构建AI智能体:七十六、深入浅出LoRA:低成本高效微调大模型的原理与实践
LoRA(低秩自适应)是一种高效的大模型微调技术,通过冻结原始模型参数并引入低秩矩阵来捕捉任务特定特征,从而显著降低计算和存储成本。相比传统全参数微调,LoRA只需训练极少量参数(通常不到原模型的1%),却能获得相近效果。其核心原理是将权重更新矩阵分解为两个低秩矩阵的乘积,通过调整秩(r)、缩放因子(alpha)等参数控制微调强度。LoRA支持灵活的任务切换,只需更换适配器即可让模型快速适应不同领
一. 前言
在我们的印象中,我们曾比喻大模型为一位学识渊博、通晓古今的大学者,他读过亿万本书,知识储备深不可测。但是,如果我们先想让他成为我们公司的法律顾问,或者帮我们写中医养生文案,他可能会显得博而不专。如果直接让他去背法律条文或中医典籍,做一个全参数微调,这就像让这位大学者为了一个新专业,把他过去学过的所有知识都重新梳理、更新一遍,这个过程不仅耗时耗力,也需要巨大的算力和时间,而且成本极高,甚至可能因为学习新知识而干扰到他原有的广博学识,形成灾难性遗忘。
那么,有没有一种方法,能像给这位学者配一个专业速成笔记本一样,让他快速掌握新技能,同时又不用动他脑子里的底层知识呢?明确的说,是有的,这就是我们今天要介绍的LoRA技术。它是一种 “轻量级微调” 或 “高效参数微调” 方法,能让我们用极低的成本,为庞大的AI模型注入专属技能。
二、LoRA基础
1. 基础概念
LoRA,英文全称是 Low-Rank Adaptation of Large Language Models,中文翻译为 “大语言模型的低秩自适应”。这个名字听起来很复杂,但我们把它拆开看:
- Large Language Models: 就是我们的大学者,庞大的基础模型。
- Adaptation: 目标是适配或定制,让模型适应新任务。
- Low-Rank: 这是LoRA的核心魔法,意思是 “低维度”。我们稍后会详细解释。
简单来说,LoRA就是一种用小改动实现大效果的模型微调技术。
2. 通俗解释
简单明了的标识就是:给模型穿上一件特殊的技能马甲,让我们用一个更生活化的比喻来理解:
- 基础模型: 就像一件百搭的纯色基础款T恤。
- 全参数微调: 为了参加一个派对,你把整件T恤重新染色、印花。效果虽好,但过程不可逆,这件T恤再也变不回原来的样子了,而且每次换场合都要重新染一件,成本很高。
- LoRA微调: 我们不需要动T恤本身,而是为它准备了很多件不同的魔术贴徽章或技能马甲。
- 需要它变成法律顾问,那就贴上法律徽章,套上律师马甲。
- 需要它变成中医大师,那就换上中医徽章,套上养生马甲。
- 活动结束,把马甲和徽章一摘,T恤还是那件原汁原味的百搭T恤。
这些技能马甲就是LoRA训练出来的小文件,通常只有几MB到几百MB,而原始的T恤(基础模型)往往有几十GB。 这就是LoRA在存储和切换上的巨大优势。
三、LoRA的核心原理
1. 核心思想:参数高效性微调
AI模型的核心是无数个权重矩阵,我们可以把它们想象成模型大脑中负责决策的“神经突触连接强度”。在微调时,我们希望调整这些连接强度,让模型在新任务上表现更好。在LoRA出现之前,微调大型模型的主流方法是全参数微调。这意味着需要更新模型所有权重,可能包含数十亿甚至数千亿参数,这带来了巨大的计算、存储和硬件成本。
LoRA的核心思想基于一个关键的假设:模型在适应新任务时,其权重变化具有“低内在秩”。尽管模型本身非常庞大,高维,但当它学习一个新任务时,其需要做出的“改变量”其实是可以用一个低维度的结构来有效表示的。简单来说,尽管模型的权重矩阵很大(例如 4096 x 4096),但其在任务适配过程中的变化量(ΔW)可以用一个低维度的矩阵来有效表示。
通俗的理解:
制作一个复杂的乐高城市沙盘需要成千上万个积木,此沙盘好比我们的基础模型。现在,我们需要把这个沙盘从现代都市改造成科幻未来城。我们不需要把每一个积木都拆掉重拼,也就是不需要进行全参数微调。观察后发现,大部分改变都集中在给大楼加上霓虹灯、给街道换上磁悬浮轨道、给天空加上飞行器这几个核心维度上。你只需要设计一套科幻改造套件,这个套件就可以理解为低秩矩阵,直接附加在原有的沙盘上,就能实现目标。
2. 技术原理:低秩分解与旁路矩阵
在技术上,首先对比一下传统微调和LoRA微调的差异行性:
- 传统微调: 对于一个预训练好的权重矩阵 W,我们直接更新它,得到新矩阵 W‘ = W + ΔW。这个 ΔW 是一个和 W 一样大的矩阵,参数极多。
- LoRA微调:
- 1. 冻结原始权重 W,不让它发生任何变化。
- 2. 我们不去直接学习巨大的 ΔW,而是用两个更小、更瘦的矩阵 A 和 B 来模拟它。具体来说,我们让 ΔW = B × A。
- 矩阵 A 负责将输入数据降维到一个低维空间(秩 r)。
- 矩阵 B 负责将这个低维表示再升维回原来的维度。
- 3. 最终,模型的前向传播公式变为:输出 = W × 输入 + B × A × 输入。
换个方式说明:
想象一个预训练好的权重矩阵 W₀(维度为 d x k)。在微调过程中,它的更新是 ΔW。全参数微调直接学习 ΔW(也是一个 d x k 的大矩阵)。
LoRA的做法是:
- 1. 冻结预训练模型的所有原始权重 W₀。在训练过程中,它们保持不变。
- 2. 对于需要更新的每个权重矩阵 W₀,引入一对低秩分解矩阵 A 和 B。
- A 的维度是 d x r(行数 x 秩)
- B 的维度是 r x k(秩 x 列数)
- 其中,秩 r << min(d, k)(例如,r=4, 8, 16)。
- 3. 权重矩阵的更新量 ΔW 就由这两个小矩阵的乘积来表示:
- ΔW = B A
- 所以,前向传播的计算公式变为:h = W₀x + ΔWx = W₀x + BAx
直观理解:
与其直接学习一个巨大的 ΔW(有 d*k 个参数),LoRA只学习两个小矩阵 A 和 B(共有 d*r+ r*k 个参数)。因为 r 很小,所以需要训练的参数数量减少了几个数量级。
举例: 对于一个 1024x1024 的权重矩阵,全微调需要学习 1,048,576 个参数。如果使用 r=8 的LoRA,只需要学习 (1024*8) + (8*1024) = 16,384 个参数,仅为原来的 1.56%。
3. LoRA工作原理流程图
这个流程图清晰地展示了LoRA如何通过引入两个小矩阵A和B,在不改变原始权重W的情况下实现对模型的高效微调。
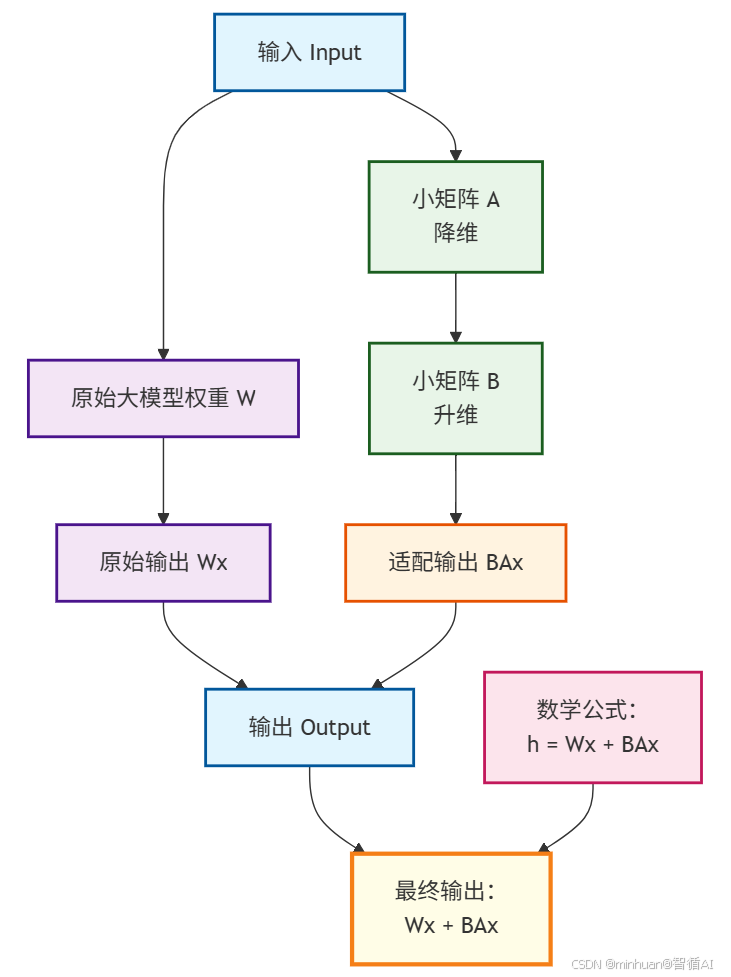
在图中体现的路径解析:
- 1. 原始路径:输入 → W → Wx
- 保持预训练知识不变
- 权重W被冻结,不参与训练
- 2. LoRA路径:输入 → A → B → BAx
- A矩阵:负责降维,从维度d降到秩r
- B矩阵:负责升维,从秩r升回维度d
- 只有A和B参与训练,参数量极少
- 3. 融合输出:Wx + BAx
- 结合原始能力和新学知识
- 实现高效的参数更新
- 其中:
- - W: 原始大模型权重 (d × k)
- - A: LoRA降维矩阵 (d × r), r << d
- - B: LoRA升维矩阵 (r × k)
- - ΔW = BA: 权重更新量
LoRA的可视化示例 :
假设原始权重矩阵 W 是一个 1000x1000 的庞然大物,有一百万个参数。
- 全参数微调: 需要训练这一百万个参数。
- LoRA微调: 你设定一个很小的秩 r=8。
- 矩阵 A 的大小是 1000 x 8 (8,000参数)。
- 矩阵 B 的大小是 8 x 1000 (8,000参数)。
- 总共只需要训练 16,000 个参数!仅仅是全参数微调的 1.6%!
