再学 RAGFlow 的问答流程
本文深入探讨了RAGFlow问答系统的三个优化细节:1)对于表格数据,系统通过field_map实现SQL检索优化;2)多轮对话时,利用大模型重写问题保持上下文连贯性;3)支持通过API传递自定义变量动态调整提示词。其中特别介绍了表格数据的分块存储机制、SQL生成过程,以及多轮对话重写的实现原理,展示了如何通过技术手段提升问答系统的精准度和灵活性。
昨天,我们对 RAGFlow 的问答流程进行了全面的学习,主要介绍了聊天助手的核心配置,并从源码的角度研究了从用户发起查询开始,到后端系统如何一步步处理并最终生成答案的过程。不过,问答过程中还有不少有趣的点可以展开学习,我们今天就继续深入这些细节。
SQL 检索优化
当知识库配置的 field_map 不为空时,RAGFlow 会使用 SQL 检索替代向量检索,来优化查询:
field_map = KnowledgebaseService.get_field_map(dialog.kb_ids)
if field_map:
ans = use_sql(questions[-1], field_map, dialog.tenant_id, chat_mdl, prompt_config.get("quote", True))
if ans:
yield ans
return
那么这个 field_map 是什么意思呢?要了解这一点,我们还需要复习下之前的 Table 分块器的代码:
def chunk(filename, binary=None, from_page=0, to_page=10000000000, lang="Chinese", callback=None, **kwargs):
# 表格文件解析
if re.search(r"\.xlsx?$", filename, re.IGNORECASE):
# 处理 Excel 文件
excel_parser = Excel()
