构建一个自主深度思考的RAG管道以解决复杂查询--通过网络搜索扩充知识(6)
然后,它使用专门的提示来指导我们强大的推理大语言模型将这些信息综合成一个全面的、多段落的答案,其中包括引用,从而成功地完成我们的研究过程。要解决我们的查询难题,我们的智能体需要查找有关AMD AI芯片战略的最新新闻(文件提交后,2024年发布的)。让我们从检索节点开始,该节点用于搜索我们内部的10-K文档。它唯一的任务是调用我们的planner_agent,并填充我们plan字段中的RAGStat
所以,我们的检索漏斗现在非常强大,但它有一个巨大的盲点。
它只能查看我们2023年10-K文件中的内容。要解决我们的查询难题,我们的智能体需要查找有关AMD AI芯片战略的最新新闻(文件提交后,2024年发布的)。而这些信息在我们的静态知识库中根本不存在。
要真正构建一个“深度思考”智能体,它需要能够认识到自身知识的局限性,并从其他地方寻找答案。我们需要为它打开一扇通往外部世界的窗口。
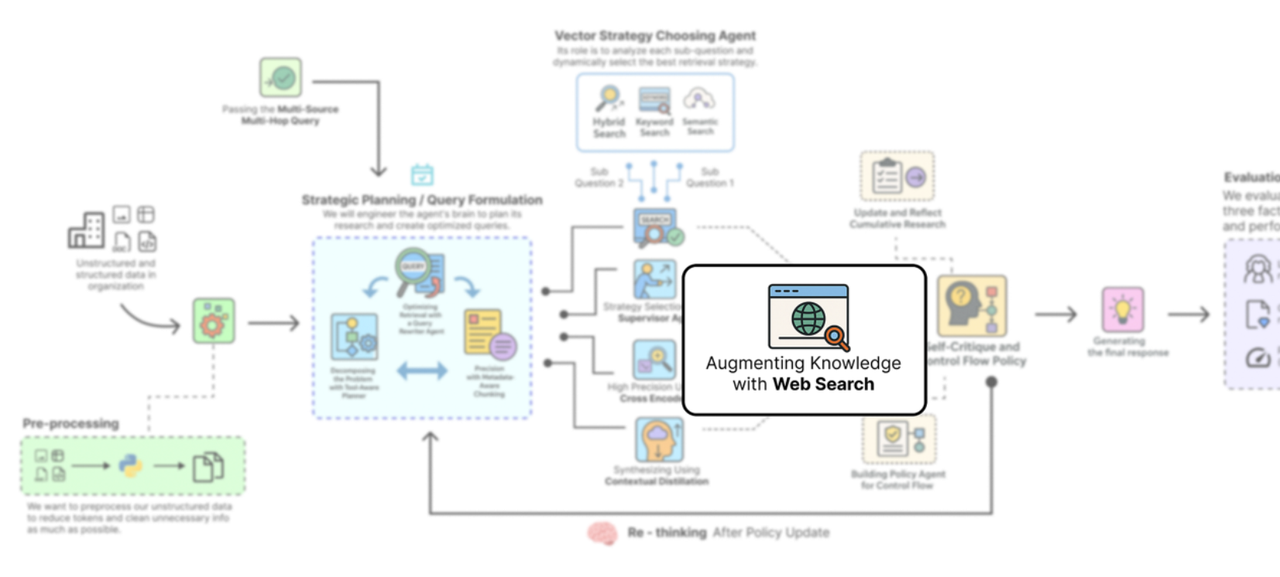
使用网络进行增强(作者: 法里德·汗 )
这是我们用新工具增强智能体能力的步骤:网络搜索。这将我们的系统从特定文档的问答机器人转变为真正的多源研究助手。
为此,我们将使用Tavily Search API。它是专门为大语言模型(LLMs)构建的搜索引擎,提供干净、无广告且相关的搜索结果,非常适合检索增强生成(RAG)管道。它还能与LangChain无缝集成。
