【每日文献阅读】HIDDEN MARKOV MODELS FOR RADAR PULSE TRAIN ANALYSIS IN ELECTRONIC WARFARE
本文提出一种用于电子战中雷达脉冲序列分析的新方法。针对复杂脉冲模式提取问题,本文提出一种替代传统到达时间(Time-Of-Arrival, TOA)直方图技术的方案:推导雷达字模板的隐马尔可夫模型(Hidden Markov Model, HMM),并开发改进版维特比(Viterbi)算法,从含噪声干扰的脉冲序列中提取雷达字。本文论证了该方法相较于标准TOA直方图技术的优势,并通过计算机仿真结果验
HIDDEN MARKOV MODELS FOR RADAR PULSE TRAIN ANALYSIS IN ELECTRONIC WARFARE
Nikita Visnevski, Simon Haykin, Vikram Krishnamurthy
McMaster University 1280 Main Street West Hamilton, ON, L8S 4K1, Canada
Fred A. Dilkes, Pierre Lavoie
Defence R&D Canada 3701 Carling Avenue Ottawa, ON, K1A 0Z4, Canada
摘要
本文提出一种用于电子战中雷达脉冲序列分析的新方法。针对复杂脉冲模式提取问题,本文提出一种替代传统到达时间(Time-Of-Arrival, TOA)直方图技术的方案:推导雷达字模板的隐马尔可夫模型(Hidden Markov Model, HMM),并开发改进版维特比(Viterbi)算法,从含噪声干扰的脉冲序列中提取雷达字。本文论证了该方法相较于标准TOA直方图技术的优势,并通过计算机仿真结果验证了算法的有效性。
1. 引言与问题陈述
本文提出一种用于防御性电子战(Electronic Warfare, EW)套件中雷达电子支援(Electronic Support, ES)系统的雷达脉冲序列分析新方法。电子支援(ES)的目标是收集并分析潜在敌方雷达信号,基于该信息的响应措施多样,既可以是向操作员发出简单警报,也可以启动软杀伤或硬杀伤对抗措施(电子战领域综述参见[1])。具体而言,电子支援系统需仅通过接收信号,解读战术态势,包括雷达辐射源的类型及威胁等级。
该任务面临的一大核心难点是军用雷达系统使用的重叠射频(RF)信道:不同辐射源的信号难以直接区分,需通过解交织处理转化为可关联至特定辐射源的航迹[2]。此外,还需利用电子情报(Electronic Intelligence, ELINT)数据库中存储的数据,对这些航迹进行分类并识别其对应的辐射源类型。电磁波到达方向、载波频率及脉冲序列结构等参数,均是该决策过程的关键输入变量。在识别出辐射源并完成脉冲解交织后,还需估计雷达的工作状态,进而判断其相关威胁等级。这为决策理论、估计理论及离散事件系统技术的应用提供了广阔空间,本文提出的方法则针对雷达信号中编码的雷达状态检测与估计相关问题展开研究。
