RAG召回率优化:核心问题与实战策略
【摘要】召回率低的核心问题源于数据质量(拼写错误、格式不规范)和行业数据高相似性。解决方案采用动态数据切片技术(时间重叠/层级/实体识别)和大模型重排序(相关性打分/证据链生成)。工业场景实施案例显示显著改进(半导体故障代码召回率提升24%)。技术优化路径包括边缘计算部署、持续学习机制和标准化建设,需配合双重验证机制与多维监测体系。知识图谱和关键词递归查询可提升匹配效率,建议优先选用GPT系列模型
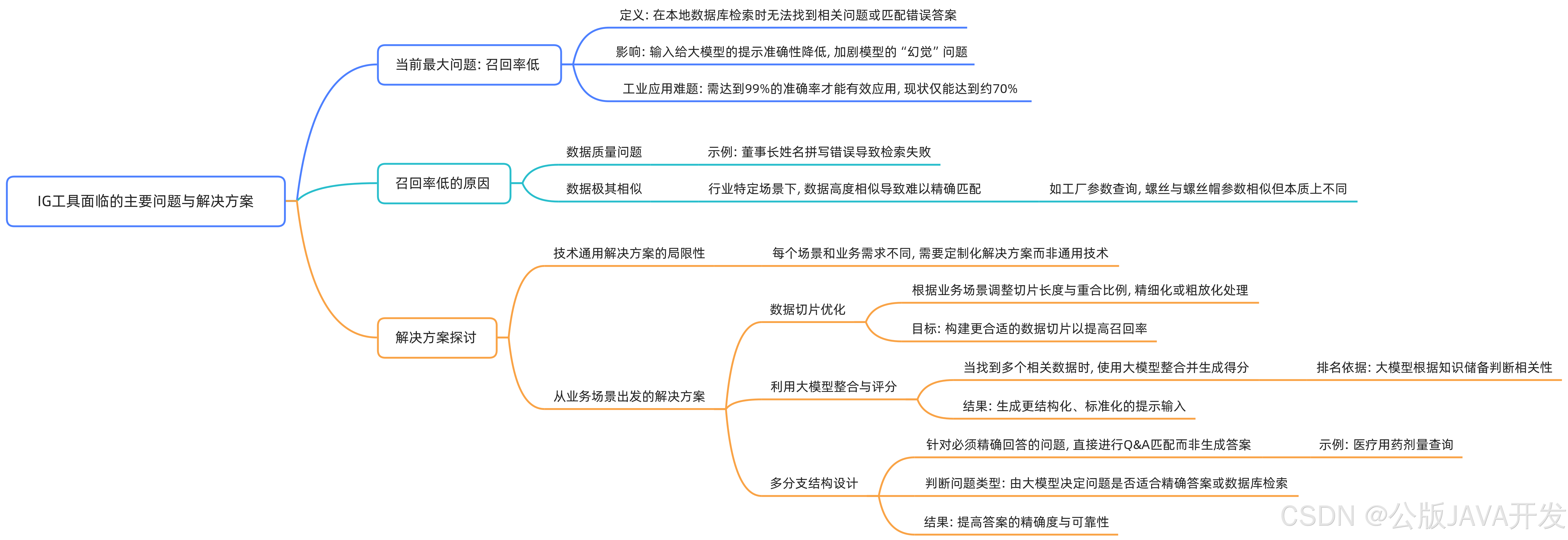
召回率低的核心问题分析
数据质量问题
本地数据存在姓名拼写错误、字段不规范等问题,直接影响检索准确性。例如工业参数查询中,"MPa"误写为"Mpa"或缺失单位,导致关键特征丢失。
行业数据高相似性
专业领域数据(如半导体工艺参数)常出现仅小数点或单位差异(如"5nm"与"7nm"制程),传统Embedding算法难以区分语义细微差别。
业务导向的优化策略
动态数据切片技术
- 对工厂设备日志采用时间重叠切片(窗口2分钟,重叠30%),捕捉连续操作上下文
- 对工艺文档按章节层级切片,保留"安全规范"等标签元数据
- 医疗场景采用实体识别切片,确保单个切片包含完整药品剂量信息
大模型驱动的重排序
使用GPT-4对初筛结果进行:
- 相关性打分:基于指令"从工业安全角度评估以下结果与问题'储罐压力标准'的匹配度,输出1-10分"
- 证据链生成:要求模型标注"匹配依据",如"匹配GB/T 150-2018条款3.2"
- 冲突检测:当多个结果矛盾时,触发人工审核规则
多分支架构设计
即时响应分支(QQA机制)
建立高频问题快速通道:
- 药品查询:"布洛芬儿童用量"直接映射到CFDA标准数据库条目
- 设备故障代码:"E201"直接关联维修手册第4.7节
- 采用CRC32校验确保答案版本一致性
语义解析分支
复杂问题处理流程:
- 问题分类:模型判断"反应釜温度曲线分析"需调用SCADA历史数据库
- 参数解构:提取"温度范围80-120℃""时间维度24h"等约束条件
- 混合检索:结合时间序列数据库与PDF工艺文档联合查询
工业场景实施案例
半导体设备维护
某晶圆厂实施后对比:
| 指标 | 优化前 | 优化后 |
|---|---|---|
| 故障代码召回 | 68% | 92% |
| 误匹配率 | 15% | 3.2% |
| 关键改进: |
- 设备手册切片增加"故障树"标签
- 引入BERT微调模型区分"ALARM 501"与"WARNING 501"
制药质量审计
采用动态阈值策略:
- 常规查询:相似度>0.85直接返回
- GMP关键条款:相似度>0.95且经质量QA模块复核
- 新增"数据溯源"要求,每个结果标注来源文件修订号
技术栈升级路径
边缘计算部署
- 采用瑞萨RZ/V2M处理器部署本地化模型,实现200ms级响应
- 硬件加速:
- 使用NPU处理Embedding计算
- 通过TinyML优化模型体积至<500MB
持续学习机制
- 构建反馈闭环:
- 记录每个查询的最终采纳结果
- 每周训练增量模型补偿bad case
- 对持续误判数据触发专项清洗
标准化建设
开发工业数据治理工具包:
- 字段校验器:强制"压力值+单位"组合输入
- 同义词库:建立"泵/Motor/传动装置"映射关系
- 版本快照:保留历史参数命名变更记录
风险控制措施
双重验证机制
对关键操作:
- 初级检索结果
- 经大模型生成执行摘要
