Coggle数据科学 | Kaggle竞赛总结:RSNA 3D颅内动脉瘤检测
本文介绍了RSNA颅内动脉瘤检测竞赛的优胜方案。该竞赛旨在通过AI技术检测脑部影像中的动脉瘤,实现早期诊断。数据集包含多模态医学影像,标注了13个血管位置。前五名方案均采用两阶段策略:先定位血管区域,再进行分类。第一名方案通过血管分割和ROI提取,结合Transformer实现精确预测;第二名使用多任务3D nnU-Net;第三名利用2D投影和3D分类;第四名采用回归定位和2.5D分类;第五名通过
本文来源公众号“Coggle数据科学”,仅用于学术分享,侵权删,干货满满。
原文链接:https://mp.weixin.qq.com/s/DVqZtIEe1q1OC7eXTluiPg
-
赛题名称:RSNA Intracranial Aneurysm Detection
-
赛题类型:3D 计算机视觉
-
赛题任务:检测是否存在颅内动脉瘤,并精确定位其位置。
https://www.kaggle.com/competitions/rsna-intracranial-aneurysm-detection/overview
赛题背景
颅内动脉瘤,俗称“脑动脉瘤”,是大脑动脉血管壁上出现的异常膨出。它就像血管上的一个“小气球”,在未破裂时通常没有症状,但一旦破裂,会导致颅内出血,致死率和致残率极高。
全球约3%的人口患有颅内动脉瘤。令人担忧的是,其中高达50%的动脉瘤是在破裂后才被诊断出来的,这往往为时已晚。每年全球约有50万人因其死亡,且近半数受害者年龄在50岁以下。
虽然经验丰富的放射科医生能够通过脑部影像(如CTA、MRA、MRI)检测出动脉瘤,但在日常繁忙的诊疗中,尤其是在因其他原因进行影像检查时,动脉瘤很容易被忽略。
本次由RSNA(北美放射学会) 联合多个国际神经放射学权威机构主办的竞赛,旨在利用人工智能技术,开发能够快速、准确地在常规脑部影像中自动检测动脉瘤的模型。这有望实现早期诊断和干预,从而拯救无数生命。
赛题任务
构建一个机器学习模型,利用多模态医学影像数据,检测是否存在颅内动脉瘤,并精确定位其位置。
-
检测存在性:判断给定的影像研究中是否包含动脉瘤。
-
精确定位:如果存在动脉瘤,需要预测它位于以下哪个(或哪些)具体的血管解剖部位。
赛题数据集
包含了数千个由专家精心整理的脑部医学影像序列,这些影像来自多种不同的成像模式。每个序列都已被标注,指示在十三个可能的血管位置之一是否存在动脉瘤。
