任务6:hdfs操作、web操作、java代码操作(Hadoop部署10.29)
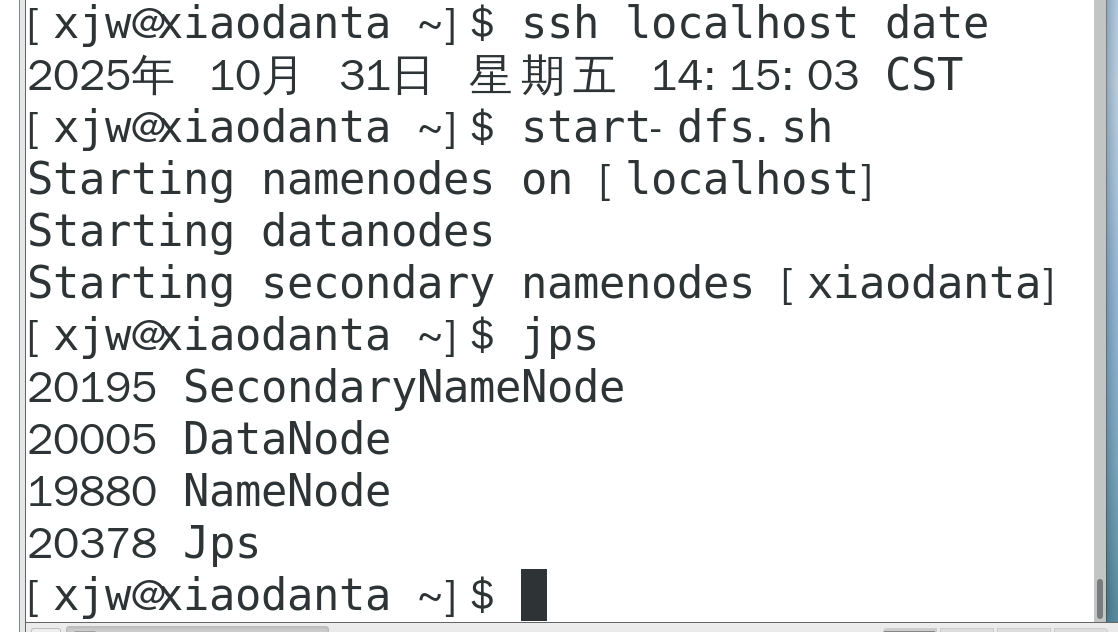
一键启动HDFS集群执行原理:在执行此脚本的机器上,启动SecondaryNameNode;在Jetbrains的产品中,均可以安装插件,其中:BigDataTools插件可以帮助我们方便的操作HDFS,比如IntelliJIDEA(JavaIDE)、PyCharm(PythonIDE)、DataGrip(SQLIDE)均可以支持BigdataTool插件。注:使用WEB浏览操作文件系统,一般会遇
一、hdfs操作
1.掌握HDFS相关进程的启停管理命令
一键启停脚本HadoopHDFS组件内置了HDFS集群的一键启停脚本。
$HADOOP_HOME/sbin/start-dfs.sh #一键启动HDFS集群一键启动HDFS集群执行原理:在执行此脚本的机器上,启动SecondaryNameNode;读取core-site.xml内容(fs.defaultFS项),确认NameNode所在机器,启动NameNode;读取workers内容,确认DataNode所在机器,启动全部DataNode。
