伯克利等高校开源kvcached:KV缓存守护进程实现动态GPU共享,大幅提升GPU利用率,成本直降70%
加州大学伯克利分校、莱斯大学和加州大学洛杉矶分校的研究人员共同开发的kvcached项目,将GPU利用率大幅提升,成本直降70%。一个模型占一张卡,GPU内存利用率低,一直是大模型部署的痛点。花大价钱买来的昂贵硬件,大部分时间都在闲置。在AI推理任务中,GPU的利用率通常只有20-40%。富士通引用的一份报告显示,超过75%的组织在峰值负载时,GPU利用率也低于70%。kvcached的本质,是利
加州大学伯克利分校、莱斯大学和加州大学洛杉矶分校的研究人员共同开发的kvcached项目,将GPU利用率大幅提升,成本直降70%。
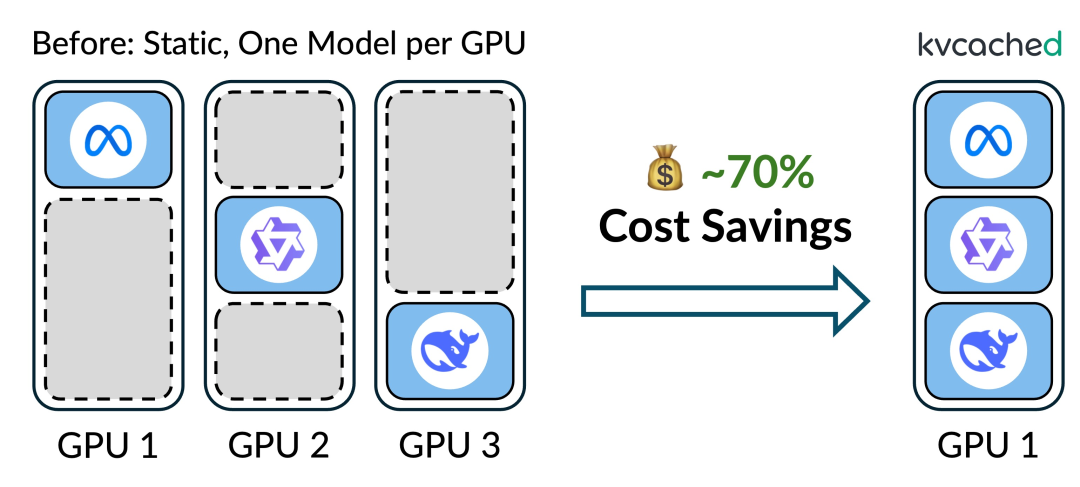
一个模型占一张卡,GPU内存利用率低,一直是大模型部署的痛点。花大价钱买来的昂贵硬件,大部分时间都在闲置。
在AI推理任务中,GPU的利用率通常只有20-40%。富士通引用的一份报告显示,超过75%的组织在峰值负载时,GPU利用率也低于70%。
kvcached的本质,是利用KV缓存守护进程,通过虚拟化技术让多个模型共享同一张GPU的显存。
GPU的昂贵与闲置是一对孪生矛盾
GPU的闲置并非偶然,而是当前技术范式下的必然结果。
AI服务的流量负载具有明显的潮汐效应。研究表明,推理请求的速率可以在短短几分钟内增加3倍。为了保证服务质量,系统必须按照流量峰值来预留GPU资源。这意味着在流量低谷期,大量GPU资源只能空闲。
硬件的飞速发展也加剧了这种不匹配。过去十年,数据中心GPU的峰值吞吐量提高了超过1000倍,显存容量和带宽也增加了20倍以上。
与此同时,参数少于100亿的小型模型在许多专用任务上表现出色,部署越来越广泛。让巨型GPU去运行这些小模型,好比用航母运送一个包裹,大材小用,容量严重浪费。
目前的GPU管理方式是一个模型霸占一张卡的静态分配。即使使用MIG(多实例GPU)这类技术将一张大卡切分成几个小实例,每个实例的计算和显存资源仍然是静态固定的。一个模型用不完的资源,另一个模型也无法借用,资源之间无法流动共享。
一些先进的技术,如PagedAttention,通过内存分页管理KV(键值)缓存,确实提高了单个应用内的显存利用率。但它没有改变游戏规则。服务引擎在启动时,仍然需要静态预留一大块显存给PagedAttention使用。这块显存无法跨模型共享的本质没有改变。
今天GPU面临的困境,并非一个全新的问题。
