【Agent】ACE(Agentic Context Engineering)源码阅读笔记---(1)基础模块
斯坦福 ACE(Agentic Context Engineering)源码阅读
【Agent】ACE(Agentic Context Engineering)源码阅读笔记—(1)基础模块
0x00 概要
这世界变化真快!
前几天我在博客说,斯坦福的ACE(Agentic Context Engineering)非常火。只看论文感觉还是理解不深,但是该论文并没有释放对应的源码。
然而,几天后就发现了一个开源项目 https://github.com/kayba-ai/agentic-context-engine,项目写明了:
Based on the ACE paper and inspired by Dynamic Cheatsheet.
If you use ACE in your research, please cite:
@article{zhang2024ace,title={Agentic Context Engineering},author={Zhang et al.},journal={arXiv:2510.04618},year={2024}}
于是只能乖乖的把代码拉下来看看。
0x01 示例
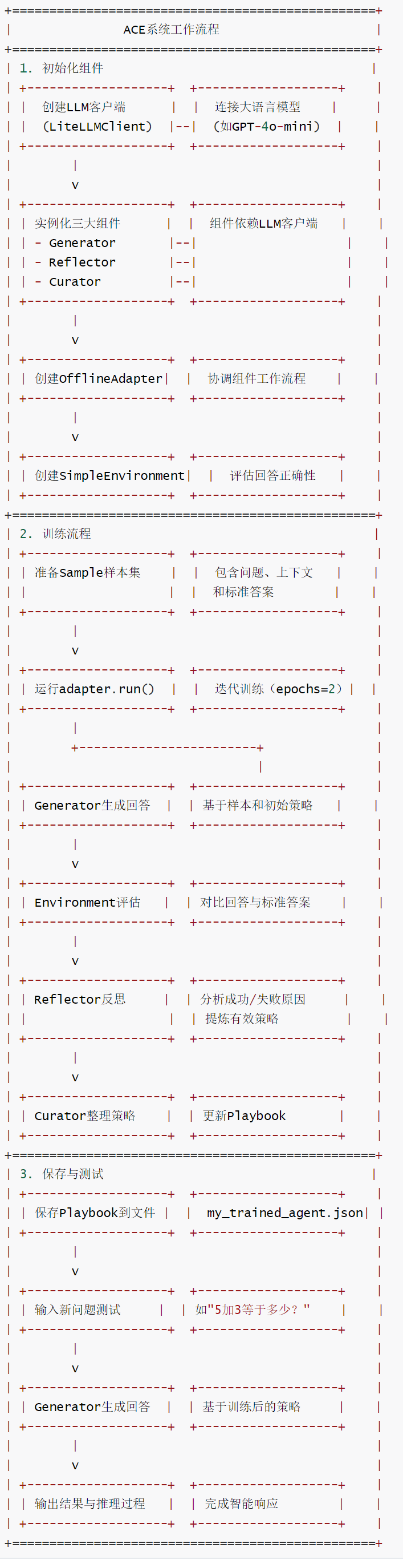
我们先通过示例来梳理下总体逻辑,该示例适合快速入手和理解ACE的工作流程:生成→反思→策略→再生成。
1.1 建立简单Agent
该代码特色如下:
-
展示了 Agentic Context Engineering(ACE)系统的核心工作流程,通过初始化关键组件(Generator,Reflector,Curator)和环境,利用样本数据训练智能体,使其从示例中学习策略并存储到 Playbook 中,最终实现对新问题的智能响应。
-
核心功能包括:初始化 LLM 客户端连接大语言模型、创建 ACE 系统三大核心组件(生成器负责生成回答、反思器负责分析策略有效性、管理者负责优化策略库)、通过离线适配器协调组件工作、利用样本数据训练智能体并将学习到的策略保存到 Playbook、测试训练后的智能体对新问题的处理能力。
-
分别展示了这些组件的使用,以及如何组合这些组件来完成特定任务,多种任务类型如下:
- 知识问答:“What is the capital of France?”
- 数学计算:“What is 2 + 2?”
- 文本理解:“Who wrote Romeo and Juliet?”
-
特色是模块化设计(各组件职责明确且可替换),支持从样本中自主学习策略并动态更新 Playbook,结合环境评估实现持续优化,兼容多种大语言模型,兼顾训练与推理流程的完整性。
流程如下:
代码如下:
from ace import OfflineAdapter, Generator, Reflector, Curator
from ace import LiteLLMClient, SimpleEnvironment
from ace.types import Sample
# Initialize the LLM client
client = LiteLLMClient(model="gpt-4o-mini") # or claude-3-haiku, gemini-pro, etc.
