RAG检索与排序增强机制深度解析:从DPR与ColBERT架构差异到多阶段协同优化
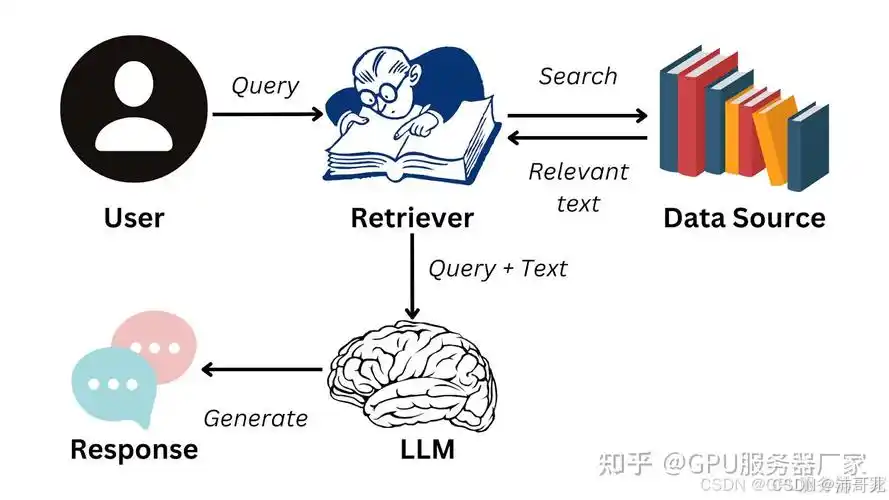
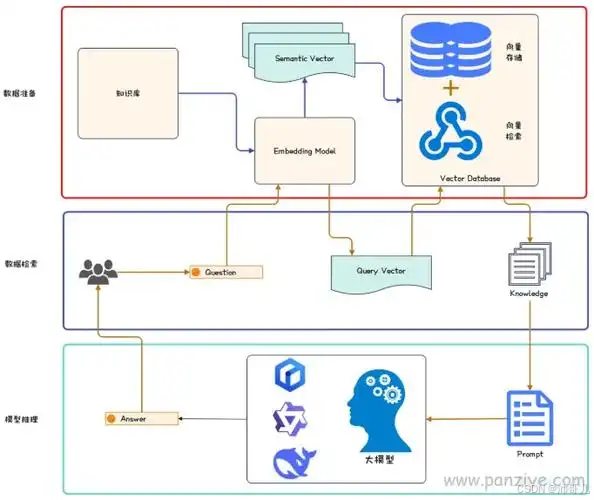
在大模型时代,检索增强生成(Retrieval-Augmented Generation, RAG)已成为提升语言模型事实准确性与知识时效性的关键技术路径。RAG通过将外部知识库引入生成过程,有效缓解了传统大模型“幻觉”和知识固化的问题。然而,其性能高度依赖于检索与排序模块的协同效率——不仅需要高效召回相关文档,还需通过精细化重排序确保生成阶段获取最相关、最可靠的信息。
图片来源网络,侵权联系删除
文章目录
前言
在大模型时代,检索增强生成(Retrieval-Augmented Generation, RAG)已成为提升语言模型事实准确性与知识时效性的关键技术路径。RAG通过将外部知识库引入生成过程,有效缓解了传统大模型“幻觉”和知识固化的问题。然而,其性能高度依赖于检索与排序模块的协同效率——不仅需要高效召回相关文档,还需通过精细化重排序确保生成阶段获取最相关、最可靠的信息。本文将深入剖析RAG中检索器与排序模型的协同机制,重点探讨多阶段检索流程中重排序的核心作用,并对比分析DPR与ColBERT两类代表性架构在向量表示与交互方式上的本质差异,进而揭示多阶段检索与精细化重排序如何共同驱动RAG系统实现更高精度的知识融合与内容生成。
一、RAG检索与排序增强的核心逻辑
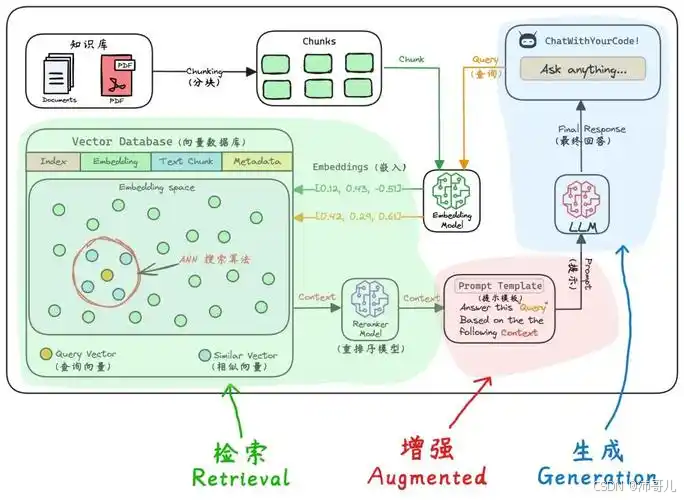
RAG的核心是**“检索外部知识+生成回答”,其性能取决于检索结果的相关性与生成模型对知识的利用效率**。检索与排序增强的目标是:
- 检索阶段:从大规模知识库中快速召回潜在相关的文档/段落;
- 排序阶段:对召回结果进行精细化排序,筛选出最相关的内容,为生成模型提供高质量上下文。
二、检索器与排序模型的协同机制
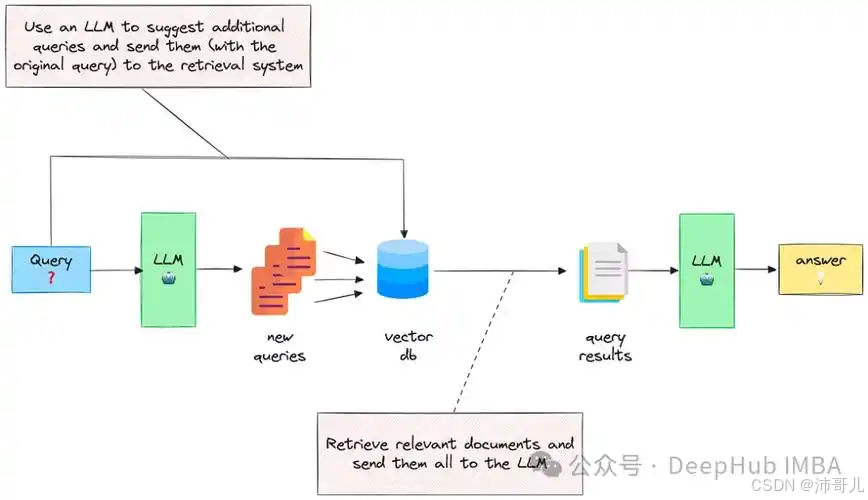
检索器(Retriever)与排序模型(Reranker)是RAG的两大核心组件,其协同机制如下:
- 检索器:负责大规模召回,通过语义匹配(如DPR、ColBERT)或关键词匹配(如BM25)快速缩小候选范围(通常召回Top-100~Top-500文档);
- 排序模型:负责精细化排序,通过深度交互(如Cross-Encoder)计算查询与文档的相关性得分,将最相关的内容排在前面(通常输出Top-5~Top-10文档)。
协同方式:
- 检索器为排序模型提供候选集(减少排序的计算量);
- 排序模型为检索器提供反馈(如通过强化学习优化检索策略,提升召回的相关性)。
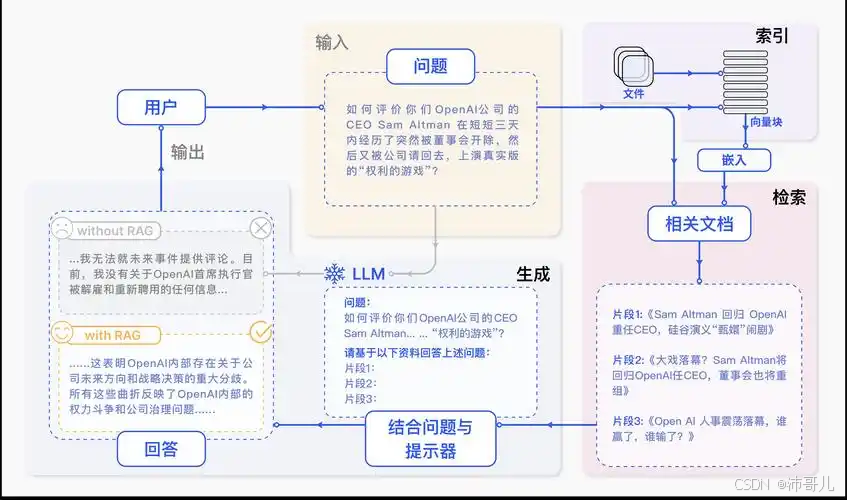
三、典型框架流程:以“多阶段检索+重排序”为例
工业级RAG系统通常采用预检索→粗排→精排 的多阶段流程,结合检索器与排序模型的优势:
- 预检索:使用稀疏检索(如BM25)或密集检索(如DPR)召回Top-500文档;
- 粗排:使用轻量级排序模型(如Cross-Encoder-Lite)对Top-500文档进行初步排序,筛选出Top-100文档;
- 精排:使用重型排序模型(如bge-reranker-large)对Top-100文档进行精细化排序,输出Top-10文档;
- 生成:将Top-10文档作为上下文,输入大语言模型(LLM)生成回答。
四、ColBERT与DPR的架构差异:向量表示与交互方式
ColBERT与DPR是密集检索的两大代表模型,其核心差异在于向量表示与交互方式: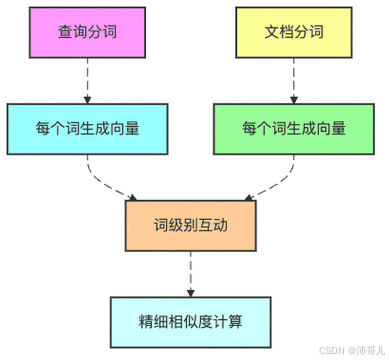
| 维度 | ColBERT | DPR |
|---|---|---|
| 向量表示 | Token级向量:保留查询与文档中每个token的上下文嵌入(如用BERT编码每个token),不压缩为单一向量。 | 单一向量:用两个独立的BERT编码器(查询编码器、文档编码器)将查询与文档压缩为单一向量(如[CLS] token的嵌入)。 |