电子支援系统的重要目标之一是评估潜在敌方雷达的威胁等级[1]。通常,威胁等级与雷达的广义工作状态(搜索、截获、跟踪或导弹制导)密切相关。边扫描边跟踪(Track-While-Scan, TWS)雷达与多功能雷达(Multi-Function Radars, MFRs)可同时执行针对多个目标的多项功能,因此评估这类雷达的威胁等级是电子支援系统最具挑战性的任务之一。文献[3]首次提出将隐马尔可夫模型(HMM)用于该场景下的雷达信号描述;在文献[4]中,我们构建了多功能雷达(MFR)的数学模型,并提出一种最优状态估计算法,用于从观测数据中推断雷达状态。研究表明,将多功能雷达辐射源信号的数据组织划分为两个层级(脉冲级与字级)具有显著便利性:雷达字可定义为多功能雷达在不同工作状态下发射的、静态或动态变化的脉冲组。识别这类脉冲组有助于更准确地评估雷达状态及威胁等级,因此电子支援系统脉冲序列分析的核心任务之一便是雷达字识别——即从电子支援系统在噪声环境下记录的失真脉冲序列中提取雷达字。图1展示了两种不同样本雷达辐射源的字脉冲结构,其详细规格参见附录A。
从观测脉冲流中提取多功能雷达(MFR)字序列是一项复杂的模式识别问题,解决该问题需应对以下几方面难点:
- 雷达脉冲通过随机非平稳环境观测获得,且环境特性可能未知;
- 解交织算法可能无法正确分离不同脉冲源,例如某一辐射源的脉冲可能“泄漏”到主要关联另一辐射源的航迹中;
- 由于电子支援接收机与雷达之间缺乏同步,观测脉冲序列存在量化失真。
前两类问题可建模为不同形式的电磁脉冲传播信道:对于第1类问题,简单的二进制信道或二进制删除信道模型已足够;对于解交织混淆效应的模拟,则可采用马尔可夫调制信道等更复杂的信道模型。本文仅考虑二进制信道模型,其中雷达发射的脉冲存在丢失概率pmissp_{miss}pmiss(即在特定量化时刻,若雷达本应发射脉冲,则该脉冲未被检测到的概率),同时存在虚假脉冲引入概率pspurp_{spur}pspur(即在特定量化时刻,若雷达未发射脉冲,则检测到虚假脉冲的概率)。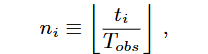
量化失真源于电子支援系统(ES)特定硬件实现的细节。通常,脉冲序列量化过程由观测时钟控制,其周期记为TobsT_{obs}Tobs。理想同步脉冲量化模型定义如下:设tit_iti为接收脉冲的相对到达时间(TOA),nin_ini为对应的量化索引,则同步量化模型满足相关表达式)。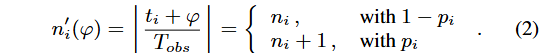
在实际场景中,由于雷达与电子支援系统之间的异步特性,脉冲量化模型需引入均匀分布的随机相位φ∈[0,Tobs)\varphi \in [0, T_{obs})φ∈[0,Tobs),此时新的量化索引是随机相位φ\varphiφ的函数,且pip_ipi为脉冲分裂概率,其中:
pi≡tiTobs−ni(3) p_i \equiv \frac{t_i}{T_{obs}} - n_i \tag{3} pi≡Tobsti−ni(3)