dfs = excel_parser(filename, binary, from_page=from_page, to_page=to_page, callback=callback)
elif re.search(r"\.(txt|csv)$", filename, re.IGNORECASE):
# 处理 TXT 或 CSV 文件
dfs = [pd.DataFrame(np.array(rows), columns=headers)]
else:
raise NotImplementedError("file type not supported yet(excel, text, csv supported)")
res = []
# 组装返回结果
for df in dfs:
# ...
# 更新 field_map
KnowledgebaseService.update_parser_config(kwargs["kb_id"], {"field_map": {k: v for k, v in clmns_map}})
return res
可以看到当知识库使用 Table 分块策略时,会在知识库的 parser_config 字段中维护一个 field_map 字典,表明 ES 中存储的是表格数据,并且记录了表格的所有列信息,可以打开 MySQL 数据库的 knowledgebase 表,parser_config 字段的值如下:
{
"pages": [
[
1,
1000000
]
],
"field_map": {
"xing_ming_tks": "姓名",
"xue_hao_long": "学号",
"nian_ling_long": "年龄",
"xing_bie_tks": "性别",
"cheng_ji_long": "成绩"
}
}
在分块列表中可以看到,表格的每一行都是一个独立分块:
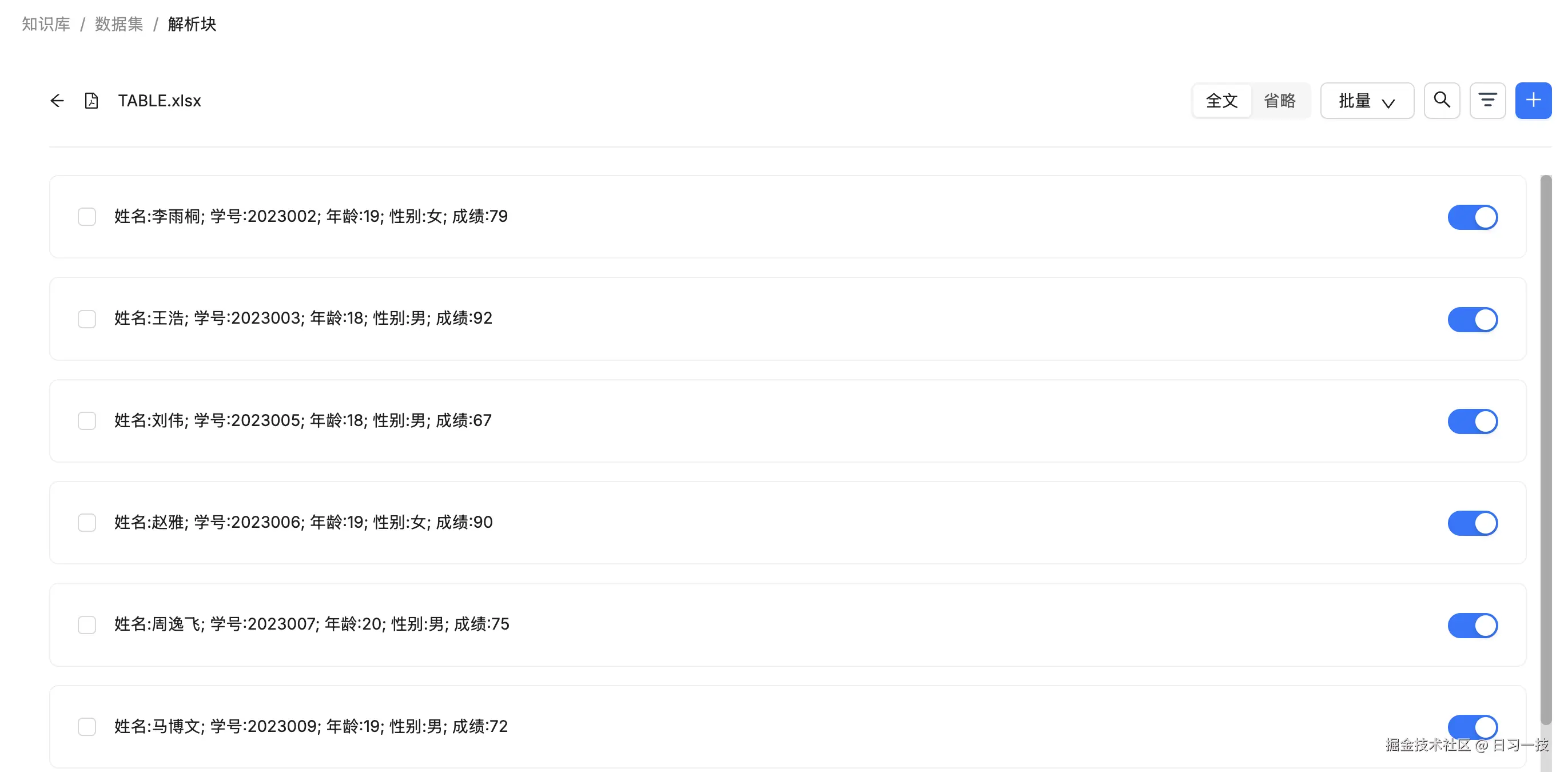