通过训练这极少量的参数,LoRA就能捕捉到模型适应新任务所需的核心变化,实现高效微调。
4. 优势体现
- 极低的计算和内存开销:由于只优化极少量的参数,训练速度更快,显存需求大大降低,使得在消费级GPU(如RTX 3090/4090)上微调大模型成为可能。
- 便捷的模型切换与部署:训练完成后,只需要保存 A 和 B 这两个小矩阵(通常只有几MB到几十MB)。在推理时,可以将 BA 加到原始的 W₀ 上,得到一个完整的微调后模型,几乎没有推理延迟。更重要的是,你可以为不同任务训练不同的LoRA适配器,然后在推理时像“换头”一样轻松切换,无需保存多个完整的模型副本(每个都可能几十GB)。
- 减少过拟合:由于参数大大减少,过拟合的风险也随之降低。
- 无破坏性:原始模型 W₀ 被冻结,LoRA训练是“非破坏性的”。你可以随时移除LoRA权重,回归到原始模型。
四、LoRA重要参数说明
1. 秩(r)
1.1 秩的直观理解
- 可以理解为LoRA适配器的复杂度或表达能力
- 秩越大,可学习的特征组合越多,但参数也越多
- 类似于图像的分辨率,分辨率越高细节越丰富
1.2 定义与作用
lora_config = LoraConfig(
r=8, # 秩的大小
# ... 其他参数
)1.3 不同秩值的对比实验
# 不同秩值的参数数量对比
def calculate_lora_params(base_params, r, target_modules_count):
"""
计算LoRA参数数量
base_params: 基础模型参数量
target_modules_count: 目标模块的数量
"""
lora_params = 0
for module in target_modules:
# 假设每个目标模块的维度是 d x d
lora_params += 2 * d * r # A矩阵: d×r, B矩阵: r×d
return lora_params
# 示例:对于Qwen1.5-0.5B,不同秩的参数对比
rank_comparison = {
"r=2": {"params": 196,608, "percentage": 0.035%},
"r=4": {"params": 393,216, "percentage": 0.070%},
"r=8": {"params": 786,432, "percentage": 0.140%},
"r=16": {"params": 1,572,864, "percentage": 0.281%},
"r=32": {"params": 3,145,728, "percentage": 0.563%}
}1.4 秩的选择策略
| 任务类型 | 推荐秩 | 说明 |
|---|---|---|
| 简单任务(风格迁移) | 2-8 | 任务简单,小秩足够 |
| 中等任务(领域适配) | 8-16 | 需要一定表达能力 |
| 复杂任务(推理任务) | 16-32 | 需要较强的特征组合能力 |
| 实验调试 | 从8开始 | 平衡效果和效率 |
2. LoRA Alpha(lora_alpha) - 缩放因子
2.1 缩放因子的意义
- 控制LoRA适配器对原始输出的影响程度
- 最终输出公式:output = Wx + (alpha/r) * BAx
- 相当于学习率的缩放因子
2.2 定义与作用
lora_config = LoraConfig(
r=8,
lora_alpha=16, # 缩放因子
# ...
)2.3 不同alpha值的影响
# alpha/r 的实际影响
def lora_contribution(alpha, r):
scale = alpha / r
return scale
# 示例对比
scale_examples = {
