构建一个自主深度思考的RAG管道以解决复杂查询深--深度思考RAG管道(1)
在我们开始编写深度检索增强生成(Deep RAG)管道的代码之前,我们需要先打好坚实的基础,因为生产级的AI系统不仅关乎最终的算法,还关乎我们在设置过程中所做的深思熟虑的选择。当我们开始开发一个管道并对其进行反复试验时,以普通字典格式定义我们的配置会更好,因为在后续管道变得复杂时,我们可以简单地参考这个字典来更改配置,并查看其对整体性能的影响。为了测试我们实现的管道并将其与基本的检索增强生成(RA
一个RAG系统常常失败,不是因为大语言模型缺乏智能,而是因为其架构过于简单。它试图用线性、一次性的方法来处理一个循环、多步骤的问题。
许多复杂的查询需要推理、反思,以及明智的决策,即何时采取行动,这很像我们面对问题时检索信息的方式。这就是RAG流程中由智能体驱动的行动发挥作用的地方。让我们来看看一个典型的深度思考RAG流程是什么样的……
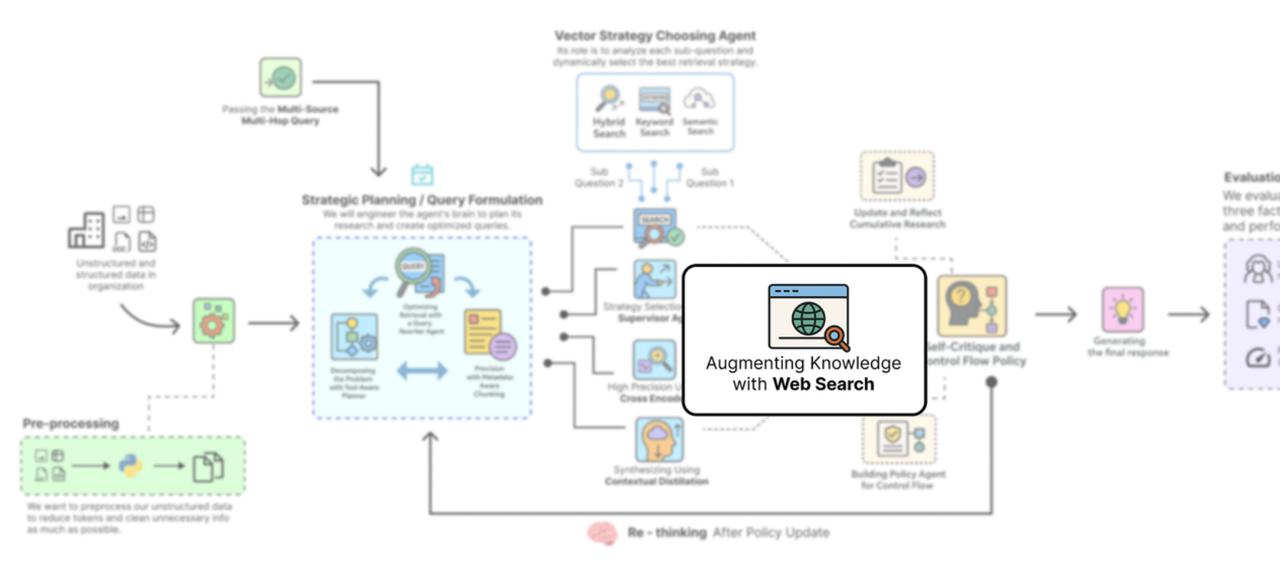
深度思考RAG管道(作者:法里德·汗)
-
计划:首先,智能体将复杂的用户查询分解为一个结构化的多步骤研究计划,确定每一步需要使用哪种工具(内部文档搜索或网络搜索)。
-
检索:对于每一步,它都会执行一个自适应的多阶段检索漏斗,使用监督器动态选择最佳搜索策略(向量、关键词或混合策略)。
-
精炼:然后使用高精度交叉编码器对初始结果进行重新排序,并使用蒸馏器代理将最佳证据压缩成简洁的上下文。
-
反思:每完成一步,智能体都会总结其发现并更新其研究历史,逐步积累对问题的理解。
-
评估:然后,策略代理会检查这段历史,做出战略决策,决定是继续进行下一个研究步骤、在遇到死胡同时修改计划,还是结束。
-
综合整理:研究完成后,最终的智能体将所有来源收集到的证据整合为一个单一、全面且可引用的答案。
在这篇博客中,我们将实现整个深度思考RAG管道,并将其与基本RAG管道进行比较,以展示它如何解决复杂的多跳查询。
所有代码和理论都可以在我的GitHub仓库中找到:
GitHub - FareedKhan-dev/deep-thinking-rag: A Deep Thinking RAG
Pipeline to Solve Complex Queries
A Deep Thinking RAG Pipeline to Solve Complex Queries - GitHub -
FareedKhan-dev/deep-thinking-rag: A Deep Thinking RAG...github.com
目录
-
环境搭建
-
获取知识库
-
了解我们的多源、多跳查询
-
构建一个注定失败的浅层RAG管道
-
定义中央代理系统的RAG状态
-
战略规划与查询制定 ∘ 使用工具感知规划器分解问题 ∘ 使用查询重写代理优化检索 ∘ 通过元数据感知分块提高精度
-
创建多阶段检索漏斗 ∘ 使用监督器动态选择策略 ∘ 通过混合、关键词和语义搜索实现广泛召回 ∘ 使用交叉编码器重排器实现高精度 ∘ 使用上下文蒸馏进行合成
-
通过网络搜索扩充知识
-
自我批判与控制流策略 ∘ 更新并反思累积研究历史 ∘ 构建控制流策略代理
-
定义图节点
-
定义条件边
-
深度思考RAG机器的布线
-
编译和可视化迭代工作流程
-
运行深度思考管道
-
分析最终的高质量答案
-
并排比较
-
评估框架与分析结果
-
总结我们的整个流程
-
基于马尔可夫决策过程(MDP)的学习策略
环境搭建
在我们开始编写深度检索增强生成(Deep RAG)管道的代码之前,我们需要先打好坚实的基础,因为生产级的AI系统不仅关乎最终的算法,还关乎我们在设置过程中所做的深思熟虑的选择。
我们将要实施的每一个步骤,对于确定最终系统的有效性和可靠性都至关重要。
当我们开始开发一个管道并对其进行反复试验时,以普通字典格式定义我们的配置会更好,因为在后续管道变得复杂时,我们可以简单地参考这个字典来更改配置,并查看其对整体性能的影响。
