DeepSeek深度解析:从技术黑马到全民工具,这篇讲透它的来龙去脉
比如它的Multi-Token Prediction(MTP)和Multi-Head Latent Attention(MLA)技术,就像给算力装了“智能开关”——原来处理一个任务要100度电,现在6.7度就够,KV缓存直接省了93.3%,跟节能灯似的,只在关键地方发力。好在它现在名气大,对有理想、想搞技术的人来说,吸引力还是很足的。OpenAI先是说它“蒸馏”自己的技术,接着又是持续的DDoS攻
一、认识DeepSeek:杭州走出的AI创新者
DeepSeek(深度求索)是2023年在杭州诞生的AI公司,由幻方量化孵化,创始人梁文锋带着团队从一开始就打定主意:不做跟风者,要搞大模型创新。
两年来,它的成长轨迹几乎就是一串开源产品的发布史:
2023年11月,先是推出专攻代码的DeepSeek Coder,架构类似Llama却更懂编程;
同月月底,通用大语言模型DeepSeek LLM上线,靠监督微调把多任务处理能力拉满;
2024年1月,DeepSeek-MoE引入混合专家架构(MoE),让模型效率飙升;
4月,DeepSeek-Math专攻数学推理,靠分组相对策略优化(GRPO)训练,解数学题的本事突飞猛进;
5月的DeepSeek V2更狠,用上多头潜在注意力(MLA)和MoE,能啃下128K长文本;
年底的V3在V2基础上扩到671亿参数,多任务能力再上一个台阶;
2025年1月,DeepSeek R1登场,专攻逻辑推理和实时问题解决,参数同样是671亿,却把“动脑”能力练到了新高度。
二、DeepSeek能帮你做什么?
不管你是普通用户还是开发者,它都能搭把手:智能对话、写文案、理解复杂文本、算数学题、写代码补代码……这些基础操作不在话下。更方便的是,它能联网搜最新信息,还支持传文件、扫图片里的文字,相当于一个“全能信息处理助手”。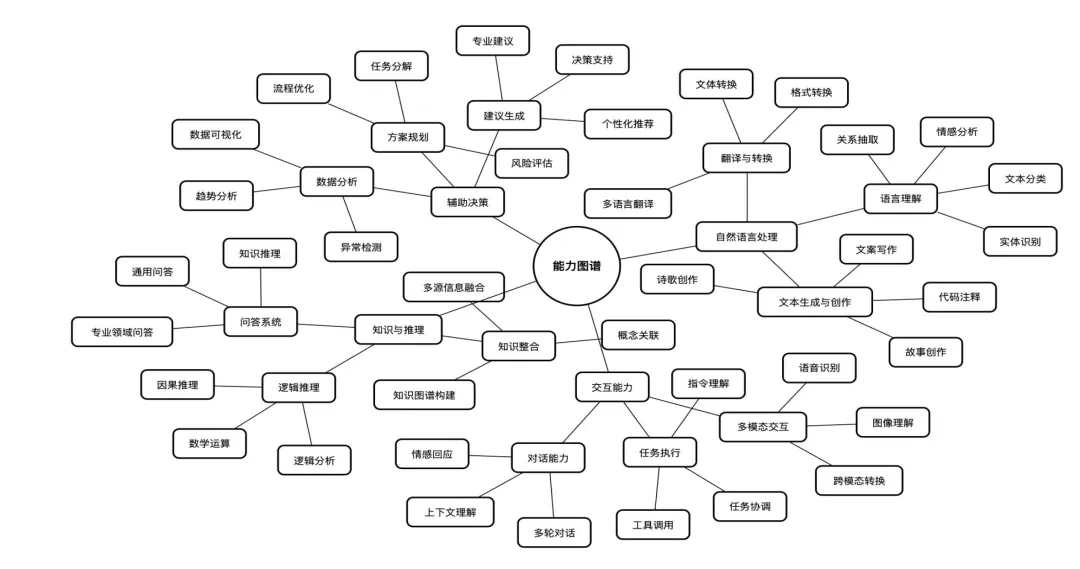
三、DeepSeek为什么能火?
