大模型开发 - 37 RAG:Retrieval Augmented Generation(RAG)详解与实战指南
Spring AI RAG技术框架解析:检索增强生成与Advisor实战指南 摘要: 本文系统介绍了Spring AI对RAG(检索增强生成)技术的实现方案。RAG通过结合大模型生成能力和外部数据检索,有效解决了模型幻觉、知识过时等问题。Spring AI采用模块化设计,核心通过Advisor API实现RAG流程,提供开箱即用的组件支持。文章详解了Advisor的工作机制、拦截点设计及多级缓存策
文章目录

Pre
大模型开发 - 03 QuickStart_借助DeepSeekChatModel实现Spring AI 集成 DeepSeek
大模型开发 - 04 QuickStart_DeepSeek 模型调用流程源码解析:从 Prompt 到远程请求
大模型开发 - 05 QuickStart_接入阿里百炼平台:Spring AI Alibaba 与 DashScope SDK
大模型开发 - 06 QuickStart_本地大模型私有化部署实战:Ollama + Spring AI 全栈指南
大模型开发 - 07 ChatClient:构建统一、优雅的大模型交互接口
大模型开发 - 08 ChatClient:构建智能对话应用的流畅 API
大模型开发 - 09 ChatClient:基于 Spring AI 的多平台多模型动态切换实战
大模型开发 - 10 ChatClient:Advisors API 构建可插拔、可组合的智能对话增强体系
大模型开发 - 11 ChatClient:Advisor 机制详解:拦截、增强与自定义 AI 对话流程
大模型开发 - 12 Prompt:Spring AI 中的提示(Prompt)系统详解_从基础概念到高级工程实践
大模型开发 - 13 Prompt:提示词工程实战指南_Spring AI 中的提示设计、模板化与最佳实践
大模型开发 - 14 Chat Memory:实现跨轮次对话上下文管理
大模型开发 - 15 Tool Calling :从入门到实战,一步步构建智能Agent系统
大模型开发 - 16 Chat Memory:借助 ChatMemory + PromptChatMemoryAdvisor轻松实现大模型多轮对话记忆
大模型开发 - 17 Structured Output Converter:结构化输出转换器_从文本到结构化数据的可靠桥梁
大模型开发 - 18 Chat Memory:集成 JdbcChatMemoryRepository 实现大模型多轮对话记忆
大模型开发 - 19 Chat Memory:集成 BaseRedisChatMemoryRepository实现大模型多轮对话记忆
大模型开发 - 20 Chat Memory:多层次记忆架构_突破大模型对话中的 Token 上限瓶颈
大模型开发 - 21 Structured Output Converter:结构化输出功能实战指南
大模型开发 - 22 Multimodality API:多模态大模型与 Spring AI 的融合
大模型开发 - 23 Chat Model API:深入解析 Spring AI Chat Model API_构建统一、灵活、可扩展的 AI 对话系统
大模型开发 - 24 Embeddings Model API:深入解析 Spring AI Embeddings Model API_构建语义理解的基石
大模型开发 - 25 Image Model API:深入解析 Spring AI Image Model API_构建统一、灵活的 AI 图像生成系统
大模型开发 - 26 Origin Tools: Spring AI 结构化多聊天客户端实战
大模型开发 - 27 Tool Calling:Spring AI 中的工具调用指南
大模型开发 - 28 Tool Calling:Spring AI 工具调用执行外部操作实战
大模型开发 - 29 Tool Calling:大模型与业务系统集成的利器 _Tool Calling 实战指南
大模型开发 - 30 Tool Calling:Spring AI Tool Calling 工作原理及源码详解
大模型开发 - 31 Tool Calling:解决大模型“工具选择困难症”_基于 RAG 的动态工具加载方案解读
大模型开发 - 32 Tool Calling:Spring AI 工具调用最佳实践完整指南
大模型开发 - 33 MCP:深入理解 Model Context Protocol(MCP)及其在 Spring AI 中的实践指南
大模型开发 - 34 MCP:Spring AI MCP 客户端启动器(MCP Client Boot Starter)深度指南
大模型开发 - 35 MCP:Spring AI MCP 服务端启动器(MCP Server Boot Starter)完全指南
大模型开发 - 36 MCP:深入理解 MCP Utilities :同步与异步工具回调
一、什么是 Retrieval Augmented Generation(RAG)?