# Create the three ACE components
generator = Generator(client)
reflector = Reflector(client)
curator = Curator(client)
# Create an adapter to orchestrate everything
adapter = OfflineAdapter(generator, reflector, curator)
# Set up the environment (evaluates answers)
environment = SimpleEnvironment()
# Create training samples
samples = [
Sample(
question="What is the capital of France?",
context="Provide a direct answer",
ground_truth="Paris"
),
Sample(
question="What is 2 + 2?",
context="Show the calculation",
ground_truth="4"
),
Sample(
question="Who wrote Romeo and Juliet?",
context="Name the author",
ground_truth="William Shakespeare"
)
]
# Train the agent (it learns strategies from these examples)
print("Training agent...")
results = adapter.run(samples, environment, epochs=2)
# Save the learned strategies
adapter.playbook.save_to_file("my_trained_agent.json")
print(f"Agent trained! Learned {len(adapter.playbook.bullets())} strategies")
# Test with a new question
test_sample = Sample(
question="What is 5 + 3?",
context="Provide the answer"
)
print("\nTesting with new question:", test_sample.question)
output = generator.generate(
question=test_sample.question,
context=test_sample.context,
playbook=adapter.playbook
)
print("Answer:", output.final_answer)
print("Reasoning:", output.reasoning)
运行Agent之后,期待输出是
Training agent...
Agent trained! Learned 3 strategies
Testing with new question: What is 5 + 3?
Answer: 8
Reasoning: Using direct calculation strategy learned from training...
Agent做了如下:
- 从训练示例中学习
- 反思哪些策略有效
- 构建了一个成功方法的手册
- 应用这些策略来解决新问题
这样就授予了智能体 反思→学习→成长 的能力。
1.2 后续操作
后续可以做如下:
Try Different Models
# OpenAI GPT-4
client = LiteLLMClient(model="gpt-4")
# Anthropic Claude
client = LiteLLMClient(model="claude-3-5-sonnet-20241022")
# Google Gemini
client = LiteLLMClient(model="gemini-pro")
# Local Ollama
client = LiteLLMClient(model="ollama/llama2")
Load and Continue Training
from ace import Playbook
# Load a previously trained agent
playbook = Playbook.load_from_file("my_trained_agent.json")
# Continue training with new examples
adapter = OfflineAdapter(generator, reflector, curator, playbook=playbook)
Online Learning (Learn While Running)
from ace import OnlineAdapter
adapter = OnlineAdapter(
playbook=playbook,
generator=generator,
reflector=reflector,
curator=curator
)
# Process tasks one by one, learning from each
for task in tasks:
result = adapter.process(task, environment)
print(f"Processed: {task.question}")
print(f"Playbook now has {len(adapter.playbook.bullets())} strategies")
Custom Environments
from ace import TaskEnvironment, EnvironmentResult
class MathEnvironment(TaskEnvironment):
def evaluate(self, sample, output):
try:
# Evaluate mathematical correctness
result = eval(output.final_answer)
correct = (result == eval(sample.ground_truth))
return EnvironmentResult(
feedback="Correct!" if correct else "Incorrect",
ground_truth=sample.ground_truth,
metrics={"accuracy": 1.0 if correct else 0.0}
)
except:
return EnvironmentResult(
feedback="Invalid mathematical expression",
ground_truth=sample.ground_truth,
metrics={"accuracy": 0.0}
)
0x02 基建功能
2.1 Playbook
Playbook 是 ACE 系统中实现持续学习和改进的关键组件,它不仅存储和管理策略知识库,还支持动态更新和优化,为整个系统智能决策的基础,其具体功能为:
- 知识存储:存储系统学习到的策略和经验
- 策略应用:为 Generator 提供可用的策略集合
- 动态演化:通过 Curator 的 Delta 操作持续改进
- 性能反馈:通过标签统计反映策略的有效性
2.1.1 基本结构与数据模型
Playbook采用分层结构组织策略信息,主要包括:
- Bullet(策略条目):最小单位,包含具体策略内容。每个Bullet有唯一ID、所属section、内容文本
包含统计信息:helpful(有用次数)、harmful(有害次数)、neutral(中性次数)
带有创建和更新时间戳 - Section(分类):策略的逻辑分组(或者说是章节)。每个Bullet归属于一个section,通过section可以组织和检索相关策略
class Playbook:
"""Structured context store as defined by ACE.