$HADOOP_HOME/sbin/stop-dfs.sh #一键关闭HDFS集群一键关闭HDFS集群执行原理:在执行此脚本的机器上,关闭SecondaryNameNode;读取core-site.xml内容(fs.defaultFS项),确认NameNode所在机器,关闭NameNode;读取workers内容,确认DataNode所在机器,关闭全部NameNode。
单进程启停
除了一键启停外,也可以单独控制进程的启停。
$HADOOP_HOME/sbin/hadoop-daemon.sh
此脚本可以单独控制所在机器的进程的启停
用法:hadoop-daemon.sh(start|status|stop)(namenode|secondarynamenode|datanode)
$HADOOP_HOME/bin/hdfs此程序也可以用以单独控制所在机器的进程的启停
用法:hdfs--daemon(start|status|stop)(namenode|secondarynamenode|datanode)
2.HDFS文件系统基本信息
HDFS作为分布式存储的文件系统,有其对数据的路径表达方式。
HDFS同Linux系统一样,均是以/作为根目录的组织形式
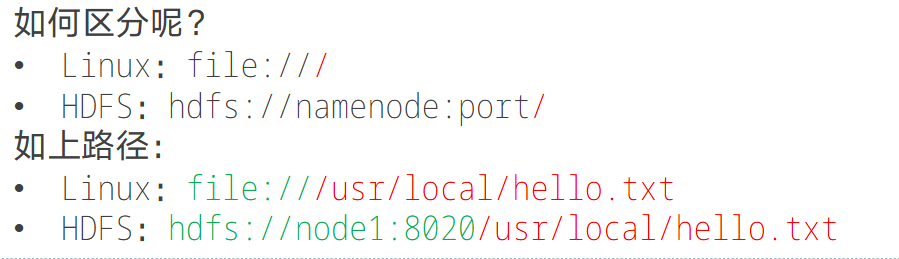

