Bright Data:为 AI 视频与多模态数据采集打造企业级基础设施
在AI驱动的时代,高质量多模态数据是推动AI引擎发展的关键,但数据采集面临技术瓶颈。Bright Data通过企业级基础设施解决了视频与网页数据采集的痛点,提供99.9%成功率的稳定抓取能力,支持AEO等新兴场景。通过N8N与Bright Data MCP的集成,可快速搭建自动化采集流程,输出结构化数据至AI训练管线,显著降低工程复杂度与成本。
在生成式 AI 与 LLM(大型语言模型)全面驱动内容创新的时代,高质量、多模态训练数据 已成为推动 AI 引擎(AI Engine)持续演进的燃料。无论是 AI 视频理解模型、音频语义引擎,还是新兴的 AI Engine Optimization(AEO)场景,模型的性能都深度依赖于高质量、规模化、稳定可得的视频与网页数据源。
然而,对于多数技术团队而言,数据采集仍是一道难以跨越的门槛。
一、AI 视频与网页数据采集的行业痛点
在视频与网页数据采集领域,即使是经验丰富的工程师,也常面临以下典型问题:
-
开源抓取工具频繁被封锁:
使用yt-dlp、youtube-dl等开源库进行视频采集时,极易遭遇 IP 封禁与 HTTP 429 错误。尤其在规模化抓取场景中,失败率高、任务中断成为常态。 -
代理与并发瓶颈导致成本飙升:
许多团队尝试自建代理池、接入第三方代理或轮换 IP,但在高并发、全球分布式采集下,系统复杂度与维护成本呈指数增长。 -
从 SEO 向 AEO 过渡的数据困境:
传统搜索引擎优化(SEO)正快速转型为 AI Engine Optimization(AEO)。企业需监控 AI 引擎榜单、AI 工具 SERP、品牌在 LLM 回答中的可见度等新指标,而相关数据的获取与解析却更加困难。
这些问题共同导致:抓取任务难以规模化、工程复杂度高、成功率不稳定、项目 ROI 受限。
二、Bright Data:企业级数据采集基础设施
Bright Data 凭借其全球领先的企业级网络基础设施,成为解决 AI 视频与网页数据采集痛点的理想方案。
① 世界级可靠性与抓取成功率
Bright Data 的底层由 原生分布式基础设施 构建,非第三方拼接代理,抓取成功率达 99.9%,在业内处于领先水平。
无论是 YouTube、TikTok、Bilibili 等视频平台,还是主流网站、SERP、社交媒体数据,均可稳定采集。
② 无限并发与无瓶颈性能
Bright Data 提供真正的企业级并发能力,无限任务扩展,无代理池维护瓶颈。