传统电子支援系统(ES)中用于脉冲序列分析的算法,均基于到达时间差(Time-Difference-Of-Arrival)直方图,具体包括自相关直方图[2]与互相关直方图[5]两类。这类算法结构简单、计算效率高,但对于图1所示的高度结构化脉冲序列,其性能无法满足需求(参见[6])。在后续章节中,本文将提出一种基于隐马尔可夫模型(HMM)理论的算法,可成功解决从解交织后的多功能雷达(MFR)脉冲序列中提取字序列的问题,并通过针对图1所示雷达字生成的合成数据验证算法性能。与传统脉冲序列分析算法不同,所提算法的性能随字脉冲模式复杂度的提高而提升。
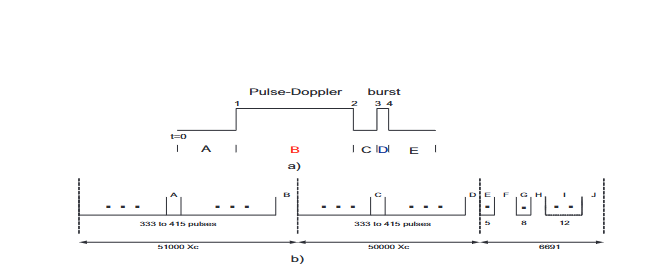
图1 多功能雷达字示例
2. 作为雷达字模板的隐马尔可夫模型
本节推导雷达字模板的统计模型。雷达输出可在由式(2)定义的量化时域内表示。根据文献[3],在任意量化时刻,脉冲的存在或缺失可分别用二进制序列中的“1”或“0”表示。在量化时域中,“单个脉冲+死区时间”可视为任意雷达脉冲序列的基本构成单元,该单元可通过图2所示的马尔可夫链表示。对于第kkk个雷达字内第iii个脉冲间隔的马尔可夫链,其转移矩阵形式为: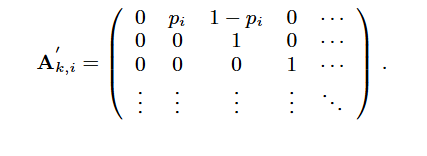
我们将该结构称为原子马尔可夫链。由于转移矩阵具有上对角线结构,该马尔可夫链属于左到右马尔可夫链[7]。此外,几乎所有非零转移概率均为1,唯一例外是从初始状态的转移——该转移概率遵循式(3)定义的脉冲重复间隔(PRI)分布。
雷达发射的任意脉冲序列均可通过连接适量原子马尔可夫链(式4)表示。通过连接这些原子链,可设计任意复杂度的雷达字模型(包括图1所示模型)。第kkk个雷达字模板的复合马尔可夫链转移概率矩阵AkA_kAk具有如式(5)所示的形式,其中pip_ipi的定义如式(3)。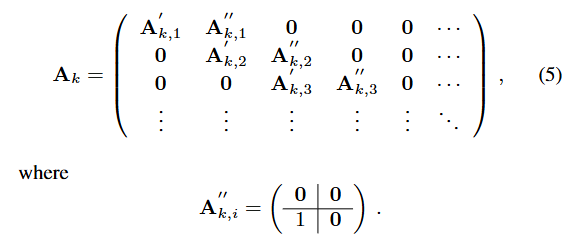
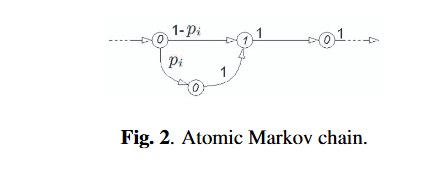
图2 原子马尔可夫链
结合第1节讨论的电子支援系统(ES)二进制信道观测模型,定义脉冲丢失概率为pmissp_{miss}pmiss、虚假脉冲概率为pspurp_{spur}pspur,可得到雷达字模板的隐马尔可夫模型(HMM),其形式如文献[7]所定义:λk=(Ak,Bk,πk)\lambda_k = (A_k, B_k, \pi_k)λk=(Ak,Bk,πk)。其中,BkB_kBk为观测概率矩阵,定义如下:
Bk=(1−pspurpspur1−pspurpspurpmiss1−pmiss1−pspurpspur⋮⋮) B_k = \begin{pmatrix} 1-p_{spur} & p_{spur} \\ 1-p_{spur} & p_{spur} \\ p_{miss} & 1-p_{miss} \\ 1-p_{spur} & p_{spur} \\ \vdots & \vdots \end{pmatrix} Bk=
1−pspur1−pspurpmiss1−pspur⋮pspurpspur1−pmisspspur⋮
πk\pi_kπk为初始状态概率分布,定义为πk≡(1,0,0,0,⋯ )T\pi_k \equiv (1, 0, 0, 0, \cdots)^Tπk≡(1,0,0,0,⋯)T。
3. 用于字提取的维特比算法