| 交互方式 | 后期交互(Late Interaction):在推理时计算查询token与文档token的最大相似度(MaxSim),即对每个查询token,取其与文档所有token的最大相似度,再求和得到最终得分。公式:( S(q,d) = \sum_{i} \max_{j} (q_i \cdot d_j) ),其中( q_i )是查询token的嵌入,( d_j )是文档token的嵌入。 | 早期交互(Early Interaction):在编码阶段,查询与文档的嵌入是独立计算的,无交互。仅在计算相似度时,用点积计算两个单一向量的相似度(( S(q,d) = q \cdot d ))。 |
| 优势 | 高精度:Token级交互捕捉了细粒度语义匹配(如“AI”与“人工智能”的对应关系),适合处理长文档或复杂查询。 | 高效率:单一向量的存储与计算成本低,适合大规模知识库(如十亿级文档),推理速度快。 |
| 劣势 | 存储开销大:需要存储每个token的嵌入,对硬件要求高。 | 忽略细粒度交互:单一向量无法捕捉token级的匹配信号,可能遗漏关键信息(如查询中的“最新”与文档中的“2025年”)。 |
五、多阶段检索与精细化重排序的协同效应
多阶段检索(如“预检索→粗排→精排”)与精细化重排序(如ColBERT、DPR+Cross-Encoder)的协同效应,是提升RAG性能的关键: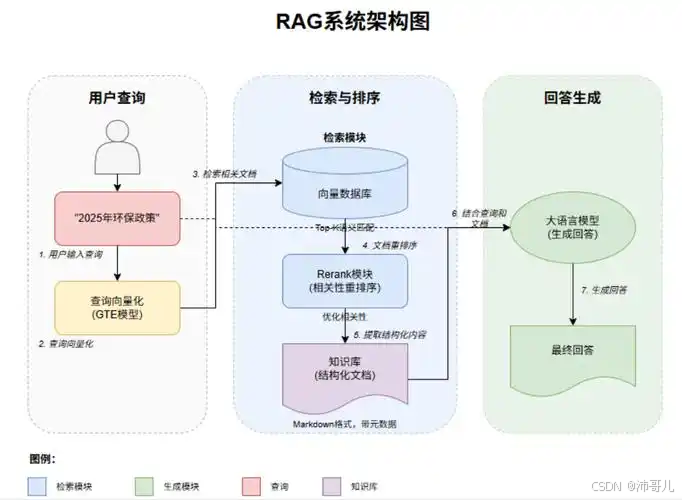
1. 多阶段检索的作用:缩小候选范围,降低计算成本
- 预检索:用稀疏检索(BM25)或密集检索(DPR)快速召回大量候选文档(Top-500),覆盖关键词匹配与语义匹配的内容;
- 粗排:用轻量级排序模型(如Cross-Encoder-Lite)对Top-500文档进行初步排序,筛选出Top-100文档,去除不相关或冗余的内容;
- 精排:用重型排序模型(如ColBERT、DPR+Cross-Encoder)对Top-100文档进行精细化排序,输出Top-10文档,确保最相关的内容排在前面。
2. 精细化重排序的作用:提升相关性,优化生成效果
- ColBERT的重排序:通过Token级交互捕捉细粒度匹配,比如查询“2025年AI发展趋势”与文档“2025年人工智能行业报告”中的“2025年”与“AI”/“人工智能”的匹配,会被ColBERT捕捉到,从而提升排序的准确性;