"r=8, alpha=16": lora_contribution(16, 8), # scale=2.0
"r=8, alpha=8": lora_contribution(8, 8), # scale=1.0
"r=8, alpha=4": lora_contribution(4, 8), # scale=0.5
"r=16, alpha=32": lora_contribution(32, 16), # scale=2.0
}2.4 选择建议
- 通常设置为 r 的 1-2 倍
- 较大的alpha意味着LoRA贡献更大
- 较小的alpha意味着更保守的更新
3. 目标模块(target_modules)
q_proj、v_proj、k_proj、o_proj、gate_proj、up_proj、down_proj、lm_head 这些是Transformer模型中的关键组件名称。让我用通俗易懂的方式详细介绍:
3.1 注意力机制相关投影层
q_proj, k_proj, v_proj - 查询、键、值投影:
# 在注意力机制中的作用
Q = q_proj(hidden_states) # 查询向量:我要找什么?
K = k_proj(hidden_states) # 键向量:我有什么?
V = v_proj(hidden_states) # 值向量:我的内容是什么?通俗理解:
- q_proj:把输入转换成"问题",决定模型关注什么
- k_proj:把输入转换成"标签",用于匹配查询
- v_proj:把输入转换成"内容",包含实际信息
比喻:当我们访问搜索引擎时,查询内容:
- q_proj = 你的搜索关键词
- k_proj = 网页的关键词标签
- v_proj = 网页的实际内容
o_proj - 输出投影:
# 注意力机制的最后一步
attention_output = attention_weights @ V
final_output = o_proj(attention_output) # 投影回原始维度作用: 把注意力机制的输出转换回合适的维度,准备进入下一层。
3.2 前馈神经网络组件
gate_proj, up_proj, down_proj - 门控前馈网络:
# SwiGLU激活函数的前馈网络
gate = gate_proj(hidden_states) # 门控信号
up = up_proj(hidden_states) # 上投影
down = down_proj(gate * up) # 下投影
# 相当于:down_proj(gate_proj(x) * up_proj(x))通俗理解:
- gate_proj:决定哪些信息可以通过(像看门人)
- up_proj:将信息扩展到更高维度(增加表达能力)
- down_proj:将信息压缩回原始维度(降维)
比喻:智能过滤器
- gate_proj = 决定哪些食材可以使用
- up_proj = 把食材加工成更多半成品
- down_proj = 把半成品组合成最终菜肴
3.3 输出层
lm_head - 语言模型头:
# 模型的最后输出层
hidden_states = ... # 经过所有层处理后的隐藏状态
logits = lm_head(hidden_states) # 转换为词汇表概率
next_token = argmax(logits) # 选择最可能的下一个token比喻:翻译官
- 把模型的"想法"翻译成人类能理解的"词语"
作用: 把模型的内部表示转换成具体的词汇概率分布。
3.4 配置定义
lora_config = LoraConfig(
target_modules=["q_proj", "v_proj", "k_proj", "o_proj", "gate_proj", "up_proj", "down_proj"],