基于第2节提出的雷达字模板隐马尔可夫模型(HMM),从含噪声脉冲序列中提取雷达字的问题,等价于在维特比意义下对脉冲序列进行“打分”的问题(详细过程参见[7])。因此,字提取算法包括以下步骤:
- 为每个雷达辐射源字kkk构建隐马尔可夫模型(HMM)模板λk=(Ak,Bk,πk)\lambda_k = (A_k, B_k, \pi_k)λk=(Ak,Bk,πk);
- 按文献[7]所述方法,计算每个字模板的维特比对数得分;
- 维特比对数得分的相对峰值对应量化脉冲序列中雷达字的候选起始时刻;
- 按文献[7]所述执行维特比回溯过程,得到最可能的单个脉冲标签分布,从而区分“来自雷达的真实脉冲”“需判定为虚假的脉冲”及“丢失的脉冲”。
标准维特比算法的计算复杂度为O[LMk2]O[L M_k^2]O[LMk2][7],其中LLL为量化脉冲序列的长度,MkM_kMk为隐马尔可夫模型(HMM)字模板λk\lambda_kλk的状态数。对于实际雷达系统,HMM字模板的状态数可高达数十万:电子支援系统(ES)的量化精度越高(即观测时钟周期TobsT_{obs}Tobs越小),状态数MkM_kMk越大。然而,通过充分利用问题的结构特性,可设计一种改进版维特比算法,其计算复杂度上限降至O[(Np×D)(Mk×Wk)]O[(N_p \times D)(M_k \times W_k)]O[(Np×D)(Mk×Wk)]。其中,Np≪LN_p \ll LNp≪L为观测雷达序列中的脉冲数,DDD和WkW_kWk为下文将讨论的常数。最重要的是,改进版维特比算法的计算复杂度随MkM_kMk的增长呈线性变化。
降低“打分”过程计算复杂度的关键观察如下:仅在量化脉冲序列中存在脉冲的位置,得分值才具有实际意义,需进行计算。观测序列的总长度为LLL,但其中仅含NpN_pNp个非零元素(即实际观测到的脉冲)。尽管LLL和NpN_pNp均随TobsT_{obs}Tobs减小而增大,但观测脉冲数NpN_pNp与TobsT_{obs}Tobs无关。然而,该技术存在一个局限:若字序列的前几个脉冲在观测序列中丢失,则整个字可能无法被检测到。解决该问题的一种可行方案是在打分算法中引入“深度为DDD的回溯”:对观测序列中的每个脉冲,计算DDD个得分值。对于二进制信道,连续丢失多个脉冲的概率呈指数下降,因此可选择合适的DDD,使该概率降至特定容忍阈值以下,此时算法复杂度上限变为O[(Np×D)Mk2]O[(N_p \times D) M_k^2]O[(Np×D)Mk2]。
维特比算法复杂度的最大降幅源于对转移概率矩阵AkA_kAk高度稀疏特性的利用。图3(a)和(b)展示了如何利用该特性减少维特比算法的路径数量:假设存在图3(a)所示的HMM字模板,图3(b)为该HMM所有可能转移的格形图。图中每行代表HMM的连续状态编号(1-16),每列代表维特比算法的量化时间步(0-15)。格形图中的最短路径(对应时间步11到达状态16)表示观测序列中无脉冲分裂的情况;最长路径(对应时间步15到达状态16)表示观测序列中每个脉冲均发生分裂的情况。定义Wk=15−11=4W_k = 15 - 11 = 4Wk=15−11=4为维特比格形图“对角带”的最大宽度,通常Wk=W(λk)W_k = W(\lambda_k)Wk=W(λk)是模板结构的显式函数,其上限为字序列中的总脉冲数。显然,改进版算法的计算复杂度O[(Np×D)(Mk×Wk)]≪O[LMk2]O[(N_p \times D)(M_k \times W_k)] \ll O[L M_k^2]O[(Np×D)(Mk×Wk)]≪O[LMk2]。