- DPR的重排序:通过单一向量的点积计算相似度,适合处理大规模文档,比如在十亿级文档中快速筛选出Top-100文档,再用Cross-Encoder进行精排。
3. 协同效应的案例:工业级RAG系统的性能提升
某电商平台采用BM25预检索→DPR粗排→ColBERT精排的多阶段流程,结合重排序模型(bge-reranker-large),将RAG系统的事实准确率从75%提升至90%,用户满意度从80%提升至92%。其中:
- BM25预检索:召回Top-500文档,覆盖关键词匹配的内容;
- DPR粗排:用单一向量筛选出Top-100文档,去除不相关的内容;
- ColBERT精排:用Token级交互筛选出Top-10文档,捕捉细粒度匹配的内容;
- 重排序模型:进一步优化Top-10文档的顺序,确保最相关的内容排在前面。
六、总结:RAG检索与排序增强的未来趋势
- 多模态检索:结合文本、图像、音频等多模态数据,提升检索的全面性(如ColPali的多模态向量表示);
- 动态检索:根据查询的复杂度动态调整检索策略(如DeepRAG的链式检索);
- 自适应排序:根据用户反馈(如点击率、停留时间)自适应调整排序模型的权重(如强化学习优化排序);
- 轻量级排序:通过模型蒸馏(如将ColBERT蒸馏为小型模型)降低排序的计算成本,适合边缘设备。
结论
RAG的检索与排序增强是召回→排序→生成的核心流程,其关键在于检索器与排序模型的协同(多阶段检索+精细化重排序)。ColBERT与DPR作为密集检索的代表,分别适合高精度与高效率的场景,其协同效应(如“DPR粗排→ColBERT精排”)能显著提升RAG系统的性能。未来,随着多模态、动态检索、自适应排序等技术的发展,RAG的检索与排序增强将更加智能,为生成模型提供更高质量的上下文,推动RAG在企业客服、医疗问答、教育辅导等场景的广泛应用。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 15
15 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)