构建一个自主深度思考的RAG管道以解决复杂查询--战略规划与查询制定(4)
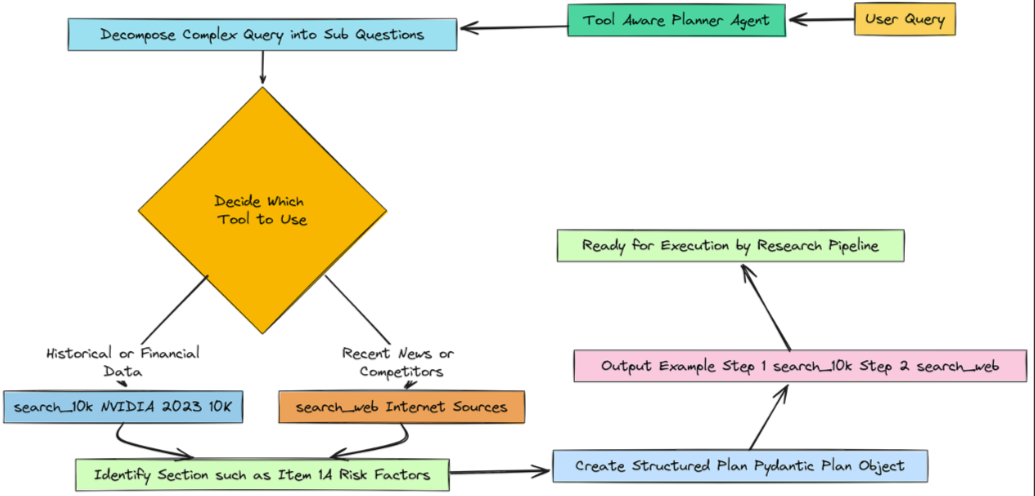
这是我们的系统从简单的数据获取器跃升为真正的推理引擎的地方。我们的代理不会天真地将用户的复杂查询视为单一搜索,而是会先暂停、思考,然后构建一个详细的、循序渐进的研究策略。我们为它提供了三条信息来开展工作:简单的子问题、我们的规划器已经确定的关键词,以及来自之前任何研究步骤的过往上下文。我们将构建一个由大语言模型驱动的智能体,其唯一任务是将用户的查询分解为结构化的计划对象,决定每一步使用何种工具。这
在定义了我们的RAGState之后,我们现在可以构建代理的第一个、也可以说是最关键的认知组件:它的规划能力。这是我们的系统从简单的数据获取器跃升为真正的推理引擎的地方。我们的代理不会天真地将用户的复杂查询视为单一搜索,而是会先暂停、思考,然后构建一个详细的、循序渐进的研究策略。
本节分为三个关键工程步骤:
-
工具感知规划器:我们将构建一个由大语言模型驱动的智能体,其唯一任务是将用户的查询分解为结构化的计划对象,决定每一步使用何种工具。
-
查询重写器:我们将创建一个专门的代理,把规划器的简单子问题转换为高效、优化的搜索查询。
-
元数据感知分块:我们将重新处理源文档,添加章节级元数据,这是实现高精度、过滤式检索的关键步骤。
使用工具感知规划器分解问题
所以,基本上我们想要构建我们业务的大脑。这个大脑在收到复杂问题时首先要做的就是制定一个行动计划。
战略规划(作者: 法里德·汗 )
我们不能只是把整个问题抛给数据库,然后寄希望于最好的结果。我们需要教会智能体如何将问题分解成更小、更易于管理的部分。
为此,我们将创建一个专门的规划代理。我们需要给它一套非常明确的指令,即提示,准确地告诉它其工作内容。
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from rich.pretty import pprint as rprint
# The system prompt that instructs the LLM how to behave as a planner
planner_prompt = ChatPromptTemplate.from_messages([
("system", """You are an expert research planner. Your task is to create a clear, multi-step plan to answer a complex user query by retrieving information from multiple sources.
You have two tools available:
1. `search_10k`: Use this to search for information within NVIDIA's 2023 10-K financial filing. This is best for historical facts, financial data, and stated company policies or risks from that specific time period.
2. `search_web`: Use this to search the public internet for recent news, competitor information, or any topic that is not specific to NVIDIA's 2023 10-K.
Decompose the user's query into a series of simple, sequential sub-questions. For each step, decide which tool is more appropriate.
