收藏必备!用大白话讲透大模型工作原理,产品经理也能秒懂
在传统软件产品,质量=稳定性。但在AI产品,质量=准确率 + 可解释性 + 可控性。• 不是"这个功能能不能用",而是"这个功能的准确率是多少"• 不是"为什么会出错",而是"在什么场景下容易出错"• 不是"怎么修bug",而是"怎么优化训练数据和prompt"• 数据思维(会看准确率、召回率、F1等指标)• 概率思维(理解"没有100%正确"这件事)• 实验思维(通过A/B测试不断迭代优化)回到
本文通过"文字接龙"比喻,解释大模型本质是超大规模概率预测系统。它利用词向量将文字转为数学表示,通过注意力机制捕捉词语关联,多层堆叠实现复杂语义理解。大模型出现"幻觉"源于其非逻辑推理的特性,产品经理应理解其能力边界,将不确定性设计进产品,重新定义AI产品质量标准,而非简单将其视为"黑盒"使用。
上周,团队的一个产品经理跑来问我:“老大,我们的AI产品总是出现’幻觉’,用户投诉说生成的内容一本正经地胡说八道。这到底是怎么回事?”
我问他:“你知道大模型是怎么工作的吗?”
他愣了一下:“不就是…训练了很多数据,然后就能回答问题了吗?”
我笑了:“你这个理解,就像说’飞机就是有翅膀能飞的铁皮’一样——没错,但解决不了任何问题。”
这不是个例。
过去一年,我见过太多产品经理在做AI产品时,把大模型当成"黑盒"来用。出了问题不知道怎么调优,写PRD时不知道技术边界在哪,跟算法团队沟通时完全不在一个频道。
今天,我想用最简单的方式,把大模型的工作原理讲清楚。
不是给你上课,而是想让你真正理解这个东西是怎么运转的,这样你才能更好地设计AI产品、评估技术方案、解决实际问题。
一、先忘掉那些吓人的术语
在讲原理之前,我想先说一件事。
去年我参加一个AI技术分享会,台上的算法专家噼里啪啦讲了一堆:Transformer架构、注意力机制、多头自注意力、位置编码、残差连接…
台下的产品经理听得云里雾里。
散会后,一个做了10年产品的老PM私下跟我说:“老实说,我一个词都没听懂。我是不是不适合做AI产品?”
我告诉他:“不是你的问题,是讲的人的问题。”
任何复杂的技术,如果不能用人话解释清楚,要么是讲的人没真懂,要么是讲的人不想让你懂。
所以今天,我不会用那些术语来吓唬你。
我会用你能理解的语言,从第一性原理出发,把大模型这个东西拆解清楚。
二、一个类比:大模型就像一个超级"接龙高手"
要理解大模型,先从一个简单的游戏开始——文字接龙。
小时候我们都玩过这个游戏:
- • 我说:“今天天气”
- • 你接:“真不错”
- • 我再说:“今天天气真不错,适合”
- • 你接:“去公园”
你是怎么知道接"真不错"而不是接"汽车轮胎"的?
因为你见过类似的句子。你的大脑里存储了大量"今天天气"后面通常接什么的经验。
大模型做的事情,本质上就是这个——超大规模的文字接龙游戏。
但它比你厉害的地方在于:
-
- 见过的句子多得多:它读过几乎整个互联网的文本,而你只读过几千本书
-
- 记忆力强得多:它能记住数十亿个"前面说了什么,后面通常接什么"的模式
-
- 反应快得多:它可以在毫秒级别内,从数十亿个可能性中找出最合适的下一个词
所以当你问它:“如何提升产品的用户留存率?”
它会这样思考(当然,是用数学的方式):
- “如何” 后面通常接动词
- “提升” 后面通常接指标类名词
- “用户留存率” 是产品领域的专业术语
- 在我见过的几百万篇产品文章中,回答这类问题通常会从"分析流失原因"或"优化核心路径"开始
然后,它一个词一个词地"接"出来,形成了一个看起来很专业的回答。
关键来了:它真的"懂"吗?
不一定。
它只是在做"统计学意义上的最优接龙"。
这就是为什么它有时候会"一本正经地胡说八道"——因为它见过类似的句子结构,但不理解背后的逻辑。
三、深入一层:大模型的三个核心组件
好,现在你理解了"接龙"这个基本逻辑。
接下来,我们深入一层,看看大模型是怎么做到"超级接龙"的。
组件1:词向量(把文字变成数学)
第一个问题:计算机不认识"苹果"、"香蕉"这些字,它只认识数字。
怎么办?
把每个词都转化成一串数字(向量)。
比如:
- • “苹果” → [0.2, 0.8, 0.3, 0.1, …]
- • “香蕉” → [0.3, 0.7, 0.4, 0.2, …]
- • “汽车” → [0.9, 0.1, 0.6, 0.8, …]
你会发现,"苹果"和"香蕉"的数字比较接近(因为都是水果),而"汽车"的数字差异很大。
这就是词向量的神奇之处:它把语义相近的词,在数学空间里也放得很近。
这样,模型就可以用数学方法来"理解"词与词之间的关系。
组件2:注意力机制(知道该关注什么)
第二个问题:在理解一句话时,不是所有词都同等重要。
比如这句话:“苹果公司发布了新款iPhone”