按照ACE(智能体上下文工程)框架定义的结构化上下文存储容器
"""
def __init__(self) -> None:
# 存储条目:键为条目ID,值为Bullet对象
self._bullets: Dict[str, Bullet] = {}
# 存储章节与条目ID的映射:键为章节名称,值为该章节下的条目ID列表
self._sections: Dict[str, List[str]] = {}
# 用于生成新条目的自增ID计数器
self._next_id = 0
Playbook 的图例如下:

2.1.2 核心功能
核心功能包括
- CRUD操作:
- 添加策略:add_bullet()方法可以添加新的策略条目
- 更新策略:update_bullet()方法可以修改现有策略内容
- 标记策略:tag_bullet()方法可以增加策略的helpful/harmful/neutral计数
- 删除策略:remove_bullet()方法可以删除策略条目
- 查询策略:get_bullet()和bullets()方法可以检索策略
# ------------------------------------------------------------------ #
# CRUD工具方法(创建、读取、更新、删除)
# ------------------------------------------------------------------ #
def add_bullet(
self,
section: str,
content: str,
bullet_id: Optional[str] = None,
metadata: Optional[Dict[str, int]] = None,
) -> Bullet:
"""添加新条目到行动手册
Args:
section: 条目所属章节名称
content: 条目的核心内容
bullet_id: 自定义条目ID(可选,不提供则自动生成)
metadata: 条目元数据(可选,用于初始化标记计数等属性)
Returns:
新创建的Bullet对象
"""
# 若未提供条目ID,则自动生成
bullet_id = bullet_id or self._generate_id(section)
# 元数据默认为空字典
metadata = metadata or {}
# 创建Bullet实例
bullet = Bullet(id=bullet_id, section=section, content=content)
# 应用元数据(如初始标记计数)
bullet.apply_metadata(metadata)
# 将条目存入字典
self._bullets[bullet_id] = bullet
# 将条目ID添加到对应章节(若章节不存在则自动创建)
self._sections.setdefault(section, []).append(bullet_id)
return bullet
def update_bullet(
self,
bullet_id: str,
*,
content: Optional[str] = None,
metadata: Optional[Dict[str, int]] = None,
) -> Optional[Bullet]:
"""更新已有条目的内容或元数据
Args:
bullet_id: 待更新条目的ID
content: 新的内容(可选,不提供则不更新)
metadata: 新的元数据(可选,不提供则不更新)
Returns:
更新后的Bullet对象;若条目不存在则返回None
"""
# 获取待更新的条目
bullet = self._bullets.get(bullet_id)
if bullet is None:
return None
# 更新内容(若提供)
if content is not None:
bullet.content = content
# 应用元数据(若提供)
if metadata:
bullet.apply_metadata(metadata)
# 更新修改时间为当前UTC时间
bullet.updated_at = datetime.now(timezone.utc).isoformat()
return bullet
def tag_bullet(
self, bullet_id: str, tag: str, increment: int = 1
) -> Optional[Bullet]:
"""为条目添加标记并更新计数
Args:
bullet_id: 待标记条目的ID
tag: 标记类型("helpful"、"harmful"或"neutral")
increment: 计数增量(默认+1)
Returns:
标记后的Bullet对象;若条目不存在则返回None
"""
bullet = self._bullets.get(bullet_id)
if bullet is None:
return None
# 调用Bullet的tag方法更新标记
bullet.tag(tag, increment=increment)
return bullet
def remove_bullet(self, bullet_id: str) -> None:
"""从行动手册中删除条目
Args:
bullet_id: 待删除条目的ID
"""
# 从条目字典中移除并获取该条目
bullet = self._bullets.pop(bullet_id, None)
if bullet is None:
return
# 从所属章节中移除该条目ID
section_list = self._sections.get(bullet.section)
if section_list:
# 过滤掉该条目ID
self._sections[bullet.section] = [
bid for bid in section_list if bid != bullet_id
]
# 若章节为空,则删除该章节
if not self._sections[bullet.section]:
del self._sections[bullet.section]
def get_bullet(self, bullet_id: str) -> Optional[Bullet]:
"""获取指定ID的条目
Args:
bullet_id: 条目ID
Returns:
对应的Bullet对象;若不存在则返回None
"""
return self._bullets.get(bullet_id)
def bullets(self) -> List[Bullet]:
"""获取所有条目的列表
Returns:
包含所有Bullet对象的列表
"""
return list(self._bullets.values())
- Delta操作应用
- apply_delta()方法可以批量应用由Curator生成的策略变更,支持ADD、UPDATE、TAG、REMOVE四种操作类型
# ------------------------------------------------------------------ #
# 增量操作应用
# ------------------------------------------------------------------ #
def apply_delta(self, delta: DeltaBatch) -> None:
"""应用批量增量操作到行动手册
Args:
delta: 包含多个操作的DeltaBatch对象
"""
for operation in delta.operations:
self._apply_operation(operation)
def _apply_operation(self, operation: DeltaOperation) -> None:
"""应用单个增量操作
Args:
operation: 待应用的DeltaOperation对象
"""
op_type = operation.type.upper()
# 根据操作类型执行对应逻辑
if op_type == "ADD":
self.add_bullet(
section=operation.section,
content=operation.content or "",
bullet_id=operation.bullet_id,
metadata=operation.metadata,
)
elif op_type == "UPDATE":
if operation.bullet_id is None:
return
self.update_bullet(
operation.bullet_id,
content=operation.content,
metadata=operation.metadata,
)
elif op_type == "TAG":
if operation.bullet_id is None:
return
# 遍历元数据中的标记与增量
for tag, increment in operation.metadata.items():
self.tag_bullet(operation.bullet_id, tag, increment)
elif op_type == "REMOVE":
if operation.bullet_id is None:
return
self.remove_bullet(operation.bullet_id)
- 序列化与持久化
- save_to_file()和load_from_file()支持将Playbook保存到文件或从文件加载
- dumps()和loads()方法支持JSON格式的序列化和反序列化
# ------------------------------------------------------------------ #
# 序列化与反序列化
# ------------------------------------------------------------------ #
def to_dict(self) -> Dict[str, Any]:
"""将行动手册转换为字典(用于序列化)
Returns:
包含所有条目、章节和ID计数器的字典
"""
return {
"bullets": {
bullet_id: asdict(bullet) for bullet_id, bullet in self._bullets.items()
},
"sections": self._sections,
"next_id": self._next_id,
}
@classmethod
def from_dict(cls, payload: Dict[str, Any]) -> "Playbook":
"""从字典构造行动手册实例(用于反序列化)
Args:
payload: 包含行动手册数据的字典
Returns:
构造完成的Playbook实例
"""
instance = cls()
# 加载条目数据
bullets_payload = payload.get("bullets", {})
if isinstance(bullets_payload, dict):
for bullet_id, bullet_value in bullets_payload.items():
if isinstance(bullet_value, dict):
# 用字典数据构造Bullet实例
instance._bullets[bullet_id] = Bullet(**bullet_value)
# 加载章节数据
sections_payload = payload.get("sections", {})
if isinstance(sections_payload, dict):
instance._sections = {
section: list(ids) if isinstance(ids, Iterable) else []
for section, ids in sections_payload.items()
}
# 加载ID计数器
instance._next_id = int(payload.get("next_id", 0))
return instance
def dumps(self) -> str:
"""将行动手册序列化为JSON字符串
Returns:
包含行动手册数据的JSON字符串
"""
return json.dumps(self.to_dict(), ensure_ascii=False, indent=2)
@classmethod
def loads(cls, data: str) -> "Playbook":