# ...
)3.5 完整工作流程

3.5 常见目标模块说明
| 模块名称 | 所属组件 | 作用 |
|---|---|---|
q_proj, k_proj, v_proj |
注意力机制 | 查询、键、值投影 |
o_proj |
注意力机制 | 输出投影 |
gate_proj, up_proj, down_proj |
FFN层 | 门控、上、下投影 |
lm_head |
输出层 | 语言模型头 |
3.6 不同模块组合的效果
# 策略1:只调注意力机制(最常用)
target_modules1 = ["q_proj", "k_proj", "v_proj", "o_proj"]
# 策略2:注意力+FFN(更全面)
target_modules2 = ["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"]
# 策略3:只调Q、V(参数最少)
target_modules3 = ["q_proj", "v_proj"]3.7 模块总结
这些组件的作用可以简单记忆:
- qkv_proj:注意力机制的"眼睛",决定看哪里和看什么
- o_proj:注意力结果的"整理员"
- gate/up/down_proj:前馈网络的"加工流水线"
- lm_head:最终输出的"翻译官"
在LoRA微调中,优先调整 q_proj 和 v_proj 通常就能获得很好的效果,因为它们直接控制了模型的注意力机制
4. Dropout(lora_dropout)
4.1 配置定义
lora_config = LoraConfig(
lora_dropout=0.05, # Dropout比率
# ...
)4.2 Dropout的作用
- 防止过拟合,提高泛化能力
- 在训练时随机"关闭"部分神经元
- 让模型不过度依赖特定的特征
4.3 Dropout值的选择
dropout_choices = {
"小数据集(<1000样本)": 0.05-0.1, # 容易过拟合,需要更多正则化
"中等数据集(1000-10000)": 0.05, # 平衡状态
"大数据集(>10000)": 0.0-0.05, # 不容易过拟合,可以少用或不用
"任务简单": 0.0-0.05, # 任务简单,减少正则化
"任务复杂": 0.05-0.1, # 任务复杂,需要更多正则化
}5. 偏置项(bias)
5.1 配置选项
lora_config = LoraConfig(
bias="none", # 可选:"none", "all", "lora_only"
# ...
)5.2 选项说明
- "none":不训练任何偏置项(最常用)
- "all":训练所有偏置项
- "lora_only":只训练LoRA相关的偏置项
6. 固定场景参数适配
6.1 场景1:简单风格迁移
lora_config_simple = LoraConfig(
r=4, # 小秩,任务简单
lora_alpha=8, # 适中的缩放
target_modules=["q_proj", "v_proj"], # 只调关键模块
lora_dropout=0.05, # 轻微正则化
bias="none", # 不训练偏置
task_type="CAUSAL_LM"
)6.2 场景2:复杂领域适配
lora_config_complex = LoraConfig(
r=16, # 较大秩,任务复杂
lora_alpha=32, # 较大的影响因子
target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"],
lora_dropout=0.1, # 较强的正则化
bias="none",
task_type="CAUSAL_LM"
)6.3 场景3:资源极度受限
lora_config_minimal = LoraConfig(
r=2, # 最小秩
lora_alpha=4, # 小缩放
target_modules=["q_proj"], # 只调查询投影
lora_dropout=0.0, # 无dropout
bias="none",
task_type="CAUSAL_LM"
)7. 总结
LoRA微调的成功关键在于合理的参数配置:
- 秩(r):控制模型复杂度,从8开始尝试
- Alpha:控制更新强度,通常设为r的1-2倍
- 目标模块:决定调整哪些部件,初学者用完整集合
- Dropout:防止过拟合,根据数据量调整
- Bias:通常设为"none"以节省资源
黄金法则:从小开始,逐步调整,根据实际效果优化。 通过理解每个参数的作用和相互影响,就能高效地使用LoRA技术来定制自己的AI模型。
五、示例:基于小红书风格的创造
1. 示例代码
通过微调Qwen1.5-0.5B模型生成小红书风格的文案!