# Central Configuration Dictionary to manage all system parameters
config = {
"data_dir": "./data", # Directory to store raw and cleaned data
"vector_store_dir": "./vector_store", # Directory to persist our vector store
"llm_provider": "openai", # The LLM provider we are using
"reasoning_llm": "gpt-4o", # The powerful model for planning and synthesis
"fast_llm": "gpt-4o-mini", # A faster, cheaper model for simpler tasks like the baseline RAG
"embedding_model": "text-embedding-3-small", # The model for creating document embeddings
"reranker_model": "cross-encoder/ms-marco-MiniLM-L-6-v2", # The model for precision reranking
"max_reasoning_iterations": 7, # A safeguard to prevent the agent from getting into an infinite loop
"top_k_retrieval": 10, # Number of documents for initial broad recall
"top_n_rerank": 3, # Number of documents to keep after precision reranking
}这些键很容易理解,但有三个键值得一提:
-
大语言模型提供商:这是我们正在使用的大语言模型提供商,在本例中是OpenAI。我选择OpenAI是因为我们可以在LangChain中轻松切换模型和提供商,但你也可以选择任何适合你需求的提供商,比如Ollama。
-
推理大语言模型:在我们的整个设置中,它一定是最强大的,因为它将用于规划和综合。
-
fast_llm: 这应该是一个更快、更便宜的模型,因为它将用于像基线RAG这样的简单任务。
现在我们需要导入在整个流程中会用到的所需库,并将 API 密钥设置为环境变量,以避免在代码块中暴露这些密钥。
import os # For interacting with the operating system (e.g., managing environment variables)
import re # For regular expression operations, useful for text cleaning
import json # For working with JSON data
from getpass import getpass # To securely prompt for user input like API keys without echoing to the screen
from pprint import pprint # For pretty-printing Python objects, making them more readable
import uuid # To generate unique identifiers
from typing import List, Dict, TypedDict, Literal, Optional # For type hinting to create clean, readable, and maintainable code