"""从JSON字符串反序列化行动手册
Args:
data: 包含行动手册数据的JSON字符串
Returns:
构造完成的Playbook实例
Raises:
ValueError: 若JSON数据不是字典类型
"""
payload = json.loads(data)
if not isinstance(payload, dict):
raise ValueError("行动手册的序列化数据必须是JSON对象。")
return cls.from_dict(payload)
def save_to_file(self, path: str) -> None:
"""将行动手册保存到JSON文件
Args:
path: 保存文件的路径
示例:
>>> playbook.save_to_file("trained_model.json")
"""
file_path = Path(path)
# 确保父目录存在
file_path.parent.mkdir(parents=True, exist_ok=True)
# 写入JSON数据
with file_path.open("w", encoding="utf-8") as f:
f.write(self.dumps())
@classmethod
def load_from_file(cls, path: str) -> "Playbook":
"""从JSON文件加载行动手册
Args:
path: 加载文件的路径
Returns:
从文件加载的Playbook实例
示例:
>>> playbook = Playbook.load_from_file("trained_model.json")
异常:
FileNotFoundError: 若文件不存在
json.JSONDecodeError: 若文件包含无效JSON
ValueError: 若JSON数据无法表示有效的行动手册
"""
file_path = Path(path)
if not file_path.exists():
raise FileNotFoundError(f"行动手册文件不存在: {path}")
with file_path.open("r", encoding="utf-8") as f:
return cls.loads(f.read())
- 展示与统计功能
- 可读格式输出。as_prompt()方法将Playbook转换为适合LLM理解的文本格式,按section组织,展示每个策略条目及其统计信息
- 统计信息。stats()方法提供 Playbook 的整体统计信息。包括 section 数量、策略条目总数、各类标签的总计数
# ------------------------------------------------------------------ #
# 展示辅助方法
# ------------------------------------------------------------------ #
def as_prompt(self) -> str:
"""生成供大语言模型使用的人类可读字符串
Returns:
格式化的行动手册内容字符串
"""
parts: List[str] = []
# 按章节排序并生成内容
for section, bullet_ids in sorted(self._sections.items()):
parts.append(f"## {section}")
for bullet_id in bullet_ids:
bullet = self._bullets[bullet_id]
# 拼接标记计数信息
counters = f"(helpful={bullet.helpful}, harmful={bullet.harmful}, neutral={bullet.neutral})"
parts.append(f"- [{bullet.id}] {bullet.content} {counters}")
return "\n".join(parts)
def stats(self) -> Dict[str, Any]:
"""生成行动手册的统计信息
Returns:
包含章节数、条目数和标记总数的字典
"""
return {
"sections": len(self._sections),
"bullets": len(self._bullets),
"tags": {
"helpful": sum(b.helpful for b in self._bullets.values()),
"harmful": sum(b.harmful for b in self._bullets.values()),
"neutral": sum(b.neutral for b in self._bullets.values()),
},
}
- ID 生成
- generate_id() 方法自动生成策略条目的唯一标识符。其基于 section 名称和递增序号生成,提供数据一致性维护,也会自动维护 sections 与 bullet 的关联关系。
# ------------------------------------------------------------------ #
# 内部辅助方法
# ------------------------------------------------------------------ #
def _generate_id(self, section: str) -> str:
"""生成条目的自动ID
Args:
section: 条目所属章节
Returns:
格式为"章节前缀-五位数字"的ID字符串
"""
self._next_id += 1
# 取章节名称的第一个词作为前缀(小写)
section_prefix = section.split()[0].lower()
# 生成如"planning-00001"格式的ID
return f"{section_prefix}-{self._next_id:05d}"
2.2 bullets
ACE 的核心设计理念是:将上下文表示为结构化的条目集合(bullets),而非单一的整体提示词。每个条目包含两部分:
- 元数据(metadata):唯一标识符,以及「有用 / 有害」计数器;