而在 ES 中,每条记录不仅以文本的形式存储在 content_with_weight 字段中,而且每一列的值也都单独存储:
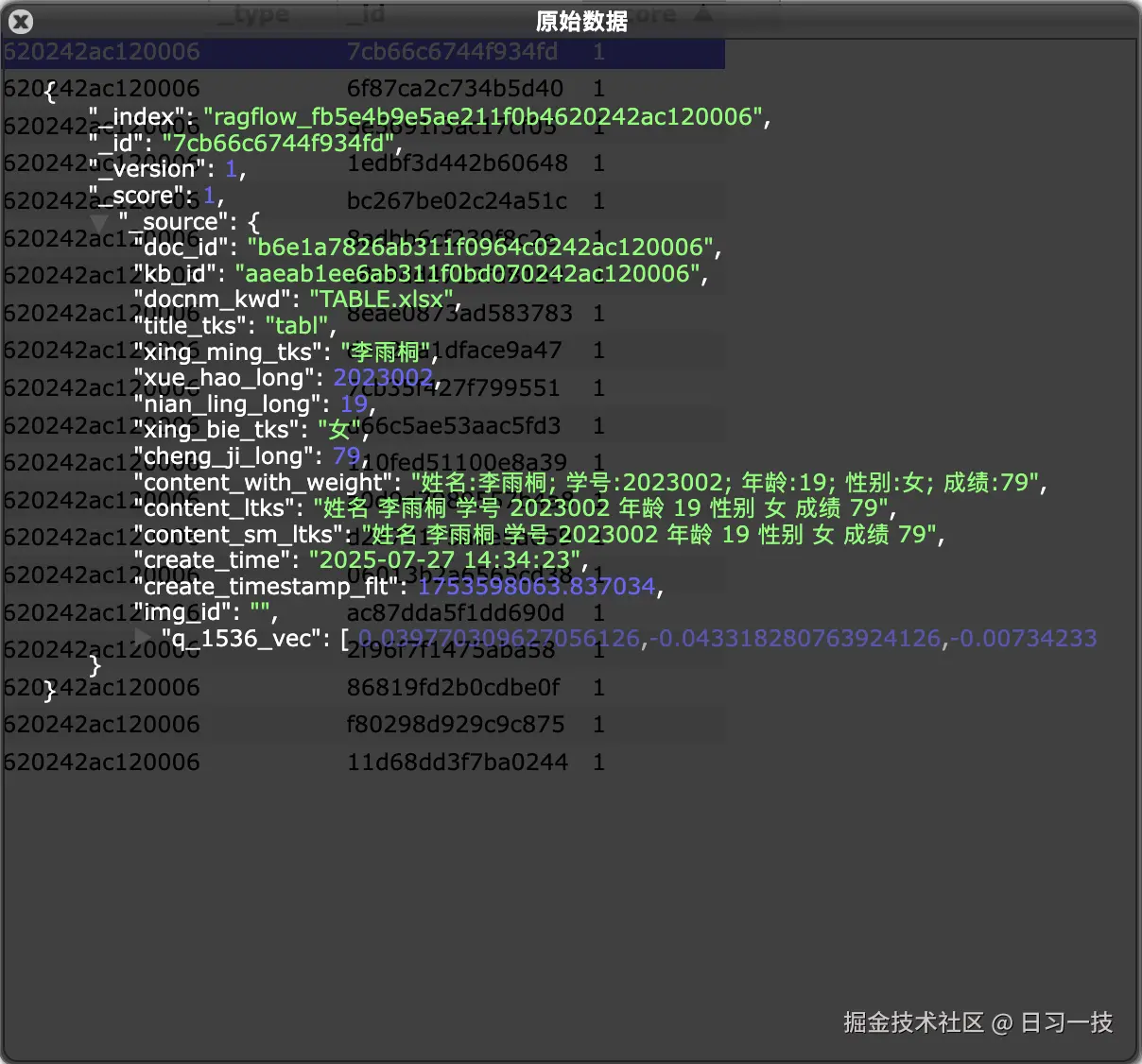
这就给 SQL 检索提供了条件。后面的 use_sql() 函数逻辑如下:
def use_sql(question, field_map, tenant_id, chat_mdl, quota=True):
# 表数据查询
def get_table():
# 根据表结构和用户问题,生成 SQL
sql = chat_mdl.chat(sys_prompt, [{"role": "user", "content": user_prompt}], {"temperature": 0.06})
# 调用 ES 的 SQL 查询接口
return settings.retrievaler.sql_retrieval(sql, format="json"), sql
tbl, sql = get_table()
# 如果出错,则提供错误信息,重新生成 SQL
if tbl.get("error") and tried_times <= 2:
tbl, sql = get_table()
# 组装 Markdown 表格,并返回引用块
return {
"answer": "\n".join([columns, line, rows]),
"reference": {
"chunks": [{"doc_id": r[docid_idx], "docnm_kwd": r[doc_name_idx]} for r in tbl["rows"]],
"doc_aggs": [{"doc_id": did, "doc_name": d["doc_name"], "count": d["count"]} for did, d in doc_aggs.items()],
},
"prompt": sys_prompt,
}