媒体总说它是“AI圈的奇迹”,但哪有随随便便的成功?这背后是一群懂技术、有理想的人实打实拼出来的。
(1)技术上:用巧劲代替蛮干
DeepSeek的核心本事,是把“暴力堆算力”改成了“精准用算力”。比如它的Multi-Token Prediction(MTP)和Multi-Head Latent Attention(MLA)技术,就像给算力装了“智能开关”——原来处理一个任务要100度电,现在6.7度就够,KV缓存直接省了93.3%,跟节能灯似的,只在关键地方发力。
最让人叫绝的是R1模型,纯靠深度学习“自己悟”,数学和编程能力干过了Claude 3.5 Sonnet,推理成本却只有人家的1/50210。这得益于它的训练法革新:用规则奖励代替人工标注,砍了一堆没必要的环节,训练成本直接压到OpenAI的1/20。
还有V3模型,性能快追上GPT-4o了,预训练只花了600万美元;而OpenAI同类模型,没几亿美元下不来。
(2)硬件上:早就铺好了路
DeepSeek的“靠山”是幻方量化——国内顶尖的对冲基金,早就把AI用到了交易里。他们早看透了AI的潜力,2021年就在出口限制前囤了1万块A100 GPU;2023年把DeepSeek分拆独立后,又给它搭了5万块GPU的超级集群(用的是合规的H800和H20)。
这种提前布局,让DeepSeek一有技术突破,就能马上用足够的算力验证,不用等“弹药”。
(3)团队上:小而精的“特种部队”
150人的团队,全是北大、浙大等顶尖高校的人才,年薪开到130万美元(约934万人民币),比国内同行高一大截;还没什么层级官僚,决策快得像初创公司。更关键的是,这些人能随便调用1万多块GPU,自己建了数据中心,全技术栈都攥在手里,不看别人脸色。
这种“小团队+大资源”的模式,让它既能像小公司一样灵活,又有巨头级的实力。
(4)策略上:开源免费拉近距离
以前,好的大模型要么像ChatGPT、Claude那样闭源(只能用,不知道咋回事),要么像LLama、Qwen这样的开源模型,总感觉比第一梯队差口气。DeepSeek一出来,直接打破了这个局面——开源模型也能这么好用。
这一招让普通人都能用起来、传起来,一下子成了现象级产品。
四、DeepSeek带来了什么影响?
它就像AI圈的“鲶鱼”,不光推着大模型开源往前走,还让全球的大模型竞赛节奏更快了——大家都得卯着劲创新,不然就被甩在后面。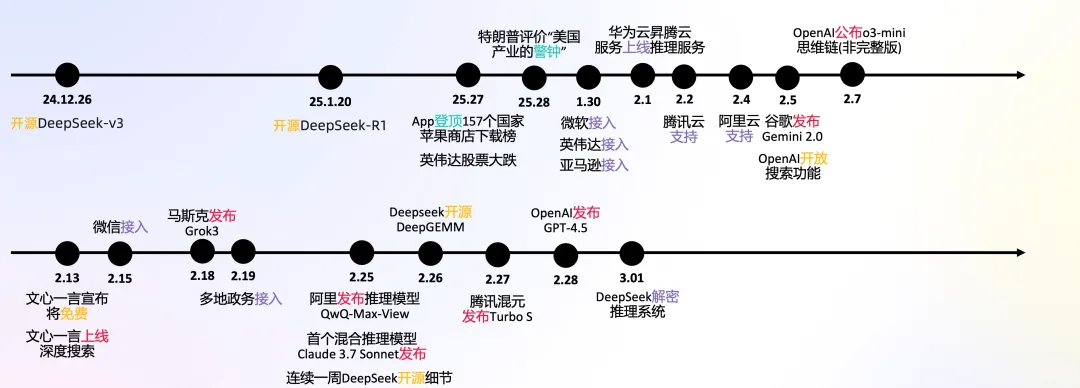
五、DeepSeek的坎儿在哪里?
别看现在风光,它面临的挑战可不少。
(1)硬件还是卡脖子
DeepSeek靠“算法省芯片”确实厉害,动态计算技术让同等算力下效率翻好几倍,相当于用“战术”破了传统算力竞赛的局。但算法优势总有天花板,随着模型越来越强,芯片不够的问题迟早会冒出来。在全球芯片封锁的大环境下,还得指望国内芯片能跟上。
(2)美国的反击越来越猛
估计它要走华为的老路了。OpenAI先是说它“蒸馏”自己的技术,接着又是持续的DDoS攻击,美国各级政府也老提“DeepSeek的威胁”——这些都说明,来自海外的压力只会越来越大。
(3)人才成了“香饽饽”
出名之后,团队成了各大厂挖角的目标。150人的小团队,要是核心人才被高薪挖走,影响可不小。已经有消息说罗福莉被小米以千万年薪挖走了,接下来怎么留住人,是DeepSeek必须解决的问题。好在它现在名气大,对有理想、想搞技术的人来说,吸引力还是很足的。
六、怎么用DeepSeek?
