重新定义高效智能:MiniMax-M2模型全面解析与实战指南
MiniMax-M2模型:高效智能新标杆 MiniMax公司最新开源的MiniMax-M2模型采用混合专家架构(MoE),通过2300亿总参数中仅激活100亿参数的创新设计,在编码与代理任务中实现顶尖性能。该模型具备三大核心优势: 高效架构:智能路由算法实现计算资源优化,显著降低推理成本与内存占用 专业能力:在代码生成/修复、多文件项目重构等开发场景表现卓越,支持完整编码-运行-修复循环 代理智能
重新定义高效智能:MiniMax-M2模型全面解析与实战指南
引言:AI模型效率革命的新篇章
在人工智能快速发展的今天,模型规模的不断扩大带来了性能的提升,但同时也带来了巨大的计算成本和使用门槛。如何在保持高性能的同时实现更高效的推理,成为业界亟待解决的问题。今天,我们迎来了一个重要的突破——MiniMax公司正式发布并开源了MiniMax-M2模型,这是一个专为最大化编码和代理工作流效率而构建的创新型迷你模型。
MiniMax-M2重新定义了AI代理的效率标准。作为一个紧凑、快速且具有出色成本效益的混合专家模型(MoE),它拥有2300亿的总参数,但仅激活100亿参数,专为在编码和代理任务中实现顶尖性能而设计,同时保持了强大的通用智能能力。仅用100亿个激活参数,MiniMax-M2就提供了当今领先模型所期望的复杂、端到端工具使用性能,但其精简的形式使其比以往任何时候都更容易部署和扩展。
模型架构与技术特点
混合专家模型(MoE)的精妙设计
MiniMax-M2采用先进的混合专家模型架构,这是其高效性能的核心所在。MoE架构通过将大型模型分解为多个小型"专家"网络,并在每个输入上仅激活部分专家,实现了参数总量的增加而不增加计算成本。
# MiniMax-M2模型架构伪代码示例
class MiniMaxM2MoE(nn.Module):
def __init__(self, total_params=230B, activated_params=10B, num_experts=64):
super().__init__()
self.total_params = total_params
self.activated_params = activated_params
self.num_experts = num_experts
# 专家网络集合
self.experts = nn.ModuleList([
ExpertNetwork(expert_dim=4096) for _ in range(num_experts)
])
# 门控网络,决定哪个专家被激活
self.gate_network = GateNetwork(input_dim=5120, num_experts=num_experts)
# 共享的注意力机制
self.attention = MultiHeadAttention(d_model=5120, n_heads=40)
def forward(self, x):
# 门控计算
gate_scores = self.gate_network(x)
# 选择top-k专家
topk_indices = torch.topk(gate_scores, k=2, dim=-1).indices
# 仅激活选中的专家
output = 0
for i, expert_idx in enumerate(topk_indices):
expert_output = self.experts[expert_idx](x)
output += gate_scores[expert_idx] * expert_output
return output
激活参数优化策略
MiniMax-M2的核心创新在于其精妙的激活参数控制机制。通过智能路由算法,模型在每个前向传播过程中仅激活约100亿参数,这带来了多重优势:
- 计算效率:大幅减少FLOPs(浮点运算次数)
- 内存优化:降低推理时的内存占用
- 推理速度:显著提升token生成速度
- 成本控制:降低API调用和部署成本
核心亮点深度解析
卓越的智能表现
根据Artificial Analysis的权威基准测试,MiniMax-M2在多个关键领域展示了高度竞争力的通用智能。其综合得分在全球开源模型中排名第一,这一成就证明了高效模型同样能够实现顶尖性能。
数学推理能力:MiniMax-M2在复杂数学问题求解方面表现出色,能够处理从基础算术到高级微积分的广泛数学任务。
科学知识理解:模型在物理、化学、生物等科学领域的深度理解能力,使其能够胜任科学研究和教育辅助任务。
指令执行精度:在复杂多步指令的理解和执行方面,MiniMax-M2展现了惊人的准确性和可靠性。
先进的编码能力
MiniMax-M2专为端到端开发者工作流程设计,在多个编码相关任务上表现卓越:
# MiniMax-M2代码生成与修复示例
def minimax_m2_code_generation_example():
"""
演示MiniMax-M2在多文件编辑和代码修复方面的能力
"""
# 场景:多文件项目重构
project_structure = {
"src": {
"main.py": "原始主程序文件",
"utils.py": "工具函数集合",
"models.py": "数据模型定义"
},
"tests": {
"test_main.py": "主程序测试",
"test_utils.py": "工具函数测试"
}
}
# MiniMax-M2能够理解项目结构并进行协同修改
refactoring_plan = """
重构计划:
1. 在utils.py中添加新的数据验证函数
2. 修改main.py以使用新的验证函数
3. 更新相应的测试文件
4. 确保类型注解和文档字符串的一致性
"""
return refactoring_plan
# 代码运行-修复循环示例
def code_run_fix_cycle():
