数据Agent之——Milvus向量数据库基础介绍

在开发数据 agent 时,我们的目的是希望将文字语言转化为 SQL 语言,这就涉及到文字语言到 SQL 的准确转化。SQL 的语法可以依赖使用 prompt 让 Claude 帮我们来完成,但如何让 Claude 准确识别我们希望使用的是哪张表呢?最简单的方式就是通过完善表名和表字段的描述,让它知道我们说的是哪张表。经过完善的表描述和字段描述,我们可以将这些内容视为这张表的标签,Claude 可以通过这些标签准确命中对应的数据表,提升返回 SQL 的准确性。这些标签通常存储在向量数据库中,本次项目使用的就是 Milvus 向量数据库。
非结构化数据(如文本、图像和音频)格式各异,蕴含丰富的潜在语义,因此分析起来极具挑战性。为了处理这种复杂性,Embeddings 被用来将非结构化数据转换成能够捕捉其基本特征的数字向量。然后将这些向量存储在向量数据库中,从而实现快速、可扩展的搜索和分析。
什么是向量数据库
向量数据库是一种专门为 AI 和语义搜索设计的数据库,它与传统数据库最大的不同是:
- 传统数据库存的是结构化数据(数字、字符串等),用于做「精确匹配」(比如:id=123)。
- 向量数据库存的是高维向量(一长串浮点数),用于做「相似匹配」(比如:找“语义最相近”的内容)。
你可能有一个疑问:对于文本搜索,我们不是可以通过 Elasticsearch 来实现吗?下面举个例子,可以体现二者在区分能力上的差异。
假设你有一句话:
“我今天心情很好。”
用语言模型(如 BERT、OpenAI Embedding API)把它变成一个 1536 维的向量:
[0.13, -0.42, 0.57, ... , 0.03]
如果再输入一句话:
“我很开心。”
这句话的向量可能非常接近上面的那一个,相当于不要求两者有相同的关键词,而是近义词即可 于是,向量数据库能帮你快速找出语义最相似的文本、图片或音频等数据。 这就是“相似度搜索(similarity search)”或“语义检索”的核心。
而Elasticsearch则不同,是属于切词搜索,通过切分输入为各种关键词,来命中Elasticsearch中存储的内容。
总结为一句话:
向量数据库 = 让 AI 能够“理解相似性”的数据库。它不追求精确匹配,而是帮助你找到“语义最相近”的内容。
Milvus系统架构
| 缩写 | 全称 | 中文名称 | 主要作用 | 示例 |
|---|---|---|---|---|
| DDL | Data Definition Language | 数据定义语言 | 定义数据库结构(schema) | CREATE COLLECTION, DROP COLLECTION, CREATE INDEX |
| DCL | Data Control Language | 数据控制语言 | 权限与访问控制 | GRANT, REVOKE |
| DML | Data Manipulation Language | 数据操作语言 | 操作实际数据 | INSERT, DELETE, UPDATE, UPSERT |
| DQL | Data Query Language | 数据查询语言 | 查询数据(通常为 SELECT / SEARCH) | SEARCH, QUERY |
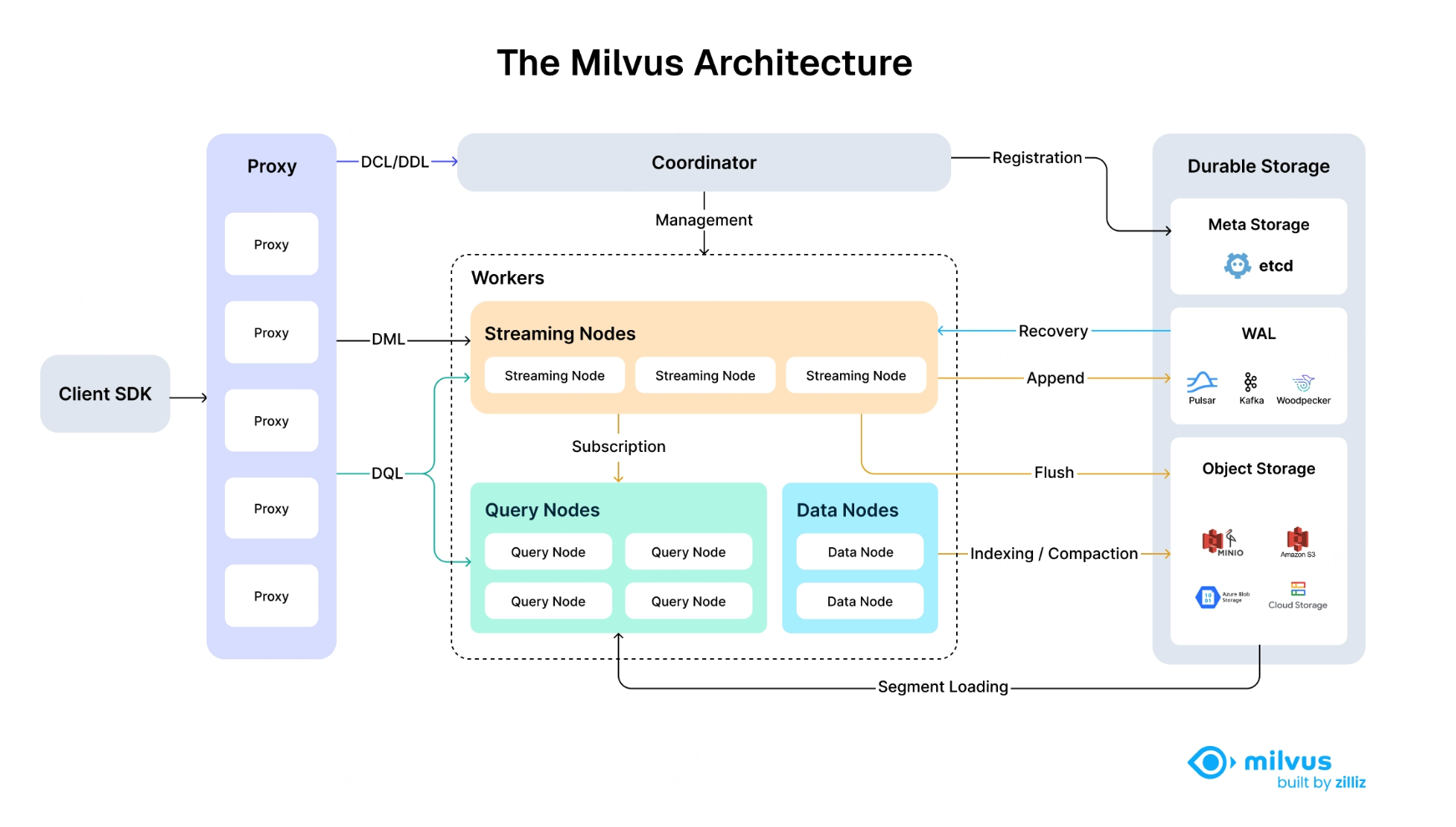
