大模型太贵,小模型太笨?医疗 AI 诊断的“蒸馏”破局之路
在医疗 AI 领域,我们常陷入两难:大型多模态模型(如 GPT-4V)效果惊艳,但因其高昂的推理成本和隐私风险而难以在医院落地;而小型模型虽易于部署,却在复杂诊断任务上精度不足。本文提出了一种“视觉语言-知识蒸馏 (VL-KD)”的实战框架,巧妙地结合了“教师-学生”模式。我们利用大型视觉语言模型(如 Med-CLIP)的强大泛化能力作为“教师”,指导一个轻量级的“学生”模型(如 MobileNe
引言:医疗 AI 的“重量级”困境
想象一个场景:
张医生是市人民医院放射科的主任,他每天要看几百张 X 光片和 CT。他听说 AI 辅助诊断很火,也尝试引入过一些系统,但很快就遇到了瓶颈:
- “请不起”的专家: 那些效果惊艳的“GPT-4V”级别的大模型,每次调用都在“烧钱”,而且必须联网,医院的数据隐私怎么办?
- “猜不透”的菜鸟: 医院自研的小模型,虽然跑得快,但准确率起伏不定,面对罕见病例就“抓瞎”,医生不敢完全信任。
张医生的困境,就是医疗 AI 落地难的缩影:我们似乎必须在“昂贵但聪明的大脑”(大模型)和“廉价但平庸的助手”(小模型)之间二选一。
但,技术人的天职就是拒绝“二选一”。

今天,我们要介绍一个“鱼与熊掌兼得”的解决方案:视觉语言-知识蒸馏 (Visual-Language Knowledge Distillation, VL-KD)。
简单来说,就是请一个“全科专家”(大型视觉语言模型)来当“教师”,手把手教会一个“专科学生”(轻量级 CNN/Transformer 模型),让“学生”既有“专家”的智慧,又有“学生”的轻快。
读完本文,你将收获:
- 为什么“视觉语言模型”是医疗 AI 的未来?
- “知识蒸馏”如何解决大模型落地的“最后一公里”?
- 一个在医学影像上实践 VL-KD 的完整技术框架(附伪代码)。
模块一:为什么是“视觉语言模型”?
在 VL-KD 框架中,“视觉语言模型 (VLM)” 扮演的是“教师”角色。为什么选它?
传统的医学影像 AI(如一个 ResNet),它的学习方式是“看图说话”:X-ray.jpg -> [0.1, 0.9, 0.0] -> “肺炎”。
这种模型的局限性很大:
- 数据黑洞: 它需要海量的、由专家手动“打标签”的图像(例如 10 万张“肺炎” X 光片)。
- 知识单一: 它只能理解图像,但医生诊断时,看的是“图像”+“文字报告”。它无法理解报告中“右下肺叶可见斑片状阴影”这种丰富的文本知识。
而 VLM(如 CLIP, Med-CLIP)不同,它在预训练阶段就同时学习了图像和描述文本。
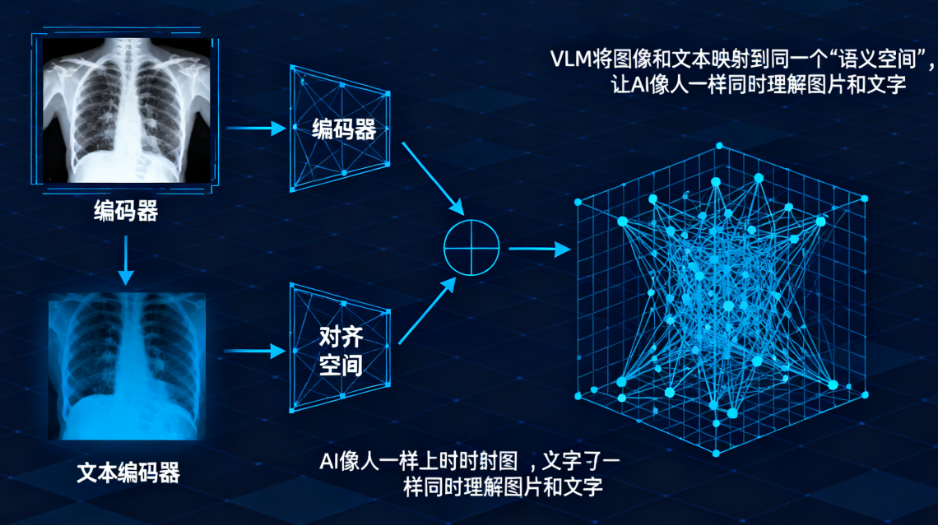
VLM 作为“教师”的优势在于:
- 知识更丰富: 它从海量的(图像+报告)数据中学会了什么是“骨折”,什么是“肿瘤”。
- 泛化能力强: 即使没见过某个特定病例,它也能根据文本描述进行“零样本 (Zero-Shot)”或“少样本 (Few-Shot)”推理。
- 提供更优的指导: 它不仅知道“这是肺炎”,它还知道“这 90% 像肺炎,10% 像肺结节”,这种“不确定性”知识(即“软标签”)对“学生”的训练至关重要。
模块二:“知识蒸馏”如何充当“导师”?