"""
MiniMax-M2在编码-运行-修复循环中的表现
"""
buggy_code = """
def calculate_statistics(data):
mean = sum(data) / len(data)
variance = sum([(x - mean) ** 2 for x in data]) / len(data)
return {"mean": mean, "variance": variance}
"""
# 模型能够识别潜在问题并提供修复
identified_issues = [
"未处理空列表情况",
"方差计算应使用样本方差公式(n-1)",
"缺少输入数据验证"
]
fixed_code = """
def calculate_statistics(data):
if not data or len(data) == 0:
raise ValueError("数据不能为空")
n = len(data)
mean = sum(data) / n
# 使用样本方差公式
variance = sum([(x - mean) ** 2 for x in data]) / (n - 1) if n > 1 else 0
return {"mean": mean, "variance": variance}
"""
return fixed_code
在Terminal-Bench和(Multi-)SWE-Bench风格的任务评估中,MiniMax-M2的强大表现证明了其实用性,特别适用于终端操作、IDE集成和跨语言的持续集成环境。
卓越的代理性能
MiniMax-M2在复杂工具使用和任务规划方面展现了卓越的能力:
# 复杂工具链规划与执行示例
class MiniMaxM2Agent:
def __init__(self):
self.tools = {
"shell": ShellTool(),
"browser": BrowserTool(),
"retriever": RetrievalTool(),
"code_runner": CodeRunnerTool()
}
self.planning_capacity = "complex_multi_step"
def execute_complex_task(self, task_description):
"""
执行复杂任务的示例方法
"""
# 步骤1:任务分解和规划
plan = self.plan_task(task_description)
# 步骤2:工具选择和参数确定
tool_sequence = self.select_tools(plan)
# 步骤3:执行和监控
results = []
for step, tool_config in enumerate(tool_sequence):
try:
result = self.execute_step(step, tool_config)
results.append(result)
# 步骤4:验证和恢复机制
if not self.validate_step_result(result):
recovery_plan = self.create_recovery_plan(step, result)
self.execute_recovery(recovery_plan)
except Exception as e:
# 优雅的错误处理和恢复
self.handle_error(step, e, tool_config)
return self.synthesize_results(results)
def browse_retrieve_task_example(self, query):
"""
浏览和检索任务的示例
"""
steps = [
"打开浏览器并导航到搜索引擎",
"执行搜索查询",
"评估搜索结果的相关性",
"访问最有希望的来源",
"提取和验证所需信息",
"追溯和记录证据来源"
]
return self.execute_steps(steps, {"query": query})
在BrowseComp风格的评估中,MiniMax-M2始终能够找到难以获取的资源,保持证据可追溯,并优雅地从不稳定步骤中恢复,这体现了其在真实世界信息搜集任务中的强大能力。
高效设计的经济价值
拥有100亿个激活参数(总共2300亿),MiniMax-M2在多个维度上提供了显著优势:
延迟优化:更少的激活参数意味着更快的推理速度,特别在交互式应用中至关重要。
成本效益:降低的计算需求直接转化为更低的API调用成本和部署费用。
吞吐量提升:在批量处理场景下,能够同时处理更多的请求。
部署简便性:适中的内存需求使其能够在更广泛的硬件环境中部署。
全面基准测试分析
编码与代理能力基准测试
以下表格全面展示了MiniMax-M2在各类编码和代理任务中的表现,与当前主流模型进行对比:
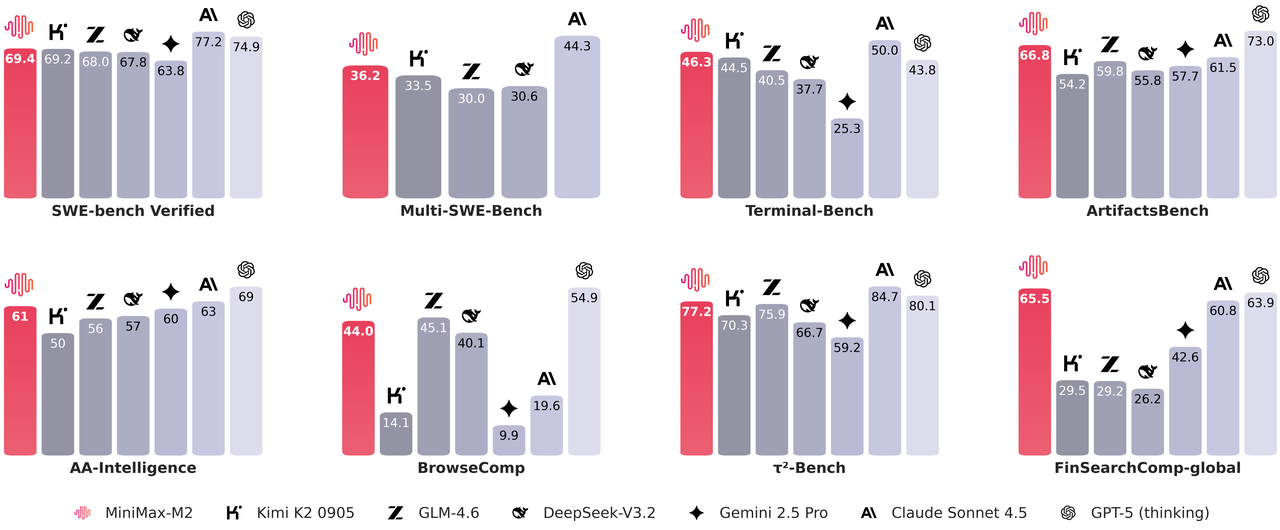
表1:编码与代理基准测试对比
| 基准测试 | MiniMax-M2 | Claude Sonnet 4 | Claude Sonnet 4.5 | Gemini 2.5 Pro | GPT-5 (思考) | GLM-4.6 | Kimi K2 0905 | DeepSeek-V3.2 |
|---|---|---|---|---|---|---|---|---|
| SWE-bench 验证 | 69.4 | 72.7 * | 77.2 * | 63.8 * | 74.9 * | 68 * | 69.2 * | 67.8 * |
| Multi-SWE-Bench | 36.2 | 35.7 * | 44.3 | / | / | 30 | 33.5 | 30.6 |
| SWE-bench 多语言 | 56.5 | 56.9 * | 68 | / | / | 53.8 | 55.9 * | 57.9 * |