这里的核心有两点。第一点,我们要知道 ES 除了关键词检索和向量检索,也提供了 SQL 检索的功能,这里的 retrievaler.sql_retrieval() 就是调用 ES 的 SQL 接口,使用标准的 SQL 语句来查询 ES 数据库:
POST /_sql?format=json
{
"query": "select doc_id, docnm_kwd, xing_ming_tks, xue_hao_long, nian_ling_long, xing_bie_tks, cheng_ji_long from ragflow_fb5e4b9e5ae211f0b4620242ac120006 where cheng_ji_long >= 80"
}
更多内容可以阅读 ES 的官方文档:
第二点,这里通过大模型生成 SQL 语句,表结构信息就是从 field_map 里取的,调用 ES 查询如果出错,会将出错信息丢给大模型重试一次,这是 Text to SQL 很常见的一种做法。
最后,将查询结果组装成 Markdown 格式,插入引用信息,并返回:
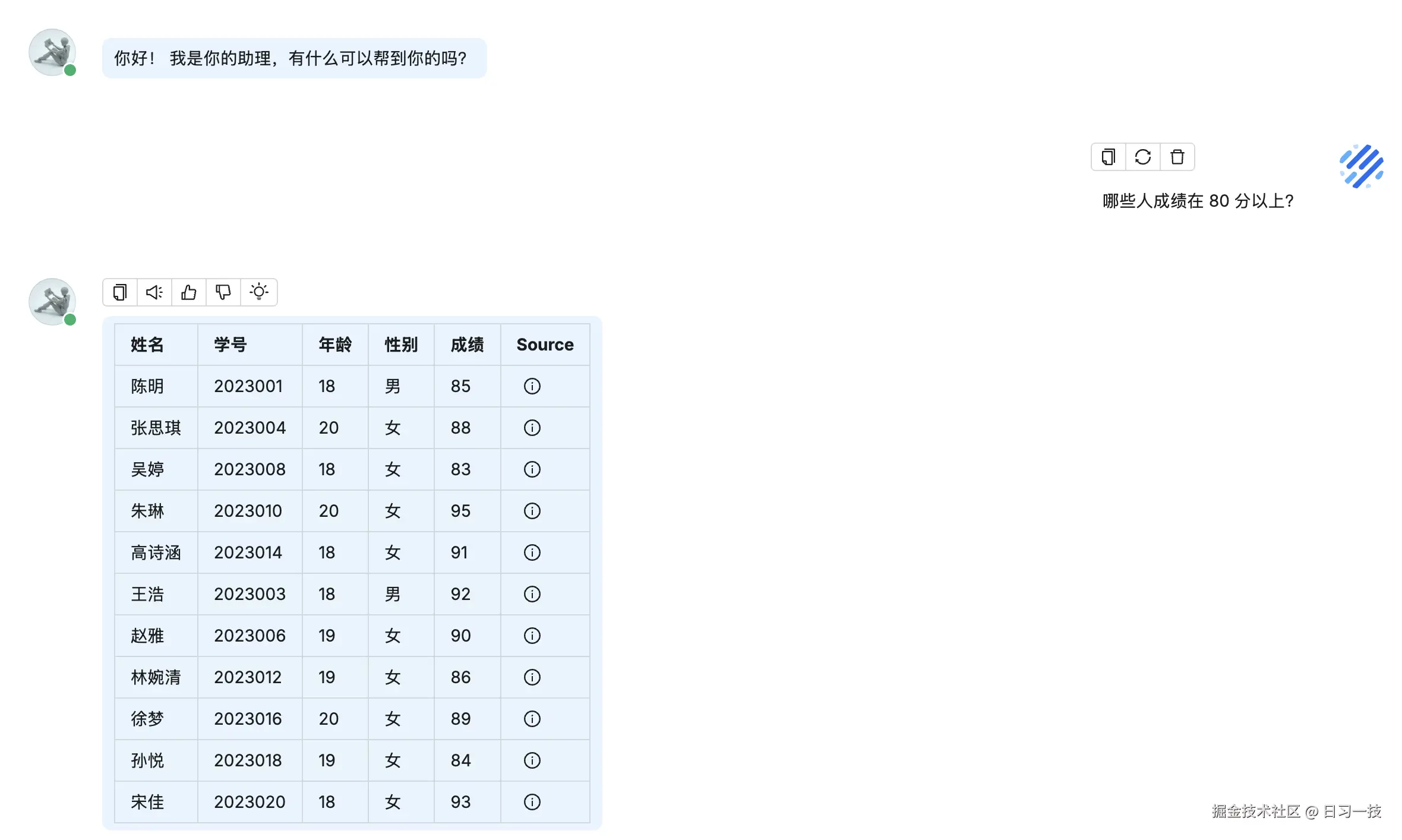
多轮对话优化
在 RAG 问答中,我们需要根据用户的问题检索知识库。但是在处理多轮对话时,用户的问题往往会不完整,比如用户第一个问题是 “张三的成绩怎么样?”,第二个问题是 “李四呢?”,如果只处理最近一轮对话,就会丢失很多上下文信息。
RAGFlow 支持开启多轮对话优化:
if len(questions) > 1 and prompt_config.get("refine_multiturn"):
# 如果开启多轮优化,使用大模型分析对话,生成完整的问题
questions = [full_question(dialog.tenant_id, dialog.llm_id, messages)]
else:
# 如果未开启,取最后一轮用户的问题
questions = questions[-1:]