-
train.csv (主要训练标签文件):每一行对应一个独立的影像序列。除了唯一标识符和基本信息外,它还包含了动脉瘤是否存在以及其具体位置的标签。
-
train_localizers.csv (动脉瘤定位数据):训练集中动脉瘤更精确的空间位置信息。注一个序列(Series)如果包含多个动脉瘤,则可能对应多行记录。
-
series/ 文件夹 (DICOM影像数据):训练集的原始DICOM影像序列。
-
segmentations/ 文件夹 (血管分割数据):DICOM序列所对应的血管分割图,以NifTI格式(.nii.gz)存储。
评价指标
本次竞赛采用一种加权的多标签ROC曲线下面积 进行评估。模型的预测目标不是一个,而是十四个相关的二分类标签:
-
其中一个标签是
Aneurysm Present(是否存在动脉瘤)。 -
另外十三个标签是具体的血管位置。
对于这十四个标签中的每一个,独立计算其AUC ROC 分数。AUC ROC是衡量模型区分正负样本能力的强大指标,值越接近1越好。计算最终得分时,不是简单地将十四个AUC分数平均。
优胜方案
第1名
> https://www.kaggle.com/competitions/rsna-intracranial-aneurysm-detection/writeups/1st-place-solution
> Training code: https://github.com/uchiyama33/rsna2025_1st_place
> Submission notebook: https://www.kaggle.com/code/tomoon33/rsna2025-submission-1st-place
核心思想非常清晰:不要在整个脑部影像中盲目地寻找小动脉瘤,而是先找到血管,再在血管上找动脉瘤。 这模仿了放射科医生的阅读逻辑,并利用了动脉瘤是血管壁病变这一先验知识。
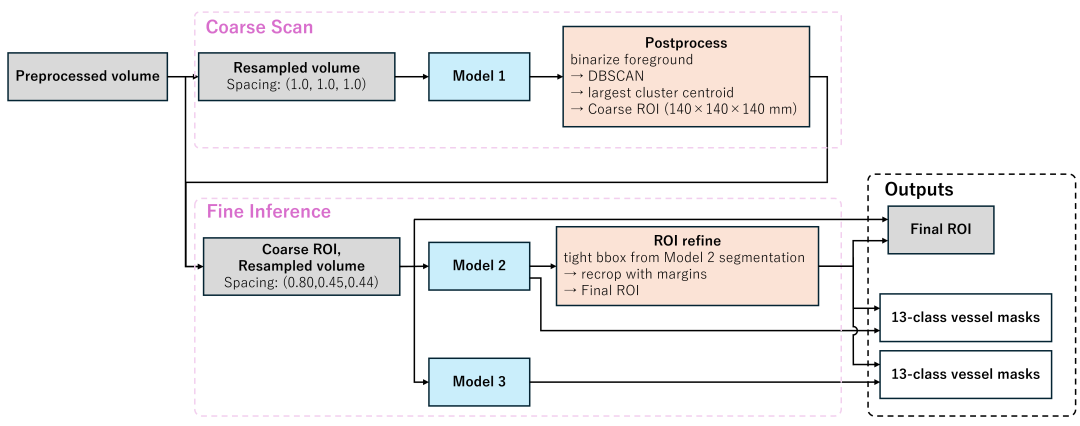
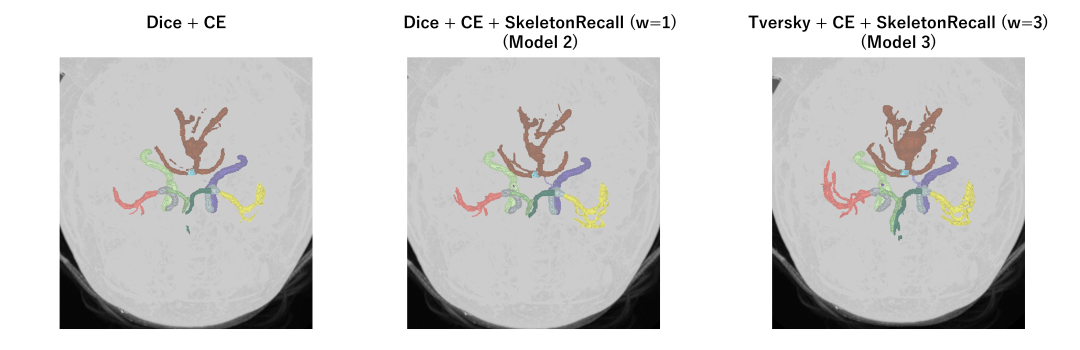
-
阶段一(血管分割与ROI提取):使用强大的分割模型精确勾勒出脑血管系统,并据此确定需要重点分析的区域。
-
阶段二(ROI分类):将注意力集中在血管区域,使用分类模型不仅判断有无动脉瘤,还精确预测其所在的13个具体解剖位置。