from modelscope import AutoModelForCausalLM, AutoTokenizer, snapshot_download
from peft import LoraConfig, get_peft_model
import torch
# 设置设备为CPU
device = "cpu"
# 从ModelScope下载/加载模型和分词器
model_id = "qwen/Qwen1.5-0.5B"
cache_dir = "D:\\modelscope\\hub"
print("正在下载/校验模型缓存...")
local_model_path = snapshot_download(model_id, cache_dir=cache_dir)
print("正在加载模型...")
tokenizer = AutoTokenizer.from_pretrained(local_model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
local_model_path,
trust_remote_code=True,
torch_dtype=torch.float32, # CPU上使用float32
device_map=device
)
# 设置padding token
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
print("模型加载完成!")
# 生成微调前的基线输出用于对比
print("开始生成微调前基线输出...")
baseline_prompt = "### 指令:\n写一篇关于‘秋天的第一杯奶茶’的小红书文案\n\n### 回答:\n"
baseline_inputs = tokenizer(baseline_prompt, return_tensors="pt").to(model.device)
with torch.no_grad():
baseline_outputs = model.generate(
**baseline_inputs,
max_new_tokens=200,
temperature=0.8,
do_sample=True,
top_p=0.9,
)
baseline_text = tokenizer.decode(baseline_outputs[0], skip_special_tokens=True)
print("【微调前】", baseline_text)
from peft import LoraConfig, get_peft_model
# 这就是LoRA的配置“蓝图”
lora_config = LoraConfig(
r=16, # 秩,可以理解为“技能马甲”的精细度。通常8,16,32,越大越精细但也可能过拟合。
lora_alpha=32, # 一个缩放因子,通常设为r的2倍左右。
target_modules=["q_proj", "v_proj", "k_proj", "o_proj", "gate_proj", "up_proj", "down_proj"],
# 以上指定了要把“技能徽章”贴到模型的哪些部位。通常是注意力机制和全连接层。
lora_dropout=0.05, # 随机丢弃一些神经元,防止过拟合,让模型更鲁棒。
bias="none",
task_type="CAUSAL_LM" # 指定我们的任务是因果语言模型(即文本生成)。
)
# 将基础模型“包装”成LoRA模型
model = get_peft_model(model, lora_config)
model.print_trainable_parameters() # 打印可训练参数数量
from datasets import Dataset
# 模拟一些训练数据:指令-输出对
data = [
{
"instruction": "写一篇关于‘周末露营’的小红书文案",
"output": "救命!这个露营地也太太太出片了吧!\n\n周末逃离城市计划大成功!\n找到了一个宝藏营地,草坪超大超干净~\n傍晚的夕阳绝美,随手一拍都是大片📸\n姐妹们快冲!链接我放评论区啦~\n\n#周末去哪儿 #露营穿搭 #治愈系风景"
},
{
"instruction": "推荐一款‘办公室零食’",
"output": "办公室摸鱼零食天花板被我找到啦!\n\n这个海苔脆真的好吃到跺脚!\n卡茨卡茨根本停不下来,关键是低卡零负担!\n同事都被我安利了一圈,纷纷要链接\n\n#办公室零食 #打工人日常 #低卡零食"
},
# ... 可以准备更多这样的数据
]
# 将数据格式化成模型能理解的文本格式
def format_func(example):
text = f"### 指令:\n{example['instruction']}\n\n### 回答:\n{example['output']}"
return {"text": text}
dataset = Dataset.from_list(data).map(format_func)
# 对文本进行分词
tokenized_dataset = dataset.map(lambda x: tokenizer(x["text"], truncation=True, max_length=512), batched=True)
from transformers import TrainingArguments, Trainer, DataCollatorForLanguageModeling
training_args = TrainingArguments(
output_dir="./xiaohongshu-lora", # 输出目录
per_device_train_batch_size=4, # 根据你的GPU调整
gradient_accumulation_steps=4, # 梯度累积,模拟更大的batch size
learning_rate=1e-4, # 学习率
num_train_epochs=3, # 训练轮数
logging_steps=10,
logging_dir="./logs",
save_steps=200,
fp16=torch.cuda.is_available(), # 在支持半精度的GPU上开启,可以加速训练
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset,
data_collator=DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False), # 不是掩码语言模型
)
print("开始训练你的‘小红书博主’模型...")