VLM 虽好,但它太“重”了(参数动辄数十亿)。我们不可能把它部署到每一台医院的本地服务器上。
这时,“知识蒸馏 (KD)” 就登场了。
KD 的核心思想非常符合直觉:一个好老师(Teacher Model)教学生(Student Model),不应该只给“标准答案”(Hard Labels),更应该传授“解题思路”(Soft Labels)。
- 学生: 一个轻量级、推理速度快的模型,比如 MobileNetV2 或一个小型 ViT。它的目标是部署在医院本地。
- 教师: 我们选定的 VLM 大模型,如 Med-CLIP。
- 课堂: 我们的训练数据集(可以是有标签的,甚至是无标签的)。

模块三:实战框架 (The “How”):三步构建 VL-KD 系统
假设我们的任务是:训练一个轻量级模型,用于高精度地分类“胸部 X 光片”(例如:正常、肺炎、肺结节)。
第 1 步:定义“教师”和“学生”
首先,我们要明确“师徒”的身份。
- 教师 (Teacher): 一个在海量医学数据上预训练过的 VLM。例如,一个基于 CLIP 并在 MIMIC-CXR 这类(影像+报告)数据集上微调过的
Med-VLM。 - 学生 (Student): 一个你希望最终部署的轻量级 CNN。例如
MobileNetV2或ResNet50。
# 教师:一个强大的、预训练好的视觉语言模型 (VLM)
# (假设我们有一个封装好的 Med-VLM 库)
teacher_model = MedVLM.load("med-clip-pretrained")
teacher_model.eval() # 教师只负责指导,不参与训练
# 学生:一个轻量级的、从零开始或在 ImageNet 上预训练的 CNN
student_model = torchvision.models.mobilenet_v2(pretrained=True)
# 修改最后一层以匹配我们的任务(3分类)
num_classes = 3
student_model.classifier[1] = nn.Linear(student_model.last_channel, num_classes)
第 2 步:设计“教学大纲”(Soft Labels)
这是 VL-KD 的核心。我们如何让 VLM “教师” 把它的知识传给 CNN “学生”?
关键在于,VLM 是一个“视觉-语言”模型。我们可以利用它的文本理解能力。
- 定义“诊断提示 (Prompts)”: 为我们的每个类别(正常、肺炎、肺结节)设计描述性的文本。
prompt_normal = "a normal chest X-ray"prompt_pneumonia = "a chest X-ray showing signs of pneumonia"prompt_nodule = "a chest X-ray with a pulmonary nodule"
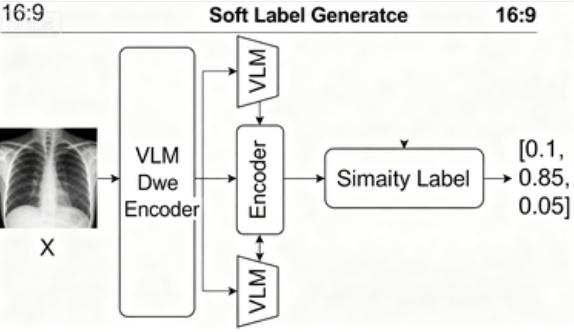
- 获取“教师的思路”(Soft Labels):
对于每一张输入的 X 光片image:- “教师” VLM 会同时处理这张
image和上面所有的prompts。 - 它会输出一个“相似度得分”向量,表示这张图片和哪句描述最像。例如:
[0.1, 0.85, 0.05]。 - 这个向量,就是 VLM 教师给出的“解题思路”或“软标签”。它告诉学生:“这张图 85% 像肺炎,10% 像正常,5% 像结节。”
- “教师” VLM 会同时处理这张
**
**
第 3 步:开始“上课”(混合损失训练)
现在,我们让“学生”在“教师”的指导下,同时对照“标准答案”(Ground Truth)进行学习。
对于同一张 image(假设其真实标签是“肺炎”,即 [0, 1, 0]):
- 学生作答:
student_model(image)-> 输出学生自己的 logitsstudent_logits。 - 教师指导:
teacher_model(image, prompts)-> 输出教师的 logitsteacher_logits(即 Soft Labels)。 - 标准答案:
ground_truth-> 即[0, 1, 0]。
我们使用一个混合损失函数 (Hybrid Loss) 来更新“学生”的参数:
Loss_Total = (1 - α) * Loss_Hard + α * Loss_KD
Loss_Hard(标准答案损失):- 即传统的交叉熵损失 (Cross-Entropy Loss)。
Loss_CE = CrossEntropy(student_logits, ground_truth)- 作用:确保学生至少能答对“标准答案”。