RAG(检索增强生成) 是一种结合了“检索”与“大模型生成”的 AI 技术框架,旨在克服当下大模型在事实正确性、上下文理解和长文本处理等方面的局限。它让大模型在作答时不仅依赖模型本身参数,还能动态检索外部数据源的相关信息,从而输出更为精准与实时的回答。
Spring AI 对 RAG 的支持包括:
- 提供模块化架构,方便开发者自定义与组装 RAG 流程
- 内置数种 Advisor,可以直接开箱即用进行 RAG 流程
二、Spring AI 的 RAG 实现核心——Advisor API
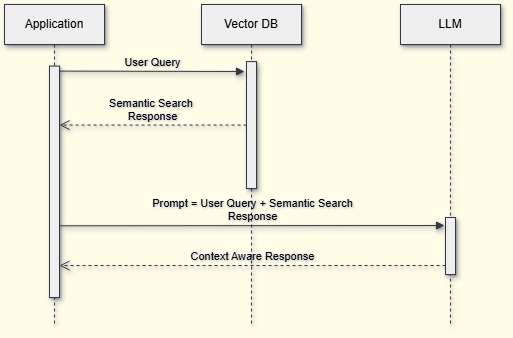
1. 概述
Advisor(顾问)是 Spring AI 提供的一种高阶接口,用于实现常见的 RAG 流程。两大常用 Advisor:
QuestionAnswerAdvisorRetrievalAugmentationAdvisor
2. 依赖集成
以 Maven 为例,需加入相关依赖:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-advisors-vector-store</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-rag</artifactId>
</dependency>
三、核心 Advisor 详解及用法
1. QuestionAnswerAdvisor
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-advisors-vector-store</artifactId>
</dependency>
- 用途:适用于问答场景,通过查询向量数据库找到最相关的文档,然后把这些文档和用户问题一起传递给大模型生成答案。
- 使用方式:
ChatResponse response = ChatClient.builder(chatModel)
.build()
.prompt()
.advisors(new QuestionAnswerAdvisor(vectorStore))
.user(userText)
.call()
.chatResponse();
- 进阶功能:
-
支持配置查询的
相似度阈值和返回结果数量topK// 创建 QuestionAnswerAdvisor 实例,其中阈值为 0.8 ,并返回前 6 结果 var qaAdvisor = QuestionAnswerAdvisor.builder(vectorStore) .searchRequest(SearchRequest.builder().similarityThreshold(0.8d).topK(6).build()) .build(); -
支持静态/动态过滤表达式(Filter Expression),可按元数据过滤文档
ChatClient chatClient = ChatClient.builder(chatModel) .defaultAdvisors(QuestionAnswerAdvisor.builder(vectorStore) .searchRequest(SearchRequest.builder().build()) .build()) .build(); // Update filter expression at runtime String content = this.chatClient.prompt() .user("Please answer my question XYZ") // FILTER_EXPRESSION 参数允许根据提供的表达式动态过滤搜索结果。 .advisors(a -> a.param(QuestionAnswerAdvisor.FILTER_EXPRESSION, "type == 'Spring'")) .call() .content(); -
可自定义 Prompt 模板(PromptTemplate),如对合成上下文方式定制等
-
示例:自定义 PromptTemplate
PromptTemplate customPromptTemplate = PromptTemplate.builder()
.renderer(StTemplateRenderer.builder().startDelimiterToken('<').endDelimiterToken('>').build())
.template("""
Context information is below.
---------------------
<question_answer_context>
---------------------
Given the context information and no prior knowledge, answer the query...
