OPENAI-LLM模型优化总结
摘要:大模型优化的核心在于调整输出形式而非扩展知识边界,基座模型的能力决定最终上限。优化方法包括提示工程(低成本快速改善效果)、Few-shot Learning(辅助理解任务模式)、RAG(动态引入外部知识)和微调(规范输出风格),需按任务需求选择组合。其中RAG侧重输入优化,微调侧重输出优化,提示工程则是基础环节。实践建议优先尝试低成本方法,并根据业务场景权衡成本与效果,如客服可先用RAG补充
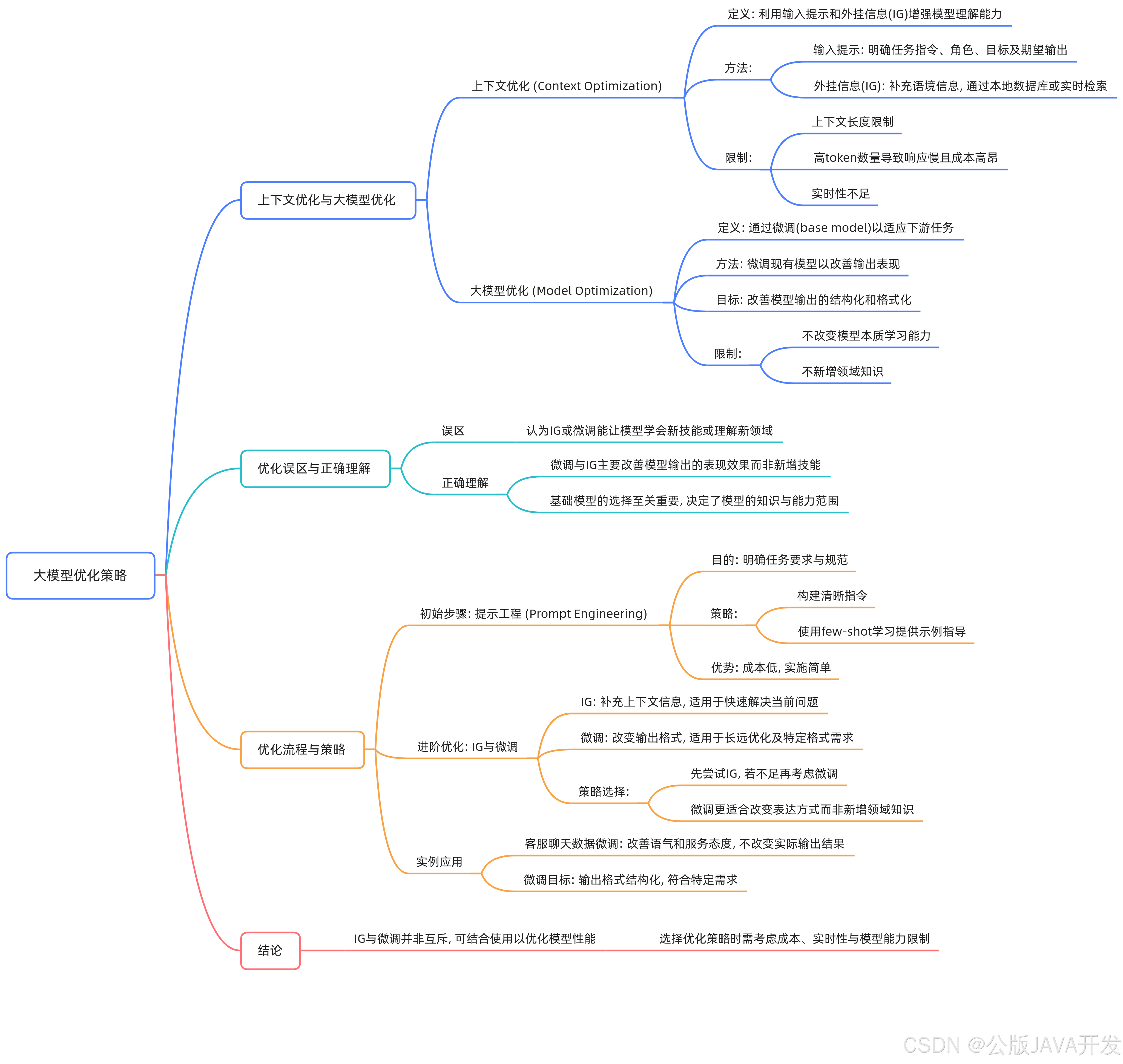
优化路径的核心原则与误区澄清
优化大模型在下游任务中的表现,核心在于调整输出形式而非扩展知识边界。基座模型的能力决定了优化的上限,无法通过微调或信息增强(IG)赋予其新领域的知识。
误区澄清:微调或RAG并非让模型“学会”新技能,而是优化其表达方式。例如,未经优化的回答可能零散,优化后可分点罗列、增加总结,使逻辑更清晰。
优化方法的选择与实施顺序
-
提示工程(Prompt Engineering)
明确指令内容、角色设定、输出格式等。通过示例展示输入输出结构,低成本快速改善效果。适用于模型对任务理解模糊或格式不符的场景。 -
Few-shot Learning
提供少量样本辅助模型理解任务模式,作为提示工程的进阶手段。 -
RAG(检索增强生成)
动态引入外部知识补充上下文,适合需要实时数据或专业库支持的场景。但受限于token长度和检索效率,可能影响响应速度与成本。 -
微调(Fine-tuning)
调整输出风格、语气或格式。例如统一客服对话的礼貌性,或定制结构化输出。无法让模型掌握基座中未训练过的知识(如少数民族语言)。
RAG与微调的协同关系
