中美研究团队发现AI文字生成顺序竟能决定质量高低
中美研究团队发现AI文字生成顺序竟能决定质量高低

这项由延世大学、甲骨文公司、卡内基梅隆大学、马里兰大学和中佛罗里达大学联合开展的研究发表于2025年10月,论文编号为arXiv:2510.05040v1。研究团队包括来自延世大学的李志勋(Jihoon Lee)、文皓延(Hoyeon Moon),甲骨文公司的阿尼特·库马尔·萨胡(Anit Kumar Sahu),卡内基梅隆大学的索米亚·卡尔(Soummya Kar)等多位研究者。这个跨国研究团队的发现可能彻底改变我们对AI文字生成的理解。
说起AI写文章,大多数人想到的都是那种从左到右、一个字一个字往下写的方式,就像我们人类写作一样。但最近有一种叫做"扩散语言模型"的新技术,它的工作方式完全不同——就像在一张纸上先随机放置一些文字片段,然后慢慢填补空白,最终形成完整的文章。这种方式听起来很神奇,但一直存在一个让研究者头疼的问题:怎样的填补顺序才能写出最好的文章?
研究团队在深入分析这个问题时有了一个惊人发现:这些扩散语言模型在训练过程中,实际上悄悄学会了许多种不同的"写作风格",就像一个作家同时掌握了新闻报道、小说创作、学术论文等各种文体。每当模型按照不同的顺序来填补文字时,就会激活其中某种特定的"写作专家"。以前的研究方法都是选择一种固定的填补顺序,这就像让一个多才多艺的作家只能用一种写作风格,白白浪费了其他才能。
为了验证这个想法,研究团队开发了一套名为HEX(隐藏半自回归专家)的全新方法。这个方法的核心思想非常巧妙:与其固执地使用一种填补顺序,不如同时尝试多种不同的顺序,然后让这些"隐藏专家"进行投票,选出最好的答案。就像解决一道数学题时,不是只用一种解法,而是同时用几种不同的方法求解,如果多种方法都得出同样的答案,那这个答案就更可靠了。
**一、从失败中发现的秘密**
故事要从研究团队遇到的一个意外现象开始。按照常理,让AI按照自己最有信心的顺序来填补文字应该能得到最好的效果,就像让学生先回答最有把握的题目一样。但在数学推理任务中,研究者们发现了令人困惑的现象:这种"按信心排序"的方法不仅没有帮助,反而经常导致AI产生大量无意义的重复内容。
更具体地说,当AI被要求解决GSM8K数学题(这是一个包含小学到初中水平数学应用题的测试集)时,传统的高信心填补方法只能达到24.72%的正确率,而完全随机的填补顺序竟然能达到50.87%的正确率。这就像一个学生在考试时,闭着眼睛胡乱答题的成绩居然比仔细思考后作答还要好,这显然不正常。
深入分析后,研究团队发现了问题的根源。在训练过程中,由于文章的大部分位置都应该是空白的(用特殊的结束符号填充),AI学会了对这些结束符号给出很高的信心分数。结果就是,当按信心排序时,AI总是优先填入结束符号,导致文章还没开始写就结束了,就像一个人刚开口说话就说"再见"一样荒谬。
这个发现让研究团队意识到,问题的关键不在于AI没有足够的能力,而在于我们没有找到正确的方式来激发它的能力。就像一把锁有很多种开法,但我们一直只尝试其中一种,结果当然打不开。
**二、隐藏专家的惊人发现**
为了深入理解这个现象,研究团队进行了一个巧妙的实验。他们让AI回答一个简单的问题:"谁发明了电话?"正确答案是"贝尔"。然后,他们观察当给AI提供不同的上下文信息时,它预测"贝尔"这个词的信心如何变化。
结果让人大开眼界:当AI能看到比较完整的句子时,比如"发明者是___",它对"贝尔"的预测信心非常高;但当给它的信息很少时,比如只有"___发明者___",它就变得不那么确定了。更有趣的是,有些情况下AI甚至会给出完全错误的答案。这就像同一个人在不同环境下展现出不同的专业水平:在图书馆里能答对历史问题,在嘈杂的咖啡厅里就可能答错。
这个实验证实了研究团队的猜想:AI内部确实存在多个"隐藏专家",每个专家都擅长处理特定类型的填补任务。有些专家擅长在有充足上下文时进行推理,有些专家则适合处理信息不完整的情况。关键是要找到合适的方法来调用这些不同的专家。
进一步的分析显示,不同的文字填补顺序实际上对应着不同的"专家调用模式"。当按照从左到右的小块顺序填补时,激活的是一类专家;当按照大块顺序填补时,激活的又是另一类专家。这就解释了为什么单一的填补策略往往效果不佳——我们只利用了AI全部能力的一小部分。