所以,基本上,我们要做的第一件事就是初始化Tavily搜索工具本身。
from langchain_community.tools.tavily_search import TavilySearchResults
# Initialize the Tavily search tool.
# k=3: This parameter instructs the tool to return the top 3 most relevant search results for a given query.
web_search_tool = TavilySearchResults(k=3)我们基本上是在创建一个Tavily搜索工具的实例,我们的智能体可以调用它。k=3参数是一个很好的起点,它能提供一些高质量的来源,而不会让智能体被过多信息淹没。
现在,原始的 API 响应并非我们所需。我们的下游组件,即重排器和蒸馏器,均设计为与特定的数据结构协同工作:一个由 LangChain 文档对象组成的列表。为确保无缝集成,我们需要创建一个简单的包装函数。该函数将接收一个查询,调用 Tavily 工具,然后将原始结果格式化为标准的 文档结构。
def web_search_function(query: str) -> List[Document]:
# Invoke the Tavily search tool with the provided query.
results = web_search_tool.invoke({"query": query})
# Format the results into a list of LangChain Document objects.
# We use a list comprehension for a concise and readable implementation.
return [
Document(
# The main content of the search result goes into 'page_content'.
page_content=res["content"],
# We store the source URL in the 'metadata' dictionary for citations.
metadata={"source": res["url"]}
) for res in results
]此网络搜索功能充当关键适配器。它调用网络搜索工具的调用方法,该方法返回一个字典列表,每个字典包含诸如"内容"和"网址"之类的键。
-
列表推导式随后遍历这些结果,并将它们整齐地重新打包成文档对象,这是我们的管道所期望的。
-
该page_content获取主要文本,重要的是,我们将url存储在元数据中。
-
这确保了我们的智能体在生成最终答案时,能够正确引用其网络来源。
这使得我们的外部知识源在外观和感觉上与内部知识源完全一致,从而使我们能够对两者使用相同的处理流程。
我们的函数已经准备好,现在让我们快速测试一下,确保它能按预期工作。我们将使用一个与主要挑战第二部分相关的查询。
# Test the web search function with a query about AMD's 2024 strategy
print("\n--- Testing Web Search Tool ---")
test_query_web = "AMD AI chip strategy 2024"
test_results_web = web_search_function(test_query_web)
print(f"Found {len(test_results_web)} results for query: '{test_query_web}'")
# Print a snippet from the first result to see what we got back
if test_results_web:
print(f"Top result snippet: {test_results_web[0].page_content[:250]}...")#### OUTPUT ####
Web search tool (Tavily) initialized.
--- Testing Web Search Tool ---
Found 3 results for query: 'AMD AI chip strategy 2024'
Top result snippet: AMD has intensified its battle with Nvidia in the AI chip market with the release of the Instinct MI300X accelerator, a powerful GPU designed to challenge Nvidia's H100 in training and inference for large language models. Major cloud providers like Microsoft Azure and Oracle Cloud are adopting the MI300X, indicating strong market interest...输出结果证实我们的工具运行得非常完美。它为我们的查询找到了3个相关网页。排名第一的结果中的摘要正是我们的智能体所缺少的那种最新的外部信息。
它提到了AMD “Instinct MI300X”及其与NVIDIA “H100”的竞争,而这正是解决我们后半部分问题所需的证据。
我们的智能体现在有了一扇通往外部世界的窗口,其规划器可以智能地决定何时透过它进行观察。最后一块拼图是赋予智能体反思其发现并决定何时完成研究的能力。
自我批判与控制流策略
到目前为止,我们已经构建了一个强大的研究机器。我们的智能体可以制定计划、选择合适的工具,并执行复杂的检索流程。但有一个关键环节缺失:思考自身进展的能力。一个盲目地按部就班执行计划的智能体并非真正智能。它需要一种自我批判的机制。
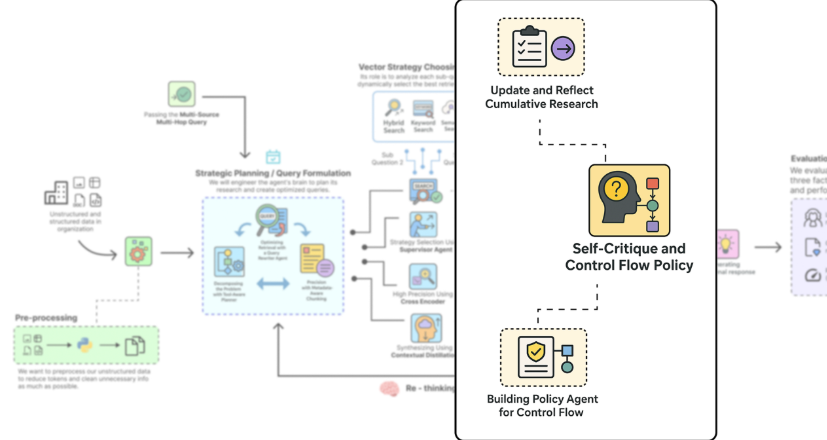
自我批判与政策制定(作者: 法里德·汗 )
这就是我们构建智能体自主性认知核心的地方。在每一个研究步骤之后,我们的智能体都会暂停并进行反思。它会审视刚刚发现的新信息,将其与已知信息进行比较,然后做出战略决策:我的研究是否已经完成,还是需要继续?