""")
.build();
2. RetrievalAugmentationAdvisor
Spring AI 包含一个 RAG 模块库 ,您可以使用它来构建自己的 RAG 流程。RetrievalAugmentationAdvisor 是一个 Advisor RetrievalAugmentationAdvisor 基于模块化架构,为最常见的 RAG 流程提供开箱即用的实现。
要使用 RetrievalAugmentationAdvisor ,需要将 spring-ai-rag 依赖项添加到项目中
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-rag</artifactId>
</dependency>
- 用途:适合需要更复杂或组合式 RAG 流程的场景,依据模块化设计理念支持灵活组装。
- 用法示例:
Advisor retrievalAugmentationAdvisor = RetrievalAugmentationAdvisor.builder()
.documentRetriever(VectorStoreDocumentRetriever.builder()
.similarityThreshold(0.50)
.vectorStore(vectorStore)
.build())
.build();
String answer = chatClient.prompt()
.advisors(retrievalAugmentationAdvisor)
.user(question)
.call()
.content();
- 扩展能力:
- 支持空上下文应答定制
- 支持 Filter Expression(同前)
- 支持 Query Transformer 等流程模块
Sequential RAG Flows
Naive RAG
Advisor retrievalAugmentationAdvisor = RetrievalAugmentationAdvisor.builder()
.documentRetriever(VectorStoreDocumentRetriever.builder()
.similarityThreshold(0.50)
.vectorStore(vectorStore)
.build())
.build();
String answer = chatClient.prompt()
.advisors(retrievalAugmentationAdvisor)
.user(question)
.call()
.content();
默认情况下, RetrievalAugmentationAdvisor 不允许检索到的上下文为空。当出现这种情况时,它会指示模型不回答用户查询。可以按如下方式允许空上下文。
Advisor retrievalAugmentationAdvisor = RetrievalAugmentationAdvisor.builder()
.documentRetriever(VectorStoreDocumentRetriever.builder()
.similarityThreshold(0.50)
.vectorStore(vectorStore)
.build())
.queryAugmenter(ContextualQueryAugmenter.builder()
.allowEmptyContext(true)
.build())
.build();
String answer = chatClient.prompt()
.advisors(retrievalAugmentationAdvisor)
.user(question)
.call()
.content();
VectorStoreDocumentRetriever 接受 FilterExpression 用于根据元数据过滤搜索结果。您可以在实例化 VectorStoreDocumentRetriever 时或在每次请求运行时使用 FILTER_EXPRESSION advisor 上下文参数提供一个 FilterExpression 参数
Advisor retrievalAugmentationAdvisor = RetrievalAugmentationAdvisor.builder()
.documentRetriever(VectorStoreDocumentRetriever.builder()
.similarityThreshold(0.50)
.vectorStore(vectorStore)
.build())
.build();
String answer = chatClient.prompt()
.advisors(retrievalAugmentationAdvisor)
.advisors(a -> a.param(VectorStoreDocumentRetriever.FILTER_EXPRESSION, "type == 'Spring'"))
.user(question)
.call()
.content();
Advanced RAG
Advisor retrievalAugmentationAdvisor = RetrievalAugmentationAdvisor.builder()
.queryTransformers(RewriteQueryTransformer.builder()
.chatClientBuilder(chatClientBuilder.build().mutate())
.build())
.documentRetriever(VectorStoreDocumentRetriever.builder()
.similarityThreshold(0.50)
.vectorStore(vectorStore)
.build())
.build();
String answer = chatClient.prompt()
.advisors(retrievalAugmentationAdvisor)
.user(question)
.call()
.content();
还可以使用 DocumentPostProcessor API 对检索到的文档进行后处理,然后再将其传递给模型。例如,可以使用此类接口根据检索到的文档与查询的相关性对其进行重新排序,移除不相关或冗余的文档,或者压缩每个文档的内容以减少噪音和冗余
