AI 真的是下一个互联网泡沫?黄仁勋的硬核回应藏着关键答案
【AI热潮与真实需求】针对近期"AI泡沫论",英伟达CEO黄仁勋指出AI与互联网泡沫的本质区别:GPU服务器的满负荷运转证明AI计算需求真实存在。关键差异在于:1)不同于互联网泡沫时期闲置的"暗光纤",当前GPU服务器持续高负载运行;2)AI模型训练需要海量并行计算,GPU架构完美适配;3)科研领域对高性能计算(如基因测序、气候模拟)的需求推动GPU服务器持
“AI 泡沫论” 最近又在圈内发酵 —— 有人说当前 AI 热和 2000 年互联网泡沫如出一辙,都是资本催生的虚假繁荣。但英伟达 CEO 黄仁勋一句话戳破本质:“两者唯一相似点是股票估值的疯狂,而 AI 的计算需求真实到无可辩驳”。这背后到底藏着什么关键差异?为什么 GPU 服务器成了破局的核心?今天用硬核知识帮你理清逻辑。

一、先搞懂 2 个关键知识点:暗光纤 vs GPU,泡沫与真实的分水岭
要理解黄仁勋的回应,首先得明确两个核心概念,这也是判断需求真伪的关键:
- 暗光纤:互联网泡沫的 “虚假基建”
所谓 “暗光纤”,是上世纪 90 年代互联网泡沫时期的典型产物 —— 行业疯狂铺设光缆,远超当时实际需求,这些闲置的光纤就成了 “暗光纤”,本质是人为制造的虚假需求。这也是互联网泡沫破裂的重要原因:基建与真实需求严重脱节。
- GPU 满负荷:AI 时代的 “真实刚需”