两种方式很简单:电脑上直接搜访问官网;手机上在应用商店搜“DeepSeek”下载APP就行。
界面跟一般大模型差不多,重点在“深度思考”和“联网搜索”两个功能。点“深度思考”,它会先自己琢磨问题的方方面面,答案更靠谱;开“联网功能”,它会先全网搜最新信息,适合问时事。
七、怎么跟DeepSeek“好好说话”?
网上传了一堆技巧,一会儿说“提需求别给指令”,一会儿又说“赛博人格分裂”,其实不用这么复杂。
看官方例子就知道,给指令是管用的。我还专门问过DeepSeek:“该怎么给你指令?”总结下来就一条:把需求说清楚。你越知道自己想要啥,它就越能帮到你。
想让需求更清楚,除了自己想明白、说准确,还能这么做:
- 让它自己给提示词:比如问“帮我写一个能让你清晰理解‘XX问题’的提示词”,它会帮你梳理;
- 告诉它答案给谁看:加上“说人话”“给小孩听”“给领导汇报”,结果会完全不一样。
比如问“什么是通货膨胀”:
- 说人话:“就是钱不值钱了,以前10块买3斤苹果,现在只能买1斤”;
- 学术回答:“指流通中的货币量超过实际需求,导致货币贬值、物价普遍持续上涨的经济现象”;
- 给小孩听:“就像你手里的贴纸,本来1张贴纸能换1块糖,现在大家手里的贴纸都变多了,得3张贴纸才能换1块糖——贴纸就是钱,糖就是你想买的东西”。
所以,用好它的关键就俩:需求清晰+读者身份清晰。
八、能在自己电脑上装DeepSeek吗?
最近DeepSeek太火,加上海外的DDoS攻击,时不时会崩。于是有人想“本地部署自救”,但装完发现效果差远了——为啥?
因为本地能装的开源模型,参数大多是1.5B-7B(比如deepseek-r1-1.5b、deepseek-r1-7b),而官网用的是千亿级参数模型,推理能力、写长文的本事根本不是一个量级。而且受限于电脑显存,跑起来特别慢,效率很低。
但本地部署也不是没用,最大的意义是让你学用最新开源工具,说不定能发现新机会。现在开源是趋势,加上AI帮忙,部署越来越简单,值得试试。
步骤就4步:
- 装Ollama:这是个大模型运行工具,去官网下载;
- 下DeepSeek:在Ollama里搜deepseek-r1,选适合你电脑配置的版本(1.5b或7b),复制命令;
- 跑命令:打开电脑的命令行窗口,粘贴刚才的命令,它会自动下载运行(下次用也这么操作);
- (可选)装Chatbox AI:如果不习惯命令行,去下载,它能提供对话窗口。
九、DeepSeek崩了怎么办?
本地部署不靠谱,真正的办法是用线上平替。因为DeepSeek是开源的,好多有实力的平台已经部署了它的671B满血版,不少还免费。
亲测有效的有10个:硅基流动、秘塔AI搜索、英伟达、国家超算互联网、perplexity AI、poe、Groq、Lambda.chat、Cursor、官方API。
简单说:国内用硅基流动或秘塔AI,海外用perplexity AI或Lambda.chat,具体可以看我另一篇详细对比的文章。
十、普通人怎么抓住DeepSeek的机会?
AI革命的核心,是给每个人加了个“数字分身”。DeepSeek的价值不是替代人思考,而是帮普通人“放大能力”。
遇到这种级别的机遇,得亲自下场试试:
- 站在技术前排:朋友圈刷到AI新工具,赶紧注册用用;看到新功能(比如能自动做报表、优化客服),动手测试效果,不用懂代码,看懂趋势就行;
- 学会跟AI“聊天”:平时遇到问题就丢给它,慢慢练出“AI听得懂的表达”;
- 做“行业接线员”:把你的专业经验和DeepSeek结合起来,比如房产中介用它生成个性化房源视频,转化率可能翻番。
别担心起步晚,现在用DeepSeek,你已经领先99%的人了。它才刚开始,正等着各行各业的人,带着它去闯每一个领域呢。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 28
28 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)