**三、半自回归策略的巧妙设计**
在发现了隐藏专家的存在后,研究团队面临一个新的挑战:如何设计出既能激活不同专家,又能保证文字生成质量的填补策略?完全随机的填补虽然有时效果不错,但很不稳定,就像闭着眼睛开车偶尔能到达目的地,但大部分时候都会出事故。
研究团队的解决方案是采用"半自回归"的策略。这个听起来复杂的名词其实描述的是一种很直观的方法:把要生成的文字分成若干个连续的小块,然后从左到右依次填补每个小块,但在每个小块内部,所有文字可以同时生成。这就像写文章时先确定段落结构,然后逐段展开,但每段内的句子可以并行构思。
这种策略的巧妙之处在于它保持了语言的自然流动性(从左到右的顺序),同时又允许局部的并行处理。实验证明,这种方法几乎完全消除了之前提到的"结束符号泛滥"问题。在GSM8K测试中,半自回归策略将正确率从22.52%提升到了76.27%,同时将产生错误输出的比例从55.8%降低到了0%。
更重要的是,不同的块大小会激活不同的隐藏专家。小块生成(比如每次4个词)激活的专家偏向于细致的局部推理,大块生成(比如每次32个词)激活的专家则更擅长整体规划。这就为下一步的创新奠定了基础。
**四、HEX方法的核心创新**
基于对隐藏专家的深入理解,研究团队开发了HEX(Hidden semi-autoregressive EXperts)方法。这个方法的基本思路可以用一个生动的比喻来解释:HEX就像组织了一场"专家会诊",让多个不同专长的专家同时对同一个问题给出解答,然后通过投票决定最终答案。
具体来说,HEX会使用5种不同的块大小(8、16、32、64、128个词)来生成文本,每种块大小对应一种不同的专家调用模式。对于每个问题,HEX会产生25个不同的答案(每种块大小生成5个答案),然后让这25个答案进行"投票",选出出现频率最高的答案作为最终结果。
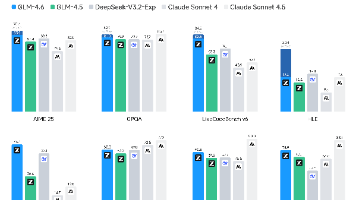
这种方法的威力是惊人的。在GSM8K数学推理测试中,HEX达到了88.10%的正确率,相比之前最好的单一策略提升了3.56倍。在更困难的MATH竞赛题目中,正确率从16.40%提升到了40.00%。在科学推理任务ARC-C中,正确率从54.18%跃升到87.80%。在测试AI是否会传播错误信息的TruthfulQA测试中,正确率从28.36%大幅提升到57.46%。
**五、实验验证与深入分析**
为了确保HEX方法的可靠性,研究团队进行了大量细致的实验验证。他们发现,随着参与投票的专家数量增加,整体正确率稳步提升,同时答案之间出现分歧的情况逐渐减少。这种现象很符合"集体智慧"的原理:当更多独立的专家参与决策时,错误答案会相互抵消,正确答案会得到强化。
研究团队还测试了一个重要问题:HEX的成功是否仅仅因为生成了更多答案,而不是因为调用了不同的专家?为了回答这个问题,他们比较了两种方法:一种是用同样的块大小生成25个答案然后投票,另一种是用5种不同块大小各生成5个答案然后投票。结果显示,多样性策略明显优于数量策略,证明了隐藏专家理论的正确性。
更有趣的是,研究团队发现不同的块大小确实会导致完全不同的推理路径。在一个关于2024年图灵奖获得者的问题中,小块大小的专家倾向于生成"Andrew"(正确答案),而大块大小的专家可能生成"Michael"或"David"等其他名字。通过投票机制,正确答案获得了更多支持,从而被选为最终结果。
**六、方法的普适性与局限性**
HEX方法不仅在数学推理任务中表现出色,在各种不同长度的文本生成任务中也展现出了稳定的优势。无论是生成128个词的短文本,还是512个词的长文本,HEX都能保持比传统方法更高的质量。这种一致性表明,隐藏专家现象是扩散语言模型的一个基本特征,而不是某些特定任务的特殊现象。
研究团队还发现,平均来看,参与HEX投票的各个专家的表现都不如最终的投票结果。这再次证实了集体决策的优势:整体的智慧确实大于部分的简单相加。
不过,HEX方法也有其局限性。最明显的是计算成本的增加:为了获得一个高质量的答案,需要生成25个候选答案,这使得计算时间增加了约5倍。对于实际应用来说,这需要在质量和效率之间找到平衡点。
