[论文阅读]FLARE: Toward Universal Dataset Purification Against Backdoor Attacks
No.4、后门攻击

期刊+链接:IEEE Transactions on Information Theoryhttps://ieeexplore.ieee.org/document/11045703
摘要
英文:Deep neural networks (DNNs) are susceptible to backdoor attacks, where adversaries poison datasets with adversary-specified triggers to implant hidden backdoors, enabling malicious manipulation of model predictions. Dataset purification serves as a proactive defense by removing malicious training samples to prevent backdoor injection at its source. We first reveal that the current advanced purification methods rely on a latent assumption that the backdoor connections between triggers and target labels in backdoor attacks are simpler to learn than the benign features. We demonstrate that this assumption, however, does not always hold, especially in all-to-all (A2A) and untargeted (UT) attacks. As a result, purification methods that analyze the separation between the poisoned and benign samples in the input-output space or the final hidden layer space are less effective. We observe that this separability is not confined to a single layer but varies across different hidden layers. Motivated by this understanding, we propose FLARE, a universal purification method to counter various backdoor attacks. FLARE aggregates abnormal activations from all hidden layers to construct representations for clustering. To enhance separation, FLARE develops an adaptive subspace selection algorithm to isolate the optimal space for dividing an entire dataset into two clusters. FLARE assesses the stability of each cluster and identifies the cluster with higher stability as poisoned. Extensive evaluations on benchmark datasets demonstrate the effectiveness of FLARE against 22 representative backdoor attacks, including all-to-one (A2O), all-to-all (A2A), and untargeted (UT) attacks, and its robustness to adaptive attacks. Codes are available at BackdoorBox and backdoor-toolbox. Index Terms—Dataset purification, backdoor defense, backdoor learning, trustworthy ML, responsible AI.
中文:深度神经网络(DNNs)易受后门攻击。在这类攻击中,攻击者会用自行指定的触发器对数据集进行 “投毒”,以植入隐藏后门,进而对模型预测结果实施恶意操控。数据集净化技术通过移除具有恶意的训练样本,从源头阻止后门注入,是一种主动防御手段。
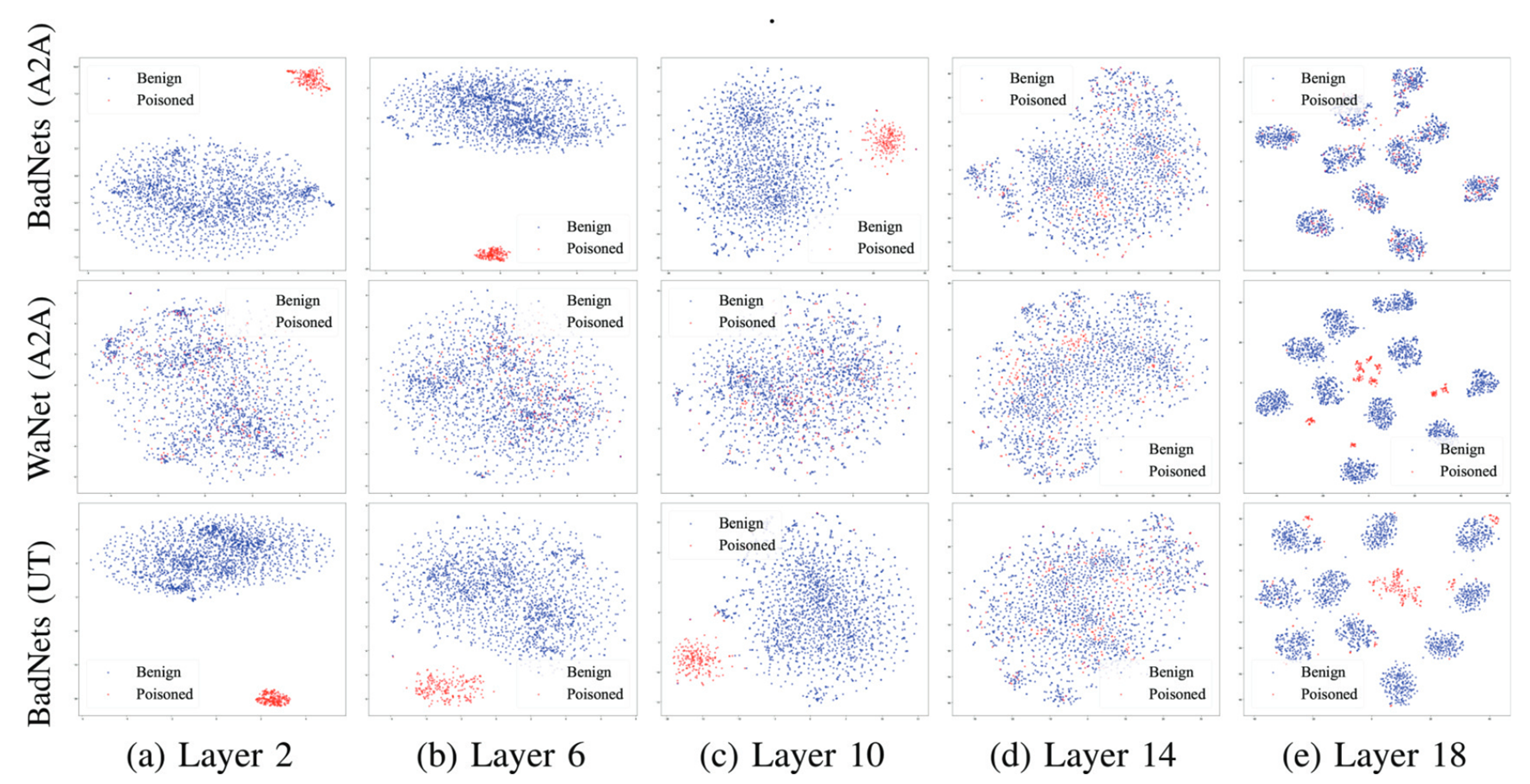
文首先指出,当前主流的先进净化方法均依赖于一个潜在假设:在后门攻击中,触发器与目标标签之间的后门关联,比正常特征更易于学习。然而,我们证明该假设并非始终成立 —— 尤其在 “全对全”(A2A)攻击和 “无目标”(UT)攻击场景下。这导致了一类净化方法的效果大打折扣,这类方法的核心逻辑是通过分析 “投毒样本” 与 “正常样本” 在输入 - 输出空间或最终隐藏层空间中的分离度来实现净化。
我们观察到,这种样本分离特性并不局限于单一网络层,而是在不同隐藏层间存在差异。基于这一认知,我们提出了一种适用于多种后门攻击的通用净化方法 ——FLARE。该方法通过聚合所有隐藏层的异常激活值构建聚类所需的特征表示;为提升样本分离效果,FLARE 设计了自适应子空间选择算法,以筛选出最优空间,将整个数据集划分为两个聚类;随后,FLARE 会评估每个聚类的稳定性,并将稳定性更高的聚类判定为 “投毒样本聚类”。
在基准数据集上的大量实验表明:FLARE 对 22 种典型后门攻击(包括 “全对一”(A2O)、“全对全”(A2A)及 “无目标”(UT)攻击)均能有效防御,且对自适应攻击具备鲁棒性。相关代码已开源至 BackdoorBox 与 backdoor-toolbox 平台。