相比开源方案或小型代理商(如 Oxylabs、Apify、Axiom),Bright Data 能实现 全球范围内毫秒级响应与稳定负载均衡。
③ 已在头部 AI 实验室与企业验证
Bright Data 的解决方案已被全球顶级 AI 实验室、内容生成平台、AEO 优化公司采用,支撑真实生产级的多模态数据抓取任务。
④ 专注 AI/SEO/AEO 新趋势
针对新兴的 AI Engine Optimization(AEO) 场景,Bright Data 已积累成熟方案:
- 监控品牌在 AI 搜索中的曝光度
- 抓取 AI 工具 SERP、生成式搜索结果
- 构建多模态训练数据集(文本 + 视频 + 音频)
⑤ 灵活支付模式——“只为成功的数据付费”
Bright Data 提供按成功抓取计费机制,大幅降低测试和规模化部署的资金门槛。
三、实际操作:通过 N8N + Bright Data MCP 快速实现 AI 视频采集
Bright Data 不仅提供强大的 API,还能与自动化工作流平台(如 N8N)无缝集成,让技术团队几分钟内即可搭建生产级采集流程。
操作步骤如下:
-
注册并开启免费试用
访问 Bright Data 官方网站,注册账号并开启免费 $10 美金试用额度。 -
选择采集方案
本次我们的目标为每天定时采集最热门的Youtube中结构化内容:选择 Web Access API。-
采用N8N自动化工作流
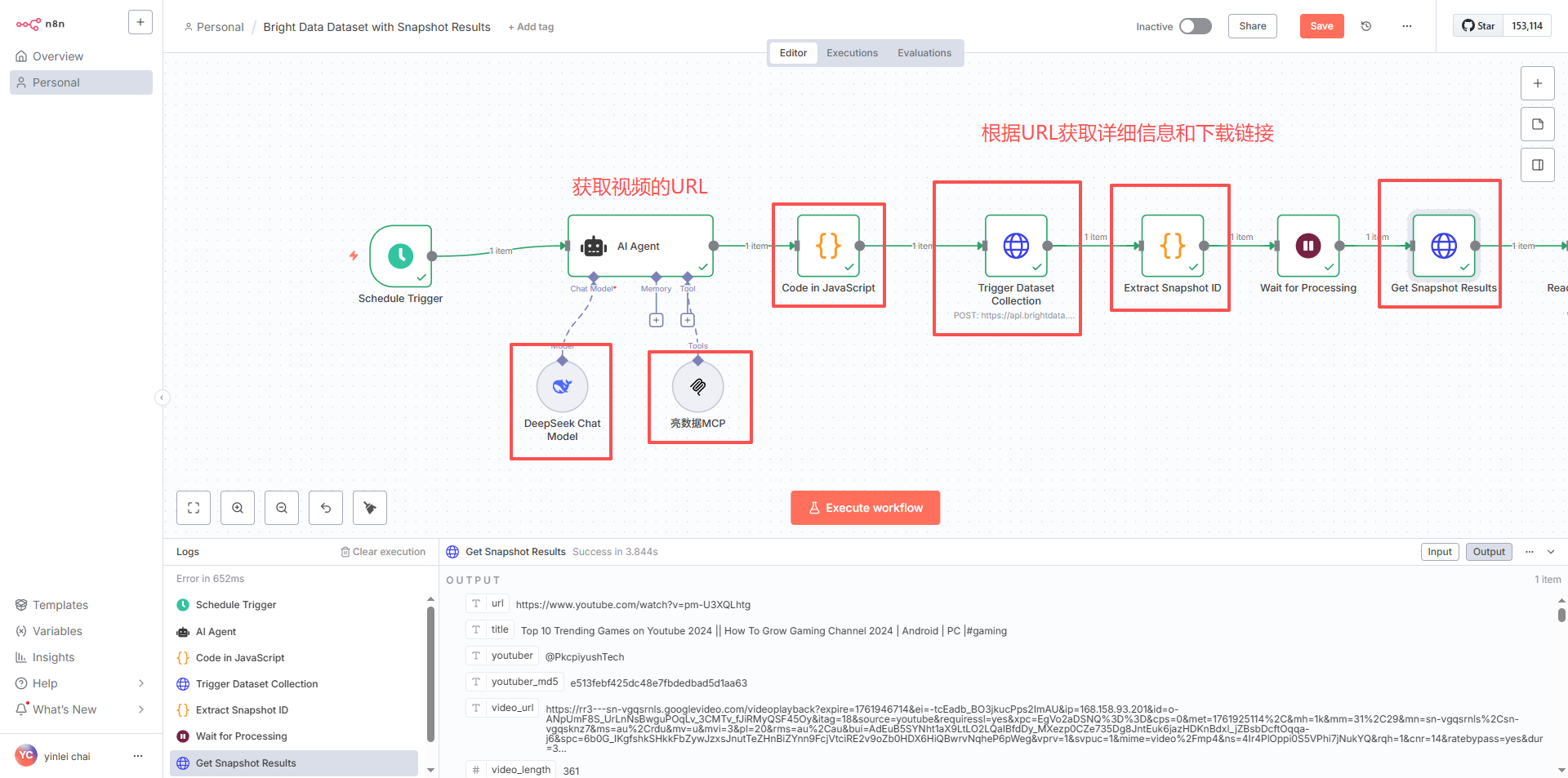
-
集成Bright Data 的MCP
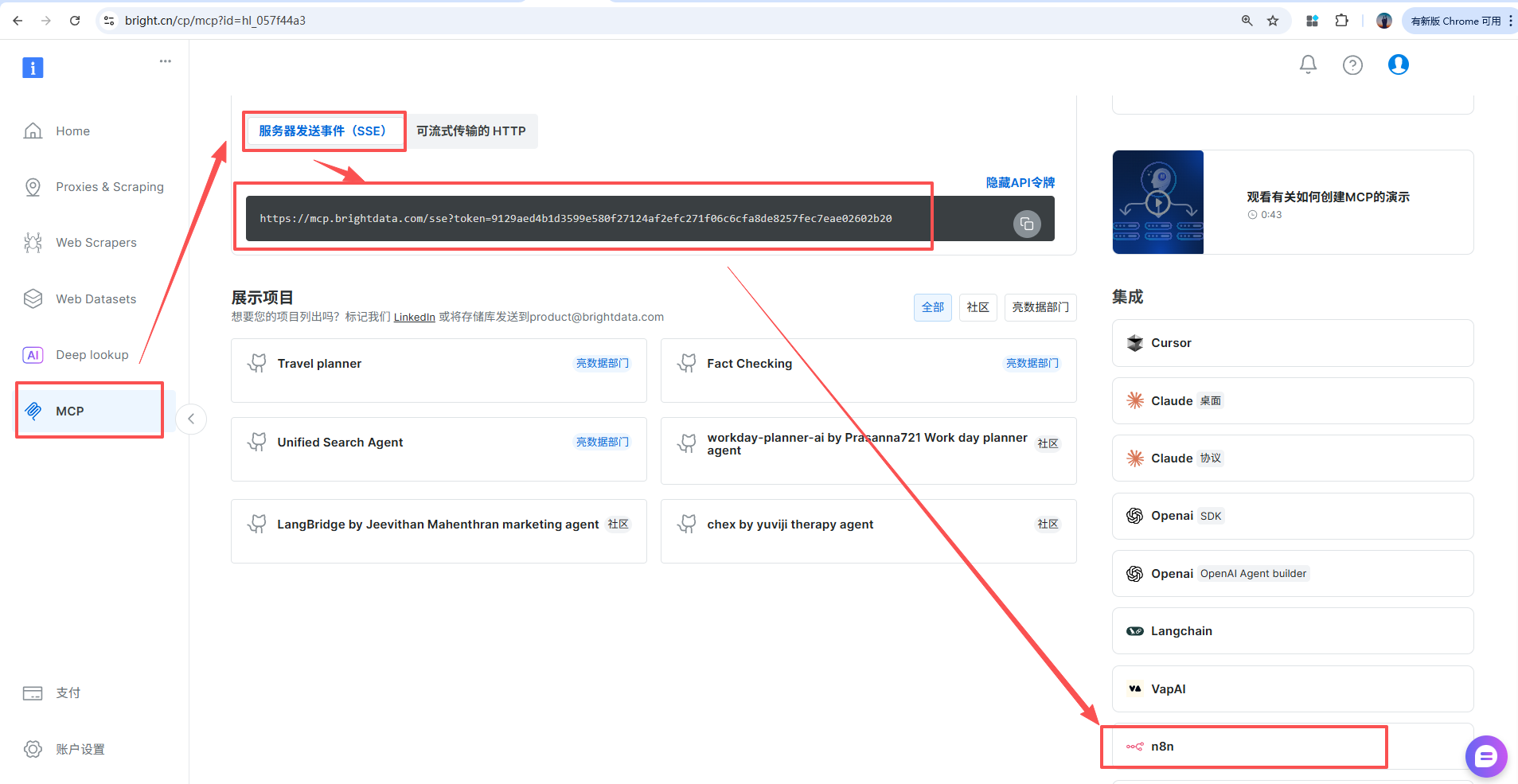
-
-
在 N8N 中配置 Bright Data MCP 节点
-
配置AIAgent 和 LLM
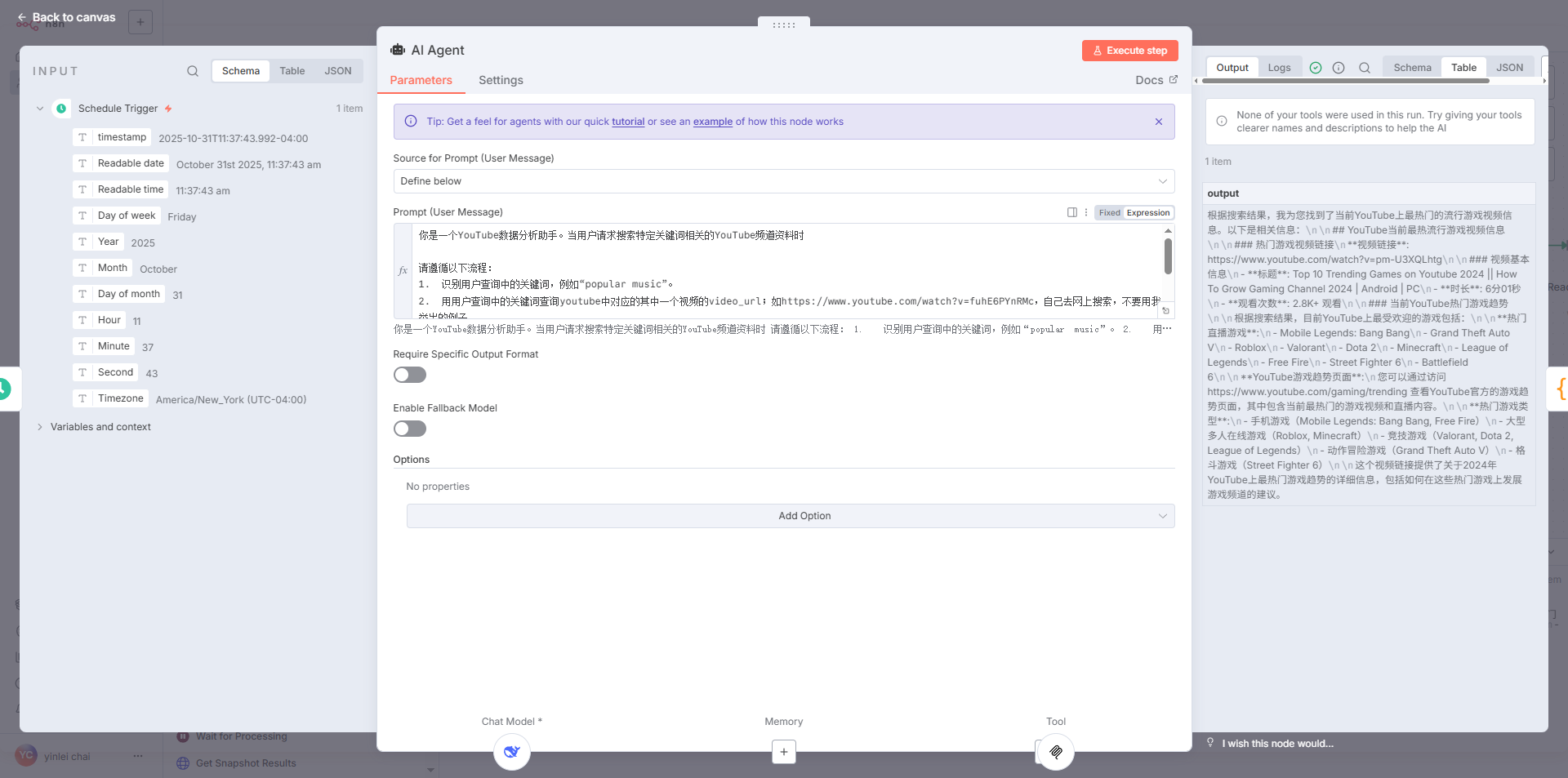
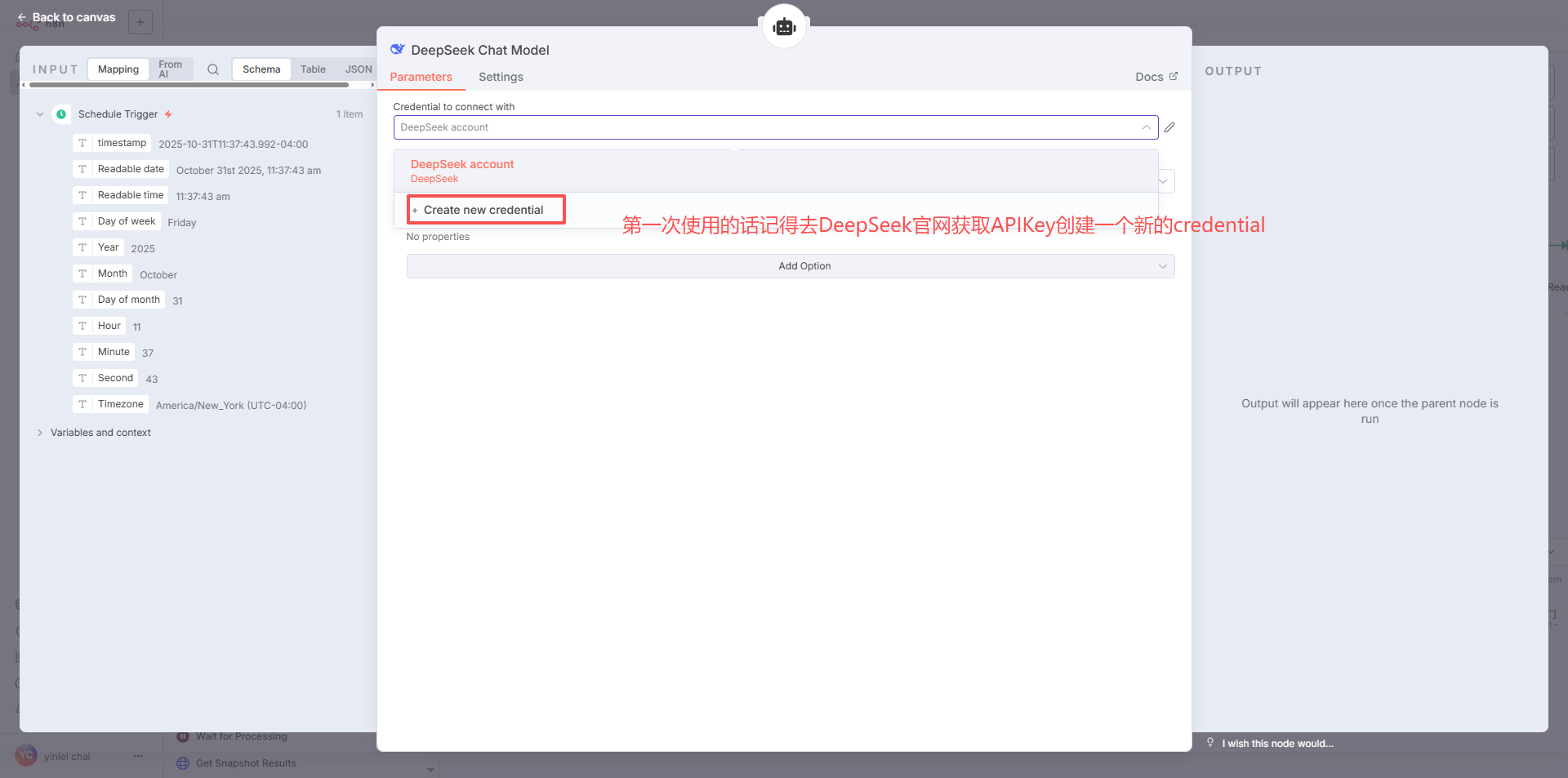
-
配置亮数据MCP节点和信息
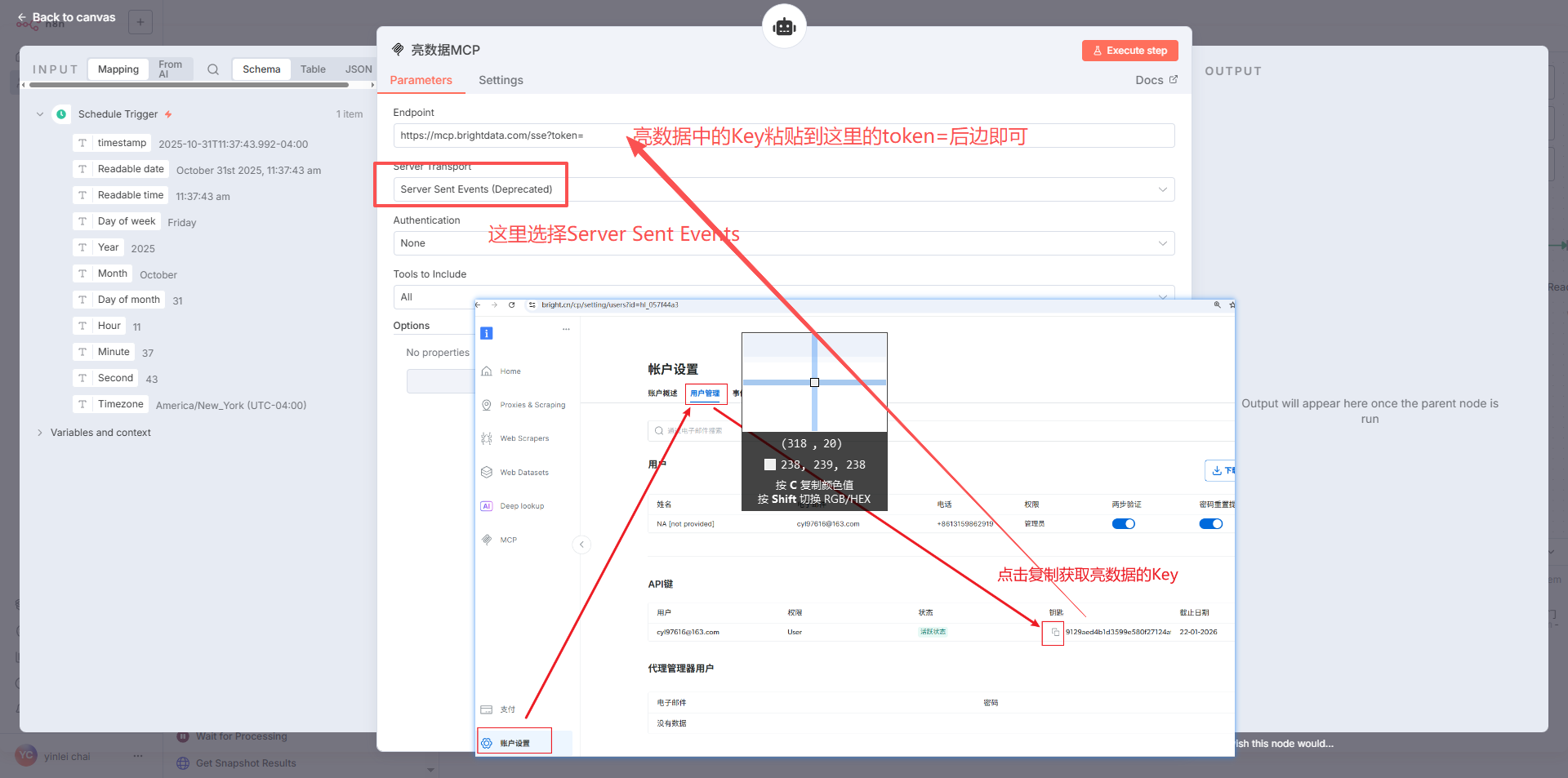
-
配置 URL、采集频率与并发数量
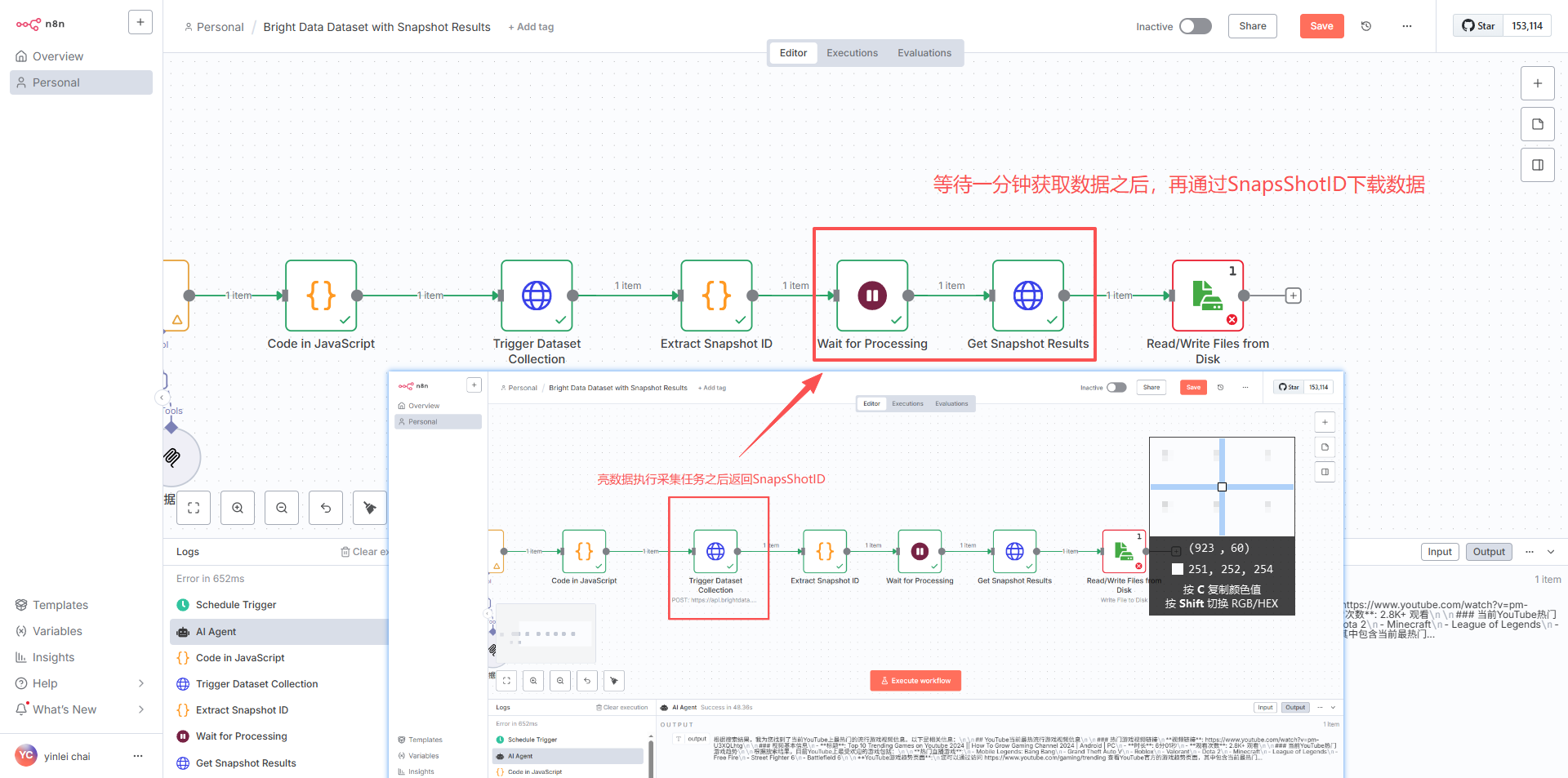
-
处理数据设置输出格式(JSON、CSV、Parquet 等)
-
-
输出结构化数据至你的 AI Pipeline
数据可直接进入数据仓库(如 Snowflake、BigQuery)或 LLM 训练管线中,当然也可以和我的工作流一样把数据是保存到文件中。 -