关于HDFS文件系统的操作命令,Hadoop提供了2套命令体系,如下:
hadoop命令(老版本)
用法:hadoop fs[generic options]
hdfs命令(新版本)
用法:hdfs dfs[generic options]
3.创建目录并验证
hadoop fs -mkdir -p <path>
#创建命令,其中path为待创建的目录,注:-p表示递归创建父目录,即使<path>不存在也会自动创建
hadoop fs -ls /
#验证命令
4.上传文件到HDFS指定目录下
echo "Hello hdfs" > word.txt #创建测试文件word.txt
hadoop fs -put word.txt /xjw_test/input #上传
hadoop fs -ls /xjw_test/input #验证结果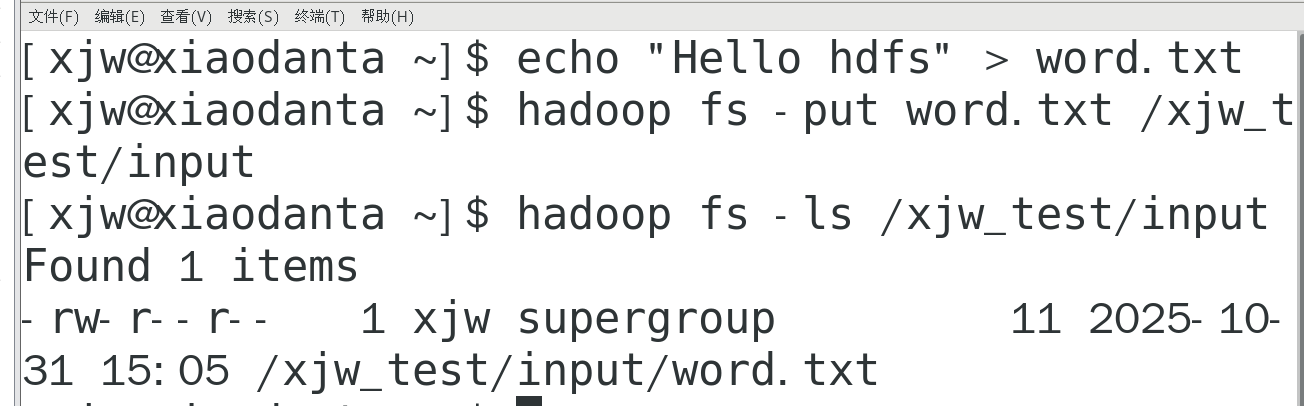
5.查看HDFS文件内容
hadoop fs -cat /xjw_test/input/word.txt #读取并查看HDFS中文件的完整内容
6.下载HDFS文件

mkdir -p xjw_demo
hadoop fs -get /xjw_test/input/word.txt xjw_demo/
