UTC))
.endTime(OffsetDateTime.now(ZoneOffset.UTC).plusSeconds(2))
.level(ObservationLevel.DEFAULT)
.metadata(Map.of("provider", "openai", "temperature", 0.7))
.build())
.build();- 批量上报
// 批量上报所有事件
IngestionRequest request = IngestionRequest.builder()
.addBatch(IngestionEvent.traceCreate(traceEvent))
.addBatch(IngestionEvent.spanCreate(preprocessingSpan))
.addBatch(IngestionEvent.observationCreate(generationEvent))
.addBatch(IngestionEvent.spanCreate(postprocessingSpan))
.build();
// 执行批量上报
IngestionResponse response = client.ingestion().batch(request);
System.out.println("成功上报: " + response.getSuccesses().size());
System.out.println("失败数量: " + response.getErrors().size());- 更新 Trace
//更新 Trace(使用相同的 traceId 但不同的事件 ID)
TraceEvent updateTraceEvent = TraceEvent.builder()
.id(UUID.randomUUID().toString()) // 新的事件 ID
.timestamp(OffsetDateTime.now(ZoneOffset.UTC).toString())
.body(TraceBody.builder()
.id(traceId) // 相同的 traceId
.output("Updated output")
.metadata(Map.of("status", "completed", "updated_at", System.currentTimeMillis()))
.build())
.build();基于OpenTelemetry-java-sdk
初始化
| SdkTracerProvider | Clock(时钟) | setClock(Clock clock) | 设置用于生成时间戳的时钟 | Clock.getDefault() | - |
| IdGenerator(ID 生成器) | setIdGenerator(IdGenerator idGenerator) | 配置 Trace ID 和 Span ID 的生成逻辑 | IdGenerator.random() | 支持自定义实现 | |
| Resource(资源) | setResource(Resource resource)、addResource(Resource resource) | 设置 / 合并服务描述信息(如服务名、版本) | Resource.getDefault() | set = 覆盖,add = 合并 | |
| SpanLimits(Span 限制) | setSpanLimits(SpanLimits)、setSpanLimits(Supplier<SpanLimits>) | 限制 Span 的属性、事件、链接数量等 | SpanLimits::getDefault | 支持直接设置或通过 Supplier 延迟获取 | |
| Sampler(采样器) | setSampler(Sampler sampler) | 配置 Span 采样策略(决定哪些 Span 被记录) | Sampler.parentBased(Sampler.alwaysOn()) | 内置多种采样器(如 AlwaysOn、Probability) | |
| SpanProcessor(处理器) | addSpanProcessor(SpanProcessor) | 添加 Span 生命周期处理器(支持多个),负责 Span 导出等逻辑 | 空列表 | 需配合具体 Processor 实现(如 BatchSpanProcessor) | |
| BatchSpanProcessor | 导出未采样 Span | setExportUnsampledSpans(boolean) | 是否导出未采样的 Span | false | 1.34.0+ 版本支持 |
| 调度延迟 | setScheduleDelay(long, TimeUnit)、setScheduleDelay(Duration) | 两次批量导出的时间间隔 | 5000 毫秒(5 秒) | - | |
| 导出超时 | setExporterTimeout(long, TimeUnit)、setExporterTimeout(Duration) | 单次导出操作的最大超时时间 | 30000 毫秒(30 秒) | 设为 0 则无超时(Long.MAX_VALUE) | |
| 最大队列大小 | setMaxQueueSize(int) | 队列缓存的最大 Span 数量,超限丢弃 | 2048 | 必须为正数 | |
| 最大导出批次大小 | setMaxExportBatchSize(int) | 单次导出的最大 Span 数量 | 512 | 必须为正数,且不超过 maxQueueSize(超限自动调整) | |
| OtlpHttpSpanExporter | Endpoint(端点) | setEndpoint(String endpoint) | 设置 OTLP HTTP 导出的目标 URL | "http://localhost:4318/v1/traces" | 需符合 OTLP HTTP 协议格式 |