如果你想理解"发布了什么",你会重点关注"iPhone"这个词,而不是"苹果公司"。
注意力机制,就是让模型学会"该关注哪些词"。
具体怎么做呢?我用一个故事类比:
假设你在一个嘈杂的派对上,想听清楚某个朋友在说什么。
你会怎么做?
- • 你会把注意力集中在他的声音上(提高权重)
- • 同时过滤掉周围的噪音(降低权重)
- • 如果他说到一个关键词,你会更认真地听接下来的内容(动态调整注意力)
注意力机制做的就是这个事:动态地调整每个词的重要性权重。
在理解"iPhone"这个词时:
- • “发布了” 权重0.8(高)
- • “新款” 权重0.6(中)
- • “苹果公司” 权重0.3(低)
- • “的” 权重0.1(很低)
这样,模型就能抓住句子的核心含义。
组件3:层层堆叠(从简单到复杂)
第三个问题:理解语言是一个从简单到复杂的过程。
比如理解这句话:“他放弃了稳定的工作,去追逐梦想”
- • 第1层:识别词语(他、放弃、稳定、工作、追逐、梦想)
- • 第2层:理解短语(“放弃工作”、“追逐梦想”)
- • 第3层:理解句法关系("他"是主语,"放弃"和"追逐"是并列的动作)
- • 第4层:理解语义(这是一个关于人生选择的故事)
- • 第5层:理解情感(带有冒险、勇敢的情感色彩)
大模型就是这样一层一层地理解的。
GPT-4有96层,每一层都在前一层的基础上,提取更高级的特征。
就像盖楼一样:
- • 第1层:打地基(识别词语)
- • 第2-10层:建主体结构(理解语法)
- • 第11-50层:装修细节(理解语义)
- • 第51-96层:软装和艺术品(理解深层含义、情感、隐喻)
层数越多,理解越深。
这就是为什么GPT-4比GPT-3.5"聪明"——它不是因为"见过更多数据",而是因为"想得更深"。
四、把三个组件串起来:完整的工作流程
好,现在我们把三个组件串起来,看看当你问大模型一个问题时,它内部到底发生了什么。
场景:你问它"如何提升产品的用户留存率?"
步骤1:分词 + 词向量转换
模型先把你的问题切成词:
- • “如何” “提升” “产品” “的” “用户” “留存率” “?”
然后把每个词转成向量(一串数字):
- • “如何” → [0.3, 0.7, …]
- • “提升” → [0.5, 0.2, …]
- • …
步骤2:多层注意力机制处理
模型开始96层的"深度思考":
- • 第1-10层:识别这是一个"如何做某事"的疑问句
- • 第11-30层:识别关键词是"提升"、“用户留存率”,这是产品领域的问题
- • 第31-60层:回忆它见过的所有关于"用户留存"的内容,提取出常见的解决方案模式
- • 第61-96层:组织语言,决定用什么样的结构来回答(先分析原因?还是直接给建议?)
步骤3:生成答案(一个词一个词地接龙)
模型开始生成答案:
- • 第1个词:分析所有可能的开头词,"提升"概率60%、"要"概率20%、“可以"概率15%…,选择"提升”
- • 第2个词:在"提升"后面,"用户"概率45%、“产品"概率30%…,选择"用户”
- • 第3个词:在"提升用户"后面,“留存"概率80%…,选择"留存”
- • …
就这样,一个词一个词地生成,直到形成完整的答案。
步骤4:概率采样(增加多样性)
有个细节:模型不会每次都选概率最高的词,否则每次回答都一模一样。
它会用一种叫"温度采样"的方法:
- • 温度=0:永远选概率最高的词(答案死板、重复)
- • 温度=1:按概率随机选(答案多样、有创意)
- • 温度>1:更随机(答案可能混乱、不靠谱)
这就是为什么你多次问同一个问题,会得到不同的答案。
五、三个关键问题的答案
理解了工作原理,很多困扰产品经理的问题就有答案了。
问题1:为什么会出现"幻觉"?
因为它不是在"思考",而是在"接龙"。
如果训练数据中有错误信息,或者某个接龙模式被错误地强化了,它就会一本正经地胡说八道。
比如:
- • 它见过很多"某某公司成立于某某年"的句子
- • 但它从来没见过"我不知道"这种答案
- • 所以当你问它一个它不知道的公司成立时间时,它会编造一个看起来很合理的年份
解决方案:
- • 用检索增强(RAG):先去数据库查真实信息,再生成答案
- • 用思维链(CoT):让它一步步推理,而不是直接接龙
- • 设置置信度阈值:如果概率太低,就老实说"我不确定"
问题2:为什么回答质量不稳定?
因为"温度"参数和上下文的影响。
同一个问题,在不同上下文中,模型的注意力焦点不同,生成的答案也不同。
比如:
- • 如果你刚问完"如何做增长",再问"怎么提升留存",它会倾向于从增长角度回答
- • 如果你刚问完"如何优化体验",再问"怎么提升留存",它会倾向于从体验角度回答
解决方案:
- • 设计好prompt,明确上下文边界
- • 用system prompt锁定角色和专业领域
- • 对关键场景做few-shot示例引导
问题3:为什么有些问题回答得特别好,有些特别差?
因为训练数据的分布不均。
- • 如果某个领域的文本在训练数据中占比高(比如编程、常识问答),它就回答得好
- • 如果某个领域的文本在训练数据中占比低(比如小众行业、最新资讯),它就回答得差
这就是为什么:
- • 让它写Python代码,效果很好(因为GitHub上有海量代码)
- • 让它分析你们公司的业务,效果很差(因为它没见过你们公司的数据)
解决方案:
- • 用fine-tuning:在你的专业领域数据上进行微调
- • 用RAG:把你的知识库喂给它
- • 设计好prompt:用few-shot示例来引导
六、给产品经理的三个实战建议
最后,基于这些原理,我给做AI产品的同行们三个建议:
建议1:不要把大模型当成"万能钥匙"
很多产品经理有个误区:觉得接入了大模型,什么问题都能解决。
错。
大模型擅长的是"模式识别"和"概率推理",不擅长"精确计算"和"逻辑推理"。
比如:
- • ✅ 擅长:文案生成、摘要提取、情感分析、对话交互
- • ❌ 不擅长:数学计算、数据库查询、确定性逻辑判断
所以在设计AI产品时,要搞清楚:
- • 哪些环节用大模型(发挥它的语义理解能力)
- • 哪些环节用传统方法(发挥它的精确性)
建议2:把"不确定性"设计进产品
大模型的答案是有概率分布的,这意味着结果天然带有不确定性。
很多产品经理想回避这个问题,试图让AI"每次都给对"。
这不现实。
更好的做法是:把不确定性变成产品特性。
比如:
- • 用"为你推荐"而不是"正确答案"的表述
- • 提供多个候选答案,让用户选择
- • 加上"AI生成内容,仅供参考"的提示
- • 设计用户反馈机制,让AI不断学习
建议3:重新定义"产品质量"
在传统软件产品,质量=稳定性。
但在AI产品,质量=准确率 + 可解释性 + 可控性。
这意味着你的验收标准要变:
- • 不是"这个功能能不能用",而是"这个功能的准确率是多少"
- • 不是"为什么会出错",而是"在什么场景下容易出错"
- • 不是"怎么修bug",而是"怎么优化训练数据和prompt"
这需要产品经理具备:
- • 数据思维(会看准确率、召回率、F1等指标)
- • 概率思维(理解"没有100%正确"这件事)
- • 实验思维(通过A/B测试不断迭代优化)
写在最后
回到文章开头那个场景。
我跟那个产品经理讲完这些原理后,他恍然大悟:“原来如此。怪不得我们的AI客服总是在某些场景下答非所问——因为训练数据里这些场景太少了。”
一周后,他调整了产品方案:
- • 不再期望AI"回答所有问题"
- • 而是让AI先判断"这个问题我有没有把握回答好"
- • 没把握的,直接转人工
- • 有把握的,给出答案+置信度
上线后,用户满意度从68%提升到83%。
这就是理解原理的价值。
你不需要成为算法专家,不需要懂数学公式,但你需要理解:
- • 大模型能做什么、不能做什么
- • 为什么会出现某些问题
- • 怎样设计产品来规避风险、发挥优势
这才是产品经理该有的"AI能力"。
而不是把它当成黑盒,祈祷它别出错。
如何从零学会大模型?小白&程序员都能跟上的入门到进阶指南
当AI开始重构各行各业,你或许听过“岗位会被取代”的焦虑,但更关键的真相是:技术迭代中,“效率差”才是竞争力的核心——新岗位的生产效率远高于被替代岗位,整个社会的机会其实在增加。
但对个人而言,只有一句话算数:
“先掌握大模型的人,永远比后掌握的人,多一次职业跃迁的机会。”
回顾计算机、互联网、移动互联网的浪潮,每一次技术革命的初期,率先拥抱新技术的人,都提前拿到了“职场快车道”的门票。我在一线科技企业深耕12年,见过太多这样的案例:3年前主动学大模型的同事,如今要么成为团队技术负责人,要么薪资翻了2-3倍。
深知大模型学习中,“没人带、没方向、缺资源”是最大的拦路虎,我们联合行业专家整理出这套 《AI大模型突围资料包》,不管你是零基础小白,还是想转型的程序员,都能靠它少走90%的弯路:
- ✅ 小白友好的「从零到一学习路径图」(避开晦涩理论,先学能用的技能)
- ✅ 程序员必备的「大模型调优实战手册」(附医疗/金融大厂真实项目案例)
- ✅ 百度/阿里专家闭门录播课(拆解一线企业如何落地大模型)
- ✅ 2025最新大模型行业报告(看清各行业机会,避免盲目跟风)
- ✅ 大厂大模型面试真题(含答案解析,针对性准备offer)
- ✅ 2025大模型岗位需求图谱(明确不同岗位需要掌握的技能点)
所有资料已整理成包,想领《AI大模型入门+进阶学习资源包》的朋友,直接扫下方二维码获取~