此外,这项研究主要聚焦于推理类任务,对于更具创造性的任务(如创意写作、开放式对话等)的效果还有待验证。不同类型的任务可能需要不同的专家组合策略。
**七、理论意义与实际影响**
从理论角度来看,这项研究最重要的贡献是揭示了扩散语言模型内部的"隐藏专家"现象。这个发现改变了我们对这类模型的理解:它们不是简单的文本生成工具,而是集成了多种专业能力的复合系统。每种填补策略实际上是在调用不同的专家子网络,而传统的单一策略方法只是在利用这个丰富系统的一小部分能力。
这种理解为未来的研究开辟了新的方向。比如,我们可以尝试设计更精细的专家调用策略,针对不同类型的任务使用不同的专家组合。也可以研究如何在训练阶段就有意识地培养不同类型的专家,而不是让它们自然涌现。
从实际应用的角度来看,HEX方法提供了一种无需重新训练就能大幅提升模型性能的途径。这对于已经部署的大型语言模型来说具有重要价值:只需要改变推理策略,就能获得显著的性能提升。这种"测试时扩展"的思路可能会成为未来AI系统优化的重要方向。
**八、对比现有技术的优势**
将HEX与现有的其他优化方法对比,其优势主要体现在几个方面。首先是无需训练的特点:传统的性能提升方法通常需要收集新数据、设计新的训练目标、进行大量的计算训练,而HEX只需要改变推理过程,可以立即应用到现有模型上。
其次是效果的显著性:HEX在多个标准测试中都达到了与专门训练的强化学习方法(如GRPO)相当甚至更好的效果。这意味着通过巧妙的推理策略,我们可以达到与昂贵的重新训练相同的效果。
第三是方法的可解释性:HEX基于清晰的理论基础(隐藏专家假说),每个组件的作用都能得到合理解释。这与许多黑盒优化方法形成对比,为进一步的研究和改进提供了明确的方向。
**九、未来发展前景**
这项研究开启了扩散语言模型优化的新篇章,但同时也提出了许多值得进一步探索的问题。比如,是否存在更优的专家组合策略?能否设计出自适应的专家选择机制,根据任务类型自动调整策略?
另一个有趣的方向是将这种思路扩展到其他类型的生成模型。图像生成、音频生成等领域的扩散模型是否也存在类似的隐藏专家现象?如果存在,我们能否开发出相应的优化方法?
从更宏观的角度来看,这项研究体现了AI研究中一个重要的趋势:从单纯追求模型规模的扩大,转向更深入地理解和利用现有模型的内在能力。这种思路可能会催生出更多创新的优化方法,推动AI技术在不大幅增加计算成本的情况下实现性能突破。
说到底,这项研究最迷人的地方在于它揭示了AI系统中隐藏的复杂性和智能性。就像发现一个看似普通的人实际上精通多种技能一样,研究团队发现了扩散语言模型内部蕴藏的多重专家能力。HEX方法的成功不仅为当前的AI应用提供了实用的改进方案,更重要的是,它为我们理解和开发下一代更智能的AI系统指明了方向。
这种发现让人想起科学史上的许多重要时刻:当我们以新的角度审视已知的事物时,往往能发现前所未见的奥秘。在AI快速发展的今天,也许最大的突破不一定来自更大的模型或更多的数据,而可能来自对现有系统更深入的理解和更巧妙的利用。这项来自中美研究团队的工作,正是这种智慧探索的典型代表。
Q&A
Q1:扩散语言模型的隐藏专家是什么意思?
A:隐藏专家是指扩散语言模型在训练过程中自动学会的多种不同"写作风格"或处理模式。就像一个作家同时掌握新闻、小说、学术等不同文体,模型内部也存在多个专门处理不同情况的"专家"。不同的文字填补顺序会激活不同的专家,产生不同质量的输出。
Q2:HEX方法为什么比传统方法效果更好?
A:HEX方法通过同时使用多种不同的块大小来激活模型内部的不同专家,然后让这些专家"投票"选择最佳答案。这就像组织专家会诊一样,比依赖单一专家更可靠。实验显示,HEX在数学推理任务中将正确率从24.72%提升到88.10%,效果提升了3.56倍。
Q3:HEX方法有什么实际应用价值和局限性?
A:HEX的最大价值是无需重新训练就能大幅提升现有模型性能,可以立即应用到已部署的AI系统中。但局限性是计算成本增加约5倍,因为需要生成多个候选答案进行投票。目前主要在推理类任务中验证有效,对创意写作等任务的效果还需进一步研究。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献284条内容
已为社区贡献284条内容

所有评论(0)