多轮对话优化的实质就是通过大模型将多轮对话压缩成一个用户问题,比如上面的例子,转写后的问题可能是 “李四的成绩怎么样?”。
使用的提示词如下:
## 角色
一个乐于助人的助手。
## 任务和步骤
1. 生成一个符合对话逻辑的完整用户问题。
2. 如果用户的问题涉及相对日期,根据今天({{ today }})将其转换为绝对日期。
- “昨天”={{ yesterday }},“明天”={{ tomorrow }}
## 要求和限制
- 如果用户最新的问题已经完整,无需进行任何操作,只需返回原始问题。
- 除了优化后的问题外,不要生成任何其他内容。
{% if language %}
- 生成的文本必须使用{{ language }}。
{% else %}
- 生成的文本必须与用户原始问题使用相同的语言。
{% endif %}
## 真实数据
**对话:**
{{ conversation }}
这里的
conversation是完整的历史会话消息,其实可以再优化下,比如只取最近 5 条消息即可。
变量的使用
昨天我们学过,在聊天助手的配置中有一个自定义变量的功能,可以使用它来动态调整大模型的系统提示词,下面我来举一个例子。正常情况下,我们创建的助手是不知道当前日期的:
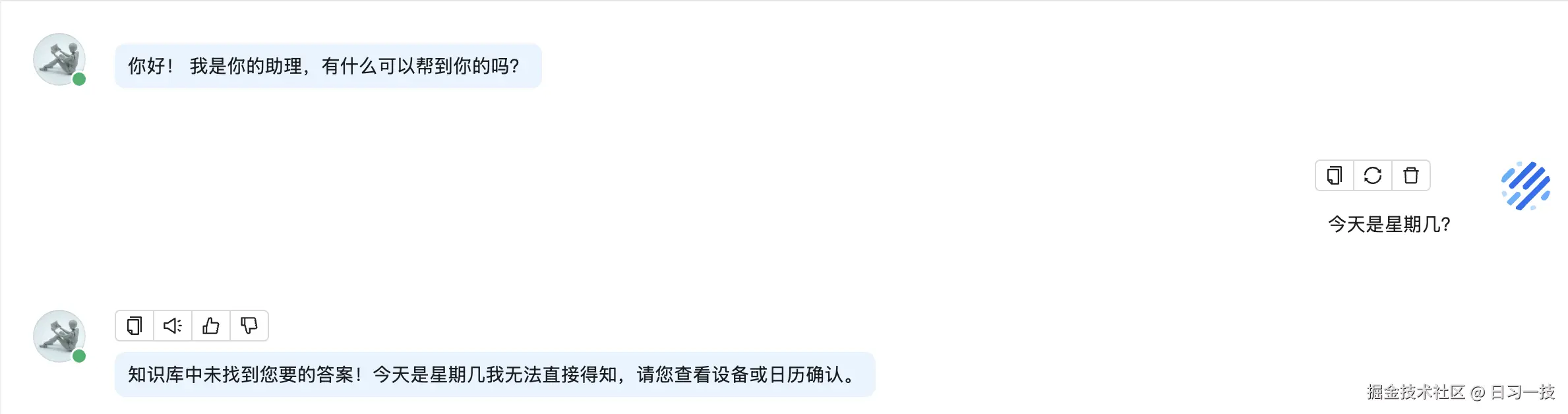
如果希望助手回答这个问题,我们可以给它加一个 current_date 自定义变量:
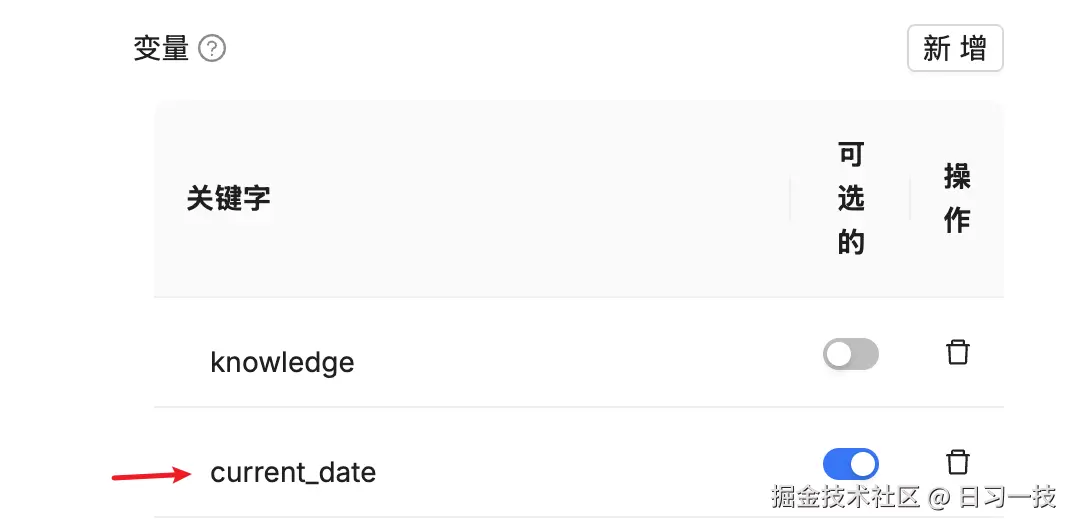
然后调整默认的提示词:

不过这个自定义变量,在页面上问答是无法传值的,唯一可以传递其值的方法是调用助手的对话 API,比如 SDK 或 HTTP 方式。
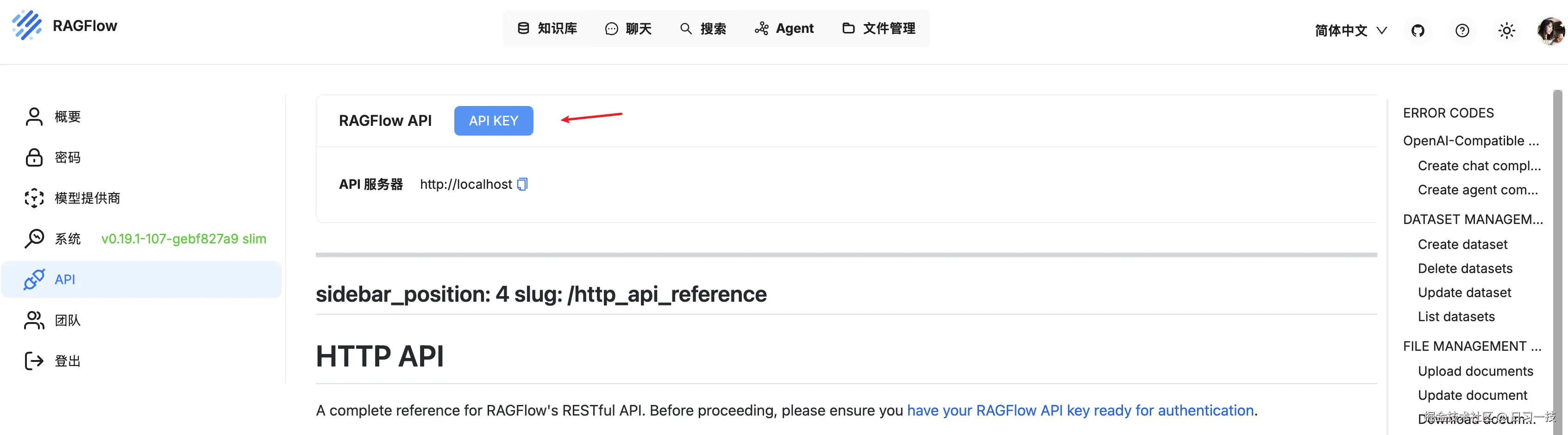
为了体验 RAGFlow 的 API 功能,我们必须先到 API 配置页面(点击右上角的头像)创建一个 API KEY:
有了 API KEY 之后,我们首先调用 /api/v1/chats/<chat-id>/sessions 接口,创建新会话:
$ curl --request POST \
--url http://localhost/api/v1/chats/59c7a84e65d111f0872a0242ac120006/sessions \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer ragflow-YxN2QxNzFjNmFlNjExZjA5OWZhMDI0Mm' \
--data '
{
"name": "demo"
}'
这里的
<chat-id>是聊天助手的 ID,可以随便进入该助手的一个聊天页面,网址中的dialogId就是。
调用结果如下:
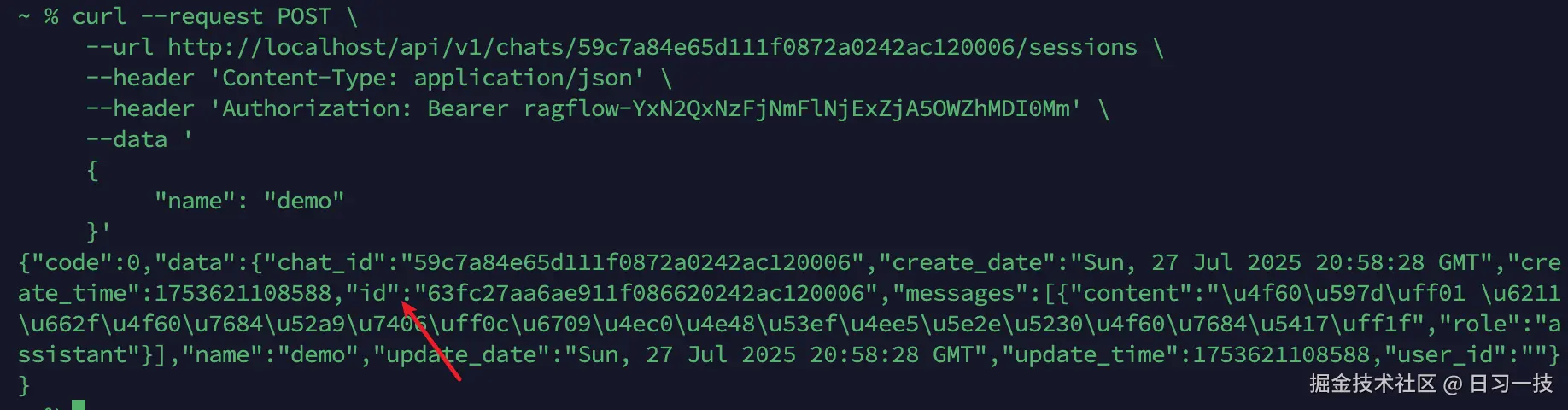
拿到会话 ID 后,就可以和助手进行对话了,调用 /api/v1/chats/<chat-id>/completions 接口:
$ curl --request POST \
--url http://localhost/api/v1/chats/59c7a84e65d111f0872a0242ac120006/completions \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer ragflow-YxN2QxNzFjNmFlNjExZjA5OWZhMDI0Mm' \
--data-binary '
{
"question": "今天是星期几?",
"stream": true,
"session_id": "63fc27aa6ae911f086620242ac120006"
}'
这时没有带 current_date 参数,调用结果如下:

带上 current_date 参数,再次调用:
$ curl --request POST \