$ ls xjw_demo/

7.拷贝HDFS文件
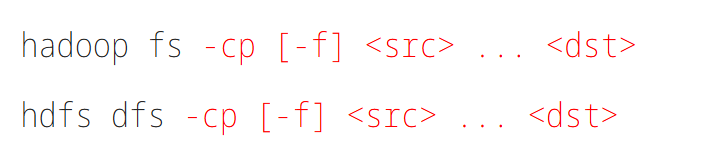
-f 覆盖目标文件(已存在下)
hadoop fs -cp /xjw_test/input/word.txt /xjw_test/input/word_copy.txt
hadoop fs -ls /xjw_test/input

8.追加数据到HDFS文件中
echo "append hello" > appendfile.txt #创建文件appendfile.txt
hadoop fs -appendToFile appendfile.txt /xjw_test/input/word.txt #追加
hadoop fs -cat /xjw_test/input/word.txt

9.HDFS数据移动操作
移动文件到指定文件夹下
可以使用该命令移动数据,重命名文件的名称
hadoop fs -mv /xjw_test/input/word_copy.txt /xjw_test/input/word_rename.txt
hadoop fs -ls /xjw_test/input

10.HDFS数据删除操作
删除指定路径的文件或文件夹
-skipTrash跳过回收站,直接删除

hadoop fs -rm /xjw_test/input/word_rename.txt #删除文件
hadoop fs -rm -r /xjw_test #删除目录
hadoop fs -ls / #验证

二、网页界面操作(通过9870端口)
1.访问web页面
(1)查端口(Hadoop 3.x 默认9870)
grep dfs.namenode.http-address $HADOOP_HOME/etc/hadoop/hdfs-site.xml无输出即代表默认9870,无需改。
(2)防火墙放行9870(CentOS 7)
sudo firewall-cmd --permanent --add-port=9870/tcp
sudo firewall-cmd --reload(3)获取虚拟机 IP
ip addr show ens33 | grep inet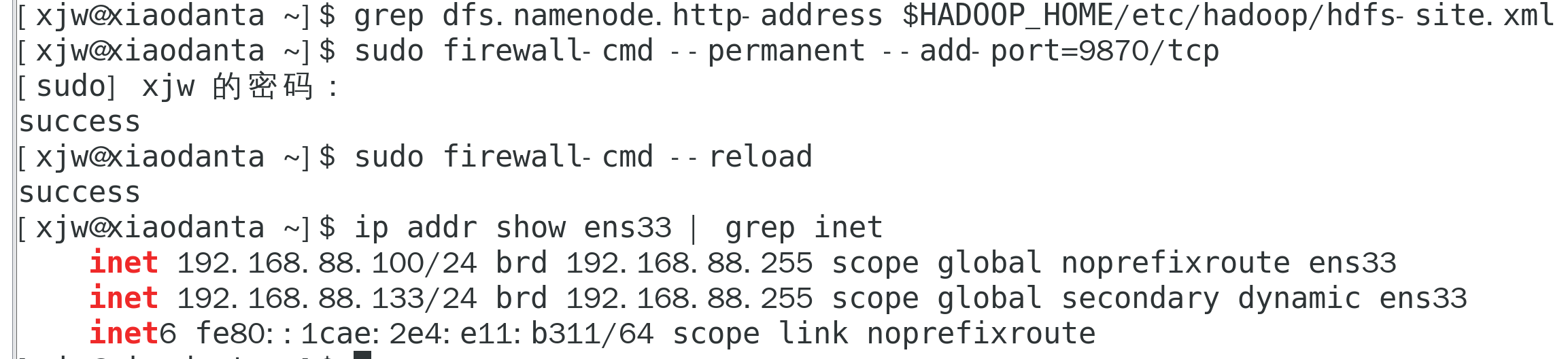
(4)访问 http://192.168.88.100:9870
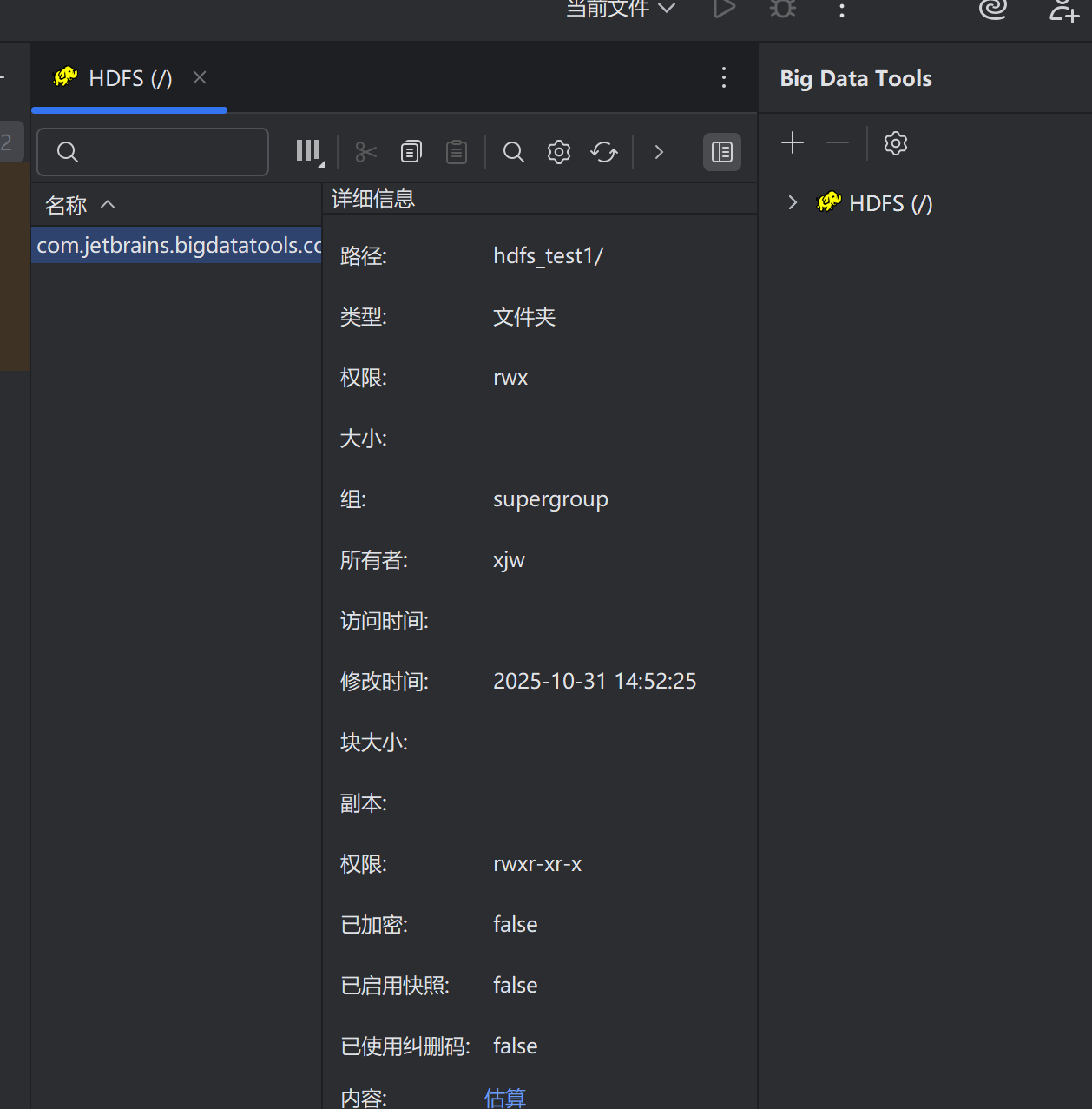
在HDFS的WEBUI上可以查看HDFS文件系统的内容