如有需要我的完整工作流如下(当然记得替换你的DeepSeek 的key 和亮数据的Key调试后测试运行):
{ "nodes": [ { "parameters": { "promptType": "define", "text": "=你是一个YouTube数据分析助手。当用户请求搜索特定关键词相关的YouTube频道资料时\n\n请遵循以下流程:\n1. 识别用户查询中的关键词,例如“popular music”。\n2. 用用户查询中的关键词查询youtube中对应的其中一个视频的video_url;如https://www.youtube.com/watch?v=fuhE6PYnRMc,自己去网上搜索,不要用我举出的例子\n3. 获得结果\n4. 提取结果中视频链接如:https://www.youtube.com/watch?v=fuhE6PYnRMc\n\n当前用户请求:获取youtube中当前最热的流行游戏视频信息", "options": {} }, "type": "@n8n/n8n-nodes-langchain.agent", "typeVersion": 2.2, "position": [ -768, 400 ], "id": "0c0b292a-25cb-4221-837a-e9f344919ed3", "name": "AI Agent" }, { "parameters": { "options": {} }, "type": "@n8n/n8n-nodes-langchain.lmChatDeepSeek", "typeVersion": 1, "position": [ -816, 624 ], "id": "48d23d70-e2c2-4731-892e-28f8c38c7adf", "name": "DeepSeek Chat Model", "credentials": { "deepSeekApi": { "id": "FIy2f0QvFHXX13et", "name": "DeepSeek account" } } }, { "parameters": { "method": "POST", "url": "https://api.brightdata.com/datasets/v3/trigger", "authentication": "predefinedCredentialType", "nodeCredentialType": "httpBearerAuth", "sendQuery": true, "queryParameters": { "parameters": [ { "name": "dataset_id", "value": "gd_lk56epmy2i5g7lzu0k" }, { "name": "include_errors", "value": "true" } ] }, "sendHeaders": true, "headerParameters": { "parameters": [ { "name": "Content-Type", "value": "application/json" } ] }, "sendBody": true, "specifyBody": "json", "jsonBody": "=[\n\t{\"url\":\"{{ $json.extracted_url[0] }}\",\"country\":\"\",\"transcription_language\":\"\"}\n] ", "options": {} }, "id": "212291b1-4eb8-4692-9c4e-da37adbd8580", "name": "Trigger Dataset Collection", "type": "n8n-nodes-base.httpRequest", "typeVersion": 4.2, "position": [ -128, 400 ], "credentials": { "httpBearerAuth": { "id": "Cj45MZf8S88fRooJ", "name": "Bearer Auth account" } } }, { "parameters": { "jsCode": "// Loop over input items and add a new field called 'myNewField' to the JSON of each one\nfor (const item of $input.all()) {\n item.json.myNewField = 1;\n}\n\nreturn $input.all();" }, "id": "919de066-4a81-4557-9617-a6add19028a3", "name": "Extract Snapshot ID", "type": "n8n-nodes-base.code", "typeVersion": 2, "position": [ 112, 400 ] }, { "parameters": { "unit": "minutes" }, "id": "664e1cf6-3ab2-4c51-9db9-ad1b1d39b945", "name": "Wait for Processing", "type": "n8n-nodes-base.wait", "typeVersion": 1, "position": [ 320, 400 ], "webhookId": "3c5f037d-542f-4c3f-8631-0b700c13fde2" }, { "parameters": { "url": "=https://api.brightdata.com/datasets/v3/snapshot/{{ $json.snapshot_id }}", "authentication": "predefinedCredentialType", "nodeCredentialType": "httpBearerAuth", "sendQuery": true, "queryParameters": { "parameters": [ { "name": "format", "value": "json" } ] }, "sendHeaders": true, "headerParameters": { "parameters": [ { "name": "Content-Type", "value": "application/json" } ] }, "options": { "timeout": 30000 } }, "id": "64454888-8b16-43a2-ac63-c09eb59c9819", "name": "Get Snapshot Results", "type": "n8n-nodes-base.httpRequest", "typeVersion": 4.2, "position": [ 528, 400 ], "credentials": { "httpBearerAuth": { "id": "Cj45MZf8S88fRooJ", "name": "Bearer Auth account" } } }, { "parameters": { "jsCode": "// 从上一节点获取输入的文本,这里假设是完整JSON中的第一个条目\nconst inputText = $input.first().json.output;\n\n// 使用正则表达式匹配URL\n// 这个正则表达式可以匹配常见的HTTP/HTTPS链接\nconst urlRegex = /https?:\\/\\/[^\\s\\]\\)]+/g;\n\nconst urls = inputText.match(urlRegex);\n\n// 如果没有找到URL,返回提示信息\nif (!urls) {\n return [{ json: { message: \"未在文本中找到URL\", original_text: inputText } }];\n}\n\n// 将提取到的所有URL(数组)作为输出\n// 如果文本中有多个URL,这里会全部返回;如果只需要第一个,可以用 urls[0]\nreturn [{ json: { extracted_url: urls } }];" }, "type": "n8n-nodes-base.code", "typeVersion": 2, "position": [ -416, 400 ], "id": "0e14cd33-5a6c-49e9-afbd-2d6101cc4a20", "name": "Code in JavaScript" }, { "parameters": { "endpointUrl": "https://mcp.brightdata.com/sse?token=", "serverTransport": "sse", "options": {} }, "type": "@n8n/n8n-nodes-langchain.mcpClientTool", "typeVersion": 1.2, "position": [ -608, 624 ], "id": "0b63ad99-efb0-4456-98a8-084d74864bcc", "name": "亮数据MCP" }, { "parameters": { "rule": { "interval": [ {} ] } }, "type": "n8n-nodes-base.scheduleTrigger", "typeVersion": 1.2, "position": [ -1072, 416 ], "id": "210d7995-e381-48a8-b1ea-18e58153774b", "name": "Schedule Trigger" }, { "parameters": { "operation": "write", "fileName": "={{ $json.title }}.json", "dataPropertyName": "={{ $json.video_url }}", "options": { "append": true } }, "type": "n8n-nodes-base.readWriteFile", "typeVersion": 1, "position": [ 768, 400 ], "id": "e2f3e0cd-b84d-4766-98fe-3a5df9a490d8", "name": "Read/Write Files from Disk", "executeOnce": true, "alwaysOutputData": false } ], "connections": { "AI Agent": { "main": [ [ { "node": "Code in JavaScript", "type": "main", "index": 0 } ] ] }, "DeepSeek Chat Model": { "ai_languageModel": [ [ { "node": "AI Agent", "type": "ai_languageModel", "index": 0 } ] ] }, "Trigger Dataset Collection": { "main": [ [ { "node": "Extract Snapshot ID", "type": "main", "index": 0 } ] ] }, "Extract Snapshot ID": { "main": [ [ { "node": "Wait for Processing", "type": "main", "index": 0 } ] ] }, "Wait for Processing": { "main": [ [ { "node": "Get Snapshot Results", "type": "main", "index": 0 } ] ] }, "Get Snapshot Results": { "main": [ [ { "node": "Read/Write Files from Disk", "type": "main", "index": 0 } ] ] }, "Code in JavaScript": { "main": [ [ { "node": "Trigger Dataset Collection", "type": "main", "index": 0 } ] ] }, "亮数据MCP": { "ai_tool": [ [ { "node": "AI Agent", "type": "ai_tool", "index": 