| Timeout(超时时间) | setTimeout(long, TimeUnit)、setTimeout(Duration) | 设置 HTTP 请求超时时间 | 内部默认值(未明确) | - | |
| Compression(压缩) | setCompression(String compressionMethod) | 设置请求压缩方式 | "none" | 仅支持 "gzip" 或 "none" | |
| Headers(HTTP 头) | addHeader(String key, String value) | 添加自定义 HTTP 请求头 | 无 | 可多次调用添加多个头 | |
| Trusted Certificates | setTrustedCertificates(byte[] trustedCertificatesPem) | 设置验证服务器证书的信任证书(PEM 格式) | 系统默认信任库 | 字节数组为 PEM 格式内容 | |
| Client TLS(客户端 TLS) | setClientTls(byte[] privateKeyPem, byte[] certificatePem) | 设置客户端 TLS 认证的私钥和证书(PEM 格式) | 无 | 用于双向 TLS 认证 | |
| SSL Context(SSL 上下文) | setSslContext(SSLContext sslContext, X509TrustManager trustManager) | 直接配置 SSL 上下文和信任管理器 | 无 | 优先级高于单独设置证书 | |
| Retry Policy(重试策略) | setRetryPolicy(RetryPolicy retryPolicy) | 配置导出失败时的重试逻辑 | 内部默认重试策略(未明确) | 需配合 RetryPolicy 实现类 | |
| SdkTracerProvider | Meter Provider(指标提供者) | setMeterProvider(MeterProvider)、setMeterProvider(Supplier<MeterProvider>) | 设置用于导出指标(metrics)的提供者 | 无 | 支持直接设置或通过 Supplier 延迟获取,关联指标采集能力 |
OTEL 上报方法
- 初始化 OpenTelemetry SDK
//初始化 OpenTelemetry SDK
OpenTelemetry openTelemetry = OpenTelemetrySdk.builder()
.setTracerProvider(tracerProvider)
.setPropagators(contextPropagators) // 设置 propagator
.buildAndRegisterGlobal();- 初始化traceProvider
// 配置 Tracer Provider(批量上报 Span,提升性能)
tracerProvider = SdkTracerProvider.builder()
.setResource(resource)
.addSpanProcessor(
BatchSpanProcessor.builder(otlpExporter)
.setMaxExportBatchSize(512)
.setScheduleDelay(5, TimeUnit.SECONDS)
.build()
)
.build();- BatchSpanProcessor:批量上报Span,可以配置每次上报的最大batchSize、上报时间
- Resource:配置资源(服务名称、版本、环境等)
// 配置资源(服务名称、版本、环境等)
Resource resource = Resource.getDefault()
.merge(Resource.create(Attributes.of(
AttributeKey.stringKey("service.name"), SERVICE_NAME,
AttributeKey.stringKey("service.version"), "1.0.0",
AttributeKey.stringKey("deployment.environment"), "dev"
)));- 初始化OtlpHttpSpanExporter
OtlpHttpSpanExporter otlpExporter = OtlpHttpSpanExporter.builder()
.setEndpoint(fullEndpoint)
.addHeader("Authorization", "Basic " + authString)
.setTimeout(30, TimeUnit.SECONDS)
.build();- fullEndpoint:追踪上报地址,即Langfuse 上报地址:https://localhost:3000/api/public/otel/v1/traces
- Header:请求Langfuse 的鉴权,是固定Base64编码的 pubilckey:secretKey
/**
* 生成 Basic Auth 认证头
*/
private static String generateAuthHeader(String publicKey, String secretKey) {
String credentials = publicKey + ":" + secretKey;
return Base64.getEncoder().encodeToString(credentials.getBytes());
}- 创建Span
/**
* 示例:用户查询接口
* 演示如何创建 Span 并设置 Langfuse 相关属性
*/
public String getUserInfo(String userId) {
// 1. 创建 Span(描述当前操作)
Span span = tracer.spanBuilder("user-service.get-user-info") // Span 名称(建议:服务名.接口名)
