ArkAPI技术解析:大模型时代的“智能流量调度器”
ArkAPI是基于云原生架构的企业级AI网关,采用控制面-数据面分离设计。通过智能路由系统实现多模型统一接入,支持基于性能、成本和负载的毫秒级路由决策。平台提供连接复用、智能缓存等优化技术,显著提升性能并降低API成本。具备零信任架构和"无存储"管道设计,确保数据全链路安全合规。同时构建了统一的模型抽象层,使企业无需代码改造即可灵活切换各类大模型,有效避免技术锁定。这些特性使ArkAPI成为企业构
从网络工程师的视角,重新思考企业AI调用架构
在当今的大模型时代,我们发现了一个有趣的现象:大多数企业都在关注“用哪个模型”,却很少思考“如何更好地使用模型”。今天我们从流量调度和系统优化的角度,分享ArkAPI如何成为大模型时代的“智能流量调度器”。
一、问题本质:我们真的需要直接连接每个模型吗?
1.1 网络架构的演进启示
回顾网络发展史,我们经历了从“直连”到“路由”的革命:
同样的演进正在AI领域重演。直接调用模型API,就像早期的网络直连,存在明显的局限性:
-
单点故障风险:一个服务商故障导致业务中断
-
资源利用率低:无法根据实时状况动态调整
-
成本控制困难:缺乏全局视角的优化能力
1.2 架构演进:从"点对点"到"控制面-数据面分离"
传统点对点架构因其固有的耦合性和管理复杂性,已无法适应多模型的企业环境。ArkAPI的核心架构借鉴了现代云原生理念,实现了"控制面"与"数据面"的清晰分离。
架构深度解析
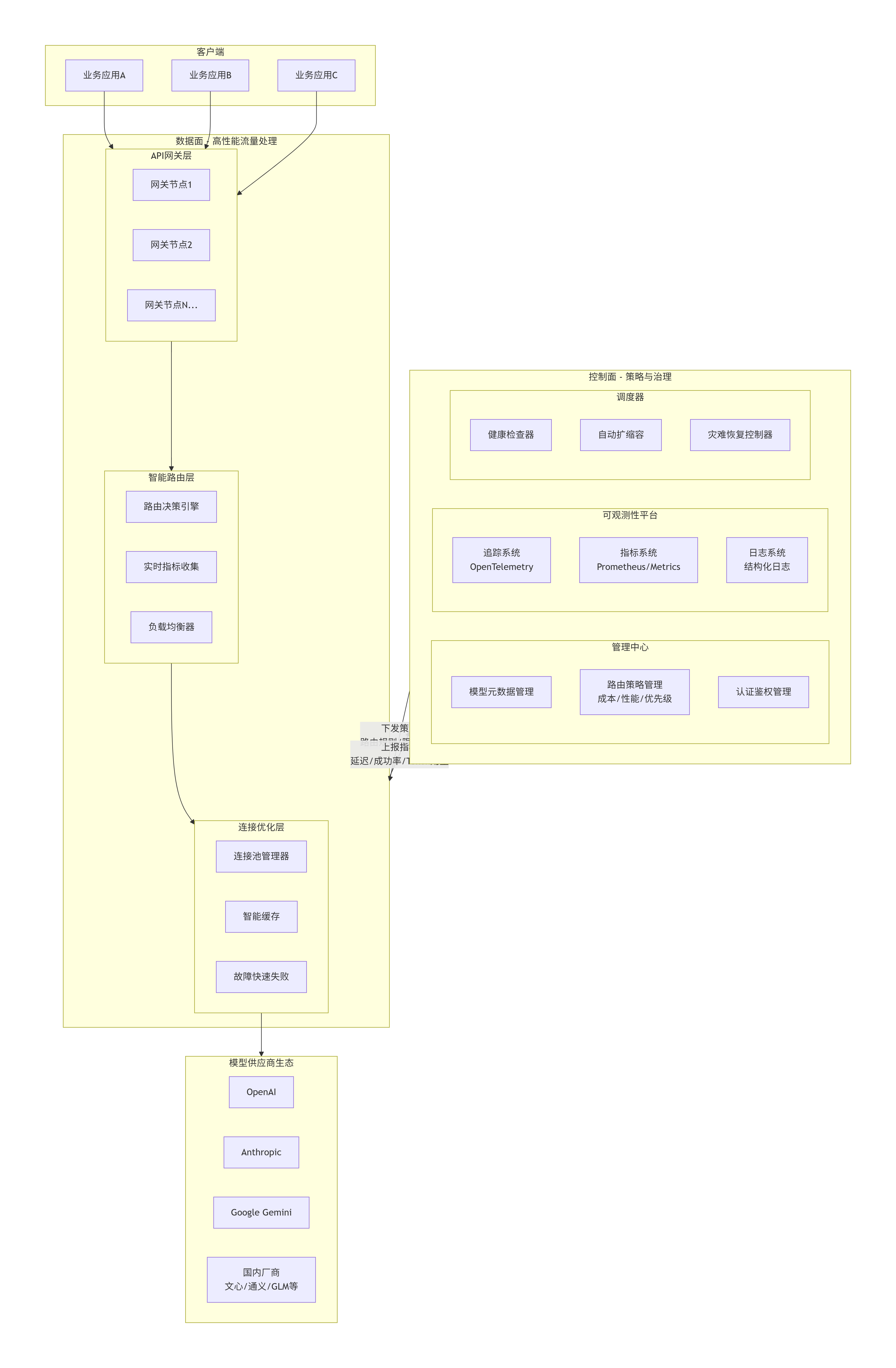
控制面(Control Plane)作为系统的大脑:
-
策略中枢:负责路由规则、限流策略、成本控制策略的管理与下发
-
可观测性:聚合所有数据面节点的指标数据,包括延迟、成功率、Token消耗等
-
智能调度:基于实时数据进行预测性调度和自动扩缩容
数据面(Data Plane)作为高性能执行层:
-
无状态网关集群:处理认证、鉴权、限流和协议转换
-
智能路由层:实现毫秒级的多维度路由决策
-
连接优化层:维护连接池,实现智能缓存和快速失败
二、核心技术特性深度解析
1. 智能路由:多目标优化算法
ArkAPI的路由决策是一个复杂的多目标优化过程:
class IntelligentRouter:
def __init__(self):
self.metrics_collector = MetricsCollector()
self.cost_optimizer = CostOptimizer()
self.performance_analyzer = PerformanceAnalyzer()
def make_routing_decision(self, request):
# 收集实时指标
realtime_metrics = self.metrics_collector.get_realtime_metrics()
# 多维度评分
scores = {
'cost': self._calculate_cost_score(request, realtime_metrics),
'performance': self._calculate_performance_score(request, realtime_metrics),
'reliability': self._calculate_reliability_score(realtime_metrics),
'compliance': self._check_compliance_requirements(request)
}
# 基于权重的决策算法
decision = self._weighted_decision_algorithm(scores, request.priority)