这种自我批判循环正是将我们的系统从脚本化工作流程提升为自主智能体的关键所在。它是一种机制,使系统能够判断何时已收集到足够的证据,从而有信心地回答用户的问题。
我们将使用两个新的专业代理来实施这一计划:
-
反思代理:该代理将从已完成的步骤中提炼的上下文,并创建一个简洁的单句摘要。然后,这个摘要将被添加到我们代理的“研究历史”中。
-
策略代理:这是主要的战略制定者。经过思考后,它将审查整个研究历史与原始计划的关系,并做出关键决策:继续执行计划或结束。
更新并反映累积研究历史
在我们的智能体完成一个研究步骤(例如,检索并提炼关于NVIDIA风险的信息)后,我们不想只是继续推进。我们需要将这些新知识整合到智能体的记忆中。
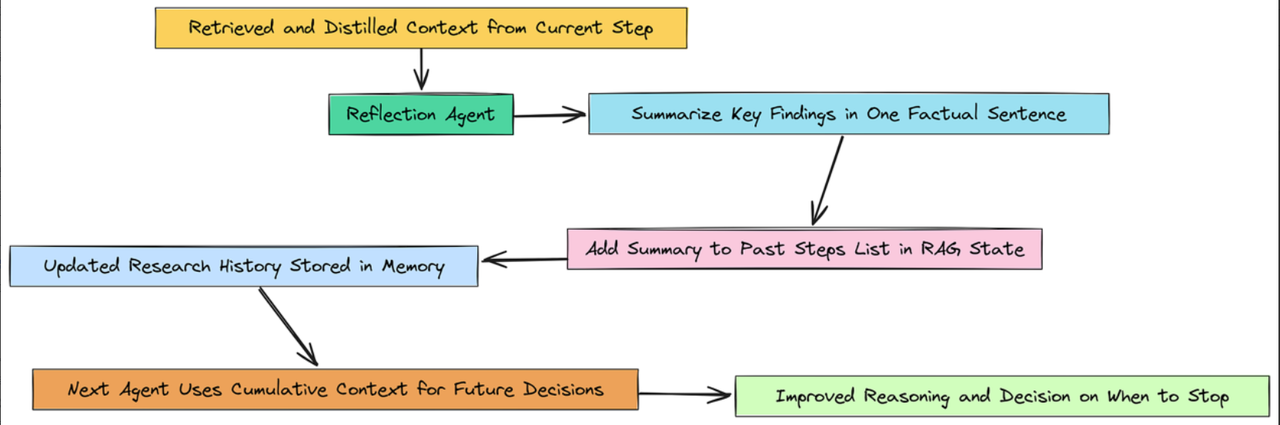
反射累积(作者: 法里德·汗 )
我们将构建一个反思代理,其唯一任务是执行此整合。它将从当前步骤中提取丰富、精炼的上下文,并将其总结为一个单一的事实性句子。然后,这个总结会被添加到我们过去步骤列表中,该列表位于检索增强生成状态中。
首先,让我们为这个智能体创建提示词。
# The prompt for our reflection agent, instructing it to be concise and factual
reflection_prompt = ChatPromptTemplate.from_messages([
("system", """You are a research assistant. Based on the retrieved context for the current sub-question, write a concise, one-sentence summary of the key findings.