几十年前,CPU也经历过完全相同的演化阶段。
在早期计算机系统中,计算资源同样以僵化、静态的方式分配。一个应用程序会独占整个CPU核心,即便它在等待输入或休息,其他程序也只能干等着,造成了大量的计算周期浪费。
转折点发生在1961年,兼容分时系统(CTSS)的出现,标志着操作系统的革命性变革。
抢占式调度、上下文切换、虚拟内存等一系列抽象技术的引入,允许多个应用程序高效地共享同一台CPU。
CPU的利用率因此大幅提升,计算成本急剧下降,整个计算机行业进入了可扩展的新纪元。
GPU生态系统此刻正站在与当年CPU相似的历史拐点。现代GPU提供了巨大的算力,却缺乏能够让这份算力被高效共享的软件抽象。
历史的经验告诉我们,效率的提升,不仅是硬件问题,更是系统设计问题。GPU需要自己的操作系统级抽象,而kvcached项目,正是朝着这个方向迈出的第一步。
kvcached让GPU学会了分身术
kvcached是一个用于弹性KV缓存管理的库,它的核心思想,是将操作系统风格的虚拟内存抽象引入到LLM系统中。
它抓住了一个关键的技术机遇:近期的CUDA驱动程序中引入了一组新的虚拟内存管理(VMM)API。
传统的cudaMalloc函数会同时分配虚拟地址和物理显存。而新的VMM API可以将这两个步骤分开。程序员可以先预留一大片虚拟地址范围,然后在真正需要读写数据时,才将一页页的物理显存映射到这些虚拟地址上。
这个特性为打破KV缓存的静态预留机制创造了可能。
但一个巨大的挑战摆在面前:兼容性。
VMM是底层的CUDA驱动API,而vLLM等现代LLM服务引擎都构建在PyTorch这类高级框架之上。这些框架依赖于一个完整的、物理内存连续的张量(Tensor)来管理KV缓存。直接使用VMM API会彻底颠覆现有的架构,无异于推倒重来。
kvcached的解决方案堪称神来之笔:它发明了一种新的抽象——虚拟张量(Virtual Tensor)。
虚拟张量对外表现得和普通的PyTorch张量别无二致。CUDA核心可以在它上面进行读、写和计算,完全察觉不到任何差异。
但在底层,虚拟张量对应的GPU物理显存是按需分配的。只有当服务引擎真正要去访问某块内存时,kvcached才会将物理显存页映射过来。
kvcached通过PyTorch的C++插件库实现了这一功能,并将服务引擎中原始的KV缓存张量替换为虚拟张量。同时,它钩住了服务引擎内部对KV缓存块的分配和释放操作,同步进行物理显存页的映射和取消映射。
这样,预留但闲置的物理显存就从根本上被消除了。