而现在的 AI 行业完全不同:黄仁勋明确表示 “几乎所有 GPU 都在被使用中”。这不是夸张 ——AI 模型从训练到推理,都需要海量并行计算:比如千亿参数大模型的训练,需要同时处理数百万个数据节点,这种任务只有 GPU 能胜任(CPU 擅长串行计算,效率差 1-2 个数量级)。这种满负荷运转的硬件需求,正是真实需求的最佳证明。
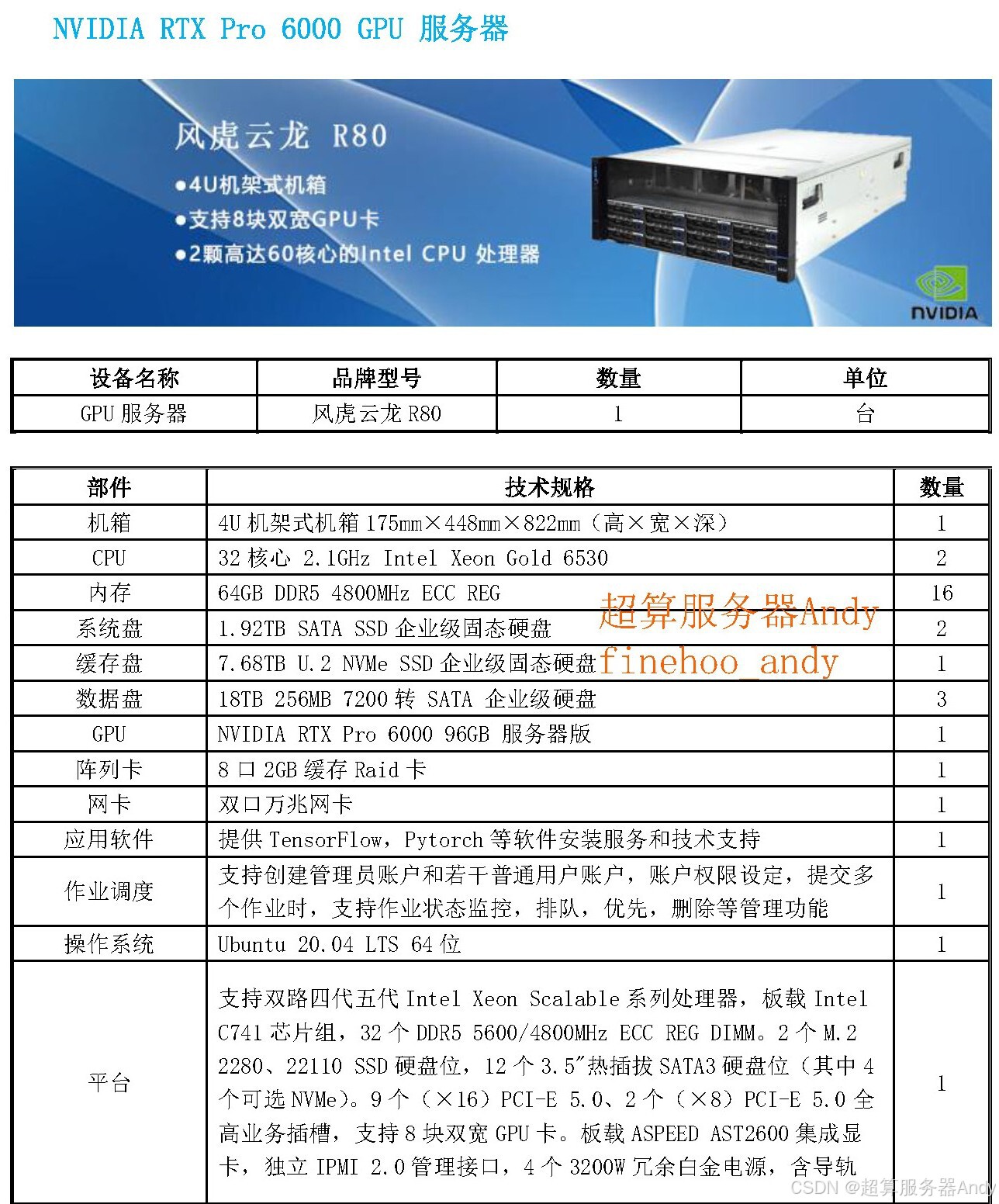
二、AI 与 GPU 服务器的深度绑定:为什么缺了它就没 “真实需求”?
很多人疑惑:AI 的计算需求,和 GPU 服务器到底是什么关系?答案很简单:GPU 服务器是 AI 真实需求的承载者,核心逻辑有 3 点:
- 硬件架构决定适配性:GPU 服务器搭载专业计算卡(如 NVIDIA H100),拥有数千个计算核心,擅长并行处理重复任务 —— 这刚好匹配 AI 模型训练、科学模拟等场景的需求,而普通服务器的 CPU 架构根本扛不住这种算力压力。
- 需求增长倒逼硬件升级:黄仁勋提到 “计算需求指数级增长”,对应的是 AI 模型从百亿参数向万亿参数突破,对算力的需求呈几何级上升。这就要求 GPU 服务器不断迭代:比如最新的 AI 服务器已支持 PCIe 5.0 接口、896GB/s GPU 互联带宽,才能跟上需求增速。
- 无闲置资源 = 真实需求:和 “暗光纤” 的闲置形成对比,AI 行业的 GPU 服务器长期处于高负载状态 —— 科研机构用它做基因测序、气候模拟,科技公司用它训练大模型,甚至医疗、制造领域的专用模型开发都离不开它,这种全场景满负荷使用,绝非人为制造的需求。