For `search_10k` steps, also identify the most likely section of the 10-K (e.g., 'Item 1A. Risk Factors', 'Item 7. Management's Discussion and Analysis...').
It is critical to use the exact section titles found in a 10-K filing where possible."""),
("human", "User Query: {question}") # The user's original, complex query
])我们基本上是在赋予大语言模型一个新的角色:专业研究规划师。我们明确告知它所拥有的两个工具(search_10k和search_web),并指导它何时使用每个工具。这就是“工具感知”部分。
我们不只是要求它制定一个计划,而是要求它制定一个能直接对应我们已构建能力的计划。
现在我们可以启动推理模型,并将其与我们的提示连接起来。这里非常重要的一步是告诉大语言模型(LLM),其最终输出必须采用我们的 Pydantic Plan 类的格式。这使得输出具有结构化和可预测性。
# Initialize our powerful reasoning model, as defined in the config
reasoning_llm = ChatOpenAI(model=config["reasoning_llm"], temperature=0)
# Create the planner agent by piping the prompt to the LLM and instructing it to use our structured 'Plan' output
planner_agent = planner_prompt | reasoning_llm.with_structured_output(Plan)
print("Tool-Aware Planner Agent created successfully.")
# Let's test the planner agent with our complex query to see its output
print("\n--- Testing Planner Agent ---")
test_plan = planner_agent.invoke({"question": complex_query_adv})
s# Use rich's pretty print for a clean, readable display of the Pydantic object
rprint(test_plan)我们将我们的planner_prompt输入到我们强大的reasoning_llm中,然后使用.with_structured_output(Plan)方法。这会告诉LangChain使用模型的函数调用能力,将其响应格式化为一个与我们的PlanPydantic模式完全匹配的JSON对象。这比尝试解析纯文本响应可靠得多。
让我们看看当我们用挑战查询对其进行测试时的输出结果。
#### OUTPUT ####
Tool-Aware Planner Agent created successfully.
--- Testing Planner Agent ---
Plan(
│ steps=[
│ │ Step(
│ │ │ sub_question="What are the key risks related to competition as stated in NVIDIA's 2023 10-K filing?",
│ │ │ justification="This step is necessary to extract the foundational information about competitive risks directly from the source document as requested by the user.",
│ │ │ tool='search_10k',
│ │ │ keywords=['competition', 'risk factors', 'semiconductor industry', 'competitors'],
│ │ │ document_section='Item 1A. Risk Factors'
│ │ ),
│ │ Step(
│ │ │ sub_question="What are the recent news and developments in AMD's AI chip strategy in 2024?",
│ │ │ justification="This step requires finding up-to-date, external information that is not available in the 2023 10-K filing. A web search is necessary to get the latest details on AMD's strategy.",
│ │ │ tool='search_web',
│ │ │ keywords=['AMD', 'AI chip strategy', '2024', 'MI300X', 'Instinct accelerator'],
│ │ │ document_section=None
│ │ )
│ ]
)如果我们查看输出结果,就会发现智能体并非只是给了我们一个模糊的计划,而是生成了一个结构化的计划对象。它正确地识别出查询包含两个部分。
-
对于第一部分,它知道答案在10-K文件中,并选择了search_10k工具,甚至正确猜出了正确的文档部分。
-
对于第二部分,它知道“2024年的新闻”不可能出现在2023年的文档中,并正确选择了search_web工具。这是我们的流程至少在思考过程中会产生有希望结果的第一个迹象。
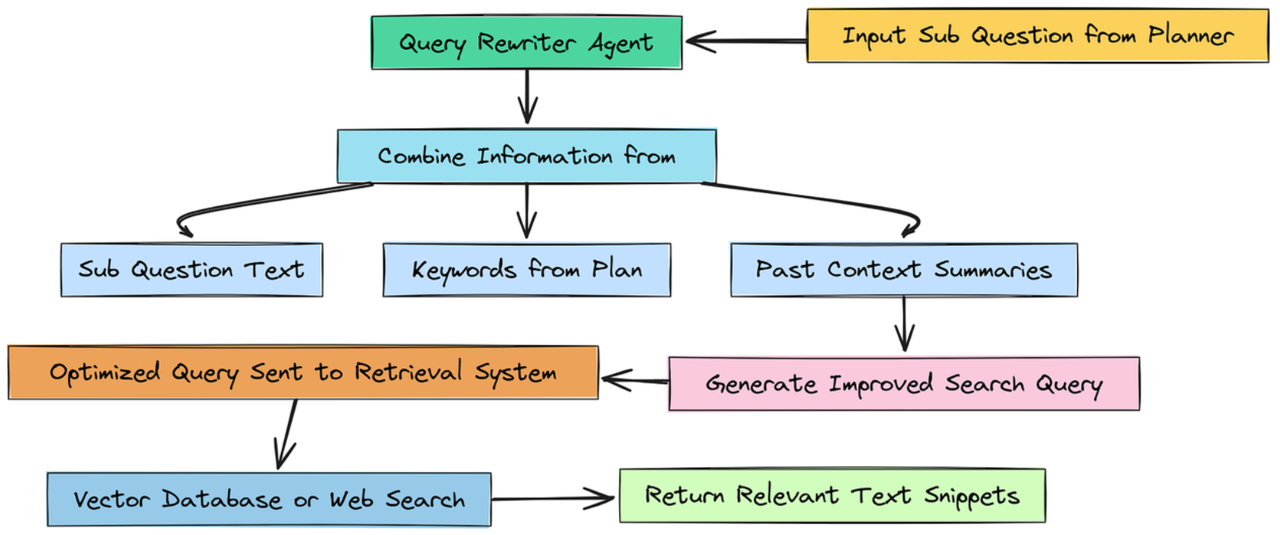