return decision
def _weighted_decision_algorithm(self, scores, priority):
# 根据业务优先级调整权重
weights = self._get_weights_by_priority(priority)
weighted_scores = {}
for provider, score_dict in scores.items():
total_score = sum(score_dict[dim] * weights[dim]
for dim in score_dict)
weighted_scores[provider] = total_score
return max(weighted_scores, key=weighted_scores.get)路由决策维度包括:
-
实时性能指标:基于历史数据的P95/P99延迟统计
-
成本最优计算:不同模型和渠道的Token成本优化
-
负载均衡:跨供应商的流量分发和容量预测
-
故障转移:基于健康检查的自动服务切换
2. 混合路由策略的经济性分析
基于对多个企业客户的实践,我们构建了精细化路由策略:
| 渠道类型 | 成本系数 | 稳定性 | 适用场景 | 路由策略 |
|---|---|---|---|---|
| 官方直连 | 1.0x | 99.99% | 核心业务、高价值场景 | 精准路由,质量优先 |
| Azure代理 | 0.7-0.9x | 99.95% | 合规要求、企业备份 | 区域性优化,合规优先 |
| 优化节点 | 0.3-0.5x | 99.9% | 内部工具、测试环境 | 成本优先,降级备用 |
| 国产模型 | 0.2-0.4x | 99.8% | 中文任务、成本敏感 | 场景适配,优势互补 |
实际效果数据:
-
总体API调用成本降低20-30%
-
高价值场景服务质量提升40%
-
非核心业务成本下降70%
3. 极致性能优化技术
连接复用优化:
class ConnectionManager:
def __init__(self):
self.connection_pools = {}
self.max_connections_per_endpoint = 100
self.connection_timeout = 30
def get_connection(self, endpoint):
if endpoint not in self.connection_pools:
self.connection_pools[endpoint] = ConnectionPool(
max_size=self.max_connections_per_endpoint,
timeout=self.connection_timeout
)
return self.connection_pools[endpoint].get_connection()智能缓存机制:
-
语义相似度缓存:基于向量相似度的请求去重
-
分层缓存策略:内存缓存 + 分布式缓存的多级架构
-
智能失效机制:基于业务特征和数据新鲜度要求
三、企业级安全与合规架构
1. 零信任安全模型
class ZeroTrustSecurity:
def __init__(self):
self.authenticator = Authenticator()
self.authorizer = Authorizer()
self.encryptor = Encryptor()
def process_request(self, request):
# 身份验证
identity = self.authenticator.verify_token(request.token)