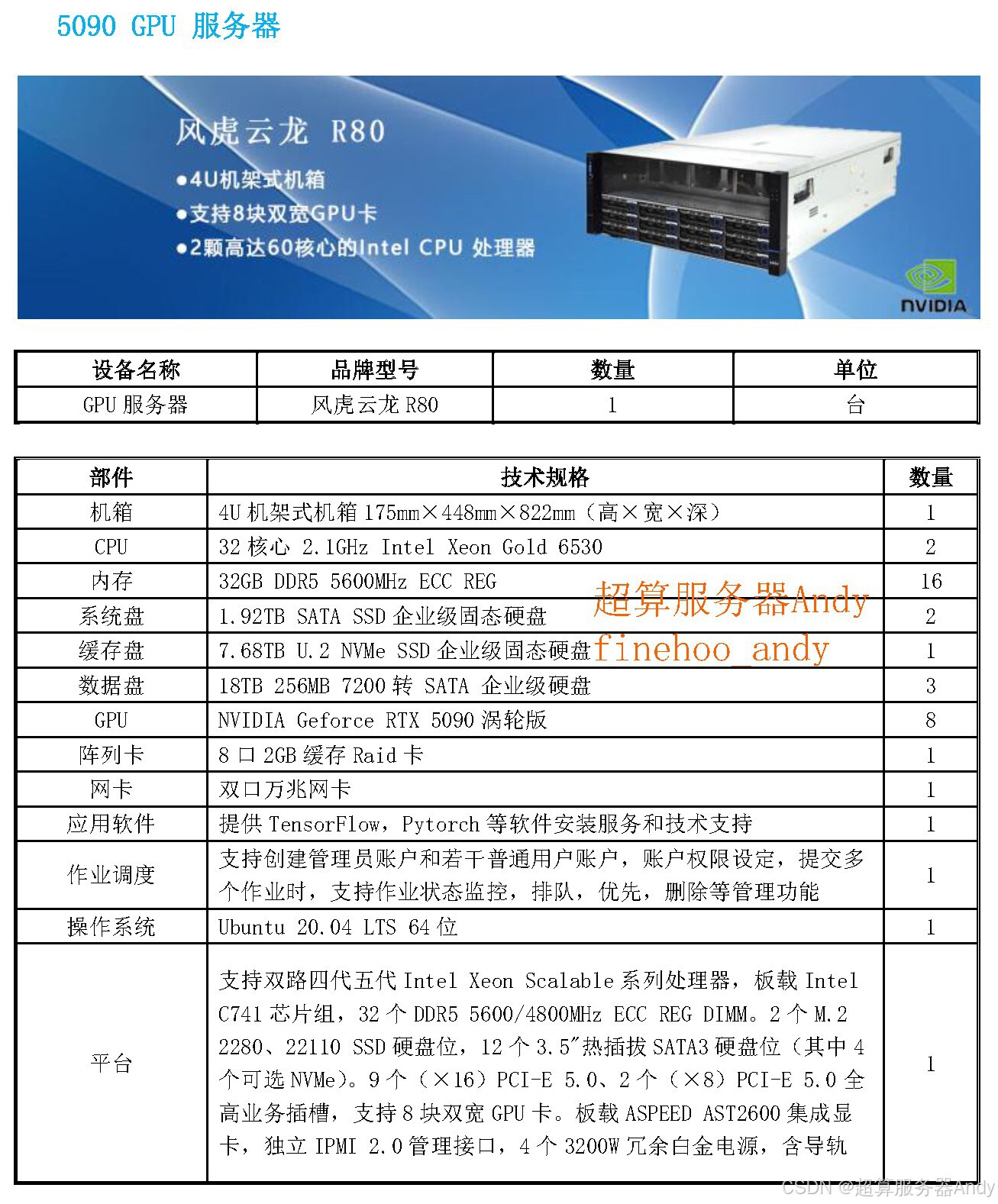
三、科研服务器为什么天生适合科研?3 个核心优势无可替代
既然 GPU 服务器是 AI 需求的核心,那为什么说它尤其适合科研场景?关键在于科研任务的特殊性与 GPU 服务器的适配性:
- 算力密度够高:科研场景常面临 “海量数据 + 复杂计算”—— 比如分子动力学模拟需要同时计算数十万原子的相互作用,GPU 服务器的单卡数百 TFLOPS 算力,能把原本需要数月的计算周期缩短到几天。
- 稳定性与扩展性强:科研计算不能中断(比如一次基因测序中断可能导致数据失效),GPU 服务器通常配备冗余电源、液冷散热(PUE 值低于 1.15),能保障 7x24 小时稳定运行;同时支持内存扩展至数 TB、多 GPU 集群部署,满足科研任务的迭代需求。
- 软件生态适配科研需求:科研常用的 TensorFlow、PyTorch 等框架,都针对 GPU 服务器做了深度优化;加上 ECC 纠错内存(避免数据计算错误)、高速 NVMe SSD(提升数据读写速度),完美匹配科研对精度和效率的双重要求。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 3
3 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)