以官方的架构图为例,可以把Milvus 整体分为 4 层「访问层、协调层、工作层、存储层」,这些层之间通过流(Streaming)和消息机制协作,构成一个高性能、可横向扩展的云原生向量数据库:
Client SDK
图示中的Client SDK并非Milvus的结构,而是客户端的访问入口,Milvus提供了提供多语言 SDK(Python、Java、Go 等),负责与 Proxy 通信,支持将用户的操作(创建集合、插入向量、搜索、删除等)转化为 RPC【Remote Procedure Call】 调用,支持 RESTful 与 gRPC 接口协议。
访问层(Access Layer)
Proxy是系统的「前门」,是无状态服务,用于验证和转发客户端请求,聚合结果,提供统一服务入口(通过负载均衡组件如 Nginx、Ingress、NodePort、LVS)
由于 Milvus 采用的是大规模并行处理(MPP)架构,通过中间代理会对中间结果进行聚合和后处理,然后再将最终结果返回给客户端。
主要职责:
- 解析 DDL(创建集合、索引)、DML(插入、删除)等请求;
- 向协调器请求任务分配;
- 在结果返回前进行聚合、排序等后处理;
- 可横向扩展以支持更多并发。
协调层(Coordinator Layer)
整个系统的大脑,主要负责负责管理、调度、元数据、一致性等功能:
- 集群拓扑管理;
- 任务调度;
- 时间戳与一致性控制;
- 查询路由与负载均衡;
- 管理流节点、查询节点、数据节点等 Worker 的生命周期。
内部主要子组件:
- Root Coordinator:处理 DDL / DCL、时间戳分配(TSO)、Collection 元信息管理;
- Query Coordinator:管理 Query Node 拓扑、负载均衡;
- Data Coordinator:调度数据压缩、索引构建任务;
- Index Coordinator:管理索引任务;
- Proxy Coordination:提供服务发现与健康检查。
DDL / DCL需要读取或者修改系统的元数据,因此实际的交互是和协调层发生的
工作层(Worker Layer)
具体执行计算与数据流处理任务的“手脚”。 Milvus 的核心计算在这一层。
包括三类节点:
Streaming Nodes(流节点)
- 负责实时写入、流式数据处理;
- 处理 DML 请求(insert、delete、upsert);
- 将数据写入 WAL 并保证碎片级一致性;
- 当数据段积累到一定大小时,触发“封存”动作转交给 Data Node;
- 实现实时查询(growth data)与历史数据(sealed segment)的切换。
类比:像 Kafka 的分区消费者 + 实时预处理引擎。
Query Nodes(查询节点)
- 负责历史数据的查询;
- 从对象存储加载封存数据段;
- 执行向量检索、过滤、TopK 等计算;
- 多节点结果汇总后再上送给 Proxy。
类比:分布式向量检索引擎(如 Faiss/HNSW 的集群版)。
Data Nodes(数据节点)
- 负责离线数据处理任务;
- 对封存分段(sealed segments)执行:
- 压缩(Compaction)
- 索引构建(Indexing)
- 将结果存回对象存储中;
- 可异步运行以减少实时查询压力。
类比:后台批处理/ETL节点。
存储层(Storage Layer)