.startSpan();
try (var scope = span.makeCurrent()) { // 绑定 Span 到当前线程
// 设置 Langfuse Trace 级别属性(可选)
span.setAttribute("langfuse.trace.name", "Get User Info");
span.setAttribute("langfuse.user.id", userId);
span.setAttribute("langfuse.trace.input", "userId: " + userId);
// 2. 业务逻辑(模拟接口调用)
String userInfo = fetchUserFromDB(userId);
// 3. 记录 Span 结果(可选:添加输出、耗时等元数据)
span.setAttribute("user.info", userInfo);
span.setAttribute("langfuse.trace.output", userInfo);
span.setStatus(StatusCode.OK); // 标记成功
return userInfo;
} catch (Exception e) {
// 4. 异常处理(标记失败,记录异常信息)
span.setStatus(StatusCode.ERROR, e.getMessage());
span.recordException(e);
span.setAttribute("langfuse.trace.output", "Error: " + e.getMessage());
throw e;
} finally {
// 5. 结束 Span(必须调用,否则数据不会上报)
span.end();
}
}- 创建子节点Span
/**
* 模拟数据库查询
* 演示如何创建子 Span(嵌套追踪)
*/
private String fetchUserFromDB(String userId) {
// 子 Span(可选:追踪内部调用,如 DB 查询、第三方 API)
Span childSpan = tracer.spanBuilder("user-service.fetch-from-db")
.startSpan();
try (var scope = childSpan.makeCurrent()) {
// 设置 Langfuse Observation 级别属性(可选)
childSpan.setAttribute("langfuse.observation.type", "span");
childSpan.setAttribute("langfuse.observation.input", "userId: " + userId);
Thread.sleep(50); // 模拟耗时
String result = "User{id=" + userId + ", name='test'}";
childSpan.setAttribute("langfuse.observation.output", result);
return result;
} catch (InterruptedException e) {
childSpan.setStatus(StatusCode.ERROR);
childSpan.recordException(e);
childSpan.setAttribute("langfuse.observation.status_message", e.getMessage());
throw new RuntimeException(e);
} finally {
childSpan.end();
}
}- 实时推送
tracerProvider.forceFlush().join(10, TimeUnit.SECONDS);- 优雅关闭
tracerProvider.shutdown().join(10, TimeUnit.SECONDS);Langfuse实现方式(python)
我们可以直接使用 langfuse-python-sdk 实现 langfuse 的接入。
初始化
一、必填参数(无默认值,必须配置)
public_key |
LANGFUSE_PUBLIC_KEY |
Langfuse 项目的公开 API 密钥,用于身份识别,从项目「Settings → API Keys」获取。 |
secret_key |
LANGFUSE_SECRET_KEY |
Langfuse 项目的私有 API 密钥,用于权限校验,需妥善保管,避免泄露。 |
二、核心可选参数(常用配置,适配不同部署 / 网络场景)
base_url |
LANGFUSE_BASE_URL |
Langfuse 服务的 API 地址:- 云版本默认 https://cloud.langfuse.com;- 自部署版本需改为自身部署地址(https://cslangfuse.lenovo.com.cn)。 |
"https://cloud.langfuse.com" |
timeout |
LANGFUSE_TIMEOUT |
API 请求超时时间(单位:秒),用于控制网络请求阻塞时长,避免因服务不可用导致业务卡顿。 | 5 |
environment |
LANGFUSE_TRACING_ENVIRONMENT |
追踪环境名称(如 development、staging、production),用于区分不同环境的追踪数据,支持小写字母、数字、连字符(-)、下划线(_)。 |
"default" |
release |
LANGFUSE_RELEASE |
应用的版本号 / 代码哈希(如 v1.0.0、a1b2c3d),用于按版本分组分析追踪数据(如对比不同版本的 LLM 调用成本)。 |
-(无默认) |
sample_rate |
LANGFUSE_SAMPLE_RATE |
追踪采样率(取值范围 0.0~1.0):- 1.0 表示 100% 全量采样;- 0.5 表示采样 50% 追踪数据,适用于高并发场景降低数据量。 | 1.0 |
