RAGFlow:告别“AI幻觉”,让你的知识库真正“聪明”起来!
RAGFlow是一款基于深度文档理解的开源RAG引擎,能精准解析PDF、Word、Excel等复杂文档,包括扫描件和图片中的文字表格。它通过智能分块、混合检索等技术,为AI问答提供可追溯的准确答案,解决传统大模型的"幻觉"问题。支持Docker一键部署,兼容多种主流AI模型,可快速搭建企业知识库、智能客服等应用,显著降低AI应用门槛。其开源特性让用户完全掌控数据流程,特别适合需
你是否也曾遇到过这样的困扰?
“公司海量的产品文档、合同、报告,想要快速查找某个信息,却像大海捞针?”
“用大模型问答时,它总是凭空捏造答案,引用来源根本不存在?”
“想搭建一个智能客服或知识库系统,但技术门槛高、流程复杂,让人望而却步……”
如果你的答案是“是”,那么,RAGFlow 可能就是那个你一直在寻找的解决方案。它不仅仅是一个工具,更是你处理复杂文档、构建可信AI应用的“得力副驾”。
当AI遇到“深度理解”,会碰撞出怎样的火花?
在AI技术日新月异的今天,大语言模型(LLM)在创造能力上令人惊叹,但其固有的“幻觉”问题和对新知识的“无知”,让它在处理严谨、专业的内部知识时显得力不从心。传统的RAG(检索增强生成)应用,也常因文档解析粗糙、检索不准,导致答案质量不佳。
RAGFlow 的诞生,精准地击中了这些痛点。作为一个基于深度文档理解的开源RAG引擎,它能让你的大模型“长出”一双火眼金睛,不仅能从复杂的非结构化数据(如合同、报表、扫描件)中精准提取信息,还能为每一个生成的答案提供精准的引用来源,让AI的回答变得有据可查,可信可靠。
它极大地降低了AI应用的门槛,让你能像搭积木一样,快速构建起面向企业或个人的智能问答、知识库和AI客服系统
|
项目 |
详情 |
|---|---|
| 名称 |
RAGFlow (Retrieval-Augmented Generation Flow) |
| 核心定位 |
基于深度文档理解的开源RAG引擎 |
| 核心特性 | 深度文档解析
、可视化分块与追溯、混合检索、模板化工作流 |
| 官网/源码 |
https://github.com/infiniflow/ragflow |
| 技术栈 |
前后端分离,支持Docker容器化部署 |
| 许可证 |
开源 |
为什么RAGFlow值得你重点关注?
-
深度文档理解,让解析更精准
-
它不仅支持PDF、Word、Excel等常规格式,还能通过OCR技术解析扫描件、图片中的文字,并精准识别和重建表格结构,这是许多同类工具的软肋。这意味着即使是合同条款、财务报表中的复杂信息也能被高保真提取。
-
-
智能分块与可视化追溯,让答案有据可依
-
摒弃传统的固定大小分块,采用基于语义和标题层级的动态分块策略,能更好地保持语义完整性,从而提升检索质量。
-
答案生成的每一步都可可视化追溯,你可以直接看到模型引用了哪份文档的哪个片段,极大增强结果的可信度。
-
-
混合检索与多路召回,让查找更全面
-
结合了向量检索(深挖语义)和全文检索(精准匹配关键词) 的优势,在多轮检索和重排序的加持下,能确保不遗漏关键信息。
-
-
开源开放与模型兼容,让选择更自由
-
作为开源软件,你可以完全掌控自己的数据和流程。
-
支持多种主流大模型(如DeepSeek、OpenAI、通义千问等)和向量数据库(如ChromaLM、FAISS、Elasticsearch等),避免被单一厂商绑定。
-
它能为你解决哪些实际问题?