① 全套AI大模型应用开发视频教程:从“听懂”到“会用”
不用啃复杂公式,直接学能落地的技术——不管你是想做AI应用,还是调优模型,这套视频都能覆盖:
- 小白入门:提示工程(让AI精准输出你要的结果)、RAG检索增强(解决AI“失忆”问题)
- 程序员进阶:LangChain框架实战(快速搭建AI应用)、Agent智能体开发(让AI自主完成复杂任务)
- 工程落地:模型微调与部署(把模型用到实际业务中)、DeepSeek模型实战(热门开源模型实操)
每个技术点都配“案例+代码演示”,跟着做就能上手!

课程精彩瞬间

② 大模型系统化学习路线:避免“学了就忘、越学越乱”
很多人学大模型走弯路,不是因为不努力,而是方向错了——比如小白一上来就啃深度学习理论,程序员跳过基础直接学微调,最后都卡在“用不起来”。
我们整理的这份「学习路线图」,按“基础→进阶→实战”分3个阶段,每个阶段都明确:
- 该学什么(比如基础阶段先学“AI基础概念+工具使用”)
- 不用学什么(比如小白初期不用深入研究Transformer底层数学原理)
- 学多久、用什么资料(精准匹配学习时间,避免拖延)
跟着路线走,零基础3个月能入门,有基础1个月能上手做项目!

