【LLM】大模型Mid-Training训练综述
中期训练技术总结,Mid-Training of Large Language Models: A Survey链接:https://arxiv.org/pdf/2510.06826,例如:MiniCPM中期训练使用20Btokens,混合预训练数据与高价值SFT数据(如SlimOrca、EvolInstruct),上采样推理/编码数据;Qwen3三阶段预训练,中期阶段(第二阶段)用5T高质量4K
Note
- 与传统预训练、微调(SFT)的核心区别。与预训练对比:预训练依赖海量、通用但噪声多的网页数据,追求“广度覆盖”;中期训练聚焦高质量、特定领域数据(如代码、数学、推理数据),通过上采样高价值数据、下采样噪声数据,实现“深度强化”;
- 与SFT对比:SFT针对具体任务(如对话、翻译)优化模型输出对齐;中期训练是通用能力增强阶段,不绑定特定任务,通过调整优化超参(如学习率)和扩展能力边界(如长上下文),为后续SFT奠定更强基础;
文章目录
一、大模型Mid-Training训练
中期训练技术总结,Mid-Training of Large Language Models: A Survey
链接:https://arxiv.org/pdf/2510.06826,
例如:
- MiniCPM中期训练使用20Btokens,混合预训练数据与高价值SFT数据(如SlimOrca、EvolInstruct),上采样推理/编码数据;
- Qwen3三阶段预训练,中期阶段(第二阶段)用5T高质量4K序列tokens,增加STEM(科学、技术、工程、数学)、编码、推理数据占比,第三阶段用数百亿tokens扩展长上下文
- OLMo2中期训练用Dolmino-Mix-1124数据集(含合成数学数据、代码数据),重复训练高价值子集,保留84%预训练分布。
看几个点:
1)中期训练定义。中期训练是LLM训练流程中,介于大规模预训练(依赖海量但噪声多的网页数据)与任务特定微调(SFT)之间的独立阶段,通过多轮“退火式”调整,让模型能力从“记忆”到“抽象”。核心解决预训练后期噪声数据导致收益递减【模型在推理、编码等能力上停滞(如额外计算投入但性能提升有限)】以及收敛稳定性问题【大规模预训练后模型接近最优解,大学习率易导致发散或不稳定】。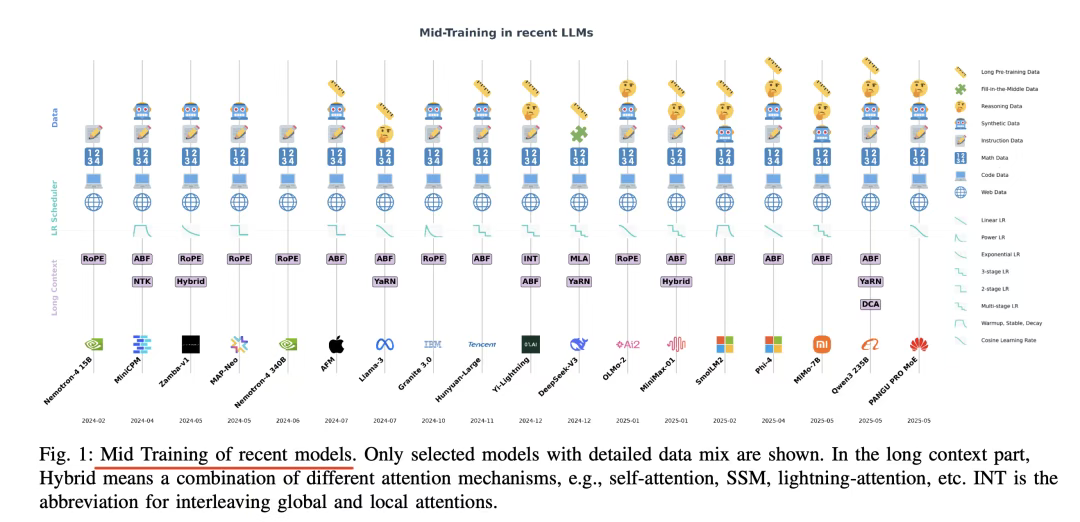