三、进阶配置参数(控制数据上报 / 调试 / 敏感数据处理)
flush_at |
LANGFUSE_FLUSH_AT |
批量上报阈值:累计达到该数量的 Span 后,自动批量发送到 Langfuse 服务,减少网络请求次数(性能优化)。 | 512 |
flush_interval |
LANGFUSE_FLUSH_INTERVAL |
批量上报间隔(单位:秒):即使未达到 flush_at 阈值,每隔该时间也会自动上报一次,避免数据堆积。 |
5 |
debug |
LANGFUSE_DEBUG |
开启调试模式:输出更详细的日志(如请求参数、响应状态),用于排查客户端与服务端的连接问题,设置为 True 或 "True" 生效。 |
False |
tracing_enabled |
LANGFUSE_TRACING_ENABLED |
启用 / 禁用追踪功能:设置为 False 时,所有 Langfuse 观测调用都会变成 “空操作”(不上报数据),适用于本地开发、测试等无需追踪的场景。 |
True |
httpx_client |
-(仅代码参数) | 自定义 httpx.Client 实例,用于发起非追踪相关的 HTTP 请求(如自定义请求头、代理、证书配置)。 |
-(默认自动创建) |
mask |
-(仅代码参数) | 敏感数据脱敏函数:接收原始数据(Any 类型),返回脱敏后的数据,用于过滤追踪中的密码、手机号等敏感信息(如替换手机号为 ****)。 |
-(无默认,不脱敏) |
media_upload_thread_count |
LANGFUSE_MEDIA_UPLOAD_THREAD_COUNT |
媒体文件上传线程数:处理图片、音频等多模态数据上传的后台线程数量,调整为更高值可提升多模态数据上报效率。 | 1 |
LANGFUSE_MEDIA_UPLOAD_ENABLED |
LANGFUSE_MEDIA_UPLOAD_ENABLED |
是否允许上传媒体文件到 Langfuse S3 存储:自部署环境若无需多模态数据存储,可设置为 False 禁用。 |
-(默认启用) |
Python SDK Method
tracing相关
start_span():
-
创建新的 span,但不自动设置为当前 span
-
需要手动调用 .end() 结束
start_as_current_span():
-
创建 span 并自动设置为当前 span(上下文管理器)
-
退出时自动结束,适合 with 语句
start_observation():
-
创建指定类型的 observation(span, generation, agent, tool 等)
-
通过 as_type 参数指定类型
start_as_current_observation():
-
创建并设置为当前 observation(上下文管理器)
-
支持多种类型:span, generation, agent, tool, chain 等
update_current_span():更新当前活动的 span 信息
update_current_trace():更新当前 trace 的元数据(用户 ID、会话 ID、标签等)
create_trace_id():生成唯一的 trace ID(32 位十六进制字符串)
create_observation_id():生成唯一的 observation ID(16 位十六进制字符串)
get_current_trace_id():获取当前活动 span 的 trace ID
get_current_observation_id():获取当前活动 span 的 observation ID
create_event():创建 EVENT 类型的 observation(瞬时事件,立即结束)
工具方法
flush():强制刷新所有待发送的数据到 Langfuse API
shutdown():优雅关闭客户端,确保数据已发送
get_trace_url():获取在 Langfuse UI 中查看 trace 的 URL
resolve_media_references():将媒体引用字符串替换为 base64 数据 URI
auth_check():检查提供的凭证是否有效
基于LangChain 框架
- 使用方式:初始化
CallbackHandler并将其添加到您的 Langchain 调用中,可以全局添加,也可以按调用添加。 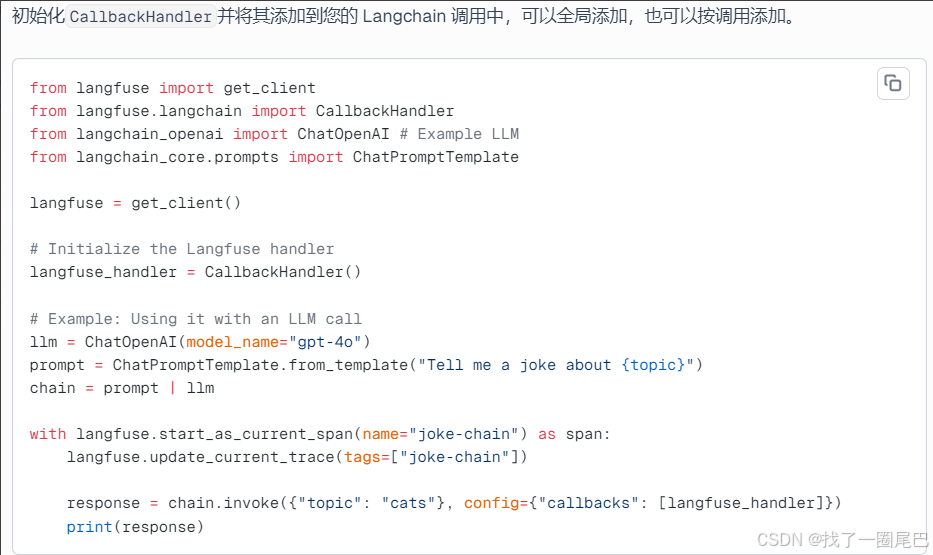
- 原理:回调处理函数会将各种 Langchain 事件映射到 Langfuse 观测值,Langchain事件包括:
- Chains (
on_chain_start,on_chain_end,on_chain_error): Traced as spans. - LLMs (
on_llm_start,on_llm_end,on_llm_error,on_chat_model_start): Traced as generations, capturing model name, prompts, responses, and usage if available from the LLM provider. - Tools (
on_tool_start,on_tool_end,on_tool_error): Traced as spans, capturing tool input and output. - Retrievers (
on_retriever_start,on_retriever_end,on_retriever_error): Traced as spans, capturing the query and retrieved documents. - Agents (
on_agent_action,on_agent_finish): Agent actions and final finishes are captured within their parent chain/agent span.