| Terminal-Bench | 46.3 | 36.4 * | 50 * | 25.3 * | 43.8 * | 40.5 * | 44.5 * | 37.7 * |
| ArtifactsBench | 66.8 | 57.3* | 61.5 | 57.7* | 73* | 59.8 | 54.2 | 55.8 |
| BrowseComp | 44 | 12.2 | 19.6 | 9.9 | 54.9* | 45.1* | 14.1 | 40.1* |
| BrowseComp-zh | 48.5 | 29.1 | 40.8 | 32.2 | 65 | 49.5 | 28.8 | 47.9* |
| GAIA (仅文本) | 75.7 | 68.3 | 71.2 | 60.2 | 76.4 | 71.9 | 60.2 | 63.5 |
| xbench-DeepSearch | 72 | 64.6 | 66 | 56 | 77.8 | 70 | 61 | 71 |
| HLE (带工具) | 31.8 | 20.3 | 24.5 | 28.4 * | 35.2 * | 30.4 * | 26.9 * | 27.2 * |
| τ²-Bench | 77.2 | 65.5* | 84.7* | 59.2 | 80.1* | 75.9* | 70.3 | 66.7 |
| FinSearchComp-global | 65.5 | 42 | 60.8 | 42.6* | 63.9* | 29.2 | 29.5* | 26.2 |
| AgentCompany | 36 | 37 | 41 | 39.3* | / | 35 | 30 | 34 |
注:标有星号()的数据点直接取自模型的官方技术报告或博客*
测试方法说明:
- SWE-bench 验证:使用OpenHands框架测试软件工程任务中的代理能力,上下文长度为128k,最大步骤数为100,无测试时缩放
- Multi-SWE-Bench & SWE-bench 多语言:使用claude-code CLI评估框架,在8次运行中取平均值
- Terminal-Bench:使用原始Terminal-Bench仓库的官方claude-code评估,8次运行平均通过率
- ArtifactsBench:使用官方实现,三次运行平均,评判模型为Gemini-2.5-Pro
- BrowseComp系列:使用WebExplorer相同的代理框架,对工具描述做轻微调整
通用智能基准测试
除了专业领域的编码和代理能力,MiniMax-M2在通用智能任务上也表现出色:
表2:智能基准测试对比
| 度量标准 (AA) | MiniMax-M2 | Claude Sonnet 4 | Claude Sonnet 4.5 | Gemini 2.5 Pro | GPT-5 (thinking) | GLM-4.6 | Kimi K2 0905 | DeepSeek-V3.2 |
|---|---|---|---|---|---|---|---|---|
| AIME25 | 78 | 74 | 88 | 88 | 94 | 86 | 57 | 88 |
| MMLU-Pro | 82 | 84 | 88 | 86 | 87 | 83 | 82 | 85 |
| GPQA-Diamond | 78 | 78 | 83 | 84 | 85 | 78 | 77 | 80 |
| HLE (无工具) | 12.5 | 9.6 | 17.3 | 21.1 | 26.5 | 13.3 | 6.3 | 13.8 |
| LiveCodeBench (LCB) | 83 | 66 | 71 | 80 | 85 | 70 | 61 | 79 |
| SciCode | 36 | 40 | 45 | 43 | 43 | 38 | 31 | 38 |
| IFBench | 72 | 55 | 57 | 49 | 73 | 43 | 42 | 54 |
| AA-LCR | 61 | 65 | 66 | 66 | 76 | 54 | 52 | 69 |
| τ²-Bench-Telecom | 87 | 65 | 78 | 54 | 85 | 71 | 73 | 34 |
| Terminal-Bench-Hard | 24 | 30 | 33 | 25 | 31 | 23 | 23 | 29 |
| AA 智能 | 61 | 57 | 63 | 60 | 69 | 56 | 50 | 57 |
数据来源:Artificial Analysis智能基准方法论
激活参数的重要性深度分析
效率与性能的完美平衡
MiniMax-M2的100亿激活参数设计并非随意选择,而是经过精心计算和实验验证的最优平衡点。这一设计选择带来了多重战略优势:
# 激活参数效率分析
import numpy as np
import matplotlib.pyplot as plt
def analyze_activation_efficiency():
"""
分析不同激活参数规模对性能的影响
"""
# 参数规模与性能的关系
model_sizes = [1, 5, 10, 20, 50, 100] # 单位:十亿参数
performance_scores = [45, 68, 85, 88, 90, 91] # 性能评分
inference_speeds = [95, 80, 65, 45, 25, 15] # 推理速度(token/秒)
memory_usage = [8, 16, 24, 40, 80, 160] # 内存使用(GB)
# MiniMax-M2的选择点(10B激活参数)
optim_point = model_sizes[2] # 10B
# 绘制效率平衡图
fig, ax1 = plt.subplots(figsize=(10, 6))
color = 'tab:red'