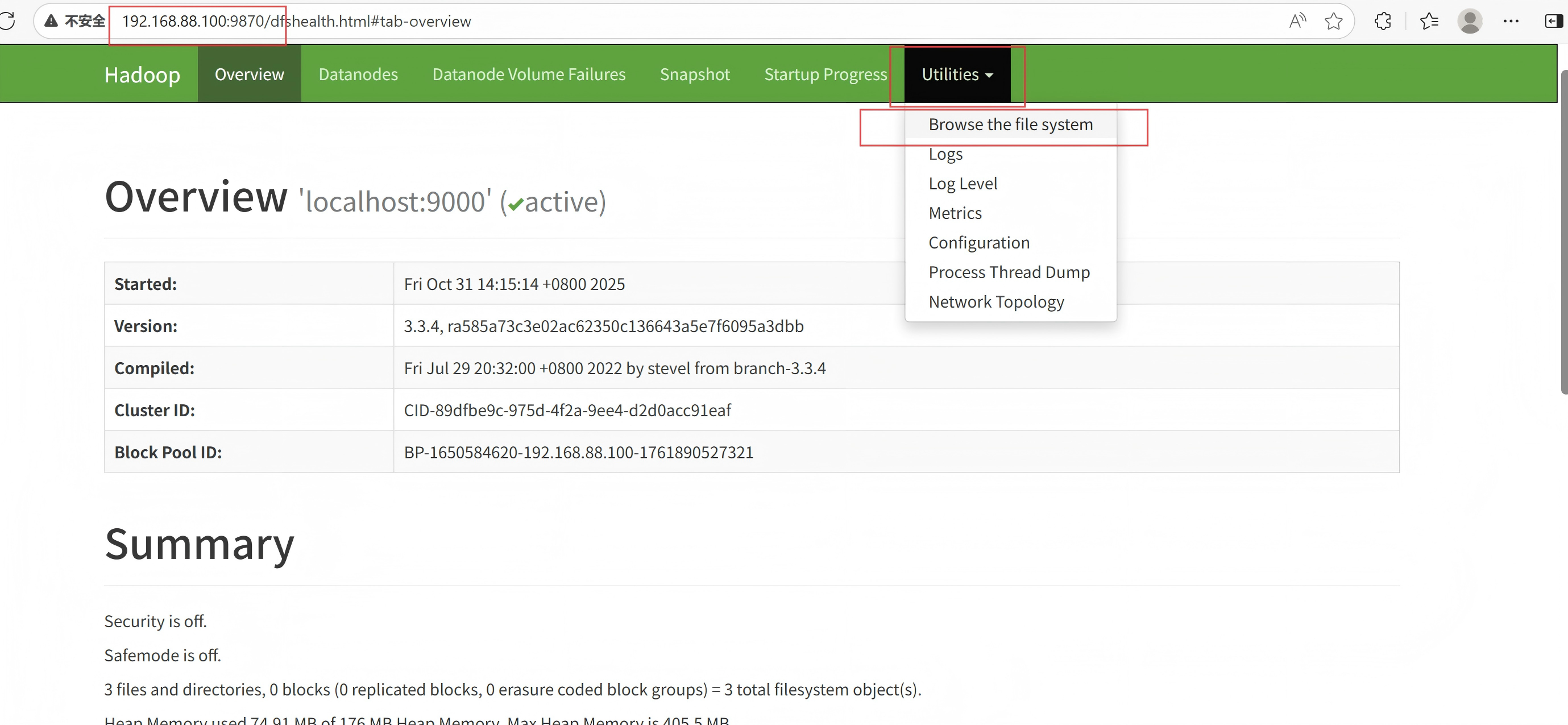
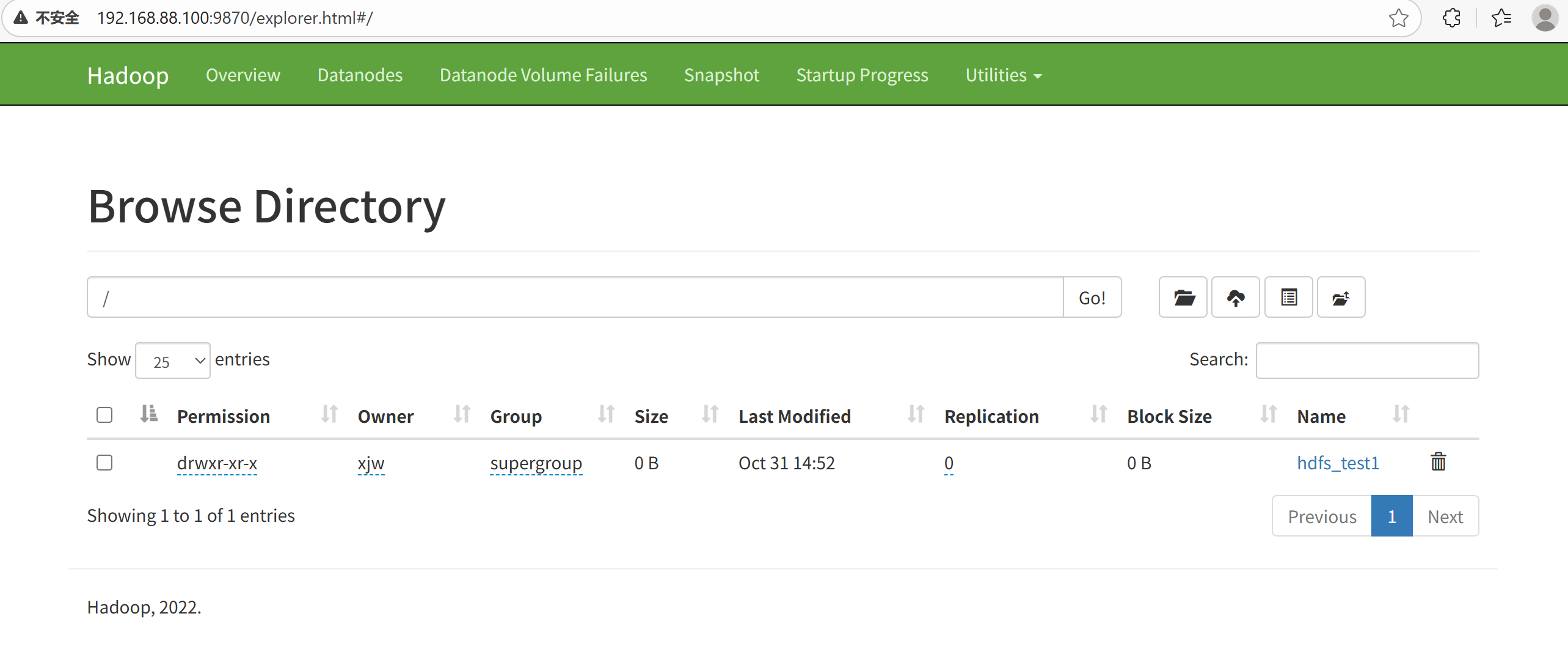
注:使用WEB浏览操作文件系统,一般会遇到权限问题,这是因为WEB浏览器中是以匿名用户(dr.who)登陆的,其只有只读权限,多数操作是做不了的。如果需要以特权用户在浏览器中进行操作,需要配置如下内容到core-site.xml并重启集群。
<property>
<name>hadoop.http.staticuser.user</name>
<value>hadoop</value>
</property>
三、java代码操作
了解在JetBrains产品中安装使用BigDataTools插件
在Jetbrains的产品中,均可以安装插件,其中:BigDataTools插件可以帮助我们方便的操作HDFS,比如IntelliJIDEA(JavaIDE)、PyCharm(PythonIDE)、DataGrip(SQLIDE)均可以支持BigdataTool插件
1.配置Windows
需要对Windows系统做一些基础设置,配合插件使用.解压Hadoop安装包到Windows系统
(1) 解压Hadoop安装包
