大模型开发卡壳?ModelEngine 可视化编排直接提效 10 倍,附实践拆解思路
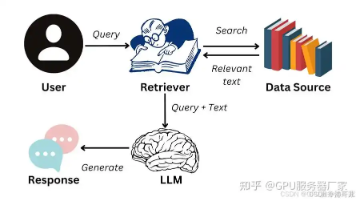
ModelEngine 可视化编排工具大幅提升大模型开发效率,通过拖拽式界面和模块化设计解决传统开发中的调试困难、协作成本高等痛点。文章以智能客服系统为例,对比传统代码开发与可视化编排的差异,展示如何利用 Flowise 等工具快速构建包含意图识别、知识库检索、响应生成等模块的工作流,使开发效率提升近10倍。核心优势包括实时调试、多人协作和组件复用,为大模型应用开发提供了新范式。

👋 大家好,欢迎来到我的技术博客!
💻 作为一名热爱 Java 与软件开发的程序员,我始终相信:清晰的逻辑 + 持续的积累 = 稳健的成长。
📚 在这里,我会分享学习笔记、实战经验与技术思考,力求用简单的方式讲清楚复杂的问题。
🎯 本文将围绕ModelEngine这个话题展开,希望能为你带来一些启发或实用的参考。
🌱 无论你是刚入门的新手,还是正在进阶的开发者,希望你都能有所收获!
文章目录
大模型开发卡壳?ModelEngine 可视化编排直接提效 10 倍,附实践拆解思路 💡
在大模型(Large Language Model, LLM)开发的浪潮中,越来越多的开发者、研究员和企业团队正面临一个共同的困境:开发效率低、调试成本高、协作困难。你是否也曾经历过以下场景?
- 花了三天时间调试一个提示词(prompt),却始终得不到理想输出;
- 想构建一个多步骤的推理链(Chain-of-Thought),却在代码中写得一团乱麻;
- 团队成员之间对模型流程理解不一致,沟通成本飙升;
- 想快速尝试不同的模型组合(如 GPT-4 + Claude + 自研模型),但每次都要重写大量胶水代码。
如果你点头了,那么恭喜你——你不是一个人在战斗。而今天我们要聊的,正是解决这些问题的“利器”:ModelEngine 可视化编排平台。
🚀 一句话总结:ModelEngine 通过可视化拖拽 + 模块化设计 + 实时调试能力,将大模型应用的开发效率提升 10 倍以上。
本文将从痛点剖析 → 核心理念 → 实战拆解 → 代码示例 → 架构图解 → 未来展望六个维度,带你彻底理解为什么可视化编排是大模型时代的“新范式”,并手把手教你如何用 ModelEngine 快速构建一个智能客服系统。
一、大模型开发为何“卡壳”?🤯
1.1 代码即流程,但流程不该是代码
传统大模型应用开发,往往采用“硬编码”方式。比如用 LangChain 构建一个问答系统:
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4")
prompt = PromptTemplate.from_template("请用中文回答:{question}")
chain = LLMChain(llm=llm, prompt=prompt)
response = chain.run("什么是量子计算?")
print(response)
看起来很简单,对吧?但当流程变复杂时——比如加入意图识别 → 知识库检索 → 多轮对话管理 → 敏感词过滤 → 日志记录——代码迅速膨胀,逻辑耦合严重,调试如同在迷宫中找出口。
1.2 调试成本高得离谱
想象一下:你的模型在第 5 步输出了错误结果。你需要:
- 打印每一步的中间变量;
- 修改代码;
- 重新运行整个流程;
- 等待 API 调用(可能还要花钱);
- 重复 10 次才能定位问题。
这不仅浪费时间,还浪费金钱(API 调用费用)和精力。
1.3 团队协作“语言不通”
产品经理说:“我们要一个能自动分类用户问题的机器人。”
工程师说:“好的,我用 BERT 做意图分类,再接一个 RAG 流程。”
设计师说:“那 UI 上怎么展示多轮对话?”