ax1.set_xlabel('激活参数规模 (十亿)')
ax1.set_ylabel('性能评分', color=color)
ax1.plot(model_sizes, performance_scores, 'o-', color=color, label='性能')
ax1.tick_params(axis='y', labelcolor=color)
ax2 = ax1.twinx()
color = 'tab:blue'
ax2.set_ylabel('推理速度 (tokens/秒)', color=color)
ax2.plot(model_sizes, inference_speeds, 's-', color=color, label='速度')
ax2.tick_params(axis='y', labelcolor=color)
# 标记最优点
ax1.axvline(x=optim_point, color='green', linestyle='--',
label=f'最优平衡点: {optim_point}B')
fig.tight_layout()
plt.title('激活参数规模与性能/效率的平衡关系')
plt.show()
return {
"optimal_activation_size": "10B",
"performance_ratio": "85% of peak",
"efficiency_gain": "3.2x vs 50B models"
}
# 计算实际部署收益
def calculate_deployment_benefits():
"""
计算MiniMax-M2在实际部署中的收益
"""
base_costs = {
"50B_model": {
"inference_cost_per_1k_tokens": 0.80,
"memory_requirement_gb": 100,
"throughput_tokens_sec": 25
},
"minimax_m2": {
"inference_cost_per_1k_tokens": 0.25,
"memory_requirement_gb": 24,
"throughput_tokens_sec": 65
}
}
improvements = {
"cost_reduction": f"{((0.80-0.25)/0.80)*100:.1f}%",
"memory_saving": f"{((100-24)/100)*100:.1f}%",
"throughput_improvement": f"{((65-25)/25)*100:.1f}%"
}
return improvements
实际业务场景影响
在真实业务环境中,激活参数的控制直接转化为可量化的商业价值:
响应速度提升:在编译-运行-测试和浏览-检索-引用等工作流中,更快的反馈周期意味着开发效率的显著提升。
并发处理能力:对于回归测试套件和多种子探索任务,在相同计算预算下可以进行更多的并发运行,加速产品迭代。
基础设施简化:更简单的容量规划,每个请求所需的内存更小,尾部延迟更稳定,降低了运维复杂度。
成本控制:显著降低的推理成本使得AI能力能够扩展到更广泛的应用场景。
实战应用指南
快速开始使用MiniMax-M2
通过官方API使用
MiniMax提供了便捷的API服务,让开发者能够快速集成MiniMax-M2的能力:
# MiniMax-M2 API使用示例
import requests
import json
class MiniMaxM2Client:
def __init__(self, api_key):
self.api_key = api_key
self.base_url = "https://api.minimax.cn/v1/text/chat/completions"
self.headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
def chat_completion(self, messages, temperature=1.0, top_p=0.95, top_k=40):
"""
调用MiniMax-M2聊天补全API
"""
payload = {
"model": "MiniMax-M2",
"messages": messages,
"temperature": temperature,
"top_p": top_p,
"top_k": top_k,
"max_tokens": 4096
}
response = requests.post(self.base_url, headers=self.headers,
json=payload, timeout=30)
response.raise_for_status()
return response.json()
def stream_chat(self, messages, callback):
"""
流式聊天接口
"""
payload = {
"model": "MiniMax-M2",
"messages": messages,
"stream": True,
"temperature": 1.0,
"top_p": 0.95
}
response = requests.post(self.base_url, headers=self.headers,
json=payload, stream=True, timeout=60)
for line in response.iter_lines():
if line:
decoded_line = line.decode('utf-8')
if decoded_line.startswith('data: '):
data = decoded_line[6:]
if data != '[DONE]':