关键词:数据集净化;后门防御;后门学习;可信机器学习(trustworthy ML);负责任人工智能(responsible AI)
论文方法:FLARE
FLARE(Full-spectrum Learning Analysis for Removing Embedded poisoned samples)通过全层特征分析和自适应聚类实现通用数据集净化,分为两大阶段:
stage 1: latent 表示提取(构建全层异常特征)
整合所有隐藏层的异常激活,形成样本的综合表示,解决特征尺度差异和高维噪声问题:
- 特征对齐:利用批量归一化(BN)层的均值(μ)和方差(σ),将各隐藏层特征图归一化到 [0,1] 统一尺度。
- 异常特征提取:后门特征易引发极端激活值,从每个对齐后的特征图中提取最小值(代表异常),并整合所有隐藏层的最小值,形成样本的最终 latent 表示\(R_i\)。
stage 2:中毒样本检测(自适应聚类与稳定性评估)
通过聚类区分良性与中毒样本,核心是自适应子空间选择和聚类稳定性判断:
- 降维与聚类:用 UMAP 降维减少计算量,再用 HDBSCAN(层次密度聚类)将数据集分为两类(HDBSCAN 擅长处理不同形状 / 密度的簇)。
- 稳定子空间选择:深层网络侧重类别区分特征,易导致良性样本分散。FLARE 自适应排除最后几层特征,保留浅层语义特征,确保良性样本在子空间内聚集。
- 聚类稳定性评估:选出稳定性高的为中毒样本。定义稳定性\(\kappa^C = \lambda_e^C - \lambda_s^C\)(\(\lambda_s^C\)为簇首次出现的密度水平,\(\lambda_e^C\)为簇分裂前的密度水平)。中毒样本因共享触发特征,形成的簇更紧凑、稳定性更高,故将高稳定性簇判定为中毒样本。
后处理策略
- 策略 1:从零安全训练:移除检测出的中毒样本,用净化后的数据集重新训练模型,确保无后门。
- 策略 2:后门移除:通过 “遗忘 - 重学习” 两步优化:先对中毒样本最大化交叉熵损失(遗忘后门关联),再用良性样本微调(恢复良性任务性能)。
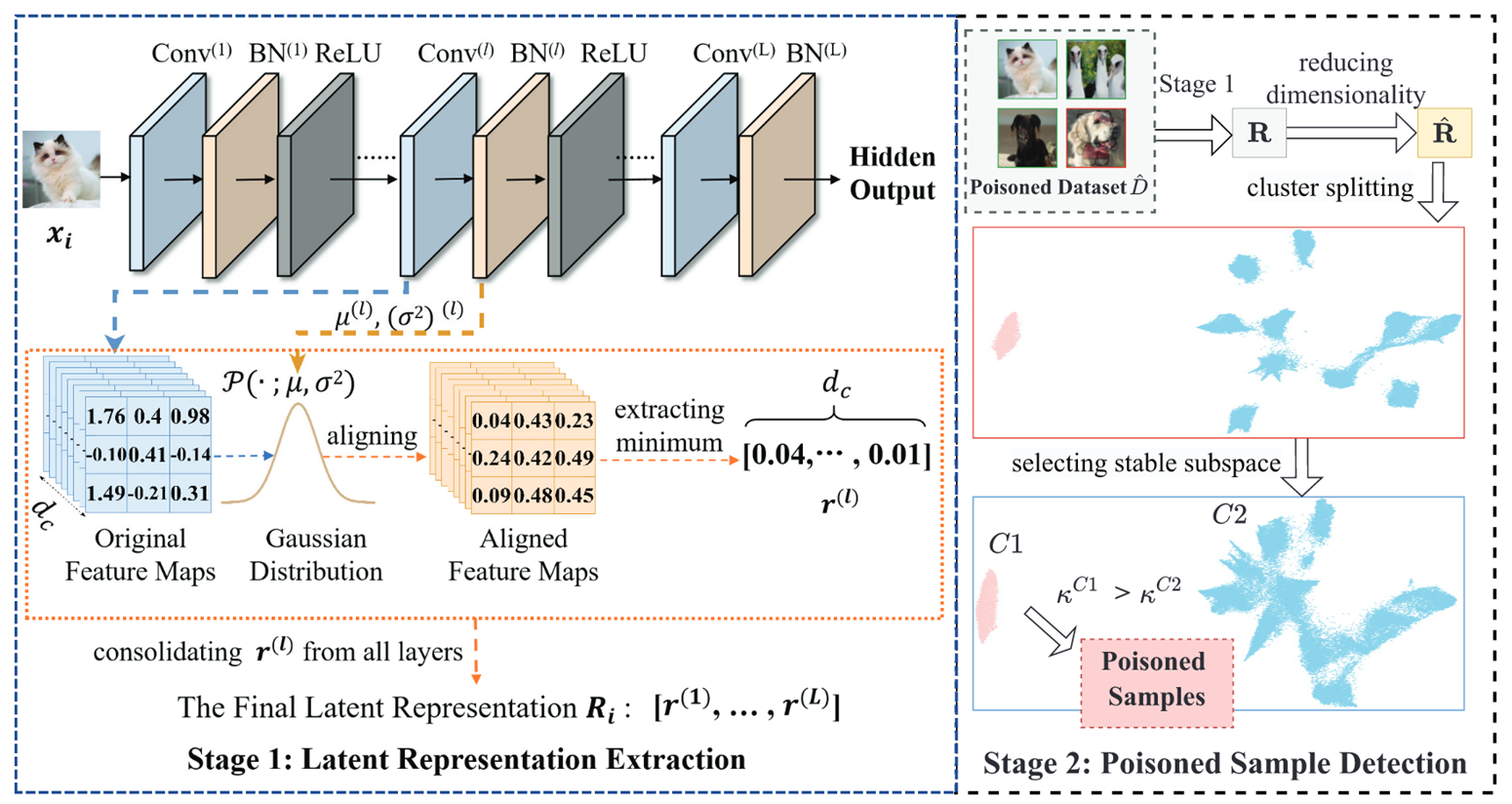
dc为Conv通道数、L为隐藏层层数、Ri为单个样本异常特征
思考问题
- 额外时间开销:相比标准训练,需额外 180 秒(ResNet-18+CIFAR-10)用于特征提取与聚类,未来可优化效率。
- 触发逆向缺失:仅检测中毒样本,无法逆向恢复触发模式,后续需研究触发追踪技术。
- 任务范围局限:当前聚焦图像分类,未来计划扩展至多模态数据(语音、文本)的跨模态后门防御。
小结
假设出 毒化与良性样本的潜在可分离性在不同层存在差异。基于此,提出的 FLARE 方法通过聚合所有隐藏层的异常特征构建潜在表示,并结合自适应子空间选择和簇稳定性评估检测毒化样本。在 22 种后门攻击的实验中,FLARE 展现出卓越的有效性和鲁棒性,为后门攻击防御提供了通用且高效的解决方案。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 19
19 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)