在实际场景中,格形图中的最短路径与最长路径均不成立。事实上,真实雷达字模板具有固定持续时间(例如图1(b)所示),该持续时间在量化域内可通过式(1)计算。因此,有效路径位于最短路径与最长路径之间,且对每个字模板唯一。以图3为例,若量化字持续时间为13,则图3(b)中灰色虚线所示的所有路径均为无效路径,需剔除——这约可减少一半的路径数量。对于状态数高达数十万的HMM字模板,该优化可显著提升算法性能。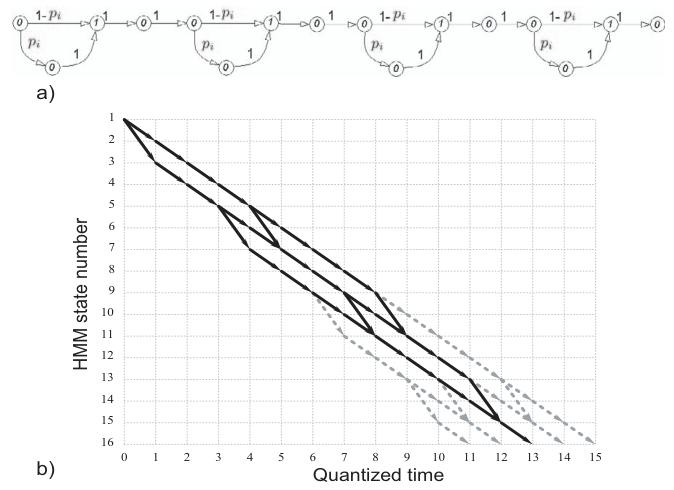
图3 维特比算法的格形图路径示例
(a)HMM状态编号;(b)量化时间步与路径分布
4. 仿真结果
本节展示针对图1所示字结构雷达辐射源的仿真结果(字结构详细说明参见附录A)。实验过程如下:生成这些辐射源的合成字序列,加入不同程度的噪声干扰,再利用第3节提出的维特比算法对数据进行打分与字提取。
图4(a)展示了具有图1(a)所示字结构的雷达辐射源产生的约35ms数据的分析结果。此处观测时钟周期Tobs=1.1μsT_{obs}=1.1 \mu sTobs=1.1μs,约20%的雷达脉冲被丢失,虚假脉冲率设置为6000个/秒。图4(a)的上图为维特比得分曲线,下图为从得分曲线中提取的字序列。辐射源字及其对应得分采用颜色编码:字W1、W3、W5、W6、W7分别用红色、蓝色、粉色、黑色和绿色表示。本实验中仅检测到上述辐射源字,且每个字的得分在其序列起始位置均出现明显峰值,提取的字序列与雷达实际发射的序列完全一致。
该辐射源采用时分复用方式实现多目标搜索与跟踪,其发射信号以“4个连续字为一个块”的形式组织,每个字对应跟踪序列或搜索模式。在图4(a)中,该辐射源首先通过“W7-W7-W7-W7”块跟踪第一个目标,随后通过“W1-W6-W6-W6”块跟踪第二个目标,接下来的3个块(共12个字)采用另一类模式搜索新增目标,之后再次通过“W7-W7-W7-W7”块回到对第一个目标的跟踪——整个5块模式循环重复(含微小变化)。该图表明,仅通过提取并识别雷达脉冲序列中编码的字序列,即可获取潜在敌方雷达辐射源的大量状态信息。
图4(b)展示了具有图1(b)所示字结构的雷达辐射源产生的约17ms数据的分析结果。该雷达辐射源仅含5个有效字,但实验中将图1(b)所示的终止符、段间死区时间以及偶尔出现的雷达静默期(已知时长内无任何脉冲发射的时段)均视为独立字,因此总处理字数量为8。本示例中雷达处于目标截获状态,提取的字序列与预期结果几乎完全一致。仅在约4.2ms处,由于观测序列中出现局部噪声爆发,算法未能检测到字W8,导致字序列器无法做出可靠判决。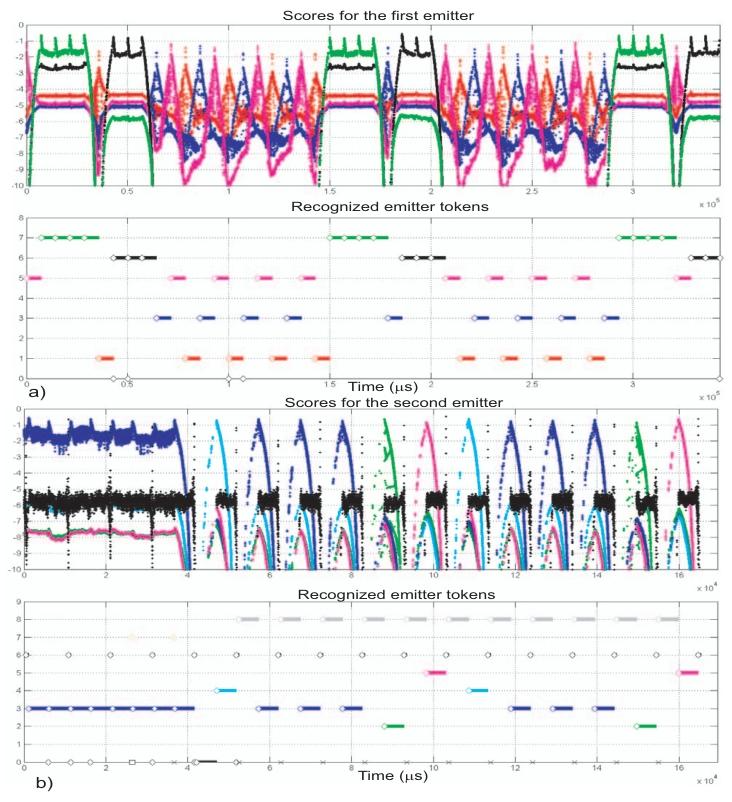
图4 维特比得分仿真结果
(a)图1(a)所示雷达字的提取序列;(b)图1(b)所示雷达字的提取序列
5. 结论
