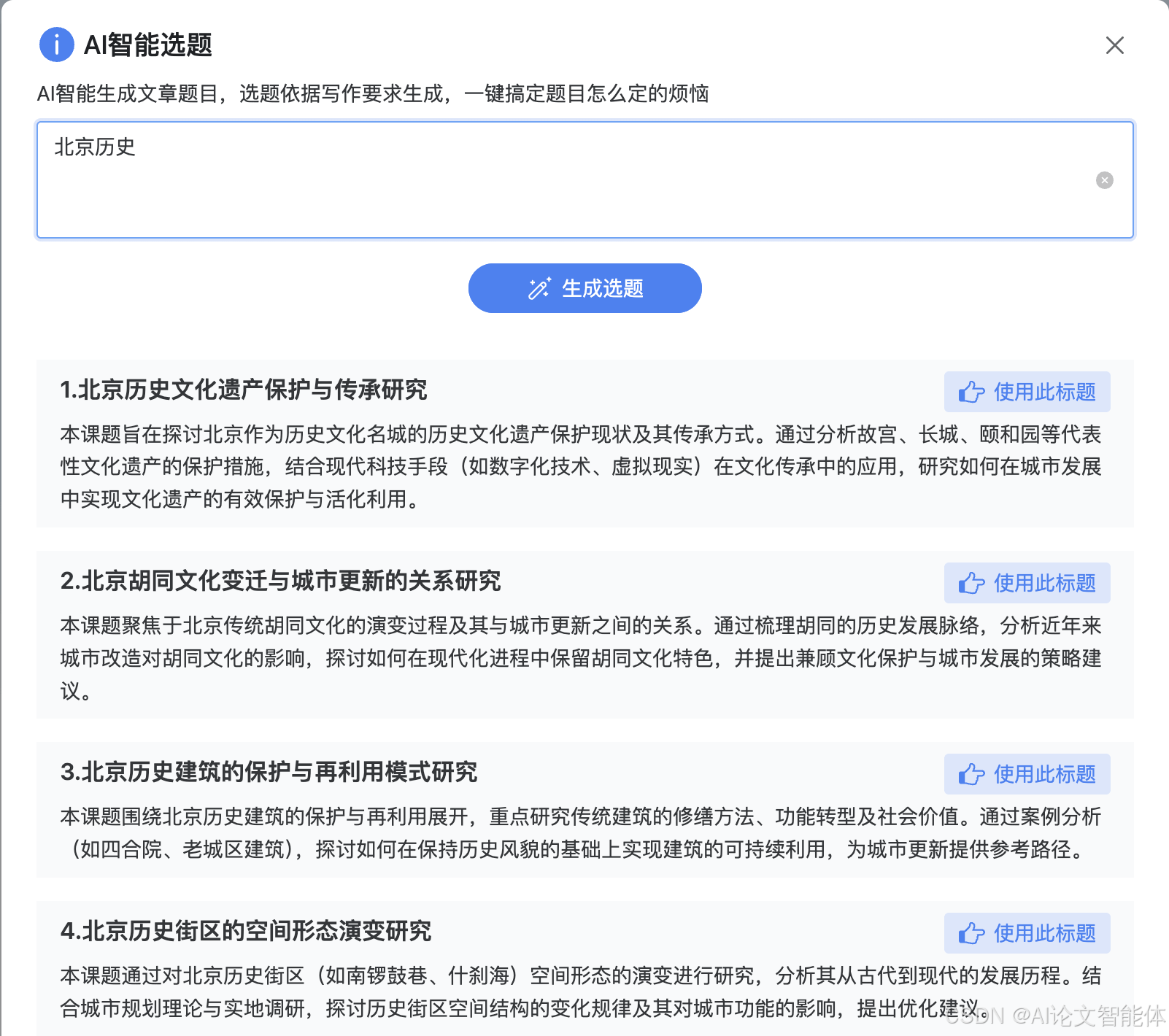
用户话题推荐
本文介绍了两种话题推荐方法:常规推荐和大模型推荐。
常规话题推荐
理解用户意图
分析用户输入的搜索词或问题,识别其核心意图和潜在兴趣点。通过自然语言处理技术提取关键词、实体和上下文信息。
提取关键词和实体
使用NLP工具如TF-IDF、BERT或命名实体识别(NER)模型,从用户输入中提取重要关键词和实体。这些元素将作为话题推荐的种子。
构建话题图谱
基于提取的关键词和实体,构建或查询现有的话题图谱。话题图谱可以包含相关概念、子话题、领域专家和热门内容。
计算相关性分数
为每个候选话题计算与用户意图的相关性分数。可以使用余弦相似度、Jaccard相似度或更复杂的语义相似度模型。分数越高,推荐优先级越高。
多样性保证
避免推荐过于相似的话题。通过聚类或多样性算法确保推荐列表覆盖多个子领域或视角。平衡热门话题和长尾内容。
个性化调整
结合用户历史行为数据(如点击、停留时间)调整推荐权重。引入协同过滤或深度学习模型提升个性化程度。
生成推荐列表
整合上述步骤结果,按优先级排序生成最终推荐列表。每个推荐话题附带简短描述或理由,帮助用户理解关联性。
示例代码片段
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
def recommend_topics(user_query, topic_pool):
vectorizer = TfidfVectorizer()
query_vec = vectorizer.fit_transform([user_query])
topic_vecs = vectorizer.transform(topic_pool)
similarities = cosine_similarity(query_vec, topic_vecs).flatten()
ranked_indices = similarities.argsort()[::-1]
return [topic_pool[i] for i in ranked_indices[:5]]
持续优化机制
建立反馈循环系统,收集用户对推荐结果的互动数据。定期更新模型和话题图谱,动态适应趋势变化和用户偏好演变。
采用大模型进行话题推荐
大模型话题推荐的实现方法
数据预处理与特征提取
收集用户历史行为数据(如浏览记录、点赞、评论等),清洗后通过Embedding技术(如BERT、Word2Vec)将文本转换为向量表示。对于非结构化数据(如图片、视频),可采用CLIP等多模态模型提取特征。确保数据覆盖用户兴趣的多样性,避免冷启动问题。