使用查询重写器代理优化检索
所以,基本上我们有一个包含良好子问题的计划。
但像“风险有哪些?”这样的问题并不是一个好的搜索查询。它太笼统了。搜索引擎,无论是向量数据库还是网络搜索,在处理具体、富含关键词的查询时效果最佳。
查询重写代理(作者: 法里德·汗 )
为了解决这个问题,我们将构建另一个小型的、专门的智能体:查询改写器。它的唯一任务是获取当前步骤的子问题,并通过添加相关关键词和我们已经掌握的上下文信息,使其更适合搜索。
首先,让我们为这个新代理设计提示词。
from langchain_core.output_parsers import StrOutputParser # To parse the LLM's output as a simple string
# The prompt for our query rewriter, instructing it to act as a search expert
query_rewriter_prompt = ChatPromptTemplate.from_messages([
("system", """You are a search query optimization expert. Your task is to rewrite a given sub-question into a highly effective search query for a vector database or web search engine, using keywords and context from the research plan.
The rewritten query should be specific, use terminology likely to be found in the target source (a financial 10-K or news articles), and be structured to retrieve the most relevant text snippets."""),
("human", "Current sub-question: {sub_question}\n\nRelevant keywords from plan: {keywords}\n\nContext from past steps:\n{past_context}")
])我们基本上是在告诉这个智能体要像搜索查询优化专家一样行事。我们为它提供了三条信息来开展工作:简单的子问题、我们的规划器已经确定的关键词,以及来自之前任何研究步骤的过往上下文。这为它提供了构建更好查询所需的所有原始材料。
现在我们可以启动这个代理了。这是一个简单的链,因为我们只需要一个字符串作为输出。
# Create the agent by piping the prompt to our reasoning LLM and a string output parser query_rewriter_agent = query_rewriter_prompt | reasoning_llm | StrOutputParser() print("Query Rewriter Agent created successfully.") # Let's test the rewriter agent. We'll pretend we've already completed the first two steps of our plan. print("\n--- Testing Query Rewriter Agent ---") # Let's imagine we are at a final synthesis step that needs context from the first two. test_sub_q = "How does AMD's 2024 AI chip strategy potentially exacerbate the competitive risks identified in NVIDIA's 10-K?" test_keywords = ['impact', 'threaten', 'competitive pressure', 'market share', 'technological change'] # We create some mock "past context" to simulate what the agent would know at this point in a real run. test_past_context = "Step 1 Summary: NVIDIA's 10-K lists intense competition and rapid technological change as key risks. Step 2 Summary: AMD launched its MI300X AI accelerator in 2024 to directly compete with NVIDIA's H100." # Invoke the agent with our test data rewritten_q = query_rewriter_agent.invoke({ "sub_question": test_sub_q, "keywords": test_keywords, "past_context": test_past_context }) print(f"Original sub-question: {test_sub_q}") print(f"Rewritten Search Query: {rewritten_q}")
为了正确测试这一点,我们必须模拟一个真实场景。我们创建一个test_past_context字符串,它代表代理从其计划的前两个步骤中已经生成的摘要。然后,我们将这个字符串与下一个子问题一起输入到我们的query_rewriter_agent中。
让我们看看结果。
#### OUTPUT ####
Query Rewriter Agent created successfully.