本文提出一种用于电子支援(ES)系统脉冲序列分析的新方法,解决了电子战中的一项难题——分析多功能雷达(MFR)辐射源产生的高度结构化脉冲序列,以提取与雷达状态相关的雷达字序列。据我们所知,目前公开的雷达信号处理文献中,尚未有针对该问题的完整解决方案。
该方法的核心是雷达字模板的新型隐马尔可夫模型(HMM)统计模型,仿真结果验证了其有效性。由于隐马尔可夫模型具有动态特性,所提方法可适用于更广泛类别的多功能雷达(MFR)——这类雷达的字序列可能是“灵活实体”,其脉冲表示形式可动态变化且依赖于所处上下文。此外,该方法可作为文献[4]中提出的雷达状态估计算法的“脉冲序列分析模块”,为雷达状态估计问题提供完整解决方案。
附录A:雷达字规格
图1展示了用于演示的两种不同雷达辐射源的字脉冲结构,具体规格如下:
辐射源1(图1(a))
该辐射源包含9个雷达字(W1-W9),所有字均具有相同的脉冲包络。该包络结构可划分为5个不同区段(A至E):
- 区段A、C、E:已知时长的死区时间,此期间辐射源不发射脉冲;
- 区段B:固定脉冲重复间隔(PRI)的脉冲多普勒分量,9个雷达字通过该区段不同的PRI值区分;
- 区段D:包含12个脉冲,其PRI标称固定。
其中,区段B中所有脉冲多普勒分量的PRI均小于100μs,区段D中脉冲的PRI约为4μs。
辐射源2(图1(b))
该辐射源的字序列规模更小,包含4个有效字(W1-W4)和1个空白字(W5,即在指定时长内不发射任何脉冲)。其字序列以“字对”形式发射,每个字对后跟随一个短终止符。图1(b)展示了该脉冲序列的3个固定长度分量:
- 第一个分量:51000个晶体时钟计数(晶体时钟周期Xc≈0.095μsX_c \approx 0.095 \mu sXc≈0.095μs);
- 第二个分量:50000个晶体时钟计数;
- 终止符:6691个晶体时钟计数。
根据指定字对的不同,区段A和C各包含333-415个脉冲,且分别跟随可变长度的死区时间(区段B和D)。所有雷达状态的终止符结构一致,包含3组脉冲(E、G、I)和3个固定时长的死区时间(F、H、J):其中E、G、I组分别包含5个、8个和12个固定PRI脉冲,F、H、J为固定时长的死区。
Viterbi算法原理详解
Viterbi算法是由美国科学家Andrew Viterbi于1967年提出的一种动态规划算法,核心用于解决隐马尔可夫模型(Hidden Markov Model, HMM)的“状态解码”问题——即已知观测序列和HMM模型参数,找到与观测序列最匹配的“隐藏状态序列”。该算法凭借“最优子结构”和“无后效性”的动态规划思想,大幅降低了暴力搜索的复杂度,广泛应用于通信、语音识别、雷达信号处理(如前文雷达字提取)、生物信息学(如基因序列分析)等领域。
一、算法的前置基础:隐马尔可夫模型(HMM)
Viterbi算法是为HMM量身设计的,需先明确HMM的核心假设与三要素,这是理解Viterbi原理的前提。
1. HMM的核心假设
HMM基于两个关键假设,确保算法可解:
- 齐次马尔可夫性:任意时刻的隐藏状态仅依赖于前一时刻的隐藏状态,与更早的状态或观测无关,即