This summary will be added to our research history. Be factual and to the point."""),
("human", "Current sub-question: {sub_question}\n\nDistilled context:\n{context}")
])我们告诉这个智能体要像一个勤奋的研究助理那样行事。它的任务不是发挥创造力,而是做好记录工作。它读取上下文并撰写摘要。现在我们可以组装智能体本身了。
# Create the agent by piping our prompt to the reasoning LLM and a string output parser
reflection_agent = reflection_prompt | reasoning_llm | StrOutputParser()
print("Reflection Agent created.")这个反思代理是我们认知循环的一部分。通过创建这些简洁的摘要,它构建了一个清晰、易读的研究历史。这段历史将作为我们下一个也是最重要的代理的输入:即决定何时停止的代理。
构建控制流的策略代理
这是我们智能体自主性的核心。在反思智能体更新研究历史后,策略智能体开始发挥作用。它充当整个操作的监督者。
它的任务是审视代理所知道的一切——原始问题、初始计划以及已完成步骤的完整摘要历史,并做出高层次的战略决策。
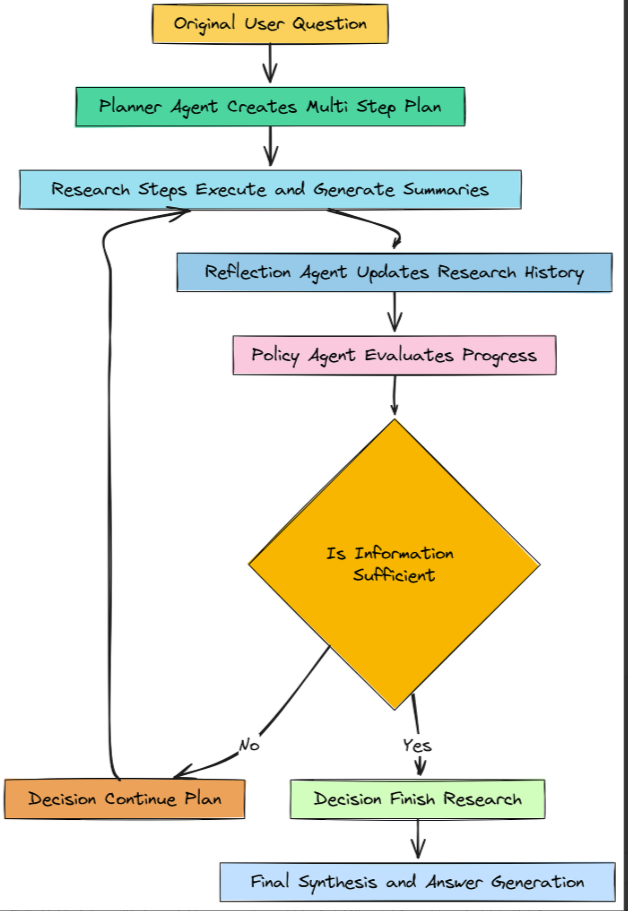
策略代理(作者: 法里德·汗 )
我们将首先使用 Pydantic 模型定义其决策的结构。
class Decision(BaseModel):
# The decision must be one of these two actions.
next_action: Literal["CONTINUE_PLAN", "FINISH"]
# The agent must justify its decision.
justification: str这个决策类促使我们的策略代理做出明确的二元选择,并解释其推理过程。这使得其行为透明且易于调试。
接下来,我们设计将引导其决策链路的提示词。
# The prompt for our policy agent, instructing it to act as a master strategist
policy_prompt = ChatPromptTemplate.from_messages([
("system", """You are a master strategist. Your role is to analyze the research progress and decide the next action.
You have the original question, the initial plan, and a log of completed steps with their summaries.
- If the collected information in the Research History is sufficient to comprehensively answer the Original Question, decide to FINISH.
- Otherwise, if the plan is not yet complete, decide to CONTINUE_PLAN."""),
("human", "Original Question: {question}\n\nInitial Plan:\n{plan}\n\nResearch History (Completed Steps):\n{history}")
])我们基本上是在要求大语言模型进行元分析。它不是在直接回答问题本身,而是在对研究过程的状态进行推理。它将自己所拥有的(历史)与所需要的(计划和问题)进行比较,并做出判断。
现在,我们可以组装策略代理了。
# Create the agent by piping our prompt to the reasoning LLM and structuring its output with our Decision class
policy_agent = policy_prompt | reasoning_llm.with_structured_output(Decision)
print("Policy Agent created.")