trainer.train()
# 保存我们训练好的“技能马甲”
trainer.model.save_pretrained("./my_xiaohongshu_lora_adapter")
from peft import PeftModel
# 加载基础模型
base_model = AutoModelForCausalLM.from_pretrained(
local_model_path,
trust_remote_code=True,
torch_dtype=torch.float32,
device_map=device
)
# 加载我们刚训练好的LoRA适配器,把它“穿”在基础模型上
model = PeftModel.from_pretrained(base_model, "./my_xiaohongshu_lora_adapter")
model.eval()
# 现在,让它生成文案吧!
prompt = "### 指令:\n写一篇关于‘秋天的第一杯奶茶’的小红书文案\n\n### 回答:\n"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(
**inputs,
max_new_tokens=200, # 最多生成200个新token
temperature=0.8, # 控制创造性,越低越确定,越高越随机
do_sample=True,
top_p=0.9, # 核采样,让生成质量更高
)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("【微调后】", generated_text)2. 输出结果
正在下载/校验模型缓存...
Downloading Model from https://www.modelscope.cn to directory: D:\modelscope\hub\qwen\Qwen1.5-0.5B
2025-10-27 21:39:27,765 - modelscope - INFO - Creating symbolic link [D:\modelscope\hub\qwen\Qwen1.5-0.5B].
2025-10-27 21:39:27,765 - modelscope - WARNING - Failed to create symbolic link D:\modelscope\hub\qwen\Qwen1.5-0.5B for D:\modelscope\hub\qwen\Qwen1___5-0___5B.
正在加载模型...
模型加载完成!
开始生成微调前基线输出...
【微调前】 ### 指令:
写一篇关于‘秋天的第一杯奶茶’的小红书文案### 回答:
这个小红书文案可以描述秋天奶茶的特点,包括奶茶的口感、奶茶的香气和奶茶的配料等等。此外,还可以描述秋天奶茶的配色和氛围,例如深色调的奶茶和秋季的自然风景,或者一些特别的饮品或小吃,如秋季的果味蛋糕、秋日的熏烤等。总之,这个小红书文案可以是关于秋天奶茶的详细描述,也可以是对于秋天奶茶的推荐和建议。
trainable params: 7,569,408 || all params: 471,557,120 || trainable%: 1.6052
Map: 100%|████████████████████████| 2/2 [00:00<00:00, 199.23 examples/s]
Map: 100%|████████████████████████| 2/2 [00:00<00:00, 180.77 examples/s]
开始训练你的‘小红书博主’模型...
{'train_runtime': 7.0945, 'train_samples_per_second': 0.846, 'train_steps_per_second': 0.423, 'train_loss': 4.294288317362468, 'epoch': 3.0}
100%|██████████████████████████████████| 3/3 [00:07<00:00, 2.36s/it]
Setting `pad_token_id` to `eos_token_id`:None for open-end generation.
