基于检索的生成用于知识密集型自然语言处理任务
RAG 指的是检索增强生成(Retrieval-Augmented Generation),这是一种结合了信息检索和生成式AI的框架,旨在提升大语言模型(LLM)的输出质量。它通过在LLM生成回答之前,先从外部知识库(如数据库或文档)中检索相关信息,然后将这些信息作为上下文提供给模型,从而确保生成的内容更加准确、及时且相关,同时避免了重新训练模型。本文提出了可以访问参数和非参数记忆的混合生成模型,
今天学习一篇大模型的经典之作,RAG模型的“起源地”《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》。
定义
RAG 指的是检索增强生成(Retrieval-Augmented Generation),这是一种结合了信息检索和生成式AI的框架,旨在提升大语言模型(LLM)的输出质量。 它通过在LLM生成回答之前,先从外部知识库(如数据库或文档)中检索相关信息,然后将这些信息作为上下文提供给模型,从而确保生成的内容更加准确、及时且相关,同时避免了重新训练模型。
引言
预训练神经语言模型已被证明可以从数据中学习到大量的深入知识。它们可以在没有任何外部记忆的情况下做到这一点,作为一个参数化的隐式知识库。虽然这种发展令人兴奋,但这些模型也存在缺点:它们不能轻易地扩展或修改它们的记忆,不能直接提供对其预测的洞察力,并且可能产生“幻觉”。将参数记忆与非参数(即,基于检索的)记忆相结合的混合模型可以解决其中的一些问题,因为知识可以直接修改和扩展,并且可以检查和解释访问的知识。REALM 和ORQA 是最近推出的两个模型,它们将掩码语言模型与可微分检索器相结合,已经显示出有希望的结果,但只探索了开放域抽取式问答。在这里,本文将混合参数和非参数记忆引入到序列到序列(seq2seq)模型中,以扩展都各种NLP任务。
执行过程
本文通过一种通用微调方法,即检索增强生成(RAG),为预训练的参数记忆生成模型赋予非参数记忆。本文构建的RAG模型中,参数记忆是一个预训练的序列到序列转换器,非参数记忆是维基百科的密集向量索引,通过预训练的神经检索器访问。本文将这些组件组合在一个端到端训练的概率模型中。如图1所示,是RAG的方法概述。将预训练的检索器(查询编码器+文档索引)与预训练的seq2seq模型(生成器)相结合,并进行端到端微调。对于查询x,本文使用最大内积搜索(MIPS)来找到前K个文档zi。对于最终预测y,我们将z视为潜在变量,并对给定不同文档的seq2seq预测进行加权平均处理。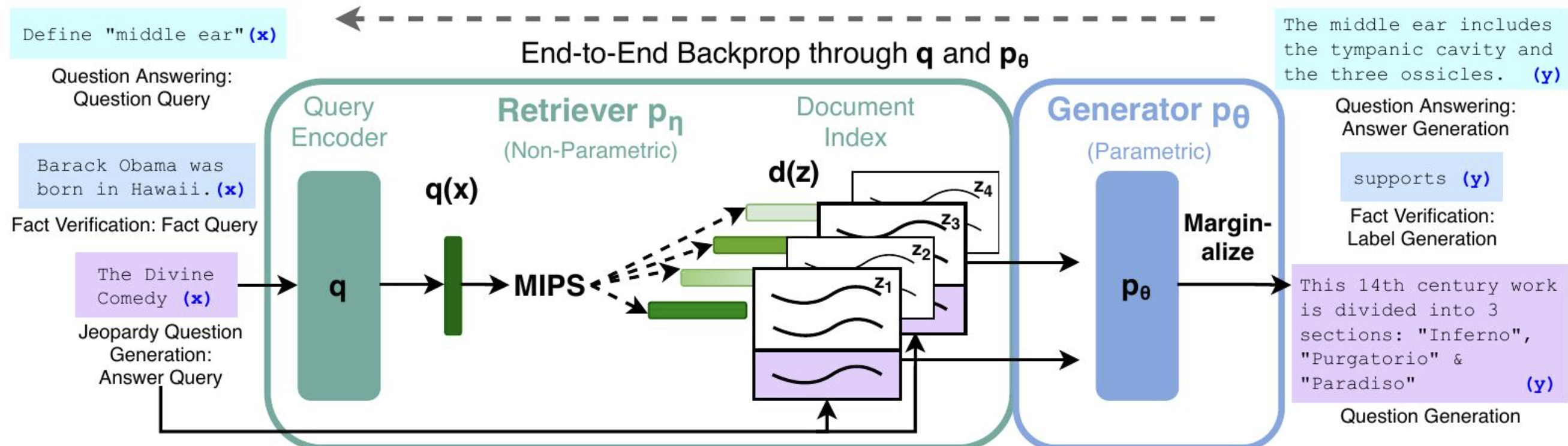
图1
具体而言,检索器(密集段落检索器,以下简称DPR)提供以输入为条件的潜在文档,然后序列到序列模型(BART)以这些潜在文档以及输入为条件来生成输出。本文使用top-K近似来加权平均潜在文档,可以基于每个输出(假设同一文档负责所有token),也可以基于每个token(不同的文档负责不同的token)。与T5 或BART一样,RAG可以在任何序列到序列任务上进行微调,从而联合学习生成器和检索器。
相关工作
考虑到这篇论文的经典性,我们针对这篇论文着重对相关工作进行概述,力求读者和作者一样,知道整个大模型的经典脉络。
1. 单任务检索 先前的工作表明,当孤立地考虑时,检索可以提高各种自然语言处理任务的性能。这些任务包括开放域问答[Reading Wikipedia to Answer Open-Domain Questions, Natural Questions: a Benchmark for Question Answering Research],事实核查[FEVER: a large-scale dataset for fact extraction and VERification],事实补全[How context affects language models’ factual predictions],长篇问答[ELI5: Long form question answering],维基百科文章生成[Generating wikipedia by summarizing long sequences],对话[Towards exploiting background knowledge for building conversation systems, Retrieve and refine: Improved sequence generation models for dialogue, Wizard of wikipedia: Knowledge-powered conversational agents, Augmenting transformers with KNN-based composite memory],翻译[Search engine guided neural machine translation]和语言建模[Generating sentences by editing prototypes, Generalization through memorization: Nearest neighbor language models]。RAG统一了先前将检索纳入各个任务的成功经验,表明基于单一检索的架构能够跨多个任务实现强大的性能。