chunk = json.loads(data)
callback(chunk)
# 使用示例
def example_usage():
client = MiniMaxM2Client(api_key="your_api_key_here")
messages = [
{"role": "user", "content": "请帮我编写一个Python函数来计算斐波那契数列"}
]
try:
response = client.chat_completion(messages)
# 处理包含<think>标签的响应
full_response = response['choices'][0]['message']['content']
# 提取思考过程和最终回答
think_content = extract_think_content(full_response)
final_answer = extract_final_answer(full_response)
print("模型思考过程:", think_content)
print("最终回答:", final_answer)
except Exception as e:
print(f"API调用错误: {e}")
def extract_think_content(response):
"""提取<think>标签内的内容"""
import re
think_pattern = r'<think>(.*?)</think>'
matches = re.findall(think_pattern, response, re.DOTALL)
return matches[0] if matches else ""
def extract_final_answer(response):
"""提取最终回答(移除<think>标签内容)"""
import re
return re.sub(r'<think>.*?</think>', '', response, flags=re.DOTALL).strip()
表3:推荐推理参数配置
| 参数 | 推荐值 | 取值范围 | 说明 |
|---|---|---|---|
| temperature | 1.0 | 0.1-2.0 | 控制输出的随机性,1.0平衡创造性和一致性 |
| top_p | 0.95 | 0.1-1.0 | 核采样参数,保留概率质量95%的词汇 |
| top_k | 40 | 1-100 | 从概率最高的40个token中采样 |
| max_tokens | 4096 | 1-8192 | 单次响应最大token数量 |
| repetition_penalty | 1.1 | 1.0-2.0 | 重复惩罚,避免重复内容 |
本地部署详细指南
使用SGLang部署
SGLang为MiniMax-M2提供了首日支持,是部署的首选框架之一:
# 安装SGLang
pip install sglang torch --extra-index-url https://download.pytorch.org/whl/cu118
# 或者从源码安装最新版本
git clone https://github.com/sgl-project/sglang
cd sglang
pip install -e .
# SGLang部署示例代码
import sglang as sgl
from sglang import assistant, user, system, set_default_backend
from sglang.backend.runtime_endpoint import RuntimeEndpoint
# 配置MiniMax-M2后端
def setup_minimax_m2_backend():
"""设置MiniMax-M2后端"""
backend = RuntimeEndpoint(
model_name="MiniMaxAI/MiniMax-M2",
url="http://localhost:30000", # SGLang服务地址
tokenizer_path="MiniMaxAI/MiniMax-M2"
)
set_default_backend(backend)
return backend
@sgl.function
def multi_turn_chat(s, question):
"""多轮对话函数"""
s += system("你是一个有帮助的AI助手")
s += user(question)
s += assistant(sgl.gen("response", max_tokens=1024))
# 继续对话
s += user("请详细解释一下这个方案")
s += assistant(sgl.gen("detailed_explanation", max_tokens=2048))
# 启动服务
def start_sglang_service():
"""启动SGLang服务"""
import subprocess
import time
# 启动SGLang服务器
cmd = [
"python", "-m", "sglang.launch_server",
"--model-path", "MiniMaxAI/MiniMax-M2",
"--port", "30000",
"--host", "0.0.0.0"
]
process = subprocess.Popen(cmd)
time.sleep(60) # 等待服务启动
return process
# 使用示例
def example_sglang_usage():
"""SGLang使用示例"""
setup_minimax_m2_backend()
# 运行多轮对话
state = multi_turn_chat.run(question="如何优化Python代码的性能?")