模型选择与训练
选用GPT-3、LLaMA等大语言模型作为基础架构,通过微调(Fine-tuning)适应推荐场景。采用对比学习或强化学习优化推荐结果,损失函数可设计为:
L=−∑i=1NlogP(ti∣ui)+λ∥θ∥2 \mathcal{L} = -\sum_{i=1}^N \log P(t_i|u_i) + \lambda \|\theta\|^2 L=−i=1∑NlogP(ti∣ui)+λ∥θ∥2
其中 tit_iti 是用户 uiu_iui 感兴趣的话题,θ\thetaθ 为模型参数,λ\lambdaλ 控制正则化强度。
实时交互与反馈机制
部署API接口接收用户实时输入(如搜索关键词、会话上下文),模型生成Top-K话题候选列表。结合A/B测试评估推荐效果,指标包括点击率(CTR)、停留时长等。用户隐式反馈(如跳过某推荐)需动态更新用户画像。
冷启动与多样性优化
对于新用户,采用基于内容的推荐(Content-based Filtering)或热门话题填充。通过MMR(Maximal Marginal Relevance)算法平衡相关性与多样性:
MMR=argmaxti[λ⋅Sim1(ti,u)−(1−λ)⋅maxtj∈SSim2(ti,tj)] \text{MMR} = \arg\max_{t_i} \left[ \lambda \cdot \text{Sim}_1(t_i, u) - (1-\lambda) \cdot \max_{t_j \in S} \text{Sim}_2(t_i, t_j) \right] MMR=argtimax[λ⋅Sim1(ti,u)−(1−λ)⋅tj∈SmaxSim2(ti,tj)]
其中 SSS 为已推荐话题集合,Sim1\text{Sim}_1Sim1 和 Sim2\text{Sim}_2Sim2 分别表示用户-话题、话题-话题相似度。
部署与监控
使用Flask或FastAPI搭建服务,结合Kubernetes实现弹性伸缩。监控模块需跟踪延迟、吞吐量及异常率,定期重新训练模型以适应兴趣漂移。日志分析可识别长尾需求,补充训练数据。
》》待深入实践中。。。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 10
10 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)