-
模型1(粗定位模型):
-
目的:快速、低分辨率地扫描整个脑部,找到血管的大致区域。
-
策略:使用较大的体素间距(1.0mm),将血管分为3个大类(后循环+基底动脉 / 大脑中动脉 / 其他)。输出后通过DBSCAN聚类去除散在的假阳性,并以最大簇的中心点裁剪出一个大的候选区域(140mm立方体)。这大大提升了后续步骤的效率。
-
-
模型2 & 模型3(精细分割模型):
-
目的:在粗定位的ROI内,进行高分辨率、精确的血管分割。
-
策略:使用更小的体素间距(约0.4-0.8mm)。
-
在训练时,让模型利用解码器特征去重建一个以动脉瘤标注点为中心的小球体。这强制模型学习动脉瘤本身的局部特征,而不仅仅是血管上下文。
-
血管区域掩码池化:对于13个位置标签中的每一个,使用对应的血管分割掩码(来自两个精细分割模型)在特征图上池化,提取出与该位置血管相关的特征向量。
-
位置感知Transformer:将这13个特征向量与一个全局特征向量拼接后,送入一个轻量级Transformer。这允许模型学习不同血管位置之间的关系(例如,前交通动脉的异常可能与大脑前动脉有关)。
-
独立MLP头:最终由独立的MLP为每个位置输出概率。
使用平衡BCE + Focal-Tversky++ 组合,专门处理极其稀疏的目标(小球体),并防止模型过度自信。辅助分割任务权重最高(1.0),分类任务权重较低(0.1和0.05)。
第2名
> https://www.kaggle.com/competitions/rsna-intracranial-aneurysm-detection/writeups/2nd-place-solution
> Training and inference code: https://github.com/PengchengShi1220/RSNA2025_Intracranial-Aneurysm-Detection
> Inference demo: https://www.kaggle.com/code/pengchengshi/bravecowcow-2nd-place-inference-demo
对于每个3D影像序列,在横断面、矢状面、冠状面三个轴向上,分别在其1/4、1/2和3/4位置各取一张2D切片。这样,每个序列仅用9张2D图像来代表。
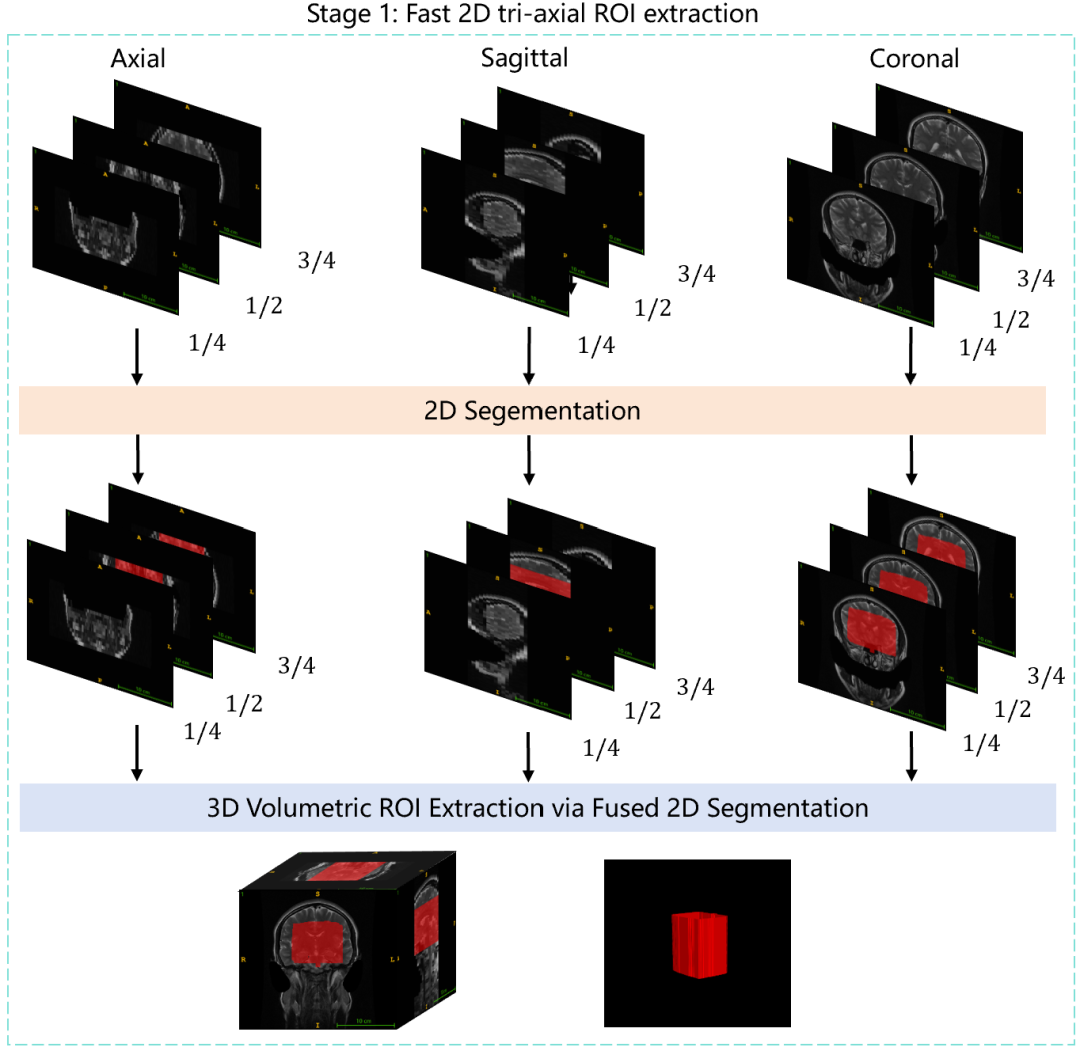