- RAG:侧重输入侧优化,通过检索丰富上下文理解。
- 微调:侧重输出侧优化,规范表达形式。
- 适用场景:
- RAG:需实时数据或长尾知识补充的任务(如最新政策查询)。
- 微调:需高度一致性输出的任务(如品牌客服话术)。
实践建议与案例参考
- 优先级:先优化提示工程,再逐步引入Few-shot、RAG或微调。
- 资源评估:微调需权衡成本,避免对基座能力不足的任务过度投入。
- 工具选择:RAG适合轻量化知识更新,微调适合长期风格固化。
案例:OpenAI工程师建议,客服场景中先用RAG引入FAQ库,再微调输出语气,而非试图教会模型未训练过的专业知识。
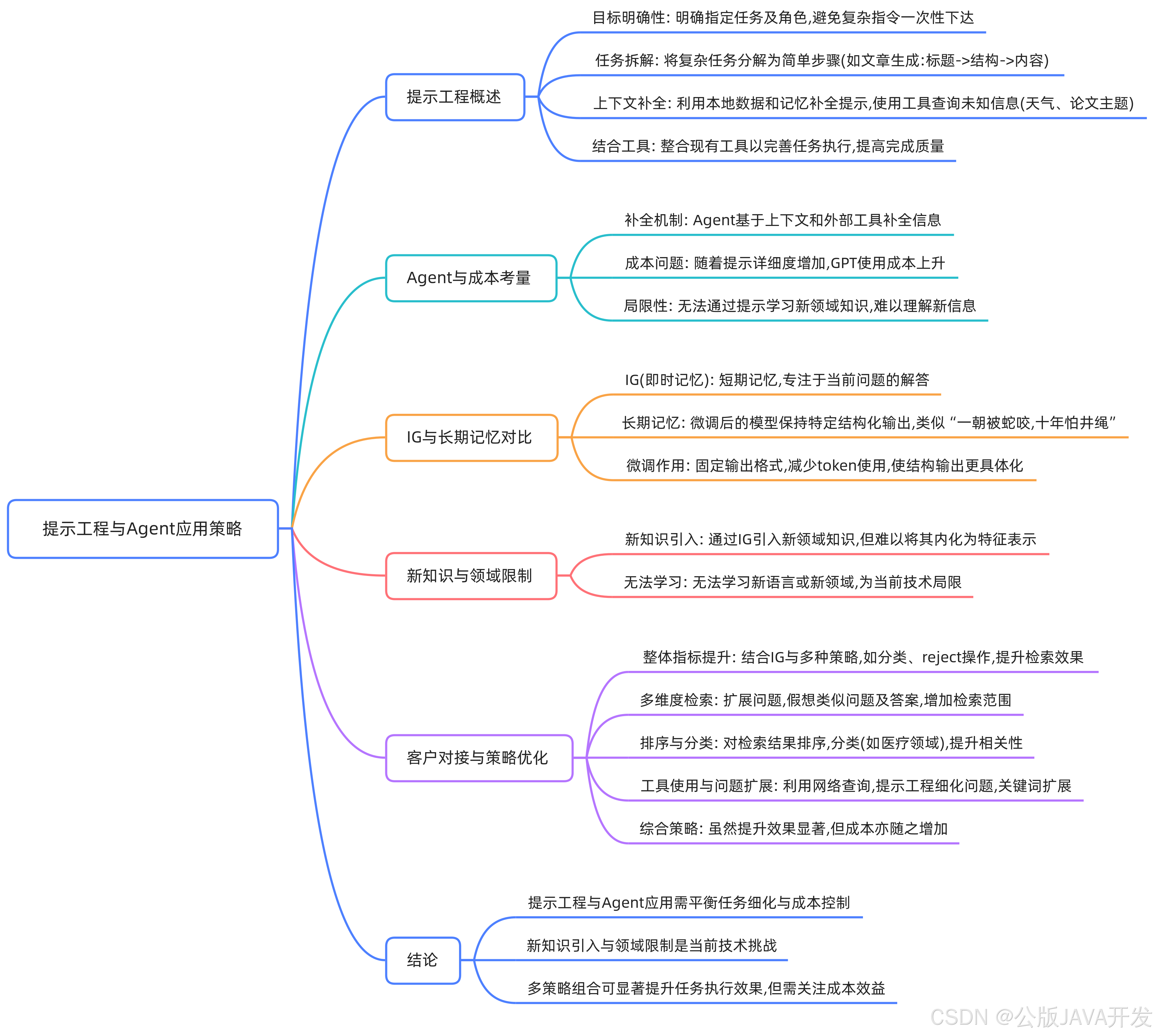
提示工程的核心方法
角色与任务定义
清晰界定模型在任务中的角色(如顾问、分析师)及具体输出要求(报告格式、回答长度)。避免模糊指令,明确任务边界。
复杂任务拆解
将多步骤任务分解为逻辑链。例如文章生成分为标题→大纲→段落填充,代码生成需先定义接口再实现函数。通过分阶段控制输出结构,减少模型偏差。
上下文补全与工具调用
本地数据与记忆补全
利用Agent的本地数据库或对话历史补充上下文。例如用户提及“上次方案”,自动关联前序对话中的项目细节。
外部工具集成
对模型未知信息(实时数据、专业文献),调用搜索引擎或API获取。通过工具链(如论文摘要提取→关键点分析)构建增强型输入。
适用性与限制分析
优势领域
- 优化已知知识输出:通过精细提示调整语气、格式或细节层次。
- 多工具协同:结合检索、计算等模块解决复杂问题(如数据分析+可视化)。
核心限制
- 知识边界固化:无法学习训练数据外的新领域(如小众文化习俗)。
