ControlNet:Adding Conditional Control to Text-to-Image Diffusion Models
ControlNet 通过“冻结原模型+学习控制信号”的轻量设计,为扩散模型赋予了精确的可控性,既保留了大模型的生成质量,又降低了定制化控制的门槛。它的出现不仅推动了 AIGC 从“随机生成”走向“精准创作”,也为普通用户提供了用“视觉语言”与 AI 协作的能力,成为连接创意与实现的重要桥梁。
ControlNet 是一种针对文本到图像扩散模型(如 Stable Diffusion)的增强技术,核心目标是通过引入额外的条件输入(如边缘图、姿态图、深度图等),解决传统扩散模型生成结果“不可控”的问题,让用户能精确引导图像生成的结构、姿态或细节。它由斯坦福大学团队于 2023 年提出,凭借高效性和强可控性,成为 AIGC 领域最具影响力的技术之一。

一、核心定位:让扩散模型“听话”
传统文本到图像模型(如早期 Stable Diffusion)主要依赖文本描述生成图像,但文本的模糊性(如“一个站着的人”)往往导致生成结果与预期偏差(比如姿态、结构不符合要求)。
ControlNet 的核心创新是:在不破坏原模型生成能力的前提下,通过“外挂”式的控制模块,让模型同时“看懂”文本和额外的视觉条件,从而生成既符合文本描述、又严格遵循视觉条件结构的图像。
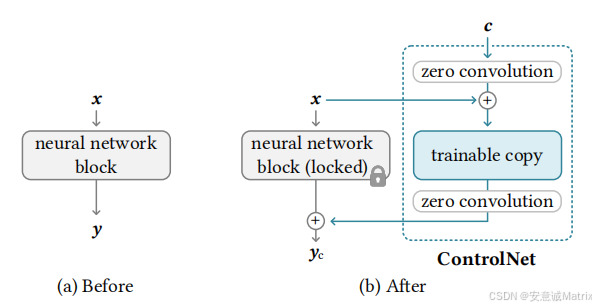
二、工作原理:“冻结-复制-融合”的巧妙设计
ControlNet 的架构设计兼顾了“保留原模型能力”和“学习控制条件”两大需求,核心逻辑可概括为三步骤:
1. 冻结原模型,保留基础能力
ControlNet 通常基于预训练的扩散模型(如 Stable Diffusion 的 U-Net 结构)工作。它会冻结原模型的所有参数(不参与训练),确保原模型的图像生成质量和文本理解能力不受影响。
2. 复制网络,学习控制信号
为了引入控制条件,ControlNet 会复制一份原模型的 U-Net 结构(称为“副本网络”),并让副本网络仅学习如何将控制条件融入生成过程。副本网络与原网络结构完全一致,但参数可训练。
3. 零卷积层:连接原网络与副本网络
原网络与副本网络通过“零卷积层”(Zero Convolution)连接。零卷积层的初始权重为 0,这意味着:
- 训练初期,副本网络的输出对原网络无影响(保证生成结果与原模型一致,避免破坏基础能力);
- 训练过程中,零卷积层逐渐学习权重,将副本网络提取的“控制特征”与原网络的“生成特征”融合,最终让控制条件影响生成结果。
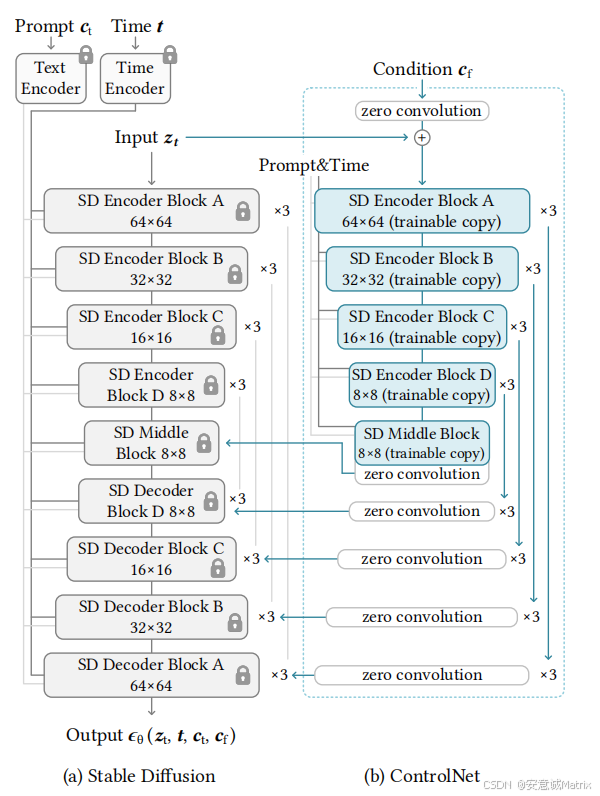
三、控制条件:支持多种“视觉语言”
ControlNet 支持多种类型的控制条件(输入),用户可通过这些“视觉语言”精确指定生成图像的结构或细节。常见条件包括:
| 控制条件类型 | 作用示例 | 应用场景 |
|---|---|---|
| Canny 边缘图 | 用线条勾勒物体轮廓,模型按轮廓生成细节 | 线稿上色、轮廓修复 |
| OpenPose 姿态图 | 用骨骼点定义人物动作,模型严格遵循姿态 | 动画角色设计、人体姿势控制 |