# 权限检查
if not self.authorizer.check_permission(identity, request):
raise PermissionDeniedError("Insufficient permissions")
# 数据加密
encrypted_request = self.encryptor.encrypt(request.data)
return encrypted_request, identity2. "无存储"管道设计
-
传输中加密:全链路TLS 1.3加密
-
处理中隔离:内存级数据处理,无持久化存储
-
处理后清理:请求完成后立即清除内存数据
-
审计日志脱敏:敏感信息在日志中自动脱敏
四、技术方案对比分析
| 特性维度 | 直接调用原生API | 自建代理网关 | ArkAPI |
|---|---|---|---|
| 架构模式 | 点对点,高度耦合 | 简单的反向代理 | 控制面-数据面分离的云原生架构 |
| 路由能力 | 无,硬编码 | 基础路由 | 多维度智能路由(成本/性能/负载) |
| 可用性 | 依赖单一供应商 | 依赖自建基础设施 | 全局负载均衡与自动故障转移 |
| 可观测性 | 分散,难以聚合 | 基础日志 | 统一的指标、日志、追踪三位一体 |
| 数据安全 | 依赖供应商承诺 | 自建保障 | 端到端加密 + "无存储"管道设计 |
| 维护成本 | 低(初期)→ 高(后期) | 非常高 | 接近零运维,按需使用 |
五、面向未来的模型抽象层
ArkAPI最具前瞻性的设计在于构建了"模型抽象层",这意味着:
技术敏捷性提升
-
新模型接入时间从周级降至小时级
-
模型切换实现零代码修改
-
多模型并行测试成为标准能力
风险控制增强
-
避免供应商锁定风险
-
降低服务中断影响范围
-
增强技术选型的议价能力
六、实施路径与最佳实践
阶段化实施建议
第一阶段:评估规划(1-2周)
# 成本分析工具
def analyze_current_usage(api_logs):
cost_breakdown = {}
for log in api_logs:
provider = log['provider']
tokens = log['token_usage']
cost = calculate_cost(provider, tokens)
cost_breakdown[provider] = cost_breakdown.get(provider, 0) + cost
return cost_breakdown第二阶段:试点验证(2-4周)
-
非核心业务先行验证
-
性能基准测试和对比
-
故障恢复演练
第三阶段:全面推广(1-2月)
-
核心业务渐进式迁移
-
监控告警体系完善
-
团队培训和技术支持
结论
ArkAPI本质上是一个运行在AI模型之上的智能调度系统,它通过精妙的架构设计和深入的工程优化,将调用大模型这一行为从简单的网络请求,提升为了一个可管理、可观测、可优化、可保障的企业级服务。
对于追求生产环境高可用性、卓越性能、严格合规与总拥有成本优化的企业而言,采用ArkAPI这类中间件已不再是"可选项",而是构建稳健AI基础设施的必由之路。它让工程团队能够专注于创造业务价值,而非深陷于对接、维护和救火的泥潭。
欢迎体验ArkAPI带来的简单与高效
-
技术文档:提供清晰的接入指南,最快5分钟即可上手。
-
免费测试:立即申请试用,亲身感受“一条线”调用全球顶级AI模型的便捷。
希望这篇科普能帮您更好地理解ArkAPI。如果您有任何疑问,欢迎在评论区留言交流!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)