# Helper function to securely set environment variables if they are not already present
def _set_env(var: str):
# Check if the environment variable is not already set
if not os.environ.get(var):
# If not, prompt the user to enter it securely
os.environ[var] = getpass(f"Enter your {var}: ")
# Set the API keys for the services we will use
_set_env("OPENAI_API_KEY") # For accessing OpenAI models (GPT-4o, embeddings)
_set_env("LANGSMITH_API_KEY") # For tracing and debugging with LangSmith
_set_env("TAVILY_API_KEY") # For the web search tool
# Enable LangSmith tracing to get detailed logs and visualizations of our agent's execution
os.environ["LANGSMITH_TRACING"] = "true"
# Define a project name in LangSmith to organize our runs
os.environ["LANGSMITH_PROJECT"] = "Advanced-Deep-Thinking-RAG"我们还启用了 LangSmith 进行追踪。当你使用具有复杂、循环工作流程的智能体系统时,追踪不仅仅是锦上添花,它很重要。它能帮助你直观地了解正在发生的事情,并且让调试智能体的思维过程变得容易得多。
获取知识库
一个生产级的RAG系统需要一个既复杂又要求高的知识库,才能真正展现其有效性。为此,我们将使用NVIDIA的2023年10-K文件,这是一份超过一百页的综合文件,详细介绍了该公司的商业运营、财务业绩和披露的风险因素。
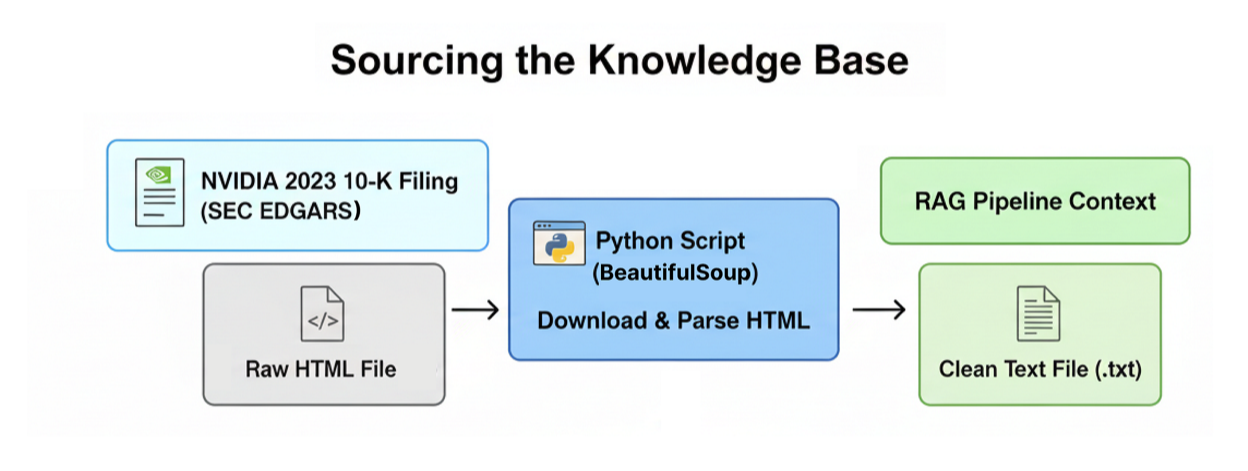
深度思考RAG管道(作者:法里德·汗)
首先,我们将实现一个自定义函数,该函数将以编程方式直接从SEC EDGAR数据库下载10-K文件,解析原始HTML,并将其转换为适合我们的RAG管道处理的简洁结构化文本格式。那么,让我们来编写这个函数。
import requests # For making HTTP requests to download the document
from bs4 import BeautifulSoup # A powerful library for parsing HTML and XML documents
from langchain.docstore.document import Document # LangChain's standard data structure for a piece of text
def download_and_parse_10k(url, doc_path_raw, doc_path_clean):
# Check if the cleaned file already exists to avoid re-downloading
if os.path.exists(doc_path_clean):
print(f"Cleaned 10-K file already exists at: {doc_path_clean}")
return
print(f"Downloading 10-K filing from {url}...")