P(st∣st−1,st−2,...,s1,o1,...,ot)=P(st∣st−1)P(s_t | s_{t-1}, s_{t-2}, ..., s_1, o_1, ..., o_t) = P(s_t | s_{t-1})P(st∣st−1,st−2,...,s1,o1,...,ot)=P(st∣st−1)(sts_tst为时刻ttt的隐藏状态,oto_tot为时刻ttt的观测)。 - 观测独立性:任意时刻的观测仅依赖于当前时刻的隐藏状态,与其他状态或观测无关,即
P(ot∣st,st−1,...,s1,o1,...,ot−1)=P(ot∣st)P(o_t | s_t, s_{t-1}, ..., s_1, o_1, ..., o_{t-1}) = P(o_t | s_t)P(ot∣st,st−1,...,s1,o1,...,ot−1)=P(ot∣st)。
2. HMM的三要素
Viterbi算法需已知HMM的三个核心参数(通常记为λ=(A,B,π)\lambda=(A, B, \pi)λ=(A,B,π)):
- 状态转移概率矩阵AAA:Aij=P(st=j∣st−1=i)A_{ij} = P(s_t = j | s_{t-1} = i)Aij=P(st=j∣st−1=i),表示从时刻t−1t-1t−1的状态iii转移到时刻ttt的状态jjj的概率(NNN个状态则AAA为N×NN×NN×N矩阵)。
- 观测概率矩阵BBB:Bjk=P(ot=k∣st=j)B_{jk} = P(o_t = k | s_t = j)Bjk=P(ot=k∣st=j),表示状态jjj生成观测kkk的概率(MMM个观测则BBB为N×MN×MN×M矩阵)。
- 初始状态分布π\piπ:πi=P(s1=i)\pi_i = P(s_1 = i)πi=P(s1=i),表示初始时刻(t=1t=1t=1)处于状态iii的概率。
二、Viterbi算法的核心思想
Viterbi算法的本质是**“分阶段保留最优路径”**:将“寻找整个观测序列的最优隐藏状态序列”分解为“每个时刻每个状态的最优子路径”问题,通过动态规划避免重复计算。
关键逻辑:
对于时刻ttt的每个隐藏状态jjj,仅需保留“从初始时刻到ttt时刻到达状态jjj的最优路径”(即概率最大的路径)。因为根据马尔可夫性,后续时刻的最优路径必然基于当前时刻的最优子路径,非最优子路径可直接“剪枝”,无需后续计算。
三、Viterbi算法的四步流程
设观测序列长度为TTT(o1,o2,...,oTo_1, o_2, ..., o_To1,o2,...,oT),隐藏状态数为NNN,算法分初始化、递推、终止、回溯四步完成。
1. 定义关键变量
为实现动态规划,需定义两个核心变量:
- 累积概率δt(j)\delta_t(j)δt(j):从初始时刻(t=1t=1t=1)到时刻ttt,到达隐藏状态jjj且匹配前ttt个观测的最优路径概率(即所有可能路径中概率最大的值)。
- 路径记录ψt(j)\psi_t(j)ψt(j):记录δt(j)\delta_t(j)δt(j)对应的“前一时刻的最优状态”(即时刻t−1t-1t−1的哪个状态iii能使路径概率最大),用于后续回溯完整路径。
2. 步骤1:初始化(t=1t=1t=1)