kvcached还必须解决另一个棘手问题:内存碎片。
比如,一个Llama-3.2-1B模型,每个token的KV缓存占用32KB显存,一个KV缓存块(包含16个token)就是512KB。但GPU硬件的物理显存页大小通常是2MB。
这意味着一个物理页可以容纳多个KV缓存块。如果随意分配,很可能导致许多2MB的物理页都只用了一部分,剩下的小块空间无法被有效利用和释放,就像一盒俄罗斯方块,中间全是零散的空洞。
kvcached为此设计了一个能感知碎片的KV缓存管理器。它会有逻辑地划分虚拟地址空间,并优先使用那些已被部分占用的物理页来分配新的KV缓存块,尽可能地将每个物理页填满,从而将内存碎片最小化。
为了追求极致性能,kvcached还包含许多优化。
例如,它通过一个并行线程异步地预分配少量GPU页缓冲区,减少了运行时的映射开销。它还引入了零页机制,将未使用的GPU虚拟地址映射到一个共享的、只读的、填满零的物理页。这样,即便是使用了CUDA图这种高性能技术,当内核访问到未分配的内存时,也不会崩溃,而是安全地读到零,保证了执行效率。
实际效果让成本大幅降低
kvcached的应用场景十分广泛,从云服务商到个人电脑,都能从中受益。
云服务提供商可以在同一张共享GPU上无缝运行多个LLM,根据负载动态调配资源,或在模型空闲时,快速回收GPU容量用于其他后台任务。
对于日益流行的无服务器(Serverless)LLM,kvcached的弹性KV缓存可以让模型的启动和缩减更加迅速和精细,真正做到按需使用,节省成本。
在个人电脑上运行编码助手等本地LLM的用户同样能感受到变化。当你在开着视频会议的同时使用AI编程,kvcached可以动态地从非活动的LLM中回收GPU显存,分配给当前需要的应用,确保系统运行流畅,避免因显存不足而卡顿或崩溃。
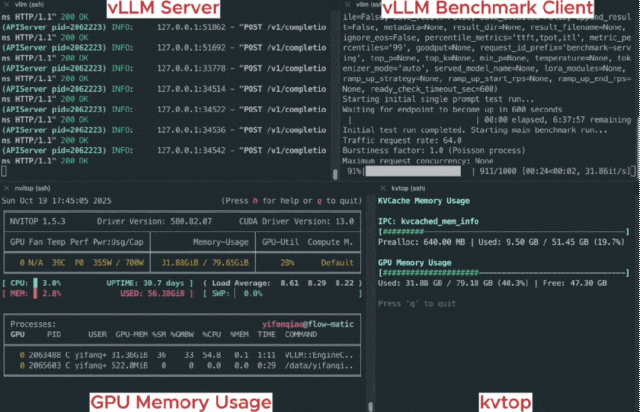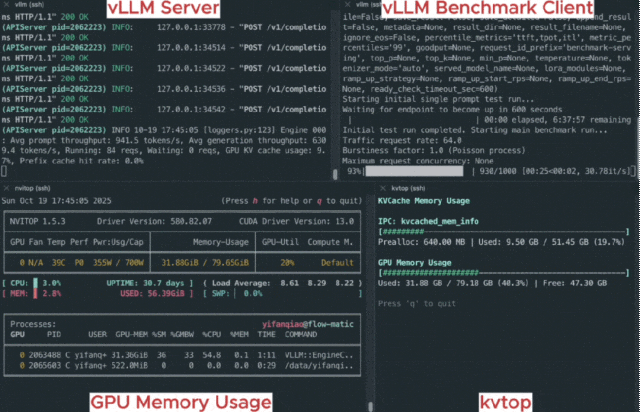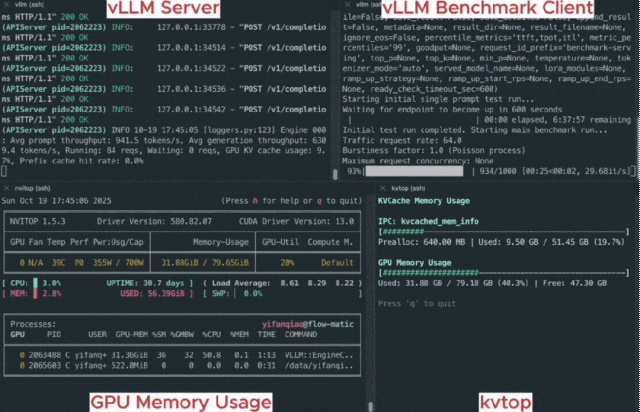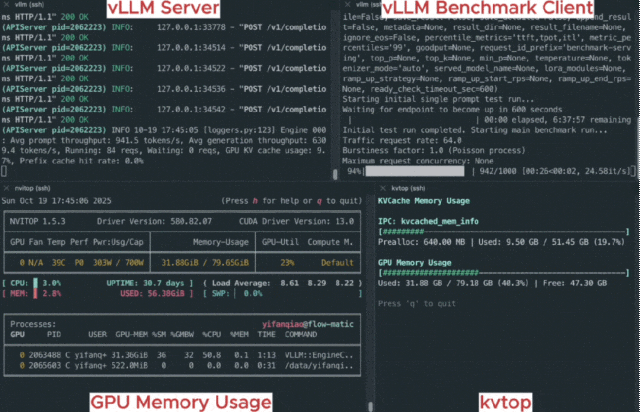
一项基准测试直观地展示了kvcached的性能优势。
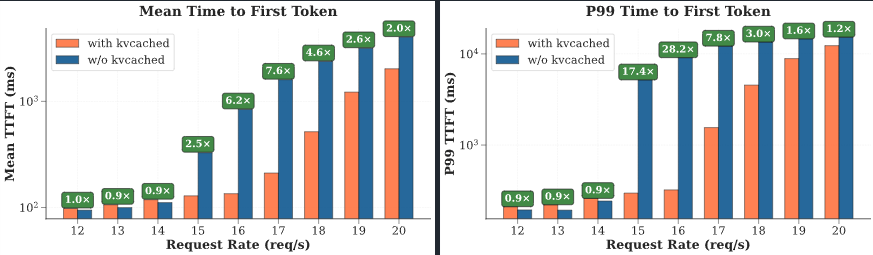
测试环境为一张A100-80G GPU,上面同时服务三个Llama-3.1-8B模型。这三个模型的工作负载都具有间歇性的流量高峰,且高峰期相互错开,这为kvcached在模型间动态重新分配资源创造了理想的共享机会。