拓展方法
propagate_attributes():将属性拓展到子节点

- 值必须是长度不超过 200 个字符的字符串。
- 元数据键:仅限字母数字字符(不含空格或特殊字符)
- 在跟踪初期就进行调用,以确保涵盖所有观测结果。这样可以确保 Langfuse 中的所有指标都准确无误。
跨业务传播
对于跨多个服务的分布式追踪,请使用as_baggage参数(更多详细信息请参阅OpenTelemetry 文档)通过 HTTP 标头传播属性。

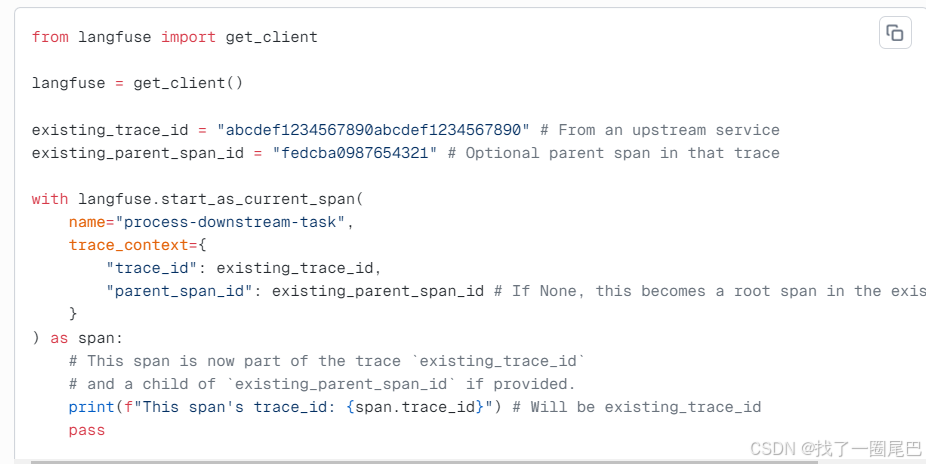
将新生成的观测数据(如 Span)关联到外部已存在的追踪(Trace)
- 适用场景:当你拥有外部来源的
trace_id(可选parent_span_id)时,需要将 Langfuse 中新建的 Span 关联到这个已有追踪上。例如:外部服务、批处理任务已生成了追踪 ID,现在要在 Langfuse 中记录该任务下游操作的 Span,并让它归属到同一个追踪链路中。 - 前提说明:OpenTelemetry 本身支持 “已接入 OTEL 的服务间” 自动传递追踪上下文,无需手动处理;该方法仅用于对接未自动传递上下文的外部系统,或需要手动关联追踪的特殊场景。
参考文献
- 开源代码地址:https://github.com/langfuse/langfuse
- 文档地址:https://langfuse.com/docs
- API接口文档: https://api.reference.langfuse.com/#tag/organizations
- 优秀教程:https://www.datacamp.com/tutorial/langfuse
- 性能基准测试参考:https://blog.csdn.net/gitblog_00342/article/details/150961332
- OpenTelemetry-otel-trace:https://opentelemetry.io/docs/specs/otel/trace/
- OpenTelemetry-java:https://opentelemetry.io/docs/languages/java/intro/
- Langfuse-OpenTelemetry支持:https://langfuse.com/integrations/native/opentelemetry

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 15
15 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)