Milvus 的所有持久化数据都在这一层。
Meta Storage(元数据存储)
- 默认使用 etcd 存储集合定义(schema)、分区信息、段信息、消费位点;
- 需要强一致、事务性存储;
- 同时用于服务注册与健康检查。
WAL(Write Ahead Log)存储
- 记录所有写操作日志;
- 确保数据在写入前先落盘,支持崩溃恢复;
- 可使用 Kafka、Pulsar 或 Milvus 自研 Woodpecker(零磁盘 WAL,直接写入对象存储)。
💡Woodpecker 特点:云原生设计、无磁盘依赖、自动扩展。
Object Storage(对象存储)
- 存储实际的向量数据、索引文件、中间查询结果;
- 默认支持 MinIO、本地存储或云存储(AWS S3、Azure Blob);
- 延迟高但成本低;
- 后续可结合缓存层(Memory/SSD)实现冷热分离。
数据流示例:数据插入
- 客户端发送带有向量数据的插入请求
- 访问层验证请求并转发给流节点
- 流节点将操作符记录到 WAL 存储,以确保持久性
- 实时处理数据并提供查询
- 当分段达到容量时,流节点触发转换为密封分段
- 数据节点处理压缩,并在密封网段上建立索引,将结果存储在对象存储中
- 查询节点加载新建索引并替换相应的增长数据
各操作语言的交互对象
| 类别 | 全称 | 中文名称 | 主要作用 | 操作类型 | 指向层级 | 执行节点 | 说明 |
|---|---|---|---|---|---|---|---|
| DDL | Data Definition Language | 数据定义语言 | 定义数据库结构(schema) | 创建 / 删除 集合、索引 | Coordinator | Root Coordinator | 修改 schema 与元数据 |
| DCL | Data Control Language | 数据控制语言 | 权限与访问控制 | 授权 / 撤销权限 | Coordinator | Root Coordinator | 修改权限控制信息 |
| DML | Data Manipulation Language | 数据操作语言 | 操作实际数据 | 插入 / 删除 / 更新 数据 | Worker | Streaming Node / Data Node | 实际写入或删除向量数据 |
| DQL | Data Query Language | 数据查询语言 | 查询数据(通常为 SELECT / SEARCH) | 搜索 / 查询 数据 | Worker | Query Node / Streaming Node | 执行向量搜索与过滤 |
总结:
Milvus 通过:
- Proxy(请求入口)
- Coordinator(集群大脑)
- Workers(流+查询+数据处理)
- Storage(WAL + 元数据 + 对象存储)
实现了一个典型的 云原生、存储计算分离、高可扩展 的分布式向量数据库。
参考文档:https://milvus.io/docs/zh/architecture_overview.md

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 40
40 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)