- 成本非线性增长:复杂提示导致token消耗激增,长对话场景费用显著上升。
IG机制与优化策略
短期记忆功能
IG(信息收集)在单次交互中临时存储上下文(如用户偏好),引导模型聚焦当前任务,但不会持久影响模型参数。
长期记忆对比
通过微调使模型固化输出模式(如法律文书生成),减少提示中的示例需求,但需大量领域数据训练。
检索增强实践方案
问题扩展与假设生成
- 基于原始问题推导关联问题(“如何优化SQL查询”→“索引设计原则”)。
- 预生成假设答案作为检索关键词,扩大信息覆盖。
结果筛选与排序
- 分类过滤:医疗问题排除非医学文献。
- 多数据库路由:按问题类型选择知识库(客户数据→CRM系统)。
混合验证策略
本地缓存优先查询,缺失时触发外部检索。结合用户行为数据(搜索历史)扩展关键词,提升召回率。
成本与效果权衡
质量提升路径
IG扩展→多源检索→排序分类→工具验证,每步增加20-40%效果,但成本可能翻倍。需根据业务优先级选择关键环节(如高精度场景保留排序,降本场景减少工具调用)。
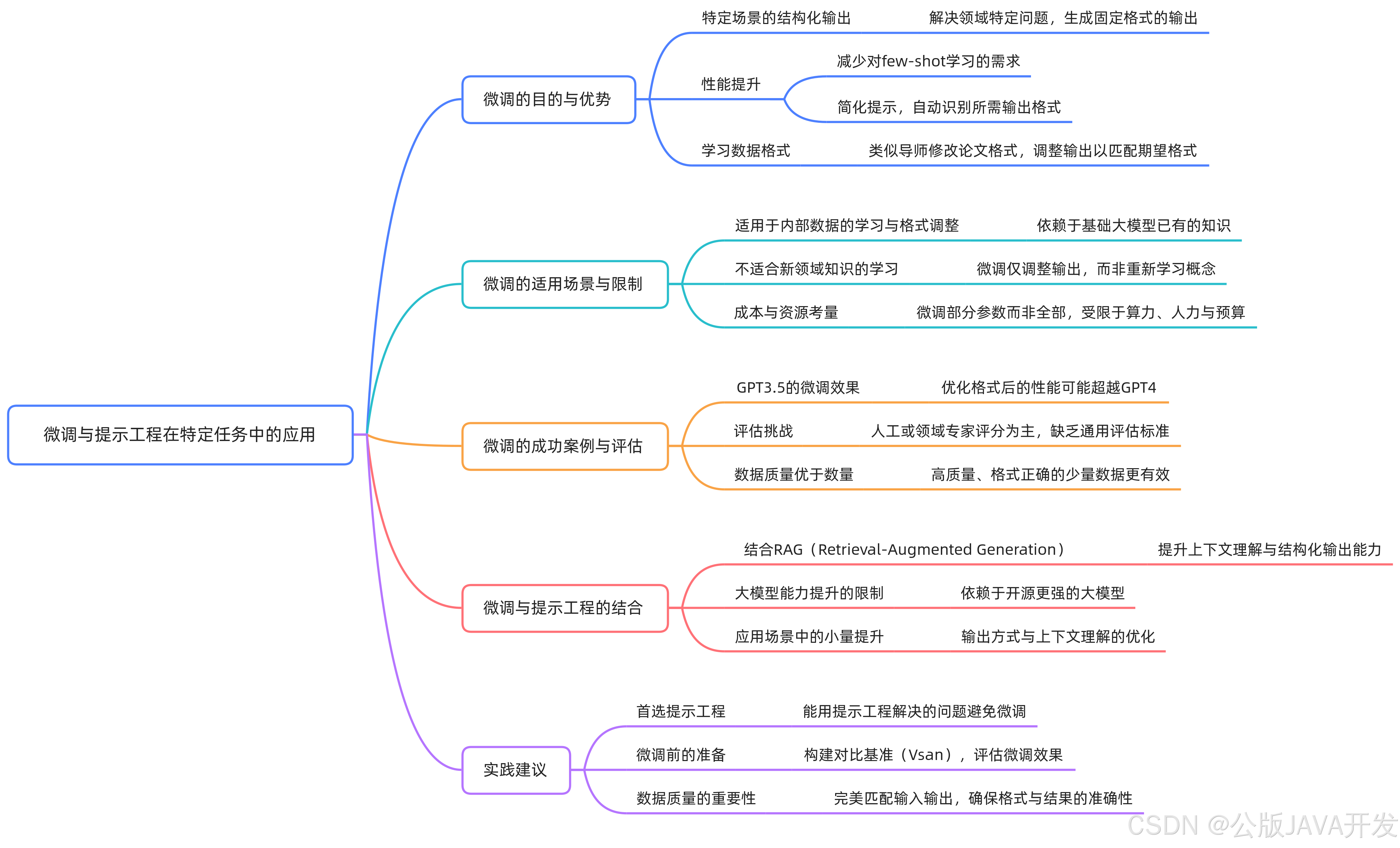
提示工程的核心方法
角色与任务定义
清晰界定模型在任务中的角色(如顾问、分析师)及具体输出要求(报告格式、回答长度)。避免模糊指令,明确任务边界。
复杂任务拆解
将多步骤任务分解为逻辑链。例如文章生成分为标题→大纲→段落填充,代码生成需先定义接口再实现函数。通过分阶段控制输出结构,减少模型偏差。
上下文补全与工具调用
本地数据与记忆补全
利用Agent的本地数据库或对话历史补充上下文。例如用户提及“上次方案”,自动关联前序对话中的项目细节。
外部工具集成