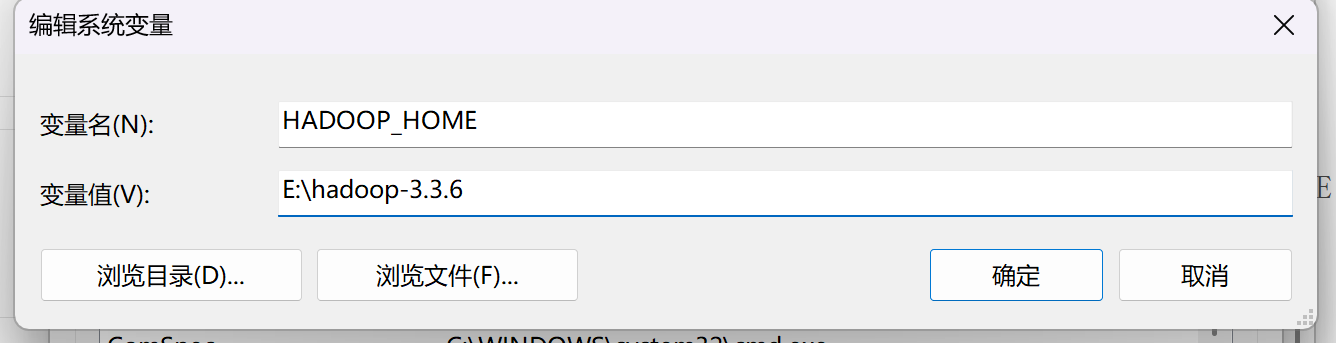
将Hadoop安装包解压到Windows本地路径,例如 E:\hadoop-3.3.6
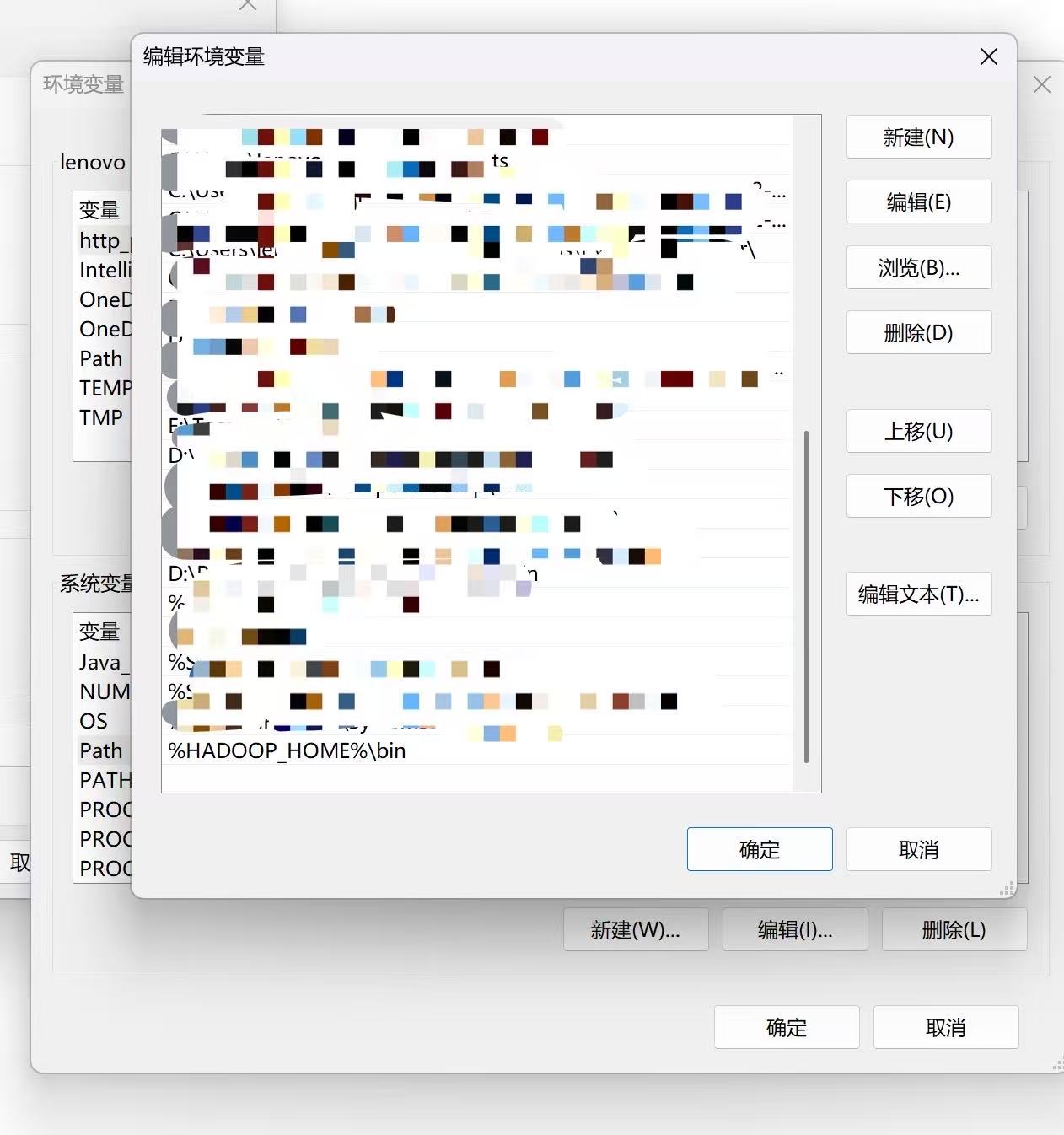
新建系统变量HADOOP_HOME,值为E:\hadoop-3.3.6(以实际为准)
编辑Path变量,添加 %HADOOP_HOME%\bin
(2)下载
hadoop.dll如下:
https://github.com/steveloughran/winutils/blob/master/hadoop-3.0.0/bin/hadoop.dll
winutils.exe如下:
https://github.com/steveloughran/winutils/blob/master/hadoop-3.0.0/bin/winutils.exe
因为🪜不行,可自行寻找镜像
hadoop-3.3.6/bin · mirrors_cdarlint/winutils - 码云 - 开源中国
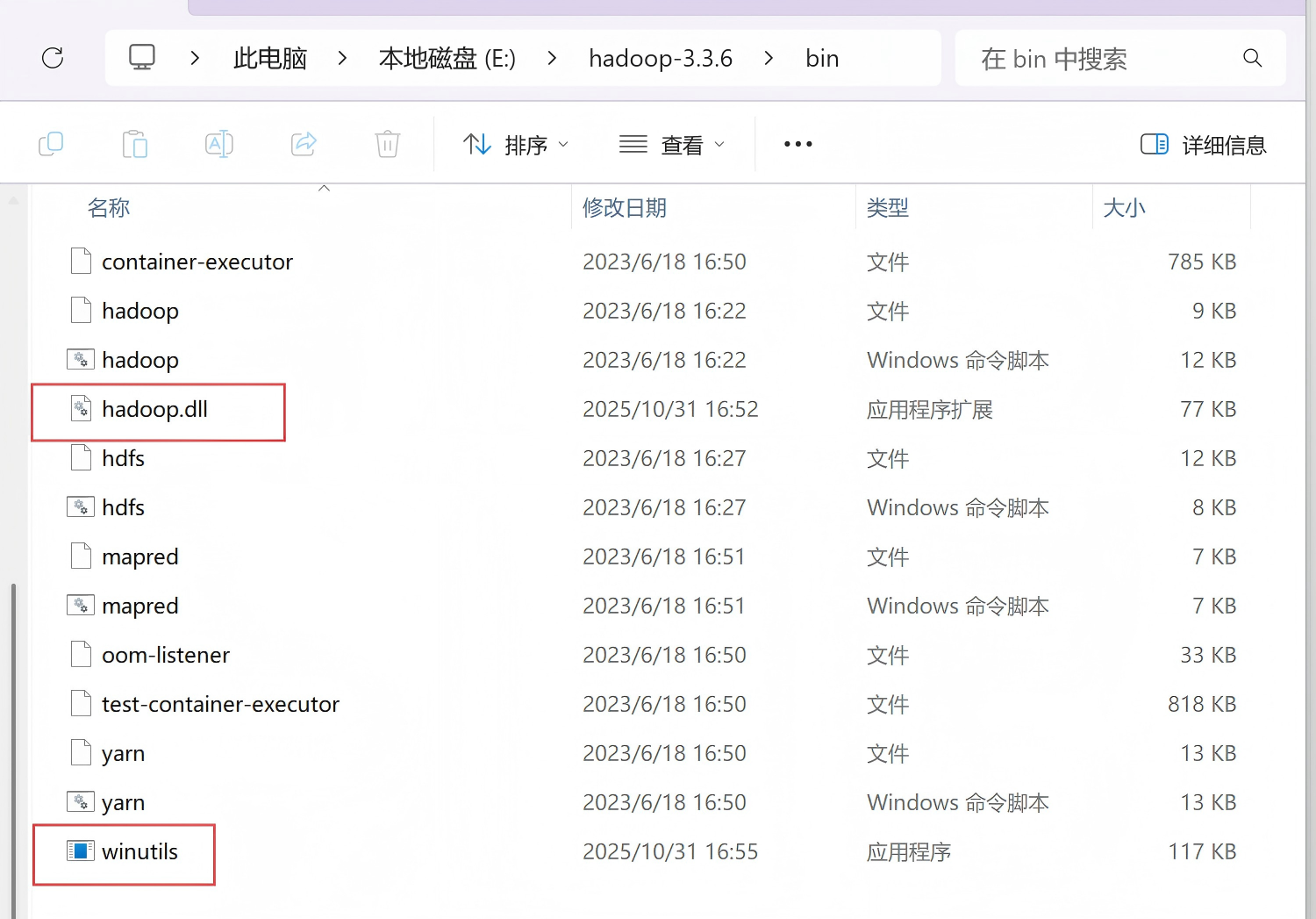
再将hadoop.dll和winutils.exe放入E:\hadoop-3.3.6\bin中