在获得ROI后,方案使用一个强大的3D nnU-Net模型同时进行多项任务,通过任务间的协同效应提升最终分类性能。基于nnU-Net 3D架构,并添加了多个任务头:
-
血管分割:分割出整个脑血管系统。
-
动脉瘤分割:分割出动脉瘤区域。
-
14分类头:预测13个位置和“动脉瘤存在”的主任务标签。
-
模态分类头(创新点):一个辅助任务头,用于预测图像的模态(CTA, MRA等)。这增强了模型的训练稳定性,迫使编码器学习与模态无关的通用特征。
对于正样本极少的类别,采用了过采样和在损失函数中赋予更高权重的策略,以平衡类别分布。此外并手动修正了官方标签中的一些错误,包括左右混淆、床突上/下颈内动脉位置错误等。这体现了高质量数据标注对于模型性能的至关重要。
第3名
> https://www.kaggle.com/competitions/rsna-intracranial-aneurysm-detection/writeups/3rd-place-solution
> Inference code: https://www.kaggle.com/code/tamotamo/rsna2025-3rd-place-inference
用了动脉瘤在轴向平面的XY坐标上相对一致的先验知识。将3D体积数据沿矢状面和冠状面方向分别进行最大强度投影,生成两张2D图像。使用YOLOv8(n和m型号)在这两张投影图上检测血管区域。该方法在验证集上取得了超过0.95的mAP@0.5,非常高效且准确。
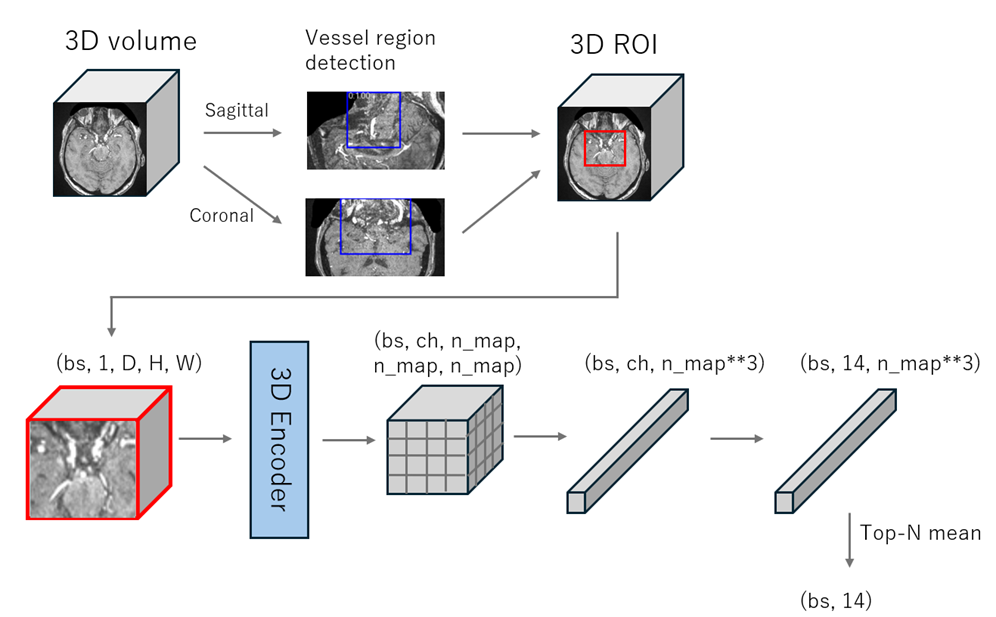
在获得高质量的血管ROI后,团队训练3D分类模型来预测最终的14个标签。
-
主干网络:使用 3D ResNet-18(通过
timm-3d库实现),结构简洁。 -
输入尺寸:探索了从128到224的不同输入尺寸,发现增大输入尺寸和特征图尺寸能直接提升分数(从0.77提升至0.81)。
-
分类头:在特征图的每个空间位置上都连接了一个14分类头,而不是对整个特征图做全局平均池化后再分类。
-
损失函数:使用加权的二元交叉熵损失来处理多标签分类和类别不平衡问题。
第4名
https://www.kaggle.com/competitions/rsna-intracranial-aneurysm-detection/writeups/4th-place-solution