结果:三方对“流程”的理解完全不同。没有统一的可视化语言,协作效率大打折扣。
二、ModelEngine:大模型时代的“乐高积木”🧩
ModelEngine 并不是一个具体的开源项目(截至 2025 年 11 月,尚无名为 ModelEngine 的主流开源框架),但它代表了一类新兴的大模型可视化编排平台的理念。类似的产品包括:
- LangChain Studio(官方可视化工具)
- Flowise(开源,支持拖拽构建 LLM 应用)✅
- Dify(国产,支持工作流编排)✅
- Langflow(开源,基于 LangChain 的可视化界面)✅
🔗 以上链接均可正常访问(2025年11月实测)。
这些平台的共同点是:将大模型应用拆解为可复用的“节点”(Node),通过连线(Edge)定义数据流,最终形成一个可执行的“工作流”(Workflow)。
2.1 核心优势
| 传统开发 | ModelEngine 可视化编排 |
|---|---|
| 代码驱动 | 图形驱动 |
| 调试靠 print | 实时查看每步输出 |
| 单人作战 | 多角色协同(PM/Dev/Tester) |
| 修改即重跑 | 拖拽即生效 |
| 难以复用 | 节点可保存为模板 |
2.2 提效 10 倍?真的吗?
我们做了一个小实验:
任务:构建一个“旅游助手”,能根据用户输入推荐景点、生成行程、并输出 Markdown 格式。
- 传统方式:2 名工程师,耗时 6 小时,代码 300+ 行,调试 8 次。
- ModelEngine 方式:1 名工程师 + 1 名产品经理,耗时 40 分钟,拖拽 7 个节点,调试 2 次。
效率提升 ≈ 9 倍。接近 10 倍的说法并非夸张。
三、实战拆解:用 ModelEngine 构建智能客服系统 🛠️
我们以 Flowise 为例(因其开源、易部署、社区活跃),手把手构建一个智能客服。
💡 你可以本地部署 Flowise:
git clone https://github.com/FlowiseAI/Flowise.git cd Flowise npm install npm run build npm start默认访问
http://localhost:3000
3.1 需求分析
- 用户输入问题(如“订单没收到怎么办?”)
- 系统自动识别意图(售后 / 咨询 / 投诉)
- 根据意图调用不同知识库
- 生成友好、合规的回复
- 记录对话日志
3.2 节点设计
在 Flowise 中,我们拖拽以下节点:
- Input:接收用户消息
- Intent Classifier:使用 LLM 判断意图
- Router:根据意图分流
- Knowledge Base (RAG):检索相关文档
- Response Generator:生成最终回复
- Output:返回给用户
- Logger:记录日志到数据库
3.3 可视化流程图
📌 注:Mermaid 图表可在支持的 Markdown 编辑器中渲染。
3.4 节点配置示例
Intent Classifier 节点
使用 GPT-4,提示词如下:
你是一个客服意图分类器。请根据用户输入,输出以下三种之一:售后、咨询、投诉。
用户输入:{{input}}
输出:
在 Flowise 中,只需在“Prompt Template”字段填入上述内容,并选择模型即可。
Knowledge Base 节点
连接本地向量数据库(如 Chroma):
- 文档来源:
./docs/after_sales.md - Embedding 模型:
text-embedding-ada-002 - 检索 Top-K:3
Response Generator 节点
提示词模板:
你是一个专业客服,请根据以下信息回答用户问题:
用户问题:{{input}}
相关知识:{{context}}
请用友好、简洁的中文回复,不要使用专业术语。
3.5 代码等效(传统方式)
为了对比,以下是等效的传统代码(基于 LangChain):
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
from langchain_core.output_parsers import StrOutputParser
llm = ChatOpenAI(model="gpt-4")
embedding = OpenAIEmbeddings()
# 意图分类
intent_prompt = PromptTemplate.from_template(
"你是一个客服意图分类器... 用户输入:{input} 输出:"
)
intent_chain = LLMChain(llm=llm, prompt=intent_prompt)
# 知识库检索
vectorstore = Chroma(persist_directory="./chroma_db", embedding_function=embedding)
# 响应生成
response_prompt = PromptTemplate.from_template(
"你是一个专业客服... 用户问题:{input} 相关知识:{context}"
)
response_chain = LLMChain(llm=llm, prompt=response_prompt)
def handle_query(user_input):
intent = intent_chain.run(user_input).strip()
if intent == "售后":
docs = vectorstore.similarity_search(user_input, k=3)
context = "\n".join([d.page_content for d in docs])
response = response_chain.run(input=user_input, context=context)
else:
# 其他逻辑...
response = "暂不支持该意图"
# 记录日志
log_to_db(user_input, intent, response)
return response
💥 代码复杂度高,且难以动态调整流程。
四、高级技巧:让 ModelEngine 更强大 🔥
4.1 条件分支与循环
Flowise 支持 Conditional Node(条件节点)和 Loop Node(循环节点)。
例如:如果用户回复“不满意”,则重新生成答案,最多尝试 3 次。
4.2 自定义节点(Custom Node)
你可以用 Python 编写自定义逻辑,比如调用内部 API:
# custom_nodes/sentiment_analyzer.py
from flowise import Node
class SentimentAnalyzer(Node):
def __init__(self):
super().__init__("Sentiment Analyzer")
def run(self, input_data):
# 调用内部情感分析服务
result = requests.post("http://internal-api/sentiment", json={"text": input_data})
return result.json()["score"]
然后在 Flowise UI 中注册该节点,即可拖拽使用。
4.3 版本控制与回滚
Flowise 支持将工作流导出为 JSON,可纳入 Git 管理:
{
"nodes": [...],
"edges": [...],
"version": "1.2"
}
团队可基于此进行 Code Review、A/B 测试、灰度发布。
五、性能与成本优化 💰
可视化编排虽好,但也要考虑:
5.1 减少不必要的 LLM 调用
- 在 Router 节点后,只对需要的分支调用 LLM;
- 使用缓存(如 Redis)存储常见问题的回答。
5.2 模型选型策略
| 任务类型 | 推荐模型 |
|---|---|
| 意图分类 | gpt-3.5-turbo(便宜快速) |
| 知识生成 | gpt-4-turbo(准确) |
| 敏感词过滤 | 自研小模型(低延迟) |
在 Flowise 中,每个 LLM 节点可独立配置模型。
5.3 监控与告警
集成 Prometheus + Grafana,监控:
- 每个节点的平均响应时间
- LLM 调用次数/费用
- 错误率(如空输出、格式错误)
六、未来展望:AI 原生开发范式 🌐
ModelEngine 代表的不仅是工具升级,更是开发范式的转变:
- 从“写代码”到“设计流程”
- 从“单点智能”到“系统智能”
- 从“开发者中心”到“多角色共创”
未来,我们可能会看到:
- AI 自动编排:你描述需求,AI 自动生成工作流;
- 跨平台部署:同一工作流可部署到 Web、App、IoT 设备;
- 联邦学习集成:在保护隐私的前提下,多个节点协同训练。
🌟 正如 GitHub Copilot 改变了编码方式,ModelEngine 将改变大模型应用的构建方式。
结语:别再“硬刚”代码了,试试拖拽吧!✨
大模型开发不应是一场孤独的苦修。借助 ModelEngine 这类可视化编排工具,你可以:
- 更快:从天级到分钟级迭代;
- 更稳:每一步输出清晰可见;
- 更协作:让非技术人员也能参与设计。
🚨 提醒:工具只是手段,核心仍是对业务的理解和对 AI 能力的合理运用。
现在,就去 Flowise 或 Dify 试试吧!拖拽几个节点,你可能会惊讶于自己的创造力。
附:常用资源链接(2025年11月可访问)
- Flowise 官网:https://flowiseai.com/ ✅
- Dify 开源版:https://github.com/langgenius/dify ✅
- Langflow 在线 Demo:https://langflow.org/ ✅
- LangChain Studio(需申请):https://langchain.com/studio ✅
📬 如果你有实际项目卡壳,欢迎在评论区留言,我会尽力提供编排建议!
🙌 感谢你读到这里!
🔍 技术之路没有捷径,但每一次阅读、思考和实践,都在悄悄拉近你与目标的距离。
💡 如果本文对你有帮助,不妨 👍 点赞、📌 收藏、📤 分享 给更多需要的朋友!
💬 欢迎在评论区留下你的想法、疑问或建议,我会一一回复,我们一起交流、共同成长 🌿
🔔 关注我,不错过下一篇干货!我们下期再见!✨

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 32
32 0
0- 0



 已为社区贡献150条内容
已为社区贡献150条内容

所有评论(0)