-
企业知识库与智能客服:快速搭建一个能理解企业内部文档(规章制度、产品手册、SOP)的问答机器人,提升员工效率与客户服务质量。
-
个人知识管理:将你的学习笔记、研究报告、收藏文章喂给它,打造一个永不忘事的“第二大脑”,随时进行高效查询和总结。
-
内容创作与报告生成:基于已有的素材库,让AI帮你快速生成内容提纲、初稿或数据分析报告。
-
法律、金融等专业领域:精准解析法律条文、合同条款或财报,进行快速的内容检索和摘要,辅助专业人士进行决策。
部署:Docker一键部署(最推荐的方式)
RAGFlow官方提供了极为便捷的Docker Compose部署方案,能让你的服务在几分钟内跑起来。
-
环境准备:
-
确保你的机器满足:CPU ≥ 4核,内存 ≥ 16GB,磁盘 ≥ 50GB。
-
安装好
Docker(版本 ≥ 24.0.0) 和Docker Compose(版本 ≥ v2.26.1)。
-
-
关键系统参数调整(尤其Linux系统):
-
执行
sysctl vm.max_map_count,确保值不小于262144。如果小于,需要执行sudo sysctl -w vm.max_map_count=262144并写入/etc/sysctl.conf文件使其永久生效。这一步是为了保证向量数据库等组件稳定运行。
-
-
拉取代码并启动:
# 克隆官方仓库 git clone https://github.com/infiniflow/ragflow.git cd ragflow # 使用 Docker Compose 一键启动所有服务 docker compose -f docker/docker-compose.yml up -d -
访问
启动成功后,在浏览器访问http://你的服务器IP(默认80端口),即可进入RAGFlow的Web操作界面。
基本使用:5步创建一个可用的知识库问答
-
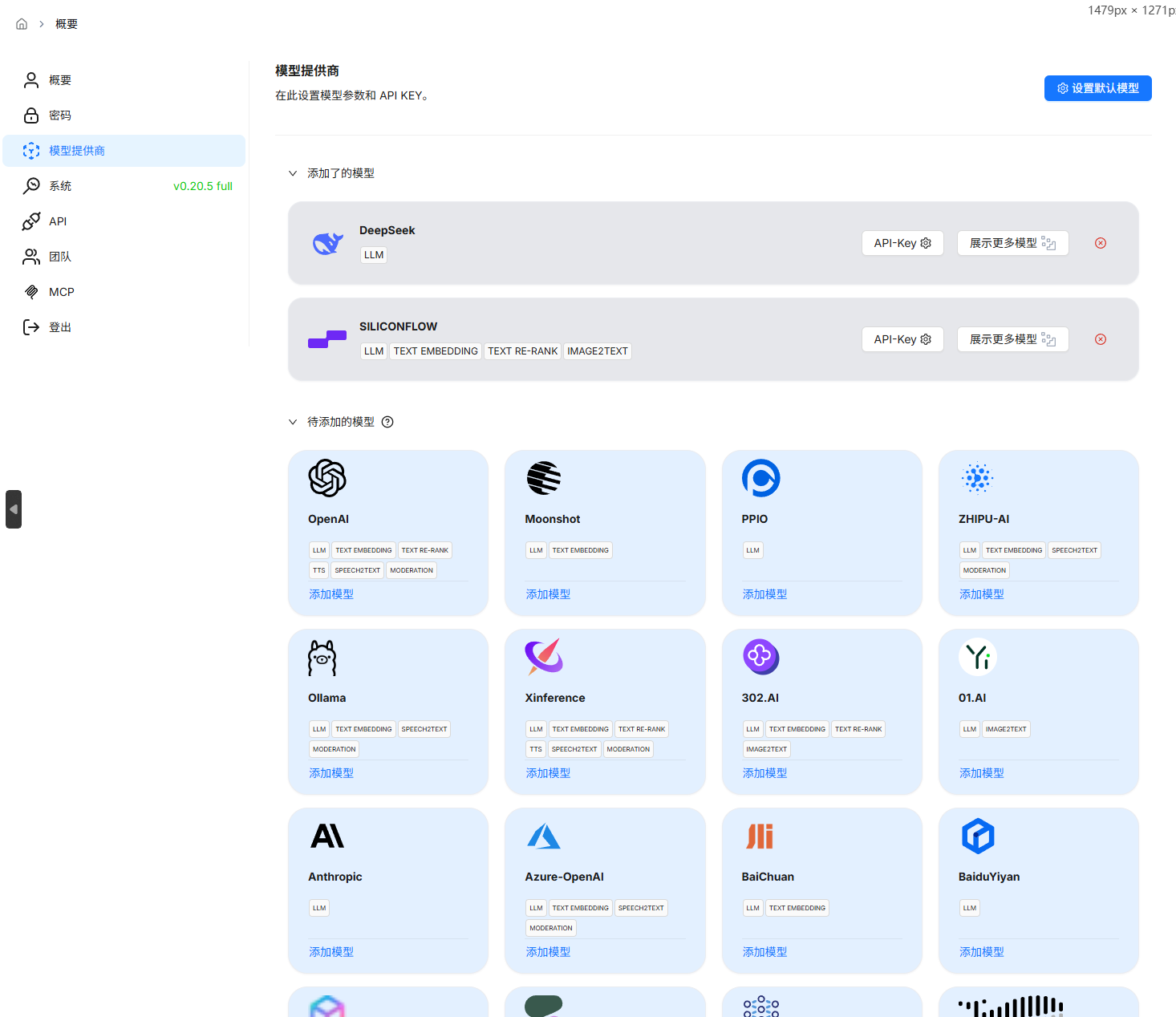
初始化与模型配置:
-
首次进入系统会引导初始化。完成后,在“设置”或“模型提供商”中,添加你需要使用的Chat模型(如DeepSeek、OpenAI等)和Embedding模型(如BGE等),并配置好API密钥或本地模型地址。