2)与传统预训练、微调(SFT)的核心区别。与预训练对比:预训练依赖海量、通用但噪声多的网页数据,追求“广度覆盖”;中期训练聚焦高质量、特定领域数据(如代码、数学、推理数据),通过上采样高价值数据、下采样噪声数据,实现“深度强化”;
与SFT对比:SFT针对具体任务(如对话、翻译)优化模型输出对齐;中期训练是通用能力增强阶段,不绑定特定任务,通过调整优化动力学(如学习率)和扩展能力边界(如长上下文),为后续SFT奠定更强基础;
3)实现思路。数据分布优化(转向高质量、特定领域数据)、学习率调度调整(如余弦/线性衰减、WSDscheduler)和长上下文扩展(如RoPE变体、ABF、YaRN)。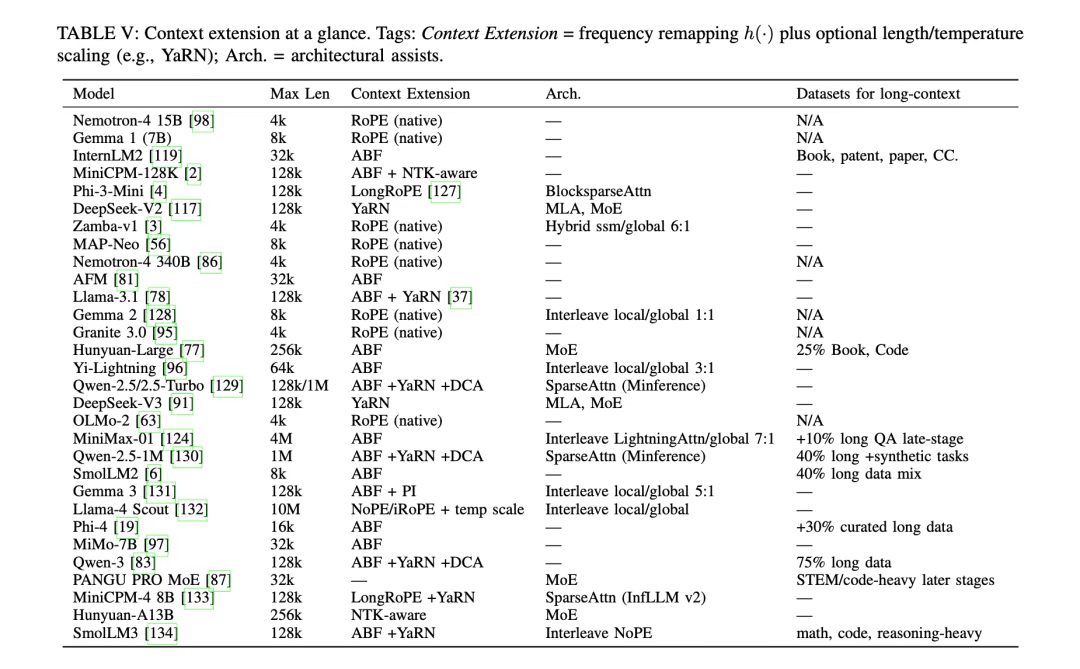
4)长上下文方案(PI、NTK-aware、YaRN、ABF)的适用场景。PI(位置插值),中小规模扩展(≤32K)、资源有限场景;NTK-aware,需保留局部细节的场景(如代码调试、短文本推理+长上下文);YaRN,中大规模扩展(32K-128K)、追求效率场景;BF(自适应基准频率),超大规模扩展(≥128K,如256K-1M)。企业选择建议:若需求为“轻量扩展至32K,低成本”:优先选PI,如中小模型(7B-13B)的文档摘要任务;若需求为“32K-128K,兼顾短上下文性能”:选YaRN,如客服对话系统(需长历史+短回复准确性);若需求为“超128K(如法律文档分析、多文件推理)”:选ABF+DCA/YaRN,如企业级知识库问答系统(如Qwen2.5-1M的1Mtokens支持);若场景需强局部细节(如代码长文件调试):选NTK-aware+交错注意力,平衡局部与全局理解。

其中,对于落地选型,有一些建议,例如:
- 若需求为“轻量扩展至32K,低成本”,优先选PI,如中小模型(7B-13B)的文档摘要任务;
- 若需求为“32K-128K,兼顾短上下文性能”,选YaRN,如客服对话系统(需长历史+短回复准确性);
- 若需求为“超128K(如法律文档分析、多文件推理)”,选ABF+DCA/YaRN,如企业级知识库问答系统(如Qwen2.5-1M的1Mtokens支持);
- 若场景需强局部细节(如代码长文件调试),选NTK-aware+交错注意力,平衡局部与全局理解。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 12
12 0
0- 0



 已为社区贡献72条内容
已为社区贡献72条内容

所有评论(0)