四、RAG 模块化架构与工作流程
来源于论文《Modular RAG: Transforming RAG Systems into LEGO-like Reconfigurable Frameworks》,Spring AI 实现了可重组的模块化 RAG 架构:
1. 预检索(Pre-Retrieval)
-
Query Transformation(查询改写/压缩/翻译)
-
包括:CompressionQueryTransformer(压缩)、RewriteQueryTransformer(重写)、TranslationQueryTransformer(翻译)
-
作用:处理冗长、模糊或多语言的用户查询;推荐低温度(temperature)配置以保结果确定性
可以通过构建器中提供的 promptTemplate() 方法自定义此组件使用的提示。
Query query = Query.builder() .text("And what is its second largest city?") .history(new UserMessage("What is the capital of Denmark?"), new AssistantMessage("Copenhagen is the capital of Denmark.")) .build(); QueryTransformer queryTransformer = CompressionQueryTransformer.builder() .chatClientBuilder(chatClientBuilder) .build(); Query transformedQuery = queryTransformer.transform(query);CompressionQueryTransformer使用大型语言模型将对话历史和后续查询压缩为捕捉对话本质的独立查询。当对话历史很长并且后续查询与对话上下文相关时,此转换器很有用。
可以通过构建器中提供的 promptTemplate() 方法自定义此组件使用的提示。RewriteQueryTransformer
Query query = new Query("I'm studying machine learning. What is an LLM?"); QueryTransformer queryTransformer = RewriteQueryTransformer.builder() .chatClientBuilder(chatClientBuilder) .build(); Query transformedQuery = queryTransformer.transform(query);RewriteQueryTransformer使用大型语言模型重写用户查询,以便在查询目标系统(例如向量存储或 Web 搜索引擎)时提供更好的结果。当用户查询冗长、含糊不清或包含可能影响搜索结果质量的不相关信息时,此转换器很有用。
可以通过构建器中提供的 promptTemplate() 方法自定义此组件使用的提示。
TranslationQueryTransformer
Query query = new Query("Hvad er Danmarks hovedstad?"); QueryTransformer queryTransformer = TranslationQueryTransformer.builder() .chatClientBuilder(chatClientBuilder) .targetLanguage("english") .build(); Query transformedQuery = queryTransformer.transform(query);TranslationQueryTransformer使用大型语言模型将查询翻译成用于生成文档嵌入的嵌入模型所支持的目标语言。如果查询已经是目标语言,则原样返回。如果查询的语言未知,则同样原样返回。当嵌入模型在特定语言上进行训练并且用户查询使用不同的语言时,此转换器很有用。
可以通过构建器中提供的 promptTemplate() 方法自定义此组件使用的提示。
-
-
Query Expansion(查询扩展)
-
MultiQueryExpander 可将一个查询扩展开为多个有多样性的子查询
用于将输入查询扩展为查询列表的组件,通过提供替代查询公式或将复杂问题分解为更简单的子查询来解决诸如格式不良的查询等挑战。
MultiQueryExpander
MultiQueryExpander queryExpander = MultiQueryExpander.builder() .chatClientBuilder(chatClientBuilder) .numberOfQueries(3) .build(); List<Query> queries = queryExpander.expand(new Query("How to run a Spring Boot app?"));默认情况下, MultiQueryExpander 会将原始查询包含在扩展查询列表中。您可以通过构建器中的 includeOriginal 方法禁用此行为。
MultiQueryExpander queryExpander = MultiQueryExpander.builder() .chatClientBuilder(chatClientBuilder) .includeOriginal(false) .build();可以通过构建器中提供的 promptTemplate() 方法自定义此组件使用的提示。
-
2. 检索(Retrieval)
-
Document Search(文档检索)
-
VectorStoreDocumentRetriever 按查询在向量数据库中检索相关文档,支持相似度阈值、topK、过滤表达式等
负责从底层数据源(例如搜索引擎、向量存储、数据库或知识图)检索 Documents 的组件。