-
-
创建知识库:
-
点击“知识库” -> “创建知识库”,填写名称,并选择文档语言和嵌入模型。
-
-
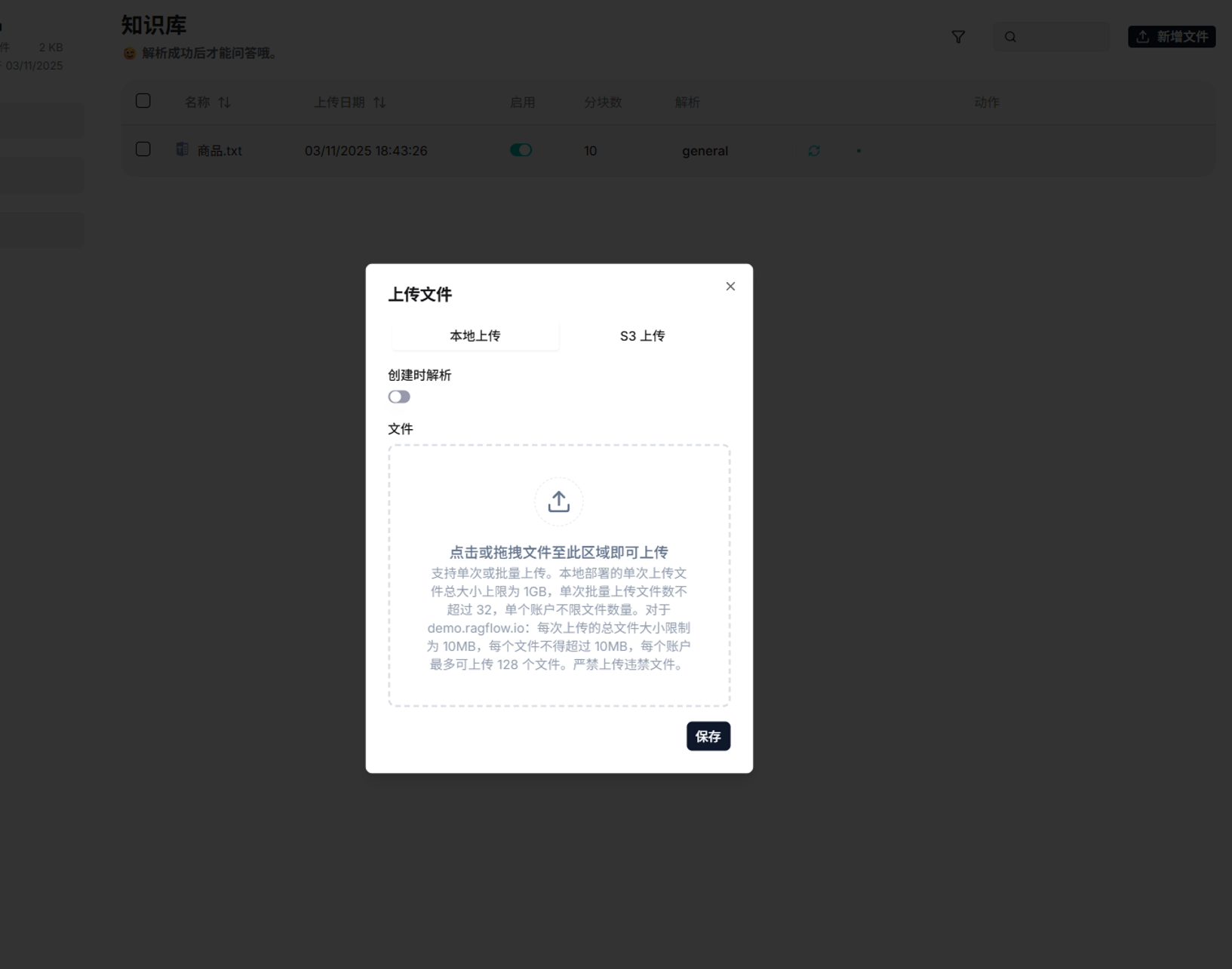
上传与解析文档:
-
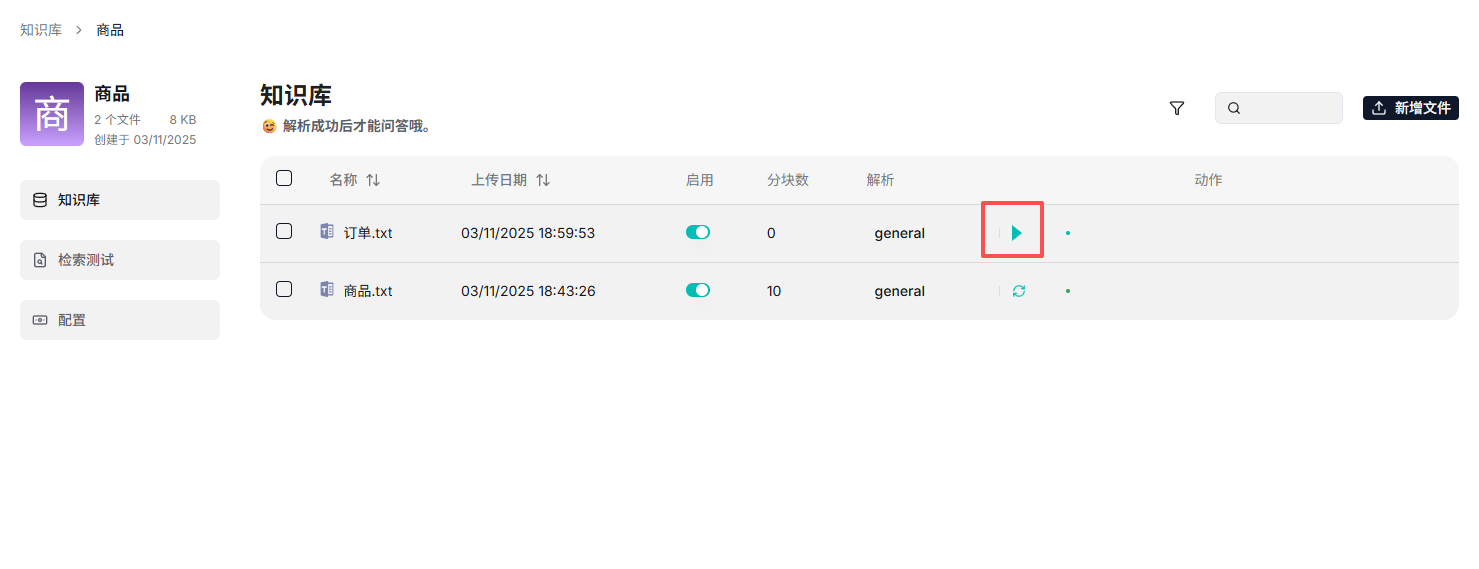
在创建好的知识库中上传你的文档(Word, PDF, PPT等)。上传后,文档状态为“未解析”,点击“解析”按钮。
-
解析过程中,RAGFlow会动用其深度文档理解能力,对文档进行分块和向量化。你可以点击解析后的文档,预览和检查解析效果,确保关键信息被正确提取。
-
-
创建对话应用:
-
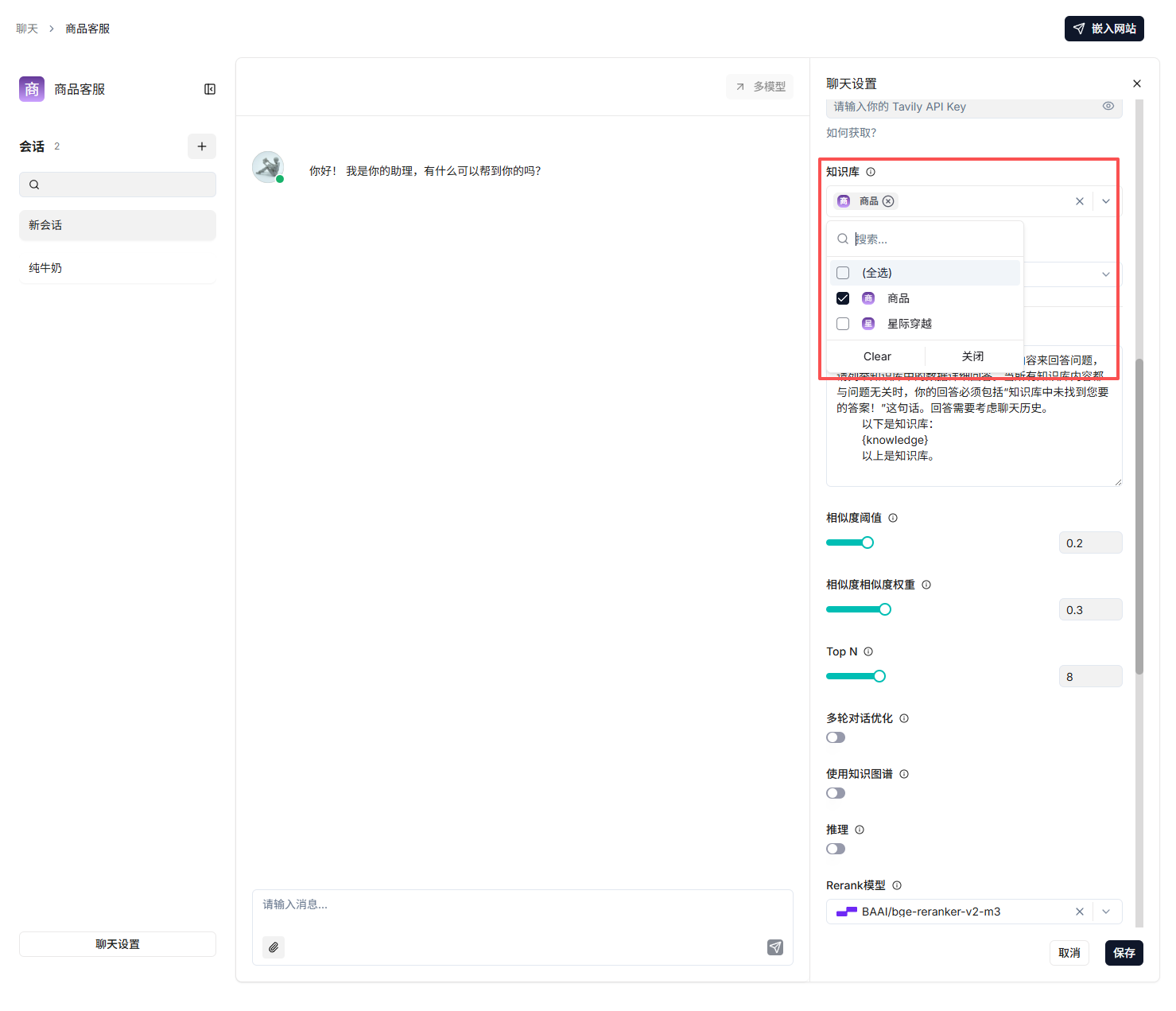
点击“聊天” -> “创建聊天”,为你的应用起个名字。
-
在设置中,关联上一步创建的知识库,并选择你配置好的Chat模型。
-
-