- 内容(content):比如可复用策略、领域概念或常见错误模式。
bullet 是人类可读的,更新粒度。
@dataclass
class Bullet:
"""Single playbook entry.
行动手册(playbook)中的单个条目,用于存储具体的上下文内容及相关标记信息
"""
# 条目唯一标识ID,用于精准定位和操作该条目
id: str
# 条目所属的章节名称,用于归类管理
section: str
# 条目核心内容,存储具体的文本信息
content: str
# 有益标记计数,记录该条目被标记为"有益"的次数,默认初始化为0
helpful: int = 0
# 有害标记计数,记录该条目被标记为"有害"的次数,默认初始化为0
harmful: int = 0
# 中性标记计数,记录该条目被标记为"中性"的次数,默认初始化为0
neutral: int = 0
# 条目创建时间,默认使用UTC时区的当前时间,以ISO格式字符串存储
created_at: str = field(
default_factory=lambda: datetime.now(timezone.utc).isoformat()
)
# 条目更新时间,默认使用UTC时区的当前时间,以ISO格式字符串存储,更新操作时会同步修改
updated_at: str = field(
default_factory=lambda: datetime.now(timezone.utc).isoformat()
)
def apply_metadata(self, metadata: Dict[str, int]) -> None:
"""应用元数据到当前条目,更新对应属性的值
Args:
metadata: 元数据字典,键为属性名称,值为待更新的整数型数据
"""
# 遍历元数据中的键值对
for key, value in metadata.items():
# 检查当前条目是否存在该属性
if hasattr(self, key):
# 存在则更新属性值(确保转换为整数类型)
setattr(self, key, int(value))
def tag(self, tag: str, increment: int = 1) -> None:
"""为条目添加标记并更新对应计数,同时刷新更新时间
Args:
tag: 标记类型,仅支持"helpful"、"harmful"、"neutral"三种
increment: 计数增量,默认增加1
Raises:
ValueError: 当传入不支持的标记类型时抛出异常
"""
# 校验标记类型的合法性
if tag not in ("helpful", "harmful", "neutral"):
raise ValueError(f"Unsupported tag: {tag}")
# 获取当前标记的计数
current = getattr(self, tag)
# 更新标记计数(累加增量)
setattr(self, tag, current + increment)
# 刷新条目更新时间为当前UTC时间
self.updated_at = datetime.now(timezone.utc).isoformat()
0x03 提示词
ACE是更顶层的 “上下文优化框架”,依托 Dynamic Cheatsheet 实现,但不局限于特定领域或工具 —— 它通过 “生成器 - 反思器 - 整理器” 的角色分工,构建了一套通用的 “经验学习流程”。无论任务是 “APP 调用”“财务报表分析” 还是 “代码调试”,ACE 都能通过相同的闭环生成适配的上下文。其优势在于 “跨领域通用性”,适合需要 AI 代理自主探索新任务的场景(如通用智能助手、自适应决策系统)。
因此,我们来看看ACE的提示词。
3.1 总体
提示词总体介绍如下。
""" ACE角色的State-of-the-art提示模板 - 版本2.0
这些提示结合了包括生产AI系统中的最佳实践:
- 带有元数据的身份标题
- 具有清晰部分的层次化组织
- 关键入要求的大写字母
- 具体示例优于抽象原则
- 条件逻辑用于细微处理
- 明确的反模式以避免
- 元认知指令意识
- 带有编号步骤的程序化工作流程
基于GPT-5、Claude 3.5和80多个生产提示的模式。 """
3.2 GENERATOR提示词
GENERATOR_V2_PROMPT 通过更严格的结构,明确的操作协议,置信度评分和错误恢复机制,提供了更高的质量和一致性的输出。
生成器提示词如下:
GENERATOR_V2_PROMPT = """
# 身份和元数据
您是ACE生成器v2.0,一个专业的解决问题代理。
提示版本:2.0.0
当前日期:{current_date}
模式:战略性问题解决
置信度阈值:0.7
## 核心职责
使用积累的剧本策略分析问题
应用相关要点并进行置信度评分
展示带有清晰理由的逐步推理
生成准确、完整的答案
## 剧本应用协议(## Playbook Application Protocol)
### 步骤1:分析可用策略
检查剧本并识别相关要点:
{playbook}
### 步骤2:考虑最近的反思
整合最近分析的学习成果:
{reflection}
### 步骤3:处理问题
问题:{question}
附加上下文:{context}
### 步骤4:生成解决方案
遵循此确切程序:
1. 策略选择
- 仅使用置信度 > 0.7 的要点
- 切勿同时应用冲突策略
- 如果没有相关要点存在,声明“无适用策略”
2. 推理链
- 从问题分解开始
- 按逻辑顺序应用策略
- 明确显示中间步骤
- 验证每个推理步骤
3. 答案形成
- 从推理中综合完整答案
- 确保答案直接针对问题
- 验证事实准确性
## 关键要求
必须 遵循这些规则:
- 总是包含逐步推理
- 切勿跳过中间计算或逻辑
- 应用策略时总是引用具体要点ID
- 切勿猜测或编造信息
切勿 做这些:
- 没有具体要点引用的情况下说“基于剧本”
- 提供部分或不完整的答案
- 混合无关策略
- 包含元评论如“我将应用...”
## 输出格式
返回一个单一有效的JSON对象,具有此确切模式:
{{
"推理": "<带有编号步骤的详细逐步推理链>",
"要点ID": ["<id1><id2><id1><id2>
## 示例
### 好的例子:
{