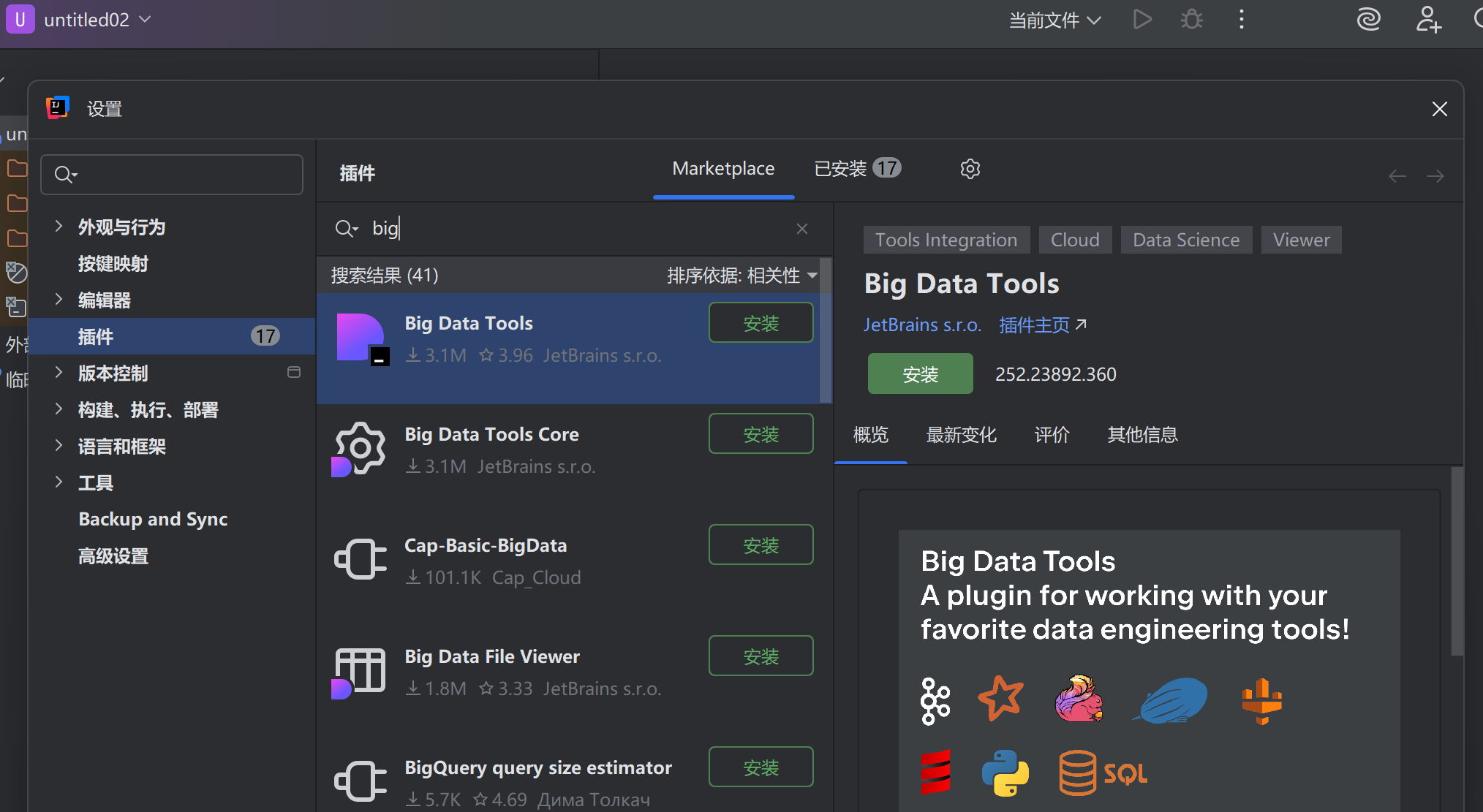
2.配置BigDataTools插件
打开IDEA Ultimate,在插件栏安装Big Data Tools,然后重启IDEA
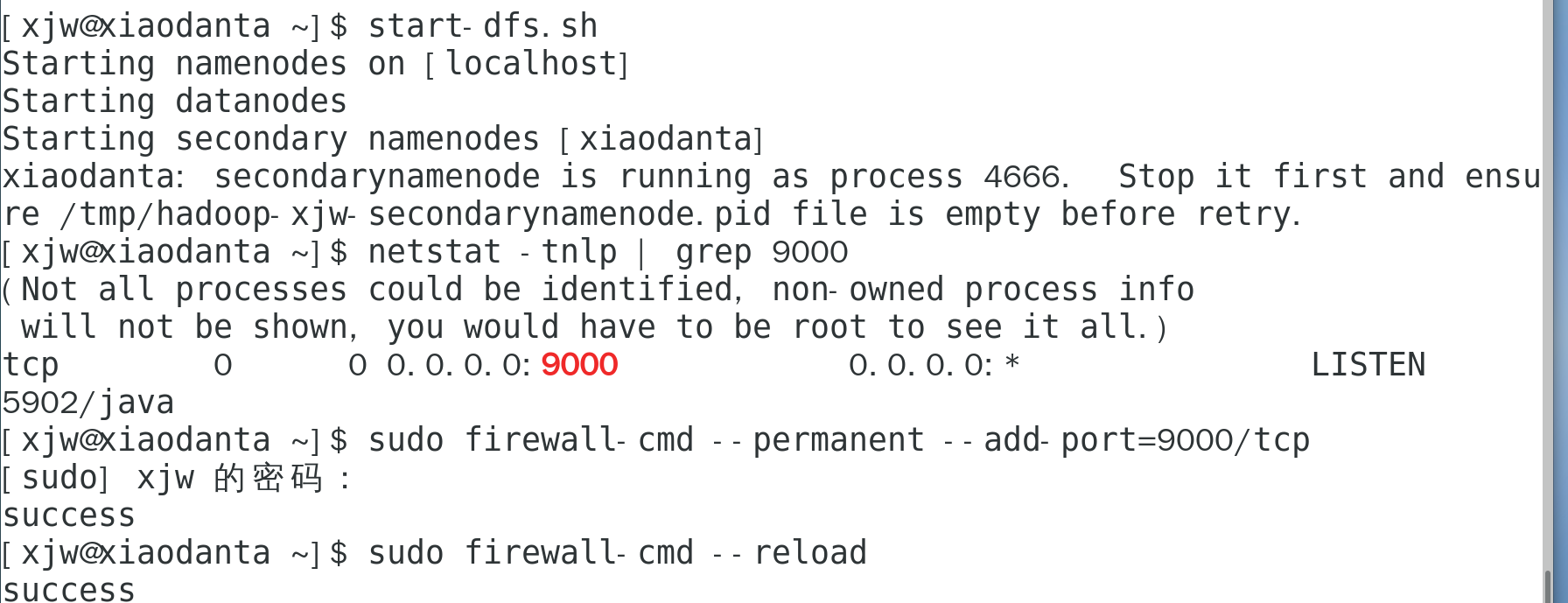
把虚拟机9000映射到Windows本地(管理员PowerShell),代码如下
netsh interface portproxy add v4tov4 listenport=9000 connectaddress=192.168.88.100 connectport=9000jps查看namenode是否启动

测试连接:已连接,即连接上HDFS
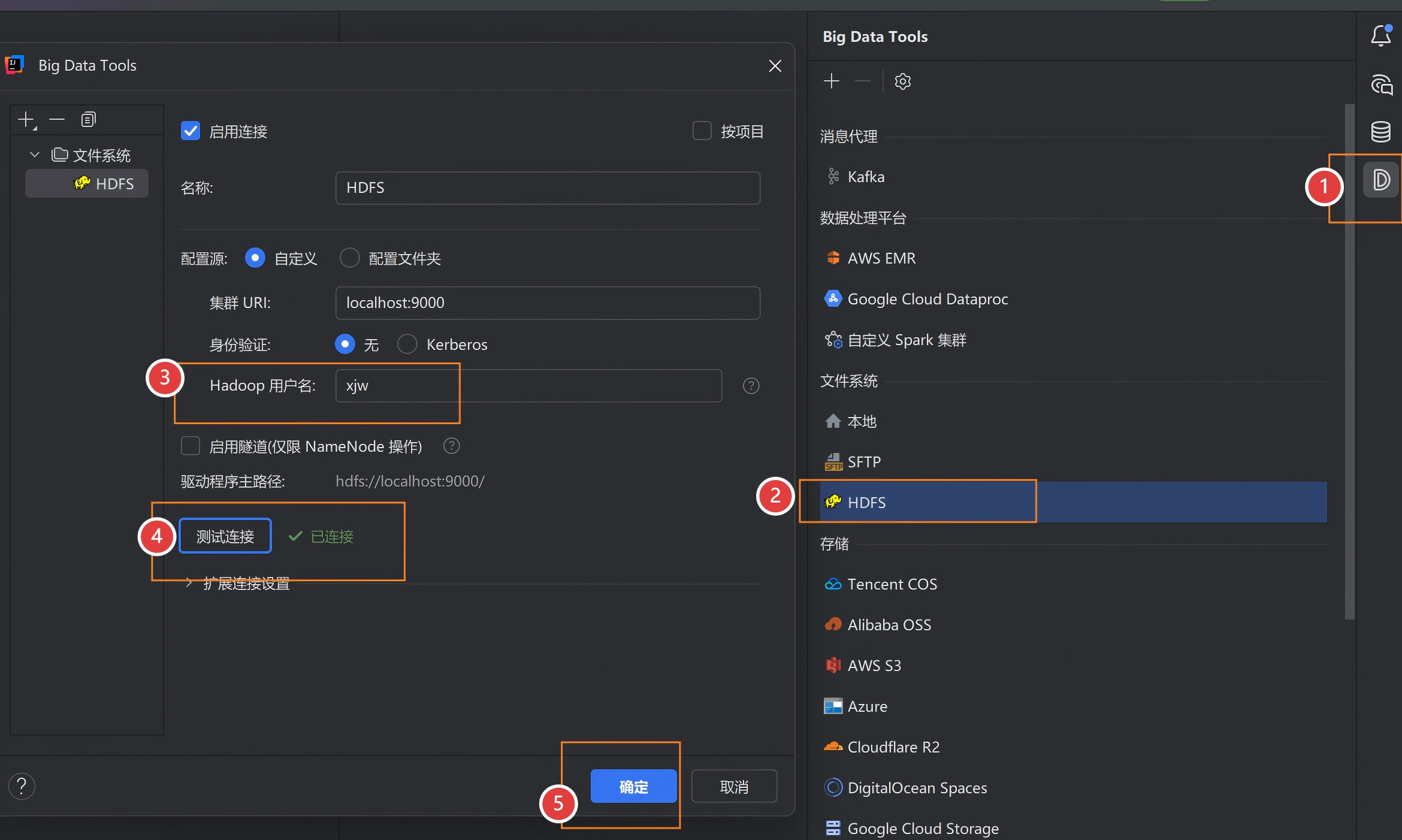
连不上原因可能有:
1.下载的hadoop.dll和winutils.exe版本与Hadoop不匹配
2.确保NameNode已启动,jps
3.检查环境变量配置,查看自己本机路径
4.将hadoop.dll复制到系统目录C:\Windows\..\System32,解决系统级的本地库加载问题

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)