告别测试用例维护噩梦:AI自动修复脚本的2大原理
AI自动修复脚本不只是一个技术功能,而是一种测试哲学: 让测试系统像生命体一样具备“自愈力”,在变化中保持稳定,在演进中持续成长。 这正是智能化测试的未来方向。
📝 面试求职: 「面试试题小程序」 ,内容涵盖 测试基础、Linux操作系统、MySQL数据库、Web功能测试、接口测试、APPium移动端测试、Python知识、Selenium自动化测试相关、性能测试、性能测试、计算机网络知识、Jmeter、HR面试,命中率杠杠的。(大家刷起来…)
📝 职场经验干货:
一、引言:测试自动化的“幸福与痛苦”
自动化测试被誉为软件质量保障的“倍增器”,它能持续验证功能正确性、缩短回归周期、提升交付效率。然而,几乎每个测试团队都在经历同样的困境——脚本维护地狱。
新版本一发布,页面结构微调、元素属性变化、ID更新、XPath漂移……测试脚本批量失效。开发者的改动可能只是改了一个按钮的 class 名,却导致数十个测试用例“集体罢工”。最终,测试人员花在“修脚本”的时间,往往超过“写脚本”的时间。
这种现象被业内称为“自动化测试的悖论”:
自动化本应提升效率,却因为脚本脆弱性反而增加了成本。
过去,我们尝试用稳健定位策略、显式等待机制、页面对象模式(POM)等方式缓解问题,但都治标不治本。直到“AI自动修复脚本(AI-based Test Script Healing)”的出现,这个老问题才迎来了系统性的解决方案。
AI自动修复技术的核心目标是:当应用界面、接口或元素发生变化时,测试脚本能自动感知、智能匹配并完成自我修复,无需人工干预。
这背后支撑的,是两个关键原理:元素特征学习(Feature Learning)**与**语义意图识别(Semantic Intention Recognition)。
接下来,我们将深入剖析这两大原理的机制、算法、工程化实现与实际价值。
二、第一个原理:元素特征学习——让脚本具备“记忆力”
1. 问题的根源:定位信息的脆弱性
传统的测试脚本依赖显式定位符(Locator)来操作界面元素,例如:

然而,一旦前端修改了id或class,这段脚本立刻失效。
现实中,前端频繁重构是常态,尤其是在使用React、Vue或Angular等组件化框架时,DOM结构随版本动态生成。
换句话说,脚本“只认ID”,一旦“脸变了”,就不认识了。
AI自愈技术的第一个任务,就是让机器学会“记人”,而不是“记名字”。
2. 核心机制:元素多特征向量化
在AI自愈系统中,每个UI元素不再仅仅以ID或XPath表示,而是被抽象为特征向量(Feature Vector),包括以下维度:
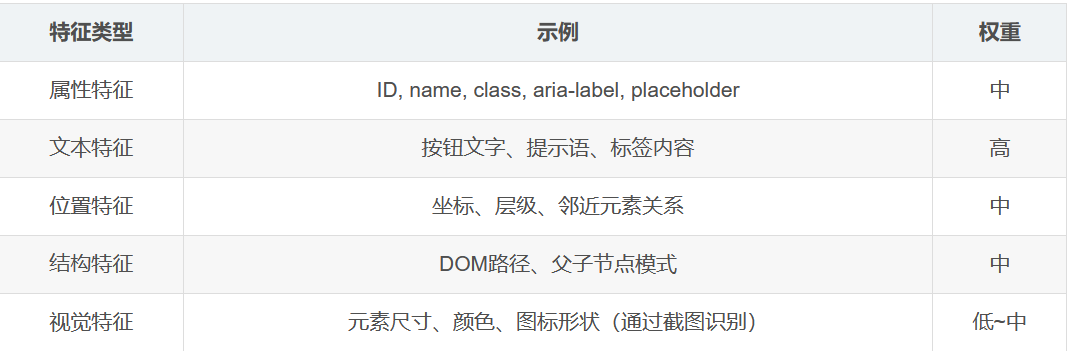
这些特征通过Embedding技术(如Word2Vec、BERT或自定义UI Embedding模型)映射到统一向量空间中。
在脚本执行时,如果原定位符失效,系统会触发特征匹配算法(通常是余弦相似度或欧式距离计算),寻找最相似的候选元素。
举例说明:
假设“登录按钮”原本定义为:
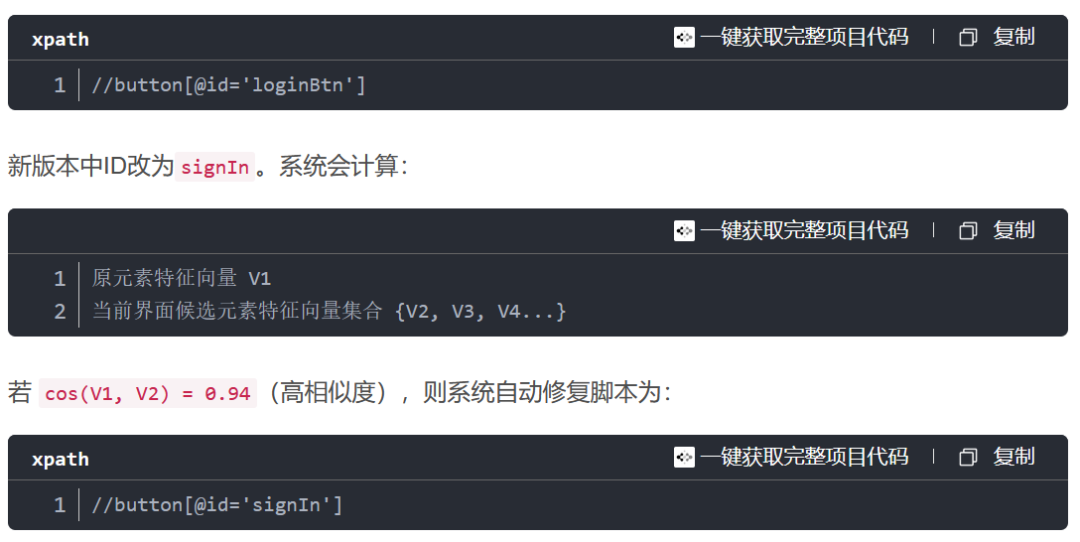
并记录修复历史供回溯分析。
3. 智能权重机制与置信度计算
实际场景中,某些特征的变化比其他特征更重要。例如:
-
按钮文字变化(如“提交”→“确认”)可能意味着功能逻辑调整;
-
class 名变化则可能只是样式重构。
因此系统会采用动态加权算法:

当置信度高于阈值(如0.85),系统执行自动修复;
当置信度处于灰区(如0.6-0.85),则触发人工确认;
当低于阈值,则中止执行并上报异常。
这种机制让自愈系统既大胆修复,又谨慎保守。
三、第二个原理:语义意图识别——让脚本具备“理解力”
1. 问题的第二层:定位修了,断言仍会错
即使元素能被重新定位,测试脚本仍可能因逻辑变化而失败。
比如:

新版本文案改为“Hello again”,脚本依然报错。
从功能角度看,这是预期变化,但传统脚本并不理解语义。
因此,AI自愈的第二个原理,就是让脚本具备**“语义理解”与“意图判断”**能力。
2. 语义识别的核心:从字符串匹配到语义对齐
传统断言基于字符串或正则表达式匹配,而语义意图识别使用自然语言模型(如BERT、SimCSE、ERNIE等)将文本嵌入语义空间。
系统不再判断两句话“是否相同”,而是判断“是否表达相同含义”。
例如:
“登录成功” 与 “欢迎回来” 的语义相似度 = 0.91
“登录成功” 与 “登录失败” 的相似度 = 0.05
这样,当UI文案更新时,系统能自动判断是否属于同义替换,而不触发断言错误。
3. 行为语义识别:理解用户意图
除了文本断言外,语义识别还可应用于行为意图层面。
假设原脚本执行:

新版本中“提交”按钮改为“立即下单”,系统通过语义分析识别出两者意图一致,因此自动替换目标元素。
甚至在复杂交互中(如下单→跳转→确认→提示),系统能根据事件序列建模(Sequence Modeling)推断“业务流程一致”,从而继续执行测试而非误判失败。
这种“语义自适应”能力,让脚本能够跨版本运行,而不被表层变化干扰。
4. 自学习机制:修复即训练
当人工确认AI修复结果正确时,系统会将该样本反向注入模型进行增量训练。
这意味着每一次修复都在“教机器更懂项目”。
久而久之,系统逐步掌握产品的语义风格与业务逻辑,实现项目专属的语义适应模型。
这也是AI自动修复区别于传统规则引擎的关键所在:
它不是一套静态规则,而是一套能持续进化的知识系统。
四、AI自动修复脚本的工程闭环
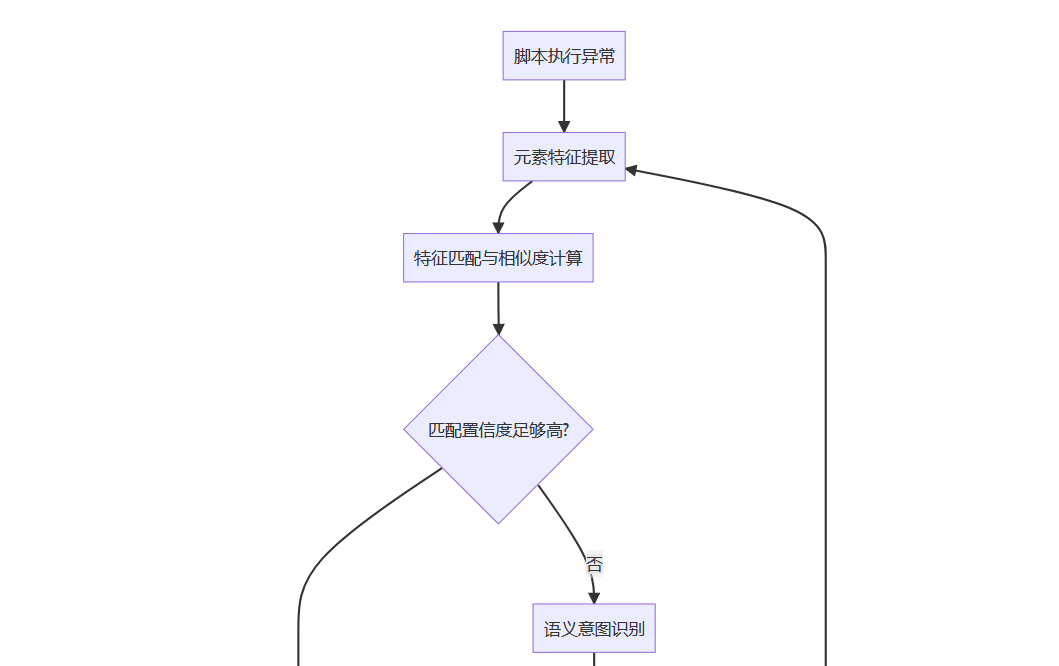
完整的AI自动修复体系包括以下环节:
异常捕获:检测脚本执行异常(如元素丢失、断言失败)
特征提取:从DOM、文本、视觉特征中构建向量
匹配决策:计算相似度与置信度
意图识别:判断是否为语义等价变更
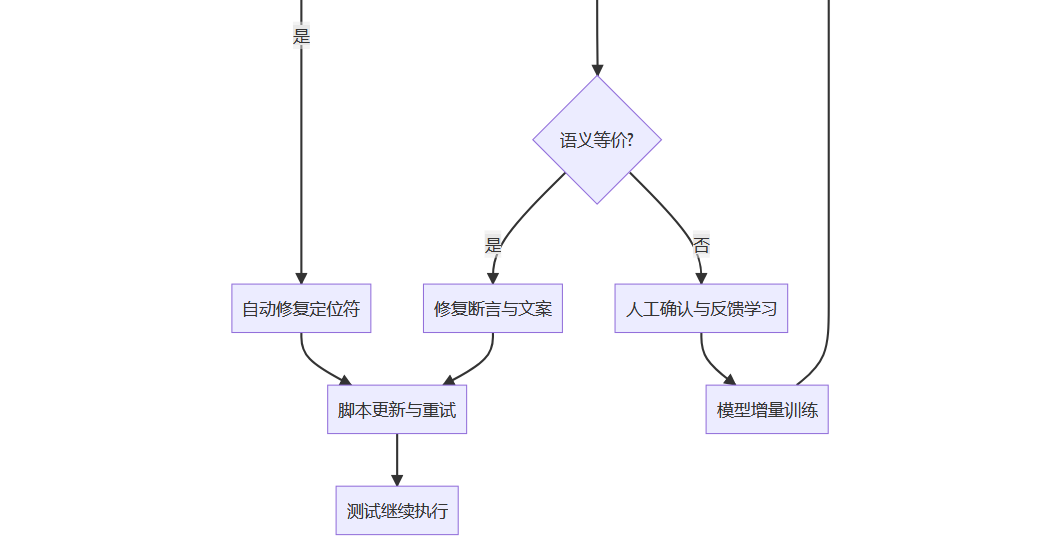
脚本更新:自动替换或标记修复
反馈学习:人工确认后的样本反向训练模型
这一闭环实现了“自我感知—自我修复—自我学习”的智能测试进化路径。
五、实践成效:从脆弱性到韧性
实际案例显示:
使用AI自愈技术后,脚本维护量可减少60%以上;
测试通过率提升20%-40%;
平均修复时间从“人均30分钟”降至“机器3秒钟”。
更重要的是,测试团队不再陷于“修脚本的循环地狱”,而能把精力转向用例设计、覆盖率优化和风险评估。
AI自动修复并非取代测试工程师,而是让他们从“体力修复者”变为“智能监督者”。
它让自动化测试真正成为“持续可维护”的系统,而非“一次性脚本工程”。
六、总结:测试的未来属于“自愈生态”
AI自动修复的两大原理——元素特征学习与语义意图识别,本质上代表着测试从“被动执行”迈向“主动理解”的演化。
未来的测试体系,不仅要能运行,还要能适应变化、感知异常、自动修复、持续学习。
这是一场从“可执行”到“可进化”的革命。
下图展示了AI自动修复脚本的整体工作流程:
AI自动修复脚本不只是一个技术功能,而是一种测试哲学: 让测试系统像生命体一样具备“自愈力”,在变化中保持稳定,在演进中持续成长。 这正是智能化测试的未来方向。
最后: 下方这份完整的软件测试视频教程已经整理上传完成,需要的朋友们可以自行领取【保证100%免费】



有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 15
15 0
0- 0



 已为社区贡献93条内容
已为社区贡献93条内容

所有评论(0)