初始时刻仅需结合“初始状态分布π\piπ”和“第一个观测的观测概率BBB”,计算每个状态的初始累积概率:
δ1(j)=πj⋅Bj,o1(j=1,2,...,N)\delta_1(j) = \pi_j \cdot B_{j, o_1} \quad (j=1, 2, ..., N)δ1(j)=πj⋅Bj,o1(j=1,2,...,N)
(o1o_1o1为第一个观测的索引,Bj,o1B_{j, o_1}Bj,o1即状态jjj生成o1o_1o1的概率)
路径记录初始化为空(或标记为−1-1−1),因t=1t=1t=1无前置状态:
ψ1(j)=−1(j=1,2,...,N)\psi_1(j) = -1 \quad (j=1, 2, ..., N)ψ1(j)=−1(j=1,2,...,N)
3. 步骤2:递推(t=2,3,...,Tt=2, 3, ..., Tt=2,3,...,T)
递推是算法的核心,通过“前一时刻所有状态的最优路径”计算当前时刻的最优路径。
对于时刻ttt的每个状态jjj,δt(j)\delta_t(j)δt(j)需遍历时刻t−1t-1t−1的所有状态iii,找到“从iii转移到jjj且匹配观测oto_tot”的最大概率:
δt(j)=maxi=1..N[δt−1(i)⋅Aij]⋅Bj,ot\delta_t(j) = \max_{i=1..N} \left[ \delta_{t-1}(i) \cdot A_{ij} \right] \cdot B_{j, o_t}δt(j)=i=1..Nmax[δt−1(i)⋅Aij]⋅Bj,ot
同时记录该最大概率对应的前一状态iii,更新路径记录:
ψt(j)=argmaxi=1..N[δt−1(i)⋅Aij]\psi_t(j) = \arg\max_{i=1..N} \left[ \delta_{t-1}(i) \cdot A_{ij} \right]ψt(j)=argi=1..Nmax[δt−1(i)⋅Aij]
直观理解:要到达ttt时刻的状态jjj,需先找到t−1t-1t−1时刻“最可能的前序状态iii”,再乘以从iii到jjj的转移概率和jjj生成oto_tot的观测概率,即为当前最优路径概率。
4. 步骤3:终止(t=Tt=Tt=T)
当处理完最后一个观测(t=Tt=Tt=T)后,最优状态序列的终点是累积概率最大的状态:
sT∗=argmaxj=1..N[δT(j)]s_T^* = \arg\max_{j=1..N} \left[ \delta_T(j) \right]sT∗=argj=1..Nmax[δT(j)]
此时δT(sT∗)\delta_T(s_T^*)δT(sT∗)即为“整个观测序列对应的最优状态序列的总概率”。
5. 步骤4:回溯(从t=Tt=Tt=T到t=1t=1t=1)
通过路径记录ψ\psiψ反向推导完整的最优状态序列:
从终点sT∗s_T^*sT∗开始,依次计算前一时刻的最优状态:
st∗=ψt+1(st+1∗)(t=T−1,T−2,...,1)s_t^* = \psi_{t+1}(s_{t+1}^*) \quad (t=T-1, T-2, ..., 1)st∗=ψt+1(st+1∗)(t=T−1,T−2,...,1)