--url http://localhost/api/v1/chats/59c7a84e65d111f0872a0242ac120006/completions \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer ragflow-YxN2QxNzFjNmFlNjExZjA5OWZhMDI0Mm' \
--data-binary '
{
"question": "今天是星期几?",
"stream": true,
"session_id": "63fc27aa6ae911f086620242ac120006",
"current_date": "2025年7月27号,星期日"
}'
调用结果如下:

RAGFlow 的流式接口有点奇怪,为什么每一帧都包含前一帧的完整数据?这在输出长文本时不会有性能问题吗?
未完待续
我们今天深入学习了问答过程中几个有趣的点,比如:对于使用 Table 切片方法的知识库,RAGFlow 会使用 SQL 检索替代向量检索,优化查询效率;对于多轮对话,RAGFlow 通过大模型对用户问题进行改写,改写后的问题可以让查询更加精准;通过自定义用户变量,我们可以在 SDK 或 API 调用聊天助手时动态调整系统提示词,实现一些页面聊天做不到的功能。今天暂且先学这么多,剩下的明天继续。
如何学习大模型?
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!
这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

😝有需要的小伙伴,可以扫描下方二v码免费领取【保证100%免费】🆓

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 6
6 0
0- 0



 已为社区贡献225条内容
已为社区贡献225条内容

所有评论(0)