对模型未知信息(实时数据、专业文献),调用搜索引擎或API获取。通过工具链(如论文摘要提取→关键点分析)构建增强型输入。
适用性与限制分析
优势领域
- 优化已知知识输出:通过精细提示调整语气、格式或细节层次。
- 多工具协同:结合检索、计算等模块解决复杂问题(如数据分析+可视化)。
核心限制
- 知识边界固化:无法学习训练数据外的新领域(如小众文化习俗)。
- 成本非线性增长:复杂提示导致token消耗激增,长对话场景费用显著上升。
IG机制与优化策略
短期记忆功能
IG(信息收集)在单次交互中临时存储上下文(如用户偏好),引导模型聚焦当前任务,但不会持久影响模型参数。
长期记忆对比
通过微调使模型固化输出模式(如法律文书生成),减少提示中的示例需求,但需大量领域数据训练。
检索增强实践方案
问题扩展与假设生成
- 基于原始问题推导关联问题(“如何优化SQL查询”→“索引设计原则”)。
- 预生成假设答案作为检索关键词,扩大信息覆盖。
结果筛选与排序
- 分类过滤:医疗问题排除非医学文献。
- 多数据库路由:按问题类型选择知识库(客户数据→CRM系统)。
混合验证策略
本地缓存优先查询,缺失时触发外部检索。结合用户行为数据(搜索历史)扩展关键词,提升召回率。
成本与效果权衡
质量提升路径
IG扩展→多源检索→排序分类→工具验证,每步增加20-40%效果,但成本可能翻倍。需根据业务优先级选择关键环节(如高精度场景保留排序,降本场景减少工具调用)。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 30
30 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)