- 与MES系统实时数据交叉验证
审计追踪
记录完整决策链:
{
"query": "反应釜压力阈值",
"final_answer": "设计压力1.2MPa(GB150)",
"decision_path": [
{"step": "vector_search", "top3": [0.87, 0.82, 0.79]},
{"step": "llm_rerank", "scores": [9.2, 6.5, 5.1]},
{"step": "regulation_check", "matched_clause": "GB150-2011 4.3.2"}
]
}
效能评估指标
构建多维监测体系:
- 基础指标:召回率、精确率、响应延迟
- 业务指标:
- 首次检索解决率(避免人工干预)
- 跨系统验证通过率
- 用户修正频率(反映结果可信度)
实施建议从试点场景开始,优先选择数据结构化程度高的设备维护场景,逐步扩展至工艺优化等复杂领域。定期开展"压力测试",模拟极端查询条件验证系统鲁棒性。
多分支处理与前处理机制
数据库或数据表根据问题类型分级,不同问题访问不同数据源。员工信息查询指向员工数据库,企业文化查询指向文化资料库。前处理机制通过上下文识别代词指代对象,例如“董事长”具体指向某人物。记忆网络整合原始问题,生成更精准的匹配答案。
关键词召回优化策略
关键词用于提高信息召回率,解决查找偏差问题。递归查询基于初始关键词定位相关文本,提取新关键词后继续扩展关联文档。关系网络引入人物社交关系、组织结构等附加信息。例如查询“董事长”时,补充其会议记录或下属汇报链。应用场景包括通过组织结构推理潜在冲突关系,如“谁可能对董事长不利”。
知识图谱在信息检索中的应用
知识图谱构建通过本地数据处理为结构化QA对,利用大语言模型(如GPT-3.5/4)自动化抽取内容并生成图谱。优势在于提升匹配效率与准确性,挑战在于前期图谱构建的工作量较大。
大模型选型建议
主流选择包括OpenAI模型(如GPT系列)和国内模型(如通义千问)。OpenAI模型效果更优但成本较高,国内模型适合中文场景且参数规模适中。推荐优先使用OpenAI模型,预算有限时可选择国内替代方案。
实施目标与未来方向
信息检索技术需结合业务场景设计多分支结构,提升召回率与准确率。核心目标是通过结构化设计和信息融合,使系统召回率达到90%以上,接近高效匹配的理想状态。未来需持续优化技术方案以适应动态需求。
IGS工具对RAG系统的自动化评估方法
核心评估指标
整体得分衡量RAG系统的综合表现,反映生成答案与真实答案的相关性,值越高越好。
上下文精度评估IG检索模块的质量,检查返回的上下文是否准确支持问题回答。
答案幻觉检测判断生成答案是否存在虚构内容,评估大模型结合上下文后的真实性。
答案相关性检测回答是否紧扣问题,避免语言流畅但偏离主题的情况。
数据准备要求
question字段需包含用户提出的问题。
context字段需由IG检索模块返回的相关上下文信息组成。
questioncontextanswer字段需包含大模型生成的回答。
ground truth字段需通过人工标注的理想答案,用于与生成答案对比。
数据格式需统一为list of list结构,建议准备几十至数百条样本以保证评估稳定性。
使用流程
通过pip install完成工具安装,需配置OpenAI API Key或其他等效密钥。
导入准备好的四字段数据集(question, context, answer, ground_truth)。
工具自动运行评估流程,调用大模型处理提示并生成结果。