作为对比的基线方案,是当前主流的静态分配方式,即为每个模型预留三分之一的GPU显存。
结果显示,与基线方案相比,kvcached将首次响应时间(TTFT,Time To First Token)缩短了1.2倍至28.2倍。
这种性能的提升,可以直接转化为显著的成本节约。没有kvcached,系统必须配置更多的GPU才能达到同等的服务水平。
kvcached结合了两篇论文的思路,《Prism: Unleashing GPU Sharing for Cost-Efficient Multi-LLM Serving》和《Towards Efficient and Practical GPU Multitasking in the Era of LLM》(迈向LLM时代高效实用的GPU多任务处理)。
Prism系统利用类似kvcached的按需内存分配和两级调度策略,在真实世界轨迹的评估中,实现了超过2倍的成本节省。
另一篇《迈向LLM时代高效实用的GPU多任务处理》的论文则指出,GPU必须像几十年前的CPU一样拥抱多任务处理,以满足现代AI工作负载的需求。
kvcached代表着构建一个高效实用的GPU操作系统的第一步。
它借鉴操作系统中虚拟内存的经典思想,用虚拟张量这一巧妙的抽象,解决了GPU显存静态分配的顽疾,为化解AI的成本危机提供了一条清晰可行的路径。
参考资料:
https://github.com/ovg-project/kvcached
https://docs.nvidia.com/cuda/cuda-driver-api/group__CUDA__VA.html
https://www.arxiv.org/abs/2505.04021
https://arxiv.org/abs/2508.08448
https://www.linkedin.com/pulse/ais-compute-crisis-billions-wasted-idle-gpus-due-poor-tony-shakib-fwtjc
https://global.fujitsu/en-global/technology/key-technologies/news/ta-maximizing-gpu-utilization-20251009
END

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献77条内容
已为社区贡献77条内容

所有评论(0)