第四名方案的核心思想是绕过复杂且耗时的3D分割,采用一个高效的回归模型来定位血管区域,然后使用一个先进的2D/2.5D分类模型在裁剪后的图像上进行端到端的分类。方案证明了,即使在时间紧迫的情况下,通过精妙的管道设计和模型选择,也能取得顶尖的成绩。
使用 DINOv3 ViT,这是一个在大量数据上预训练的、具有强大特征提取能力的视觉Transformer。从每个患者的3D体积中,等间距地抽取48张切片,形成一个 48x1x128x128 的输入体积。这相当于对3D信息进行了高度压缩的采样。
第5名
https://www.kaggle.com/competitions/rsna-intracranial-aneurysm-detection/writeups/5th-place-solution
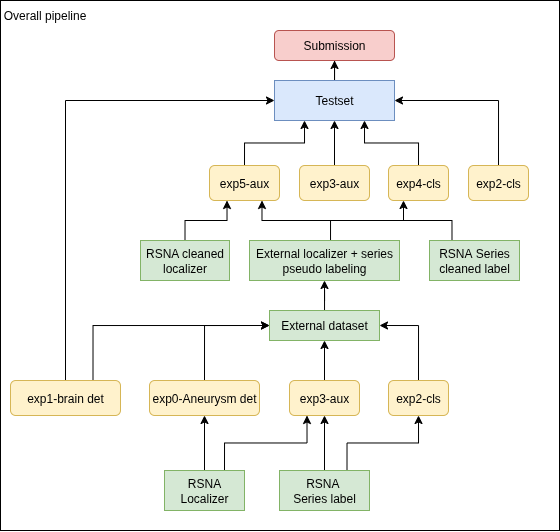
将3D医学影像问题分解为一系列2D计算机视觉任务。通过目标检测来定位目标和减少背景干扰,然后使用强大的2D分类模型进行预测,最后通过集成和伪标签策略进一步提升性能。
-
2.5D图像构建:为每张切片融合其相邻切片,以提供空间上下文。
-
动脉瘤检测:使用YOLO模型在图像级别检测动脉瘤。
-
大脑检测:使用YOLO模型裁剪掉无关背景(如肺部)。
-
分类与分割模型:训练多个模型进行最终的分类预测。
-
外部数据与数据清洗:利用外部数据和模型预测来清洗和扩充训练集。
-
模型集成:融合多个模型的预测结果。
对于每一张中心切片,将其前一张和后一张切片作为通道进行堆叠,形成3通道的2.5D输入。这为模型提供了基本的空间连续性信息。在水平翻转图像的同时,同步交换所有左右对称的血管位置标签。这是一个简单但有效的策略,明确地教会了模型解剖学对称性,带来了约0.01的性能提升。
训练5折的 YOLOv11x 模型,区分 aneurysm (CTA, MRA, T1post) 和 aneurysm_mri_t2 (T2)。将每个序列的所有切片平均成一张图像,然后手动标注大脑区域,训练一个 YOLOv5n 模型进行检测。主任务是14分类,辅助任务是利用实验0生成的动脉瘤边界框作为掩码,进行分割。
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 17
17 0
0- 0



 已为社区贡献148条内容
已为社区贡献148条内容

所有评论(0)