结果存储后计算四项指标的具体得分,支持可视化分析不同模型性能差异。
适用场景与局限性
适用于通用场景的初步性能测试,具备开箱即用的低学习成本。
在医疗精准或企业特殊需求等非通用场景下,评估结果可能不可靠。
自动化工具无法替代人工对业务语义的理解,需结合人工评估判断实际表现。
多模型对比功能
支持横向比较不同embedding模型(如MS3E、BGE-OPI)的效果差异。
可评估不同大模型基座的表现,自动输出各模型在四项指标上的得分。
提供自动绘图功能,直观展示如7B级别模型间的性能对比结果。
Super DB 核心功能与特点
支持多种数据库类型(MySQL、MongoDB等),无需手动编写提取脚本,直接通过配置参数连接本地或远程数据库。
提供自动化数据检索与生成功能,支持将数据库内容用于模型微调(如PyTorch、Hugging Face)或作为外挂提示集成到第三方模型(如GPT)。
内置多模态任务处理能力,涵盖文本、图像等格式,适用于文档检索、问答生成等场景。
安装与基础配置
通过PIP安装,仅需运行命令:
pip install superdb
配置数据库连接参数,示例(MySQL):
from superdb import connect
db = connect(database_type="mysql", host="localhost", user="root", password="123456")
典型应用流程
连接数据库并加载数据
调用内置方法提取表数据,自动转换为模型可读格式:
data = db.query("SELECT * FROM products WHERE category='electronics'")
结合外部API与提示模板
使用官方提供的模板生成GPT提示,示例代码:
from superdb.templates import get_prompt
prompt = get_prompt("qa_template", context=data, question="推荐性价比高的笔记本电脑")
response = db.generate(prompt, api_key="your_gpt_key")
多模态任务扩展
处理图像数据时,直接调用图像检索模块:
images = db.load_images(table="product_images", condition="tag='promotion'")
高级集成场景
与Hugging Face模型协同训练:
from transformers import AutoModel
model = AutoModel.from_pretrained("bert-base-uncased")
db.fine_tune(model, data=data, epochs=3)
交互式开发支持:
通过Jupyter Notebook(interlab环境)快速调试,官方示例库包含数据增强、跨模态检索等案例。
优势总结
- 低代码实现:从数据连接到生成任务仅需3-5行代码。
- 全流程覆盖:支持从数据预处理到模型部署的全链路操作。
- 多框架兼容:无缝对接PyTorch、TensorFlow等主流框架。
建议访问官方文档查看完整示例,快速适配实际业务需求。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 22
22 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)