# Now, let's test the policy agent with two different states of our research process
print("\n--- Testing Policy Agent (Incomplete State) ---")
# First, a state where only Step 1 is complete.
plan_str = json.dumps([s.dict() for s in test_plan.steps])
incomplete_history = "Step 1 Summary: NVIDIA's 10-K states that the semiconductor industry is intensely competitive and subject to rapid technological change."
decision1 = policy_agent.invoke({"question": complex_query_adv, "plan": plan_str, "history": incomplete_history})
print(f"Decision: {decision1.next_action}, Justification: {decision1.justification}")
print("\n--- Testing Policy Agent (Complete State) ---")
# Second, a state where both Step 1 and Step 2 are complete.
complete_history = incomplete_history + "\nStep 2 Summary: In 2024, AMD launched its MI300X accelerator to directly compete with NVIDIA in the AI chip market, gaining adoption from major cloud providers."
decision2 = policy_agent.invoke({"question": complex_query_adv, "plan": plan_str, "history": complete_history})
print(f"Decision: {decision2.next_action}, Justification: {decision2.justification}")为了正确测试我们的策略代理,我们模拟了代理生命周期中的两个不同时刻。在第一个测试中,我们为其提供仅包含步骤1摘要的历史记录。在第二个测试中,我们为其提供步骤1和步骤2的摘要。
让我们来研究一下它在每种情况下的决策。
#### OUTPUT ####
Policy Agent created.
--- Testing Policy Agent (Incomplete State) ---
Decision: CONTINUE_PLAN, Justification: The research has only identified NVIDIA's competitive risks from the 10-K. It has not yet gathered the required external information about AMD's 2024 strategy, which is the next step in the plan.
--- Testing Policy Agent (Complete State) ---
Decision: FINISH, Justification: The research history now contains comprehensive summaries of both NVIDIA's stated competitive risks and AMD's recent AI chip strategy. All necessary information has been gathered to perform the final synthesis and answer the user's question.让我们来理解一下输出结果……
-
在不完整状态下,智能体正确识别出它缺少关于AMD战略的信息。它查看了自己的计划,发现下一步是使用网络搜索,于是正确地决定继续执行计划。
-
在完整状态下,在获得网络搜索的总结后,它再次分析了其历史记录。这一次,它认识到自己已经掌握了关于NVIDIA风险和AMD战略的所有关键信息。它正确地判定研究已经完成,是时候结束了。
有了这个策略代理,我们就构建了自主系统的大脑。最后一步是使用LangGraph将所有这些组件连接在一起,形成一个完整的、可执行的工作流程。
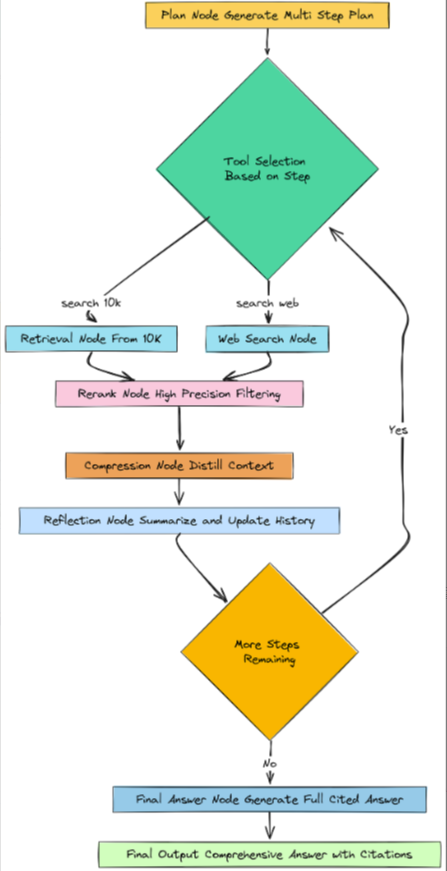
定义图节点
我们已经设计了所有这些酷炫的、专门的智能体。现在是时候将它们转化为我们工作流程的实际构建模块了。在 LangGraph 中,这些构建模块被称为节点。节点只是一个执行特定任务的 Python 函数。它将智能体的当前内存(RAGState)作为输入,执行其任务,然后返回一个包含对该内存的任何更新的字典。
我们将为我们的智能体需要采取的每一个主要步骤创建一个节点。
图形节点(作者: 法里德·汗 )
首先,我们需要一个简单的辅助函数。由于我们的智能体经常需要查看研究历史,我们希望有一种简洁的方式将past_steps列表格式化为可读的字符串。
# A helper function to format the research history for prompts
def get_past_context_str(past_steps: List[PastStep]) -> str:
# This takes the list of PastStep dictionaries and joins them into a single string.
# Each step is clearly labeled for the LLM to understand the context.
return "\\n\\n".join([f"Step {s['step_index']}: {s['sub_question']}\\nSummary: {s['summary']}" for s in past_steps])我们基本上是在创建一个实用工具,该工具将在我们的几个节点内部使用,以便为我们的提示提供历史背景信息。
现在来看我们的第一个实际节点:plan_node。这是我们代理推理的起点。它唯一的任务是调用我们的planner_agent,并填充我们plan字段中的RAGState。
# Node 1: The Planner
def plan_node(state: RAGState) -> Dict:
console.print("--- 🧠: Generating Plan ---")
# We call the planner_agent we created earlier, passing in the user's original question.
plan = planner_agent.invoke({"question": state["original_question"]})
rprint(plan)
# We return a dictionary with the updates for our RAGState.
# LangGraph will automatically merge this into the main state.
return {"plan": plan, "current_step_index": 0, "past_steps": []}此节点启动所有操作。它从状态中获取原始问题,获取计划,然后将当前步骤索引初始化为 0(从第一步开始),并清除过往步骤历史记录,以便进行新的运行。
接下来,我们需要实际去查找信息的节点。由于我们的规划器可以在两个工具之间进行选择,因此我们需要两个独立的检索节点。让我们从检索节点开始,该节点用于搜索我们内部的10-K文档。
# Node 2a: Retrieval from the 10-K document
def retrieval_node(state: RAGState) -> Dict:
# First, get the details for the current step in the plan.
current_step_index = state["current_step_index"]
current_step = state["plan"].steps[current_step_index]
console.print(f"--- 🔍: Retrieving from 10-K (Step {current_step_index + 1}: {current_step.sub_question}) ---")
# Use our query rewriter to optimize the sub-question for search.
past_context = get_past_context_str(state['past_steps'])
rewritten_query = query_rewriter_agent.invoke({
"sub_question": current_step.sub_question,
"keywords": current_step.keywords,
"past_context": past_context
})
console.print(f" Rewritten Query: {rewritten_query}")
# Get the supervisor's decision on which retrieval strategy is best.
retrieval_decision = retrieval_supervisor_agent.invoke({"sub_question": rewritten_query})
console.print(f" Supervisor Decision: Use `{retrieval_decision.strategy}`. Justification: {retrieval_decision.justification}")
# Based on the decision, execute the correct retrieval function.
if retrieval_decision.strategy == 'vector_search':
retrieved_docs = vector_search_only(rewritten_query, section_filter=current_step.document_section, k=config['top_k_retrieval'])
elif retrieval_decision.strategy == 'keyword_search':
retrieved_docs = bm25_search_only(rewritten_query, k=config['top_k_retrieval'])
else: # hybrid_search
retrieved_docs = hybrid_search(rewritten_query, section_filter=current_step.document_section, k=config['top_k_retrieval'])
# Return the retrieved documents to be added to the state.
return {"retrieved_docs": retrieved_docs}这个节点正在进行大量的智能工作。它不只是一个简单的检索器。它编排了一个小型管道:重写查询,向主管询问最佳策略,然后执行该策略。
现在,我们需要为另一个工具(即网络搜索)找到对应的节点。
# Node 2b: Retrieval from the Web
def web_search_node(state: RAGState) -> Dict:
# Get the details for the current step.
current_step_index = state["current_step_index"]
current_step = state["plan"].steps[current_step_index]
console.print(f"--- 🌐: Searching Web (Step {current_step_index + 1}: {current_step.sub_question}) ---")
# Rewrite the sub-question for a web search engine.
past_context = get_past_context_str(state['past_steps'])
rewritten_query = query_rewriter_agent.invoke({
"sub_question": current_step.sub_question,
"keywords": current_step.keywords,
"past_context": past_context
})
console.print(f" Rewritten Query: {rewritten_query}")
# Call our web search function.
retrieved_docs = web_search_function(rewritten_query)
# Return the results.
return {"retrieved_docs": retrieved_docs}这个网络搜索节点更简单,因为它不需要监管者,它只有一种搜索网络的方式。但它仍然使用我们强大的查询重写器,以确保搜索尽可能有效。
在我们(从任一来源)检索到文档后,我们需要运行我们的精确性和综合漏斗。我们将为每个阶段创建一个节点。首先是重排节点。
# Node 3: The Reranker
def rerank_node(state: RAGState) -> Dict:
console.print("--- 🎯: Reranking Documents ---")
# Get the current step's details.
current_step_index = state["current_step_index"]
current_step = state["plan"].steps[current_step_index]
# Call our reranking function on the documents we just retrieved.
reranked_docs = rerank_documents_function(current_step.sub_question, state["retrieved_docs"])
console.print(f" Reranked to top {len(reranked_docs)} documents.")