--- Testing Query Rewriter Agent ---
Original sub-question: How does AMD 2024 AI chip strategy potentially exacerbate the competitive risks identified in NVIDIA 10-K?
Rewritten Search Query: analysis of how AMD 2024 AI chip strategy, including products like the MI300X, exacerbates NVIDIA's stated competitive risks such as rapid technological change and market share erosion in the data center and AI semiconductor industry原始问题是针对分析师的,改写后的查询是针对搜索引擎的。它被赋予了特定术语,如“MI300X”、“市场份额侵蚀”和“数据中心”,所有这些都是从关键词和过往语境中综合得出的。
像这样的查询更有可能精确地检索到正确的文档,从而使我们的整个系统更加准确和高效。这一改写步骤将成为我们主要代理循环的关键部分。
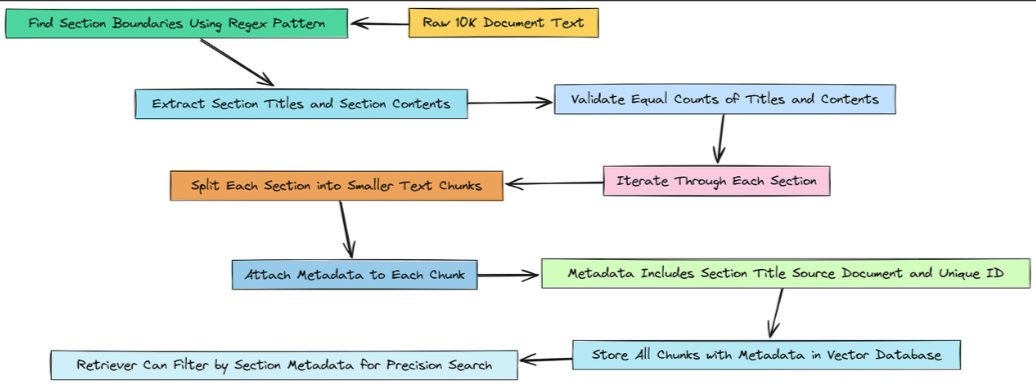
具备元数据感知分块功能的精准度
所以,基本上,我们的规划代理给了我们一个很好的机会。它不只是说查找风险,它还给了我们一个提示:在项目1A.风险因素部分查找风险。
但目前,我们的检索器还无法利用这一提示。我们的向量库只是一个包含378个文本块的大而扁平的列表。它根本不知道“章节”是什么。
元感知分块(作者: 法里德·汗 )
我们需要解决这个问题。我们将从头开始重建文档块。这一次,对于我们创建的每一个文档块,我们都将在其元数据中添加一个标签或标记,以准确告知我们的系统它来自10-K文件的哪一部分。这将使我们的代理能够在以后执行高度精确的过滤搜索。
首先,我们需要一种方法,以编程方式在原始文本文件中找到每个部分的起始位置。如果查看文档,我们可以看到一个明显的模式:每个主要部分都以单词“ITEM”开头,后面跟着一个数字,如“ITEM 1A”或“ITEM 7”。这正是正则表达式的用武之地。
# This regex is designed to find section titles like 'ITEM 1A.' or 'ITEM 7.' in the 10-K text.
# It looks for the word 'ITEM', followed by a space, a number, an optional letter, a period, and then captures the title text.
# The `re.IGNORECASE | re.DOTALL` flags make the search case-insensitive and allow '.' to match newlines.
section_pattern = r"(ITEM\\s+\\d[A-Z]?\\.\\s*.*?)(?=\\nITEM\\s+\\d[A-Z]?\\.|$)"我们基本上是在创建一个模式,它将作为我们的段落检测器。它的设计应该足够灵活,能够捕捉不同的格式,同时又足够具体,不会抓取错误的文本。
现在我们可以使用这种模式将文档分割成两个独立的列表:一个仅包含章节标题,另一个包含每个章节内的内容。
# We'll work with the raw text loaded earlier from our Document object
raw_text = documents[0].page_content
# Use re.findall to apply our pattern and extract all section titles into a list
section_titles = re.findall(section_pattern, raw_text, re.IGNORECASE | re.DOTALL)
# A quick cleanup step to remove any extra whitespace or newlines from the titles
section_titles = [title.strip().replace('\\n', ' ') for title in section_titles]
# Now, use re.split to break the document apart at each point where a section title occurs
sections_content = re.split(section_pattern, raw_text, flags=re.IGNORECASE | re.DOTALL)
# The split results in a list with titles and content mixed, so we filter it to get only the content parts
sections_content = [content.strip() for content in sections_content if content.strip() and not content.strip().lower().startswith('item ')]
print(f"Identified {len(section_titles)} document sections.")