# Set a User-Agent header to mimic a browser, as some servers block scripts
headers = {'User-Agent': 'Mozilla/5.0'}
# Make the GET request to the URL
response = requests.get(url, headers=headers)
# Raise an error if the download fails (e.g., 404 Not Found)
response.raise_for_status()
# Save the raw HTML content to a file for inspection
with open(doc_path_raw, 'w', encoding='utf-8') as f:
f.write(response.text)
print(f"Raw document saved to {doc_path_raw}")
# Use BeautifulSoup to parse and clean the HTML content
soup = BeautifulSoup(response.content, 'html.parser')
# Extract text from common HTML tags, attempting to preserve paragraph structure
text = ''
for p in soup.find_all(['p', 'div', 'span']):
# Get the text from each tag, stripping extra whitespace, and add newlines
text += p.get_text(strip=True) + '\n\n'
# Use regex to clean up excessive newlines and spaces for a cleaner final text
clean_text = re.sub(r'\n{3,}', '\n\n', text).strip() # Collapse 3+ newlines into 2
clean_text = re.sub(r'\s{2,}', ' ', clean_text).strip() # Collapse 2+ spaces into 1
# Save the final cleaned text to a .txt file
with open(doc_path_clean, 'w', encoding='utf-8') as f:
f.write(clean_text)
print(f"Cleaned text content extracted and saved to {doc_path_clean}")这段代码很容易理解,我们使用beautifulsoup4来解析 HTML 内容并提取文本。它将帮助我们轻松浏览 HTML 结构并检索相关信息,同时忽略任何不必要的元素,如脚本或样式。
现在,让我们执行这个并看看它是如何工作的。
print("Downloading and parsing NVIDIA's 2023 10-K filing...")
# Execute the download and parsing function
download_and_parse_10k(url_10k, doc_path_raw, doc_path_clean)
# Open the cleaned file and print a sample to verify the result
with open(doc_path_clean, 'r', encoding='utf-8') as f:
print("\n--- Sample content from cleaned 10-K ---")
print(f.read(1000) + "...")
#### OUTPUT ####
Downloading and parsing NVIDIA 2023 10-K filing...
Successfully downloaded 10-K filing from https://www.sec.gov/Archives/edgar/data/1045810/000104581023000017/nvda-20230129.htm
Raw document saved to ./data/nvda_10k_2023_raw.html
Cleaned text content extracted and saved to ./data/nvda_10k_2023_clean.txt
# --- Sample content from cleaned 10-K ---
Item 1. Business.
OVERVIEW
NVIDIA is the pioneer of accelerated computing. We are a full-stack computing company with a platform strategy that brings together hardware, systems, software, algorithms, libraries, and services to create unique value for the markets we serve. Our work in accelerated computing and AI is reshaping the worlds largest industries and profoundly impacting society.
Founded in 1993, we started as a PC graphics chip company, inventing the graphics processing unit, or GPU. The GPU was essential for the growth of the PC gaming market and has since been repurposed to revolutionize computer graphics, high performance computing, or HPC, and AI.
The programmability of our GPUs made them ...我们只是调用这个函数,将所有内容存储在一个txt文件中,该文件将作为我们的rag管道的上下文。
当我们运行上述代码时,你会发现它开始为我们下载报告,并且我们可以看到下载内容的示例是什么样子的。
了解我们的多源、多跳查询
为了测试我们实现的管道并将其与基本的检索增强生成(RAG)进行比较,我们需要使用一个非常复杂的查询,该查询要涵盖我们正在处理的文档的不同方面。
我们的复杂查询:根据NVIDIA 2023年的10-K文件,确定其与竞争相关的关键风险。然后,查找有关AMD的AI芯片战略的最新新闻(文件提交后,2024年),并解释这一新战略如何直接应对或加剧了NVIDIA所阐述的一项风险。
让我们来剖析一下,为什么这个查询对于标准的RAG管道来说如此困难:
-
多跳推理:它无法一步得出答案。系统必须首先识别风险,然后查找AMD新闻,最后将两者进行综合。
-
多源知识:所需信息存在于两个完全不同的地方。风险信息在我们的静态内部文件(10-K)中,而AMD新闻是外部信息,需要访问实时网络。
-
综合与分析:查询并非要求简单罗列事实,而是要求解释一组事实如何使另一组事实变得更糟,这一任务需要真正的综合能力。
在下一节中,我们将实现基本的RAG管道,实际上看看简单的RAG是如何在这方面失败的。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 21
21 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)