# Update the state with the high-precision documents.
return {"reranked_docs": reranked_docs}此节点接收检索到的文档(我们广泛召回的10个文档),并使用交叉编码器将其筛选为前3个,将结果存储在重排序后的文档中。
接下来,压缩节点将提取这3篇文档并进行提炼。
# Node 4: The Compressor / Distiller
def compression_node(state: RAGState) -> Dict:
console.print("--- ✂️: Distilling Context ---")
# Get the current step's details.
current_step_index = state["current_step_index"]
current_step = state["plan"].steps[current_step_index]
# Format the top 3 documents into a single string.
context = format_docs(state["reranked_docs"])
# Call our distiller agent to synthesize them into one paragraph.
synthesized_context = distiller_agent.invoke({"question": current_step.sub_question, "context": context})
console.print(f" Distilled Context Snippet: {synthesized_context[:200]}...")
# Update the state with the final, clean context.
return {"synthesized_context": synthesized_context}此节点是我们检索漏斗的最后一步。它接收重排序后的文档,并生成一个单一、简洁的合成上下文段落。
既然我们已经有了证据,就需要对其进行反思,并更新我们的研究历史。这是反思节点的工作。
# Node 5: The Reflection / Update Step
def reflection_node(state: RAGState) -> Dict:
console.print("--- : Reflecting on Findings ---")
# Get the current step's details.
current_step_index = state["current_step_index"]
current_step = state["plan"].steps[current_step_index]
# Call our reflection agent to summarize the findings.
summary = reflection_agent.invoke({"sub_question": current_step.sub_question, "context": state['synthesized_context']})
console.print(f" Summary: {summary}")
# Create a new PastStep dictionary with all the results from this step.
new_past_step = {
"step_index": current_step_index + 1,
"sub_question": current_step.sub_question,
"retrieved_docs": state['reranked_docs'], # We save the reranked docs for final citation
"summary": summary
}
# Append the new step to our history and increment the step index to move to the next step.
return {"past_steps": state["past_steps"] + [new_past_step], "current_step_index": current_step_index + 1}此节点是我们代理的簿记员。它调用reflection_agent来创建摘要,然后将当前研究周期的所有结果整齐地打包到一个new_past_step对象中。然后,它将此对象添加到past_steps列表中,并增加current_step_index,使代理为下一个循环做好准备。
最后,当研究完成后,我们需要一个最后的节点来生成最终答案。
# Node 6: The Final Answer Generator
def final_answer_node(state: RAGState) -> Dict:
console.print("--- ✅: Generating Final Answer with Citations ---")
# First, we need to gather all the evidence we've collected from ALL past steps.
final_context = ""
for i, step in enumerate(state['past_steps']):
final_context += f"\\n--- Findings from Research Step {i+1} ---\\n"
# We include the source metadata (section or URL) for each document to enable citations.
for doc in step['retrieved_docs']:
source = doc.metadata.get('section') or doc.metadata.get('source')
final_context += f"Source: {source}\\nContent: {doc.page_content}\\n\\n"
# We create a new prompt specifically for generating the final, citable answer.
final_answer_prompt = ChatPromptTemplate.from_messages([
("system", """You are an expert financial analyst. Synthesize the research findings from internal documents and web searches into a comprehensive, multi-paragraph answer for the user's original question.
Your answer must be grounded in the provided context. At the end of any sentence that relies on specific information, you MUST add a citation. For 10-K documents, use [Source: <section title>]. For web results, use [Source: <URL>]."""),
("human", "Original Question: {question}\n\nResearch History and Context:\n{context}")
])
# We create a temporary agent for this final task and invoke it.
final_answer_agent = final_answer_prompt | reasoning_llm | StrOutputParser()
final_answer = final_answer_agent.invoke({"question": state['original_question'], "context": final_context})
# Update the state with the final answer.
return {"final_answer": final_answer}这个最终答案节点是我们的压轴环节。它将过往步骤历史中每一步的所有高质量、重新排序的文档整合为一个庞大的上下文。然后,它使用专门的提示来指导我们强大的推理大语言模型将这些信息综合成一个全面的、多段落的答案,其中包括引用,从而成功地完成我们的研究过程。
在定义好所有节点后,我们现在已经拥有了智能体的所有构建模块。下一步是定义连接这些节点并控制图中数据流的“线路”。
定义条件边
所以,我们已经构建了所有的节点。我们有规划器、检索器、重排器、蒸馏器和反射器。可以把它们想象成一个房间里的专家集合。现在我们需要定义对话规则。谁在什么时候发言?我们如何决定下一步做什么?