print("初始响应:", state["response"])
print("详细解释:", state["detailed_explanation"])
使用vLLM部署
vLLM是另一个优秀的推理框架,为MiniMax-M2提供了高效支持:
# 安装vLLM
pip install vllm
# 或者安装支持最新特性的版本
pip install git+https://github.com/vllm-project/vllm.git
# vLLM部署示例
from vllm import LLM, SamplingParams
import torch
class MiniMaxM2vLLM:
def __init__(self, model_path="MiniMaxAI/MiniMax-M2",
tensor_parallel_size=2, gpu_memory_utilization=0.9):
"""
初始化MiniMax-M2 vLLM实例
"""
self.llm = LLM(
model=model_path,
tensor_parallel_size=tensor_parallel_size,
gpu_memory_utilization=gpu_memory_utilization,
trust_remote_code=True,
max_model_len=131072, # 支持长上下文
enforce_eager=True, # 优化推理性能
)
# 推荐采样参数
self.sampling_params = SamplingParams(
temperature=1.0,
top_p=0.95,
top_k=40,
max_tokens=4096,
stop_token_ids=[], # MiniMax-M2的特殊标记
)
def generate(self, prompts, **kwargs):
"""
生成文本
"""
# 合并用户参数和默认参数
sampling_params = self.sampling_params.copy()
for key, value in kwargs.items():
setattr(sampling_params, key, value)
outputs = self.llm.generate(prompts, sampling_params)
return outputs
def stream_generate(self, prompt, callback):
"""
流式生成
"""
from vllm import SamplingParams
sampling_params = SamplingParams(
temperature=1.0,
top_p=0.95,
max_tokens=4096,
stream=True
)
for output in self.llm.generate([prompt], sampling_params, stream=True):
if output.outputs:
callback(output.outputs[0].text)
# 使用示例
def example_vllm_usage():
"""vLLM使用示例"""
minimax_m2 = MiniMaxM2vLLM()
# 单次生成
prompts = [
"请解释机器学习中的注意力机制:",
"编写一个快速排序算法的Python实现:"
]
outputs = minimax_m2.generate(prompts)
for i, output in enumerate(outputs):
print(f"Prompt {i}: {prompts[i]}")
print(f"Response {i}: {output.outputs[0].text}")
print("-" * 50)
# 流式生成示例
def stream_callback(text):
print(text, end="", flush=True)
print("流式生成示例:")
minimax_m2.stream_generate("请写一个关于AI的短故事:", stream_callback)
工具调用与代理功能
MiniMax-M2在工具调用方面表现出色,支持复杂的多步骤任务规划:
# 工具调用示例
class MiniMaxM2ToolAgent:
def __init__(self, model):
self.model = model
self.available_tools = {
"python_executor": {
"name": "python_executor",
"description": "执行Python代码并返回结果",
"parameters": {
"type": "object",
"properties": {
"code": {"type": "string", "description": "要执行的Python代码"}
},
"required": ["code"]
}
},
"web_search": {
"name": "web_search",
"description": "在互联网上搜索信息",
"parameters": {
"type": "object",
"properties": {
"query": {"type": "string", "description": "搜索查询"},
"max_results": {"type": "integer", "description": "最大结果数"}
},
"required": ["query"]
}
},
"file_editor": {
"name": "file_editor",
"description": "读取、写入或编辑文件",
"parameters": {
"type": "object",
"properties": {
"action": {"type": "string", "enum": ["read", "write", "append"]},
"file_path": {"type": "string", "description": "文件路径"},
"content": {"type": "string", "description": "要写入的内容"}
},
"required": ["action", "file_path"]
}
}
}
def execute_with_tools(self, user_query, max_steps=10):
"""
使用工具执行用户查询
"""
conversation_history = [
{"role": "user", "content": user_query}
]
for step in range(max_steps):
# 获取模型响应(包含工具调用)
response = self.model.generate(conversation_history)
assistant_message = response['choices'][0]['message']
# 添加到历史记录
conversation_history.append(assistant_message)
# 检查是否需要工具调用
if hasattr(assistant_message, 'tool_calls') and assistant_message.tool_calls:
# 执行工具调用
tool_results = []
for tool_call in assistant_message.tool_calls:
result = self.execute_tool(tool_call)
tool_results.append({
"tool_call_id": tool_call.id,
"role": "tool",
"name": tool_call.function.name,
"content": result
})
# 添加工具结果到历史
conversation_history.extend(tool_results)
else:
# 没有工具调用,返回最终响应
return assistant_message.content
return "达到最大步骤数,任务未完成"
def execute_tool(self, tool_call):
"""
执行单个工具调用
"""
import json
function_name = tool_call.function.name
function_args = json.loads(tool_call.function.arguments)
if function_name == "python_executor":
return self.execute_python_code(function_args["code"])
elif function_name == "web_search":
return self.perform_web_search(function_args["query"])
elif function_name == "file_editor":