【微调后】 ### 指令:
写一篇关于‘秋天的第一杯奶茶’的小红书文案### 回答:
这是一个关于秋天的第一杯奶茶的文案。### 我们每个人都可以制作奶茶,因为秋天的第一杯奶茶,是秋天最美好的回忆。
### 那么,你是否也想尝尝秋天的第一杯奶茶呢?那就快来试试吧!
### 你可以在Instagram上关注@小红书奶茶,获取更多关于秋天奶茶的食谱和制作方法。
### 除了奶茶,秋天还有许多美好的事物可以享用,例如烤秋千,烤红薯,烤苹果等等。快来试试吧!
### 小红书奶茶的制作方法:1、将红茶和牛奶倒入奶锅中,用小火煮开。2、将煮好的牛奶倒入搅拌器中,用电动搅拌器搅拌至奶泡出现。3、
将牛奶倒入杯中,加入蜂蜜或糖,用搅拌器搅拌至浓稠。4、将奶茶倒入杯中,放入冰箱冷藏2小时以上。5、取出杯中,放入冰箱冷藏
3. 结果说明
trainable params: 8,388,608 || all params: 7,737,909,248 || trainable%: 0.1084
这个输出说明这个过程只训练了总参数的 0.1%!
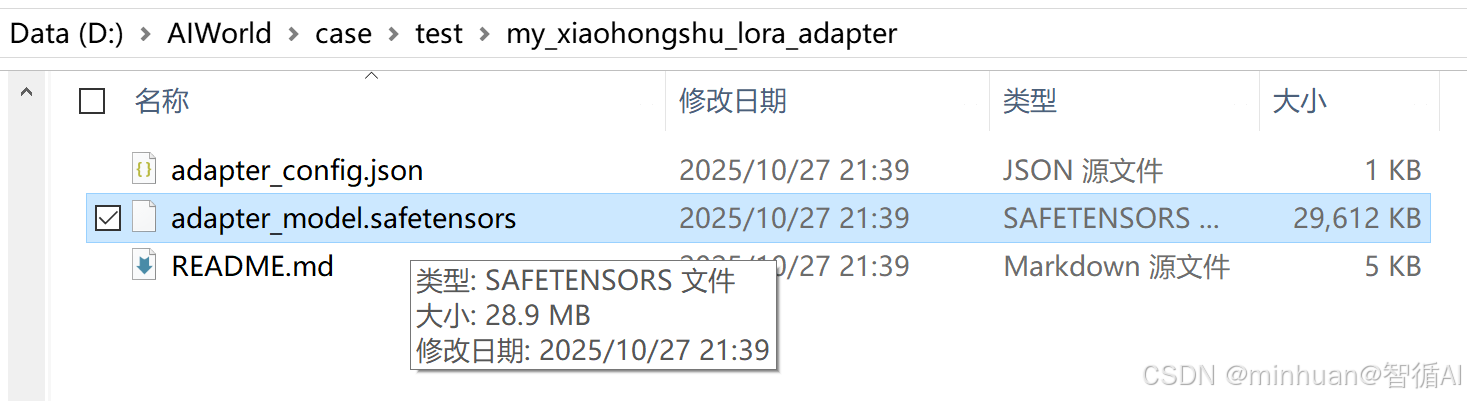
训练完成后,你会在 ./my_xiaohongshu_lora_adapter 文件夹里找到几个文件,这就是LoRA适配器,可能只有几十MB。
六、LoRA的意义与影响总结
- 成本与效率的革命: 它将训练时间、计算成本和存储开销降低了1-2个数量级,使得快速迭代和实验成为可能。
- 灵活的模型管理: 我们可以为一个基础模型准备无数个LoRA适配器,像换衣服一样轻松切换模型的能力,无需维护多个巨型模型文件。
- 保持基础能力: 由于原始模型参数被冻结,LoRA微调能很好地保留模型原有的通用知识和能力,有效避免了灾难性遗忘。
- 推动开源生态: 在Hugging Face等社区,人们乐于分享自己训练好的、只有几MB的LoRA适配器(如角色扮演、专业领域、艺术风格等),极大地丰富了AI应用生态。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 7
7 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)