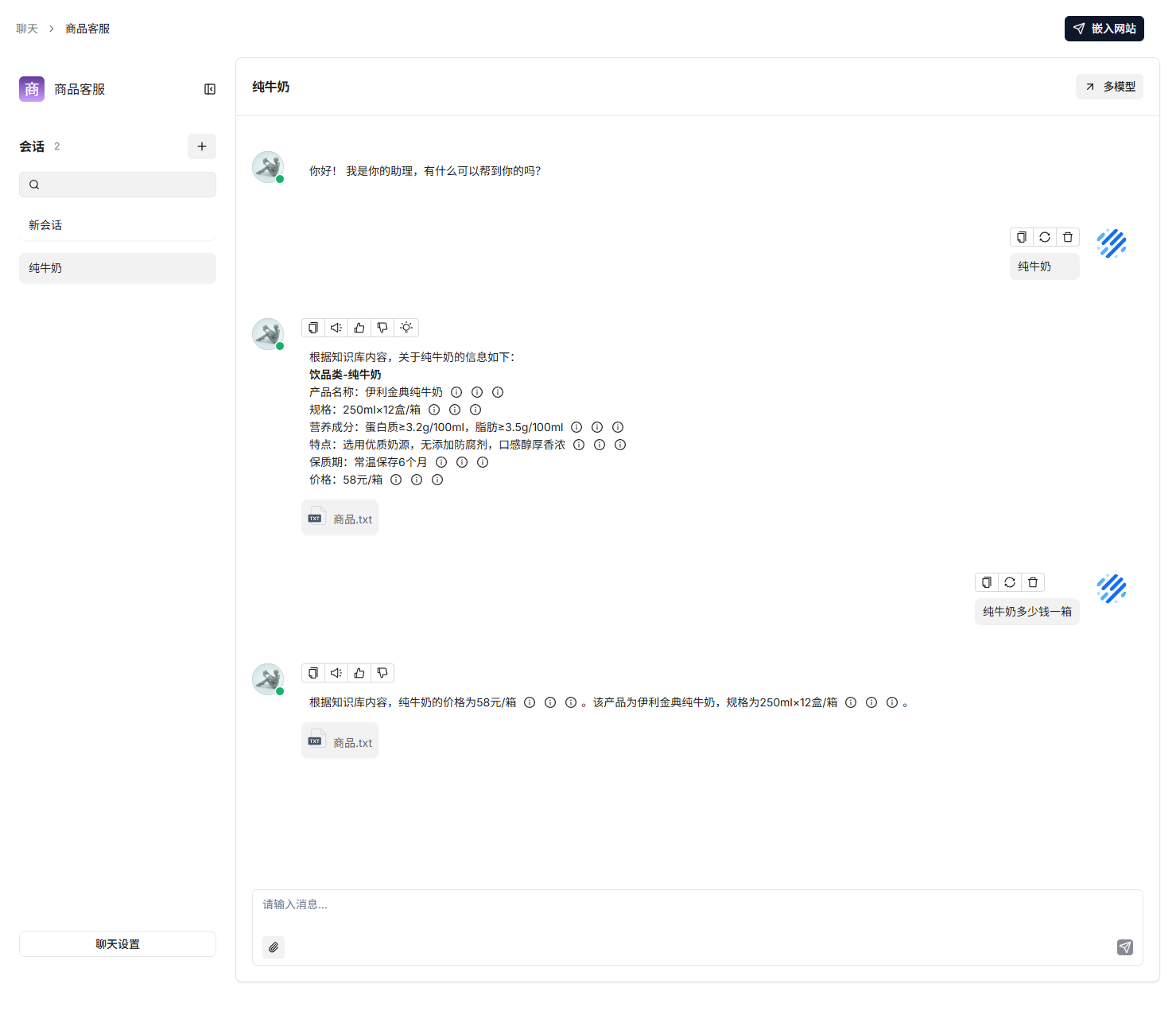
测试与对话:
-
现在,你就可以在对话窗口向AI提问了!基于你的私有知识库,它将给出精准且带有引用的回答。
-
温馨提醒和扩展
-
温馨提醒
-
解析质量是关键:RAGFlow虽然强大,但最终效果很大程度上依赖于文档解析的质量。对于格式极其复杂或扫描质量差的文档,可能仍需手动检查和调整分块结果。记住一个原则:面向人可读性高的文档,不一定面向机器可读性高,有时需要你为AI“润色”一下知识内容。
-
资源规划:RAGFlow是资源密集型应用,尤其在处理大量文档或使用本地嵌入模型时。请根据你的数据规模合理规划硬件资源。
-
模型费用与选择:如果使用云端大模型(如GPT-4),需要关注API调用费用。对于敏感数据,建议优先选择本地部署的开源模型(如通过Ollama部署的Llama、Qwen等)。
-
-
扩展探索
当你熟悉基础功能后,可以探索RAGFlow更强大的能力:-
尝试不同的分块模板:除了通用的“General”分块,对于问答对形式的内容,可以尝试“Q&A”分块,它能实现最精准的一问一答匹配。
-
构建Agent工作流:利用RAGFlow的Agent功能,设计更复杂的业务流程,例如“先优化用户问题 -> 知识库检索 -> 联网搜索 -> 综合生成答案”。
-
集成到你的系统:RAGFlow提供了丰富的API,你可以轻松将构建好的AI应用能力集成到你自己的网站、App或钉钉、企业微信等办公平台中。
-
总而言之,RAGFlow 通过其强大的文档解析和透明可控的RAG流程,为企业和个人搭建高效、可信的AI应用提供了坚实的基石。无论你是技术爱好者还是业务负责人,它都值得你立即动手尝试,开启智能知识管理的新篇章。
希望这篇介绍能帮助你快速上手RAGFlow!如果你在实践过程中有任何心得或遇到了有趣的挑战,欢迎在评论区与我们分享交流。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 20
20 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)