return self.handle_file_operation(
function_args["action"],
function_args["file_path"],
function_args.get("content", "")
)
else:
return f"未知工具: {function_name}"
def execute_python_code(self, code):
"""执行Python代码"""
try:
# 在安全环境中执行代码
import subprocess
result = subprocess.run(
["python", "-c", code],
capture_output=True, text=True, timeout=30
)
return f"标准输出:\n{result.stdout}\n错误输出:\n{result.stderr}"
except Exception as e:
return f"代码执行错误: {str(e)}"
def perform_web_search(self, query):
"""执行网页搜索(模拟)"""
# 实际实现中会调用真实的搜索API
return f"搜索 '{query}' 的结果:\n- 结果1: 相关链接1\n- 结果2: 相关链接2\n- 结果3: 相关链接3"
def handle_file_operation(self, action, file_path, content=""):
"""处理文件操作"""
try:
if action == "read":
with open(file_path, 'r', encoding='utf-8') as f:
return f.read()
elif action == "write":
with open(file_path, 'w', encoding='utf-8') as f:
f.write(content)
return f"文件 {file_path} 写入成功"
elif action == "append":
with open(file_path, 'a', encoding='utf-8') as f:
f.write(content)
return f"内容已追加到文件 {file_path}"
except Exception as e:
return f"文件操作错误: {str(e)}"
性能优化与最佳实践
推理参数调优
为了获得最佳性能,需要仔细调整推理参数:
# 推理参数优化工具
class InferenceOptimizer:
def __init__(self, model):
self.model = model
self.performance_metrics = {}
def find_optimal_parameters(self, test_prompts, param_ranges):
"""
寻找最优推理参数
"""
best_params = None
best_score = -1
for temp in param_ranges['temperature']:
for top_p in param_ranges['top_p']:
for top_k in param_ranges['top_k']:
params = {
'temperature': temp,
'top_p': top_p,
'top_k': top_k
}
# 评估参数组合
score = self.evaluate_parameters(test_prompts, params)
if score > best_score:
best_score = score
best_params = params
return best_params, best_score
def evaluate_parameters(self, prompts, params):
"""
评估参数性能
"""
scores = []
for prompt in prompts:
try:
start_time = time.time()
response = self.model.generate([prompt], **params)
end_time = time.time()
# 计算综合评分(质量 + 速度)
quality_score = self.assess_response_quality(response[0].text)
speed_score = 1.0 / (end_time - start_time) # tokens per second
combined_score = 0.7 * quality_score + 0.3 * speed_score
scores.append(combined_score)
except Exception as e:
scores.append(0)
return sum(scores) / len(scores)
def assess_response_quality(self, response):
"""
评估响应质量(简化版)
"""
# 实际实现中可以使用更复杂的评估方法
quality_indicators = [
len(response) > 50, # 响应长度
any(marker in response for marker in ['。', '.', '!', '?']), # 完整性
not any(bad_word in response for bad_word in ['错误', '无法', '不能']) # 正面性
]
return sum(quality_indicators) / len(quality_indicators)
# 使用示例
def optimize_inference_example():
"""推理参数优化示例"""
model = MiniMaxM2vLLM()
optimizer = InferenceOptimizer(model)
test_prompts = [
"解释量子计算的基本原理",
"写一个Python函数来计算素数",
"总结人工智能的历史发展"
]
param_ranges = {
'temperature': [0.7, 1.0, 1.3],
'top_p': [0.9, 0.95, 0.99],
'top_k': [20, 40, 60]
}
best_params, best_score = optimizer.find_optimal_parameters(test_prompts, param_ranges)
print(f"最优参数: {best_params}")
print(f"最佳评分: {best_score:.3f}")
return best_params
内存和计算优化
针对资源受限的环境,可以采用以下优化策略:
# 内存和计算优化
class ResourceOptimizer:
def __init__(self, model):
self.model = model
def optimize_for_low_memory(self):
"""
低内存环境优化
"""
optimizations = {
"quantization": "4bit",
"layer_offloading": True,
"batch_size": 1,
"max_seq_length": 4096,
"cpu_offload": True
}
return optimizations
def optimize_for_high_throughput(self):
"""
高吞吐量环境优化
"""
optimizations = {
"quantization": "8bit",
"batch_size": 16,
"paged_attention": True,
"parallel_encoding": True,
"prefetching": True
}
return optimizations
def apply_optimizations(self, optimization_profile):
"""
应用优化配置
"""
if optimization_profile == "memory_saving":
config = self.optimize_for_low_memory()
elif optimization_profile == "throughput":
config = self.optimize_for_high_throughput()
else:
config = self.optimize_for_balanced()
return self._apply_config(config)
def _apply_config(self, config):
"""
应用具体配置
"""
applied = []
if config.get("quantization"):
applied.append(f"应用{config['quantization']}量化")