这是边在语言图中的作用。简单边很直接,“在节点A之后,总是转到节点B”。但真正的智能来自于条件边。
条件边是一种函数,它查看代理的当前内存(RAGState)并做出决策,根据情况将工作流引导至不同路径。
我们的智能体需要两个关键的决策功能:
-
工具路由器(route_by_tool):计划制定后,此功能将查看计划的当前步骤,并决定是否将工作流发送到retrieve_10k节点或retrieve_web节点。
-
主控制循环(should_continue_node):这是最重要的一个。在每个研究步骤完成并进行反思后,此函数将调用我们的策略代理来决定是继续执行计划中的下一步,还是结束研究并生成最终答案。
首先,让我们构建简单的工具路由器。
# Conditional Edge 1: The Tool Router
def route_by_tool(state: RAGState) -> str:
# Get the index of the current step we are on.
current_step_index = state["current_step_index"]
# Get the full details of the current step from the plan.
current_step = state["plan"].steps[current_step_index]
# Return the name of the tool specified for this step.
# LangGraph will use this string to decide which node to go to next.
return current_step.tool这个函数非常简单,但至关重要。它就像一个总机。它从状态中读取当前步骤索引,在计划中找到对应的步骤,并返回其工具字段的值(该值将是"search_10k"或"search_web")。当我们连接图表时,我们将告诉它使用这个函数的输出来选择下一个节点。
现在我们需要创建一个函数来控制我们的智能体的主要推理循环。这就是我们的策略智能体发挥作用的地方。
# Conditional Edge 2: The Main Control Loop
def should_continue_node(state: RAGState) -> str:
console.print("--- 🚦: Evaluating Policy ---")
# Get the index of the step we are about to start.
current_step_index = state["current_step_index"]
# First, check our basic stopping conditions.
# Condition 1: Have we completed all the steps in the plan?
if current_step_index >= len(state["plan"].steps):
console.print(" -> Plan complete. Finishing.")
return "finish"
# Condition 2: Have we exceeded our safety limit for the number of iterations?
if current_step_index >= config["max_reasoning_iterations"]:
console.print(" -> Max iterations reached. Finishing.")
return "finish"
# A special case: If the last retrieval step failed to find any documents,
# there's no point in reflecting. It's better to just move on to the next step.
if state.get("reranked_docs") is not None and not state["reranked_docs"]:
console.print(" -> Retrieval failed for the last step. Continuing with next step in plan.")
return "continue"
# If none of the basic conditions are met, it's time to ask our Policy Agent.
# We format the history and plan into strings for the prompt.
history = get_past_context_str(state['past_steps'])
plan_str = json.dumps([s.dict() for s in state['plan'].steps])
# Invoke the policy agent to get its strategic decision.
decision = policy_agent.invoke({"question": state["original_question"], "plan": plan_str, "history": history})
console.print(f" -> Decision: {decision.next_action} | Justification: {decision.justification}")
# Based on the agent's decision, return the appropriate signal.
if decision.next_action == "FINISH":
return "finish"
else: # CONTINUE_PLAN
return "continue"这个should_continue_node函数是我们智能体控制流的认知核心。它在每次reflection_node之后运行。
-
它首先检查简单的、硬编码的停止条件。计划是否已没有步骤?我们是否已达到最大推理迭代次数安全限制?这些措施可防止代理无限期运行。
-
如果这些检查通过,它就会调用我们强大的策略代理。它会向策略代理提供所需的所有上下文信息:原始目标(问题)、完整的计划,以及到目前为止已完成事项的历史记录。
-
最后,它获取策略代理的结构化输出(继续计划或完成),并返回简单字符串"继续"或"完成"。LangGraph将使用此字符串来循环进行另一个研究周期,或继续执行最终答案节点。
现在我们已经定义了节点(专家)和条件边(对话规则),我们拥有了所需的一切。
现在是时候将所有这些部分组合成一个完整、可运行的状态图了。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 6
6 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)