# This is a crucial sanity check: if the number of titles doesn't match the number of content blocks, something went wrong.
assert len(section_titles) == len(sections_content), "Mismatch between titles and content sections"这是解析半结构化文档的一种非常有效的方法。我们使用了两次正则表达式模式:一次是获取所有章节标题的清晰列表,另一次是将正文拆分为内容块列表。断言语句让我们确信我们的解析逻辑是合理的。
好了,现在我们有了这些部分:一个标题列表和一个对应的内容列表。现在我们可以遍历它们,创建最终的、富含元数据的块。
import uuid # We'll use this to give each chunk a unique ID, which is good practice
# This list will hold our new, metadata-rich document chunks
doc_chunks_with_metadata = []
# Loop through each section's content along with its title using enumerate
for i, content in enumerate(sections_content):
# Get the corresponding title for the current content block
section_title = section_titles[i]
# Use the same text splitter as before, but this time, we run it ONLY on the content of the current section
section_chunks = text_splitter.split_text(content)
# Now, loop through the smaller chunks created from this one section
for chunk in section_chunks:
# Generate a unique ID for this specific chunk
chunk_id = str(uuid.uuid4())
# Create a new LangChain Document object for the chunk
doc_chunks_with_metadata.append(
Document(
page_content=chunk,
# This is the most important part: we attach the metadata
metadata={
"section": section_title, # The section this chunk belongs to
"source_doc": doc_path_clean, # Where the document came from
"id": chunk_id # The unique ID for this chunk
}
)
)
print(f"Created {len(doc_chunks_with_metadata)} chunks with section metadata.")
print("\n--- Sample Chunk with Metadata ---")
# To prove it worked, let's find a chunk that we know should be in the 'Risk Factors' section and print it
sample_chunk = next(c for c in doc_chunks_with_metadata if "Risk Factors" in c.metadata.get("section", ""))
print(sample_chunk)这是我们升级的核心。我们逐个遍历每个部分。对于每个部分,我们创建文本块。但在将它们添加到最终列表之前,我们会创建一个元数据字典,并附加部分标题。这有效地标记了每个文本块的来源。
让我们看看输出结果,找出差异。
#### OUTPUT ####
Processing document and adding metadata...
Identified 22 document sections.
Created 381 chunks with section metadata.
--- Sample Chunk with Metadata ---
Document(
│ page_content='Our industry is intensely competitive. We operate in the semiconductor\\nindustry, which is intensely competitive and characterized by rapid\\ntechnological change and evolving industry standards. We compete with a number of\\ncompanies that have different business models and different combinations of\\nhardware, software, and systems expertise, many of which have substantially\\ngreater resources than we have. We expect competition to increase from existing\\ncompetitors, as well as new and emerging companies. Our competitors include\\nIntel, AMD, and Qualcomm; cloud service providers, or CSPs, such as Amazon Web\\nServices, or AWS, Google Cloud, and Microsoft Azure; and various companies\\ndeveloping or that may develop processors or systems for the AI, HPC, data\\ncenter, gaming, professional visualization, and automotive markets. Some of our\\ncustomers are also our competitors. Our business could be materially and\\nadversely affected if our competitors announce or introduce new products, services,\\nor technologies that have better performance or features, are less expensive, or\\nthat gain market acceptance.',
│ metadata={
│ │ 'section': 'Item 1A. Risk Factors.',
│ │ 'source_doc': './data/nvda_10k_2023_clean.txt',
│ │ 'id': '...'
│ }
)看看那个元数据块。我们之前看到的同一文本块现在附加了一段上下文:'section': 'Item 1A. Risk Factors.'。
现在,当我们的代理需要查找风险时,它可以告诉检索器:“嘿,别搜索所有381个块。只搜索那些章节元数据为‘1A项。风险因素’的块”。
这一简单的改变将我们的检索器从一种粗糙的工具转变为一种精细的手术刀,它是构建真正生产级RAG系统的关键原则。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)