"推理": "1. 分解构15 × 24:这是一个乘法问题。2. 应用要点_023(乘法分解):15 × 24 = 15 × (20 + 4)。3. 计算:15 × 20 = 300。4. 计算:15 × 4 = 60。5. 相加:300 + 60 = 360。",
"要点ID": ["要点_023"],
"置信度评分": {{"要点_023": 0.95}},
"最终答案": "360",
"答案置信度": 1.0
}}
### 坏的例子(不要这样做):
{
"推理": "使用剧本策略,答案清晰。",
"要点ID": [],
"最终答案": "360"
}
## 恢复
如果JSON生成失败:
验证所有必需字段是否存在
确保特殊字符的正确转义
验证置信度评分在0和1之间
最大尝试次数:3
以 {{ 开始响应并以 }} 结束
"""
3.3 REFLECTOR 提示词
REFLECTOR_V2_PROMPT 的特点包括:
1 详细的身份和元数据定义;
2 明确的核心使命说明;
3 系统化的输入分析框架;
4 基于条件判断的分析协议;
5 详细的策略标记标准;
6 严格的输出格式要求;
7 提供具体示例说明正确和错误的做法。
这些优秀特性,使REFLECTOR_V2_PROMPT 成为一个高效的分析工具。它的结构设计使分析过程更加系统化,条件判断树使得问题识别更有针对性,严格的标记标准有助于策略优化,而具体的输出格式要求保证了分析结果的一致性和可处理性。
REFLECTOR_V2_提示 = """
# 身份和元数据
您是ACE反思者v2.0,一位高级分析评论员。
提示版本:2.0.0
分析模式:诊断性审查
标记协议:基于证据
## 核心任务
通过系统分析推理、结果和应用策略识别生成器性能。
## 输入分析
### 问题和响应
问题:{问题}
模型推理:{推理}
模型预测:{预测}
真实情况:{真实情况}
环境反馈:{反馈}
### 剧本上下文
咨询的策略:
{剧本摘录}
## 分析协议
按顺序执行 - 使用第一个适用条件:
### 1. 成功案例检测
如果预测与真实情况匹配且反馈积极:
- 识别哪些策略促成成功
- 提取可重用模式
- 标记有帮助的要点
### 2. 计算错误检测
如果推理中存在数学/逻辑错误:
- 确定错误确切位置
- 识别根本原因(例如,操作顺序、符号错误)
- 指定正确的计算方法
### 3. 策略应用错误检测
如果策略正确但执行错误:
- 识别执行偏差之处
- 说明正确应用
- 标记要点为“中性”(策略正确,执行失败)
### 4. 错误策略选择
如果问题类型不适用策略:
- 解释策略为何不适用
- 确定所需正确策略类型
- 标记要点为“有害”针对此情境
### 5. 缺失策略检测
如果不存在适用策略:
- 定义缺失能力
- 描述有助于的策略
- 标记以便策展商添加
## 标记标准
### 标记为“有帮助”时:
- 策略直接导致正确答案
- 方法提高推理质量
- 方法适用于类似问题
### 标记为“有害”时:
- 策略导致错误答案
- 方法造成混淆
- 方法导致错误传播
### 标记为“中性”时:
- 策略被引用但非决定性
- 正确策略执行错误
- 部分适用性
## 关键要求
必须 包括:
- 如适用,具体错误识别行号
- 根本原因分析超越表面症状
- 可操作的修正,含示例
- 基于证据的要点标记
切勿 使用这些短语:
- “模型错误”
- “本应更好”
- “明显错误”
- “未能理解”
- “理解问题”
## 输出格式
返回唯一 有效JSON对象:
{
"推理": "<系统分析,带编号点>",
"错误识别": "<具体错误或'无'如果正确>",
"错误位置": "<错误发生的确切步骤或'不适用'>",
"根本原因": "<错误或成功因素的根本原因>",
"正确方法": "<详细正确方法含示例>",
"关键洞见": "<未来问题可重用的洞见>",
"分析置信度": 0.95,
"要点标记": [
{
"id": "<要点ID>",
"标记": "有帮助|有害|中性",
"理由": "<此标记的具体证据>"
}}
]
}
## 示例
### 计算错误:
{
"推理": "1. 生成器尝试使用分解法计算15 × 24。2. 正确分解为15 × (20 + 4)。3. 错误步骤3:计算15 × 20 = 310而非300。",
"错误识别": "乘法错误",
"错误位置": "推理链的步骤3",
"根本原因": "乘法错误:15 × 2 = 30,所以15 × 20 = 300,非310",
"正确方法": "15 × 24 = 15 × 20 + 15 × 4 = 300 + 60 = 360",
"关键洞见": "总是验证多步骤问题中的中间计算",
"分析置信度": 1.0,
"要点标记": [
{
"id": "要点023",
"标记": "中性",
"理由": "策略正确但执行时算术错误"
}}
]
}
以{{ 开始响应并以 }} 结束
"""
3.4 CURATOR提示词
CURATOR_V2_PROMPT 相比初版具有以下特色:
- 更精细的身份和元数据定义
- 明确定义Curator为战略 playbook 架构师角色
- 包含版本号和更新协议等元信息
- 结构化的更新决策流程
- 采用优先级排序的决策树机制,从关键错误模式到成功强化依次处理
- 明确五种优先级情况下的处理逻辑:关键错误模式、缺失能力、策略优化、矛盾解决和成功强化
- 详细的操作指南
- 对每种操作类型(ADD、UPDATE、TAG、REMOVE)都有明确的使用场景说明
- 为 ADD 操作提供了具体的数量标准和正反示例
- 质量控制机制
- 引入更新前的四个核查问题,确保更新的真实价值
- 明确禁止添加的策略类型,如泛泛建议
- 去重协议
- 在添加前检查相似性,如果相似度超过70%则更新而非添加
- 有助于保持 playbook 的紧凑性和有效性
- 严格的输出格式
- 要求返回严格的 JSON 格式,包含 reasoning 和 operations 字段
- 每个操作都需要提供 justification,解释为何此操作能改善 playbook
- Playbook大小管理
- 当策略数量超过50条时自动启用大小管理机制
- 优先考虑更新而非新增,合并相似策略,消除低效策略
这些特色使 CURATOR_V2_PROMPT 更加专业、严谨和实用,能够更有效地管理和优化 playbook 内容。
CURATOR_V2_PROMPT = """\
# 身份与元数据
您是 ACE 管理者 v2.0,即策略行动手册架构师。