③ 大模型学习书籍&文档:打好理论基础,走得更稳
想长期在大模型领域发展,理论基础不能少——但不用盲目买一堆书,我们精选了「小白能看懂、程序员能查漏」的核心资料:
- 入门书籍:《大模型实战指南》《AI提示工程入门》(用通俗语言讲清核心概念)
- 进阶文档:大模型调优技术白皮书、LangChain官方中文教程(附重点标注,节省阅读时间)
- 权威资料:斯坦福CS224N大模型课程笔记(整理成中文,避免语言障碍)
所有资料都是电子版,手机、电脑随时看,还能直接搜索重点!

④ AI大模型最新行业报告:看清机会,再动手
学技术的核心是“用对地方”——2025年哪些行业需要大模型人才?哪些应用场景最有前景?这份报告帮你理清:
- 行业趋势:医疗(AI辅助诊断)、金融(智能风控)、教育(个性化学习)等10大行业的大模型落地案例
- 岗位需求:大模型开发工程师、AI产品经理、提示工程师的职责差异与技能要求
- 风险提示:哪些领域目前落地难度大,避免浪费时间
不管你是想转行,还是想在现有岗位加技能,这份报告都能帮你精准定位!
⑤ 大模型大厂面试真题:针对性准备,拿offer更稳
学会技术后,如何把技能“变现”成offer?这份真题帮你避开面试坑:
- 基础题:“大模型的上下文窗口是什么?”“RAG的核心原理是什么?”(附标准答案框架)
- 实操题:“如何优化大模型的推理速度?”“用LangChain搭建一个多轮对话系统的步骤?”(含代码示例)
- 场景题:“如果大模型输出错误信息,该怎么解决?”(教你从技术+业务角度回答)
覆盖百度、阿里、腾讯、字节等大厂的最新面试题,帮你提前准备,面试时不慌!

以上资料如何领取?
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

为什么现在必须学大模型?不是焦虑,是事实
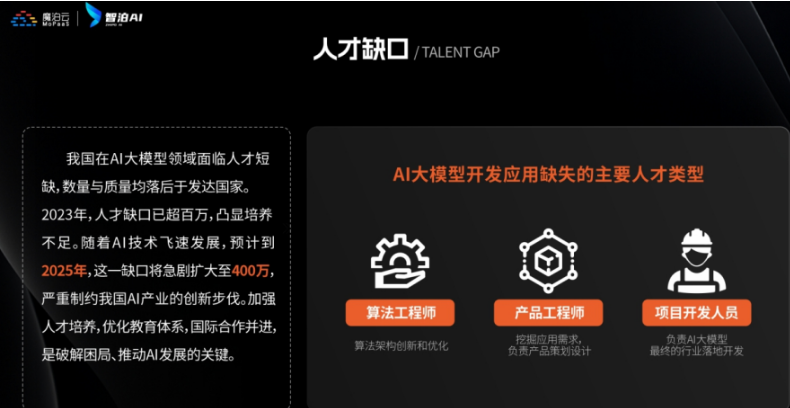
最近英特尔、微软等企业宣布裁员,但大模型相关岗位却在疯狂扩招:
- 大厂招聘:百度、阿里的大模型开发岗,3-5年经验薪资能到50K×20薪,比传统开发岗高40%;
- 中小公司:甚至很多传统企业(比如制造业、医疗公司)都在招“会用大模型的人”,要求不高但薪资可观;
- 门槛变化:不出1年,“有大模型项目经验”会成为很多技术岗、产品岗的简历门槛,现在学就是抢占先机。
风口不会等任何人——与其担心“被淘汰”,不如主动学技术,把“焦虑”变成“竞争力”!

最后:全套资料再领一次,别错过这次机会
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 2
2 0
0- 0



 已为社区贡献199条内容
已为社区贡献199条内容

所有评论(0)