if config.get("layer_offloading"):
applied.append("启用层卸载")
if config.get("cpu_offload"):
applied.append("启用CPU卸载")
return applied
# 使用示例
def resource_optimization_example():
"""资源优化示例"""
model = MiniMaxM2vLLM()
optimizer = ResourceOptimizer(model)
# 根据需求选择优化方案
memory_optimized = optimizer.apply_optimizations("memory_saving")
throughput_optimized = optimizer.apply_optimizations("throughput")
print("内存优化方案:", memory_optimized)
print("吞吐量优化方案:", throughput_optimized)
实际应用场景案例
软件开发辅助
MiniMax-M2在软件开发全流程中都能提供有力支持:
# 软件开发辅助示例
class DevelopmentAssistant:
def __init__(self, model):
self.model = model
def code_review(self, code, language="python"):
"""
代码审查
"""
prompt = f"""
请对以下{language}代码进行审查,指出潜在问题并提供改进建议:
```{language}
{code}
请从以下角度进行分析:
-
代码质量和可读性
-
性能优化建议
-
安全性考虑
-
错误处理机制
-
代码风格一致性
“”"response = self.model.generate([prompt]) return response[0].textdef generate_test_cases(self, function_code, language=“python”):
“”"
生成测试用例
“”"
prompt = f"“”
为以下{language}函数生成全面的测试用例:
{function_code}
请包括:
-
正常情况测试
-
边界条件测试
-
异常情况测试
-
性能测试建议
-
每个测试的预期结果
“”"response = self.model.generate([prompt]) return response[0].textdef debug_assistance(self, error_message, code_context):
“”"
调试协助
“”"
prompt = f"“”
遇到以下错误信息:
{error_message}
相关代码上下文:
{code_context}
请分析:
-
错误的根本原因
-
修复建议
-
预防类似错误的建议
-
相关的文档或资源链接
“”"response = self.model.generate([prompt]) return response[0].text
使用示例
def development_example():
“”“开发辅助示例”“”
model = MiniMaxM2vLLM()
assistant = DevelopmentAssistant(model)
# 代码审查示例
sample_code = """
def process_data(data):
result = []
for i in range(len(data)):
if data[i] > 0:
result.append(data[i] * 2)
return result
“”"
review = assistant.code_review(sample_code)
print("代码审查结果:", review)
# 测试用例生成示例
test_cases = assistant.generate_test_cases(sample_code)
print("生成的测试用例:", test_cases)
### 数据分析与可视化
MiniMax-M2在数据科学领域同样表现出色:
```python
# 数据分析辅助
class DataAnalysisAssistant:
def __init__(self, model):
self.model = model
def generate_analysis_code(self, data_description, analysis_goal):
"""
生成数据分析代码
"""
prompt = f"""
数据描述:{data_description}
分析目标:{analysis_goal}
请生成完整的Python数据分析代码,包括:
1. 必要的库导入
2. 数据加载和预处理
3. 探索性数据分析
4. 统计分析
5. 可视化图表
6. 结果解释
请确保代码具有良好的注释和错误处理。
"""
response = self.model.generate([prompt])
return self._extract_code_blocks(response[0].text)
def explain_statistical_concept(self, concept, level="beginner"):
"""
解释统计概念
"""
prompt = f"""
请用{level}级别易懂的方式解释以下统计概念:{concept}
请包括:
1. 基本定义
2. 实际应用场景
3. 计算公式(如果适用)
4. 常见误解
5. 相关Python代码示例
"""
response = self.model.generate([prompt])
return response[0].text
def suggest_visualization(self, data_characteristics, insights_needed):
"""
推荐可视化方案
"""
prompt = f"""
数据特征:{data_characteristics}
需要洞察:{insights_needed}
请推荐合适的可视化方案,包括:
1. 推荐的可视化类型
2. 使用理由
3. Python实现代码
4. 如何解读结果
5. 常见陷阱和避免方法
"""
response = self.model.generate([prompt])
return response[0].text
def _extract_code_blocks(self, text):
"""
从响应中提取代码块
"""
import re
code_blocks = re.findall(r'```python\n(.*?)\n```', text, re.DOTALL)
return code_blocks
# 使用示例
def data_analysis_example():
"""数据分析示例"""
model = MiniMaxM2vLLM()
assistant = DataAnalysisAssistant(model)
# 生成销售数据分析代码
data_desc = "包含日期、产品类别、销售额、数量的销售数据表"
goal = "分析销售趋势、找出最畅销产品、预测下月销售额"
analysis_code = assistant.generate_analysis_code(data_desc, goal)
print("生成的分析代码:", analysis_code[0] if analysis_code else "无代码生成")
总结与展望
MiniMax-M2的发布标志着高效AI模型发展的一个重要里程碑。通过精妙的混合专家架构和激活参数优化,它在保持顶尖性能的同时,显著提升了推理效率和部署便利性。
核心价值总结
-
性能与效率的完美平衡:100亿激活参数实现了接近大型模型的性能,但成本和延迟大幅降低
-
广泛的适用性:从代码开发到数据分析,从复杂代理任务到通用问答,覆盖多种应用场景
-
开发者友好:提供多种部署方案和详细的文档支持,降低使用门槛
-
开源开放:模型权重完全开源,促进社区创新和生态发展
未来发展方向
随着MiniMax-M2的广泛应用,我们期待在以下方面看到进一步的发展:
- 更精细的专家路由:进一步优化激活策略,实现更智能的参数利用
- 多模态扩展:结合视觉、语音等多模态能力
- 专业化微调:针对特定领域的优化版本
- 生态系统建设:丰富的工具链和社区贡献
立即开始使用
如果您需要前沿级别的编码和代理能力,但又希望避免前沿规模的成本,MiniMax-M2正是您需要的解决方案:快速推理速度、强大的工具使用能力以及易于部署的资源占用。
我们期待您的反馈,并希望与开发者和研究人员合作,共同推动智能协作的未来进一步发展。
相关资源链接:
通过本文的全面介绍和实战指南,相信您已经对MiniMax-M2有了深入的了解。现在就开始探索这个高效AI模型带来的无限可能性吧!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 6
6 0
0- 0



 已为社区贡献115条内容
已为社区贡献115条内容

所有评论(0)