Loss_KD(教师指导损失):- 即知识蒸馏损失,常用 KL 散度 (KL Divergence)。
Loss_KD = KLDivLoss(softmax(student_logits / T), softmax(teacher_logits / T))T是“温度”超参数,T > 1时,会使教师的 Soft Labels 更“平滑”,让学生学到类与类之间的“模糊关系”(比如“肺炎”和“结节”有时有点像)。- 作用:让学生的“解题思路”模仿“教师”的思路。
α(平衡因子):- 一个超参数,用于平衡“死记硬背标准答案”和“学习老师解题思路”的重要性。
# 超参数
alpha = 0.7 # 70% 权重学习老师的思路
T = 4.0 # 蒸馏温度
# 损失函数
criterion_ce = nn.CrossEntropyLoss()
criterion_kd = nn.KLDivLoss(reduction='batchmean')
# 训练循环
for images, ground_truth_labels in dataloader:
# 1. 获取教师的软标签 (在 no_grad 下执行,教师不更新)
with torch.no_grad():
# 假设 teacher_model 能返回与 prompts 匹配的 logits
teacher_logits = teacher_model(images, prompts)
teacher_softmax = F.softmax(teacher_logits / T, dim=1)
# 2. 学生作答
student_logits = student_model(images)
student_softmax_for_kd = F.log_softmax(student_logits / T, dim=1) # KDLoss 需要 log-softmax
# 3. 计算混合损失
# 3a. 标准答案损失 (Hard Loss)
loss_hard = criterion_ce(student_logits, ground_truth_labels)
# 3b. 教师指导损失 (KD Loss)
loss_kd = criterion_kd(student_softmax_for_kd, teacher_softmax) * (T * T) # 乘以 T*T 是为了保持梯度尺度
# 3c. 总损失
loss_total = (1 - alpha) * loss_hard + alpha * loss_kd
# 4. 反向传播,只更新学生模型
optimizer.zero_grad()
loss_total.backward()
optimizer.step()
模块四:价值升华:我们得到了什么?
通过这个 VL-KD 框架,我们最终部署的,是那个轻量级的 student_model。但它已经不是一个普通的 MobileNetV2 了。
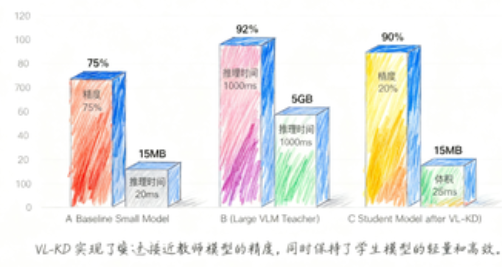
我们得到了:
- 高精度 + 高效率: 学生模型吸收了 VLM 教师对(影像+文本)知识的深刻理解,其精度远超传统方法训练的小模型,同时保持了极低的推理延迟。
- 数据高效性: VLM 教师的知识是“预先打包”好的。即使我们的标注数据不多,教师依然能提供高质量的 Soft Labels,极大地提高了数据利用效率。
- 隐私和部署友好: 最终部署的是一个小模型,它可以轻松运行在医院的本地服务器、移动设备甚至内窥镜上,完全无需联网,完美保障了患者的数据隐私。
总结:告别“二选一”
回到开头的“张医生”的困境,视觉语言-知识蒸馏 (VL-KD) 框架提供了一个优雅的破局之道。
我们不再需要在“昂贵的天才”和“廉价的庸才”之间妥协。VL-KD 让我们有能力“批量培养”出既聪明又高效的“专科精英”。
- VLM(教师) 负责“开拓视野”,利用海量多模态数据建立深刻的医学认知。
- KD(教学) 负责“知识传承”,将 VLM 的复杂知识高效地“蒸馏”到轻量级模型中。
- Student(学生) 负责“临床落地”,在资源受限的真实环境中,提供快速、可靠、私密的辅助诊断。
这不仅是模型压缩的技巧,更是大模型时代下,实现 AI 技术普惠化的必经之路。
行动号召 (Call to Action)
你是否也在医疗 AI 或其他领域中遇到了大模型“落地难”的问题?你尝试过哪些知识蒸馏的变体?欢迎在评论区分享你的经验和挑战!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 31
31 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)