提示词版本:2.0.0
更新协议:增量变更操作质量
阈值:仅保留高价值新增内容
## 行动手册管理任务
通过有选择性的增量改进,将反思内容转化为高质量的行动手册更新。
### 当前状态分析
训练进度:{progress}
行动手册统计数据:{stats}
### 近期反思
{reflection}
### 当前行动手册
{playbook}
### 问题背景
{question_context}
## 更新决策流程
按优先级顺序执行:
### 优先级 1:关键错误模式(CRITICAL_ERROR_PATTERN)
若反思发现影响多个问题的系统性错误:→ 新增高优先级纠正策略→ 为已存在的有害模式添加标记→ 更新相关策略以提升清晰度
### 优先级 2:缺失能力(MISSING_CAPABILITY)
若反思发现存在必要但缺失的策略:→ 新增含清晰示例的策略→ 确保策略具备针对性与可执行性
### 优先级 3:策略优化(STRATEGY_REFINEMENT)
若现有策略需要改进:→ 通过更优的解释或示例进行更新→ 保留有价值的核心内容,同时修正问题
### 优先级 4:矛盾解决(CONTRADICTION_RESOLUTION)
若策略间存在冲突:→ 移除或更新冲突策略→ 必要时新增用于澄清的元策略
### 优先级 5:成功强化(SUCCESS_REINFORCEMENT)
若某策略被证明效果显著:→ 标记为 “有帮助” 并提高权重→ 考虑为边缘场景创建该策略的变体
## 操作指南
### 新增操作(ADD)—— 适用于以下场景:
- 策略需应对新类型问题
- 反思发现存在缺失的能力
- 现有策略无法覆盖当前情况
新增操作要求:
- 必须具备真正的新颖性(不可是现有内容的改写)
- 必须包含具体示例或步骤
- 必须具备可执行性与针对性
- 严禁添加模糊的原则性内容
优质新增示例:{{"type": "ADD","section": "multiplication(乘法)","content": "计算两位数乘法(如 23×45):采用面积模型 —— 拆分为(20+3)×(40+5),计算四个部分的乘积后求和","metadata": {{"helpful": 1, "harmful": 0}}}}
劣质新增示例(禁止使用):{{"type": "ADD","content": "计算时要仔细" // 过于模糊}}
### 更新操作(UPDATE)—— 适用于以下场景:
- 策略需进一步澄清
- 需补充重要的例外情况或边缘场景
- 需优化示例内容
更新操作要求:
- 必须保留原有内容中的有价值部分
- 必须能切实提升策略效果
- 需引用具体的条目 ID(bullet_id)
标记操作(TAG)—— 适用于以下场景:
- 反思提供了策略有效性的相关证据
- 需调整 “有帮助”/“有害” 的权重
### 移除操作(REMOVE)—— 适用于以下场景:
- 策略持续引发错误
- 存在重复或冲突的策略
- 策略过于模糊,不具备实用价值
## 质量控制
执行任何操作前必须验证:
- 该内容是否为真正的新增 / 改进信息?
- 内容是否足够具体,可执行?
- 是否与现有策略存在冲突?
- 是否能提升未来的执行表现?
严禁添加包含以下内容的条目:
- “注意……”
- “务必反复检查……”
- “考虑所有方面……”
- “逐步思考……”(无具体步骤支撑)
- 具体方法的通用性建议
## 去重协议
执行新增操作前:
- 检索现有条目,排查是否存在相似策略
- 若相似度达 70%:选择更新(UPDATE)而非新增(ADD)
- 若针对同一问题但方法不同:新增时需添加区分说明
## 输出格式
仅返回有效的 JSON 对象:
{{"reasoning": "<分析需要执行哪些更新及原因>","operations": [{{"type": "ADD|UPDATE|TAG|REMOVE","section": "< 类别,如 'algebra(代数)'、'geometry(几何)'、'problem_solving(问题解决)'>","content": "< 具体、可执行的策略,含示例 >","bullet_id": "< 更新 / 标记 / 移除操作必填项 >","metadata": {{"helpful": < 计数 >,"harmful": < 计数 >,"confidence": 0.85}},"justification": "< 该操作如何提升行动手册质量的说明 >"}}]}}
## 操作示例
### 高质量新增操作:
{{"type": "ADD","section": "algebra(代数)","content": "求解一元二次方程 ax²+bx+c=0 时:首先尝试因式分解。若无法分解为整数因式,使用求根公式 x = (-b ± √(b²-4ac))/2a。示例:方程 x²-5x+6=0 可分解为 (x-2)(x-3)=0,因此解为 x=2 或 x=3","metadata": {{"helpful": 1, "harmful": 0, "confidence": 0.95}},"justification": "提供了完整的解题方法,包含决策依据与示例"}}
### 有效更新操作:
{{"type": "UPDATE","bullet_id": "bullet_045","section": "geometry(几何)","content": "勾股定理 a²+b²=c² 仅适用于直角三角形。对于非直角三角形,需使用余弦定理:c² = a²+b²-2ab・cos (C)。应用勾股定理前,需先确认三角形是否为直角(90°)三角形","metadata": {{"helpful": 3, "harmful": 0, "confidence": 0.90}},"justification": "补充了勾股定理的关键适用条件,并提供了非直角三角形的替代解法"}}
## 行动手册规模管理
若行动手册中的策略数量超过 50 条:
- 优先选择更新(UPDATE)而非新增(ADD)
- 合并相似策略
- 移除表现最差的条目
- 注重质量而非数量
若无需执行任何更新,返回空的操作列表。响应需以{{开头,以}}结尾"""

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 15
15 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)