VectorStoreDocumentRetriever 从向量存储中检索与输入查询语义相似的文档。它支持基于元数据、相似度阈值和 Top-k 结果的过滤。DocumentRetriever retriever = VectorStoreDocumentRetriever.builder() .vectorStore(vectorStore) .similarityThreshold(0.73) .topK(5) .filterExpression(new FilterExpressionBuilder() .eq("genre", "fairytale") .build()) .build(); List<Document> documents = retriever.retrieve(new Query("What is the main character of the story?"));过滤表达式可以是静态的,也可以是动态的。对于动态过滤表达式,你可以传递一个 Supplier 。
DocumentRetriever retriever = VectorStoreDocumentRetriever.builder() .vectorStore(vectorStore) .filterExpression(() -> new FilterExpressionBuilder() .eq("tenant", TenantContextHolder.getTenantIdentifier()) .build()) .build(); List<Document> documents = retriever.retrieve(new Query("What are the KPIs for the next semester?"));还可以通过 Query API 使用 FILTER_EXPRESSION 参数提供特定于请求的过滤表达式。如果同时提供了特定于请求和特定于检索器的过滤表达式,则特定于请求的过滤表达式优先
Query query = Query.builder() .text("Who is Anacletus?") .context(Map.of(VectorStoreDocumentRetriever.FILTER_EXPRESSION, "location == 'Whispering Woods'")) .build(); List<Document> retrievedDocuments = documentRetriever.retrieve(query);
-
-
Document Join(文档合并)
-
ConcatenationDocumentJoiner:多来源文档合并、去重
ConcatenationDocumentJoiner将基于多个查询从多个数据源检索到的文档连接成一个文档集合。如果出现重复的文档,则保留第一个出现的文档。每个文档的分数保持不变。Map<Query, List<List<Document>>> documentsForQuery = ... DocumentJoiner documentJoiner = new ConcatenationDocumentJoiner(); List<Document> documents = documentJoiner.join(documentsForQuery);
-
3. 后检索(Post-Retrieval)
- Document Post-Processing(后处理)
-
可进行相关性重排、冗余去除、或内容压缩,优化最终传递给大模型的上下文
用于根据查询对检索到的文档进行后处理的组件,解决了诸如中间丢失 、模型的上下文长度限制等挑战,以及需要减少检索到的信息中的噪音和冗余。
例如,它可以根据文档与查询的相关性对文档进行排名,删除不相关或冗余的文档,或者压缩每个文档的内容以减少噪音和冗余。
-
4. 生成(Generation)
- Query Augmentation(上下文增强)
-
ContextualQueryAugmenter:将检索文档和用户原始问题合并给大模型生成答案
ContextualQueryAugmenter 使用来自所提供文档内容的上下文数据来增强用户查询。
QueryAugmenter queryAugmenter = ContextualQueryAugmenter.builder().build();默认情况下, ContextualQueryAugmenter 不允许检索到的上下文为空。当这种情况发生时,它会指示模型不回答用户查询。
可以启用 allowEmptyContext 选项,以允许模型即使检索到的上下文为空也能生成响应。QueryAugmenter queryAugmenter = ContextualQueryAugmenter.builder() .allowEmptyContext(true) .build(); -
可定制 prompts、配置空上下文处理等
可以通过构建器中提供的 promptTemplate() 和 emptyContextPromptTemplate() 方法自定义此组件使用的提示。
-
五、最佳实践建议
- 明确区分 PromptTemplate 和 TemplateRenderer 的作用(一个作用于上下文增强,一个作用于 ChatClient 级别的整体输入渲染)
- 对需要多轮、模糊或多语言问答场景,优先加装 QueryTransformer 和 QueryExpander
- 利用动态 filter 表达式实现多租户或多类型数据场景的个性化
- 对结果准确性有追求时,可加装后处理模块优化检索文档顺序或内容浓缩
- 复杂流水线推荐采用 RetrievalAugmentationAdvisor 模块式搭建
六、总结
Spring AI 在 RAG 场景为开发者带来极大便利,底层支持完整的、可插拔的各类模块,并通过 Advisor API 显著降低工程化门槛。无论是直接使用内置 Advisor,还是根据业务灵活拼装 RAG 流程,Spring AI 都能为 LLm+RAG 技术落地提供稳健、高效的基础设施。
如需获取官方文档实例与完整模块组合,可以查阅 Spring AI RAG 官方文档 或相关模块源码及社区资源,持续关注 RAG 技术的发展与演进。


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 11
11 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)