| 语义分割图 | 用不同颜色标记物体类别(如“人”“树”“车”) | 场景布局规划、物体位置控制 |
| 深度图 | 用灰度表示物体远近,控制画面立体感 | 3D 场景生成、透视校正 |
| HED 边缘图 | 更细腻的边缘检测(如发丝、布料褶皱) | 高精度插画生成 |
| 素描/涂鸦 | 粗糙手绘线条,模型将其转化为逼真图像 | 快速原型设计、创意草图实现 |

四、训练:高效且低成本
ControlNet 的训练设计非常“轻量”,这也是它能快速普及的关键原因:
- 数据需求低:仅需小规模“控制条件-目标图像”成对数据集(如 10k-50k 样本),无需重新训练整个扩散模型。例如,训练“OpenPose 控制”时,用带骨骼点的人体图和对应真实照片即可。
- 参数更新少:仅训练“副本网络”和“零卷积层”,原模型参数冻结,整体训练参数仅为原模型的 10%-20%。
- 硬件门槛低:单张 NVIDIA RTX 3090/4090 显卡即可完成训练(几天内可收敛),无需大规模算力集群。
五、核心优势
- 强可控性:生成结果严格贴合控制条件(如边缘、姿态),解决了文本描述“说不清、控不住”的问题。
- 兼容性广:可适配多种预训练扩散模型(如 Stable Diffusion v1.5/v2、SDXL 等),无需重构模型。
- 即插即用:训练好的 ControlNet 模型可作为插件集成到 WebUI(如 AUTOMATIC1111),普通用户无需代码即可使用。
- 泛化性强:同一套架构可支持多种控制条件,且训练后能迁移到未见过的场景(如用 COCO 数据集训练的模型,可处理用户自拍的姿态图)。
六、应用场景
ControlNet 已成为 AIGC 工具链的核心组件,广泛用于:
- 艺术创作:插画师用线稿生成上色作品,摄影师用深度图调整画面透视。
- 工业设计:产品设计师通过草图生成 3D 渲染图,快速验证创意。
- 动画与游戏:用 OpenPose 控制角色动作,批量生成连贯的动画帧。
- 医学与教育:根据器官轮廓图生成解剖示意图,辅助教学或诊断。
- 内容生产:自媒体用分割图控制视频封面的元素布局,提升制作效率。
七、发展与扩展
自 2023 年提出后,ControlNet 衍生出多个改进版本和扩展方向:
- ControlNet v2:优化了零卷积层设计,提升复杂条件下的控制精度(如多物体场景)。
- 多条件融合:支持同时输入多种控制条件(如“边缘图+深度图”),实现更精细的控制。
- 跨模态扩展:从图像控制延伸到视频(如控制视频中物体的运动轨迹)、3D 模型(如用 3D 网格生成对应图像)。
总结
ControlNet 通过“冻结原模型+学习控制信号”的轻量设计,为扩散模型赋予了精确的可控性,既保留了大模型的生成质量,又降低了定制化控制的门槛。它的出现不仅推动了 AIGC 从“随机生成”走向“精准创作”,也为普通用户提供了用“视觉语言”与 AI 协作的能力,成为连接创意与实现的重要桥梁。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 6
6 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)