0 } ] ] }, "Schedule Trigger": { "main": [ [ { "node": "AI Agent", "type": "main", "index": 0 } ] ] } }, "pinData": {}, "meta": { "templateCredsSetupCompleted": true, "instanceId": "c327b70663d6181004e2fbb9e290d0271d26bc9c1fa4f18664baa3234e1536c4" } }
四、Bright Data 相比竞品的核心差异
| 指标 | Bright Data | yt-dlp / youtube-dl | Oxylabs / Apify / Axiom |
|---|---|---|---|
| 抓取成功率 | 99.9%+ | 易被封锁 | 70–85%,受限于代理 |
| 并发能力 | 无限制、原生支持 | 单机有限 | 需自建或付高价扩容 |
| 支持场景 | AI 视频、网页、音频、多模态 | 仅视频 | 网页为主,AI 适配差 |
| 成本模式 | 按成功计费,灵活可控 | 免费但不可规模化 | 订阅+使用混合,复杂 |
| 企业支持 | 全程技术导入与优化 | 无支持 | 部分基础支持 |
五、Bright Data 助力 AI Engine Optimization(AEO)与多模态 AI 未来
随着 AI 引擎取代传统搜索入口,AEO(AI Engine Optimization) 成为增长型企业的新赛道。
从监控 AI 搜索结果,到优化品牌在生成式回答中的出现频率,再到构建自有 AI 训练数据集,Bright Data 正成为连接 AI 数据采集 → 模型训练 → 增长决策 的中枢平台。
六、立即体验企业级 AI 数据采集能力
如果您有如下使用场景:AI 视频数据、视频数据提取、大规模爬虫、AI 训练数据集、yt-dlp 替代方案、SEO for AI、多模态数据采集、生成式 AI 视频数据、AI 引擎优化、品牌监测 等。
立即注册 Bright Data 免费试用,领取 $10 美金额度,体验真正可扩展、可控、稳定的视频、网页、音频数据采集能力。👉 点击免费试用 Bright Data

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 25
25 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)