**2. NLP通用架构:**先前关于NLP任务通用架构的研究表明,即使不使用检索也能取得巨大成功。一个预训练的语言模型在经过微调[Improving Language Understanding by Generative Pre-Training, BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding]后,已在GLUE基准测试[GLUE: A multi-task benchmark and analysis platform for natural language understanding, SuperGLUE: A Stickier Benchmark for GeneralPurpose Language Understanding Systems]中的各种分类任务上表现出强大的性能。GPT-2 [Language models are unsupervised multitask learners]后来表明,一个单一的、从左到右的预训练语言模型可以在判别任务和生成任务中都取得强大的性能。为了进一步改进,BART [BART: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension]和T5 [Exploring the limits of transfer learning with a unified text-to-text transformer, How much knowledge can you pack into the parameters of a language model]提出了一个单一的、预训练的编码器-解码器模型,该模型利用双向注意力在判别任务和生成任务上实现更强大的性能。RAG旨在通过学习一个检索模块来增强预训练的生成语言模型,从而扩展具有单一统一架构的可能任务空间。
3. 学习检索 在信息检索中,有大量关于学习检索文档的工作,最近的工作使用了与RAG类似的预训练神经语言模型[Passage re-ranking with BERT, Dense passage retrieval for open-domain question answering]。一些工作优化了检索模块,以辅助特定的下游任务,例如问答,使用搜索[Finding generalizable evidence by learning to convince q&a models.]、强化学习[Coarse-to-fine question answering for long documents, Evidence aggregation for answer reranking in open-domain question answering, R3: Reinforced ranker-reader for open-domain question answering]或潜在变量方法[atent retrieval for weakly supervised open domain question answering, REALM: Retrieval-augmented language model pre-training],就像RAG一样。这些成功利用了不同的基于检索的架构和优化技术,以在单个任务上实现强大的性能,而RAG表明,可以对单个基于检索的架构进行微调,以在各种任务上实现强大的性能。
4. 基于记忆的架构 RAG的文档索引可以被视为神经网络可以关注的大型外部记忆,类似于记忆网络[Memory networks., End-to-end memory networks]。并行工作[Entities as experts: Sparse memory access with entity supervision]学习检索输入中每个实体的训练嵌入,而不是像RAG的工作那样检索原始文本。其他工作通过关注事实嵌入来提高对话模型生成事实文本的能力[A knowledge-grounded neural conversation model, Augmenting transformers with KNN-based composite memory]。RAG记忆的一个关键特征是它由原始文本而非分布式表示组成,这使得记忆既 (i) 人类可读,为我们的模型提供了一种可解释性,又 (ii) 人类可写,使RAG能够通过编辑文档索引来动态更新模型的记忆。这种方法也已用于知识密集型对话,其中生成器直接以检索到的文本为条件,尽管这些文本是通过 TF-IDF 而不是端到端学习检索获得的[Wizard of wikipedia: Knowledge-powered conversational agents]。
**5. 检索与编辑方法。**RAG的方法与检索与编辑风格的方法有一些相似之处,在检索与编辑风格的方法中,对于给定的输入,检索一个相似的训练输入-输出对,然后对其进行编辑以提供最终输出。这些方法已在包括机器翻译[Search engine guided neural machine translation, Simple and effective retrieveedit-rerank text generation]和语义解析[A retrieve-and-edit framework for predicting structured outputs]在内的许多领域中被证明是成功的。RAG的方法确实存在一些差异,包括较少强调轻微编辑检索到的项目,而是强调从多个检索到的内容中聚合内容,以及学习潜在检索,以及检索证据文档而不是相关的训练对。也就是说,RAG技术可能在这些设置中运行良好,并且可能代表着有希望的未来工作。
总结
本文提出了可以访问参数和非参数记忆的混合生成模型,证明了RAG模型在开放域问答方面获得了最先进的结果。同时发现,人们更喜欢RAG的生成结果,而不是纯参数化的BART,认为RAG更具事实性和针对性。此外,对学习到的检索组件进行了彻底的调查,验证了其有效性,并说明了如何热插拔检索索引来更新模型,而无需任何重新训练。
10月24日和10月25日学习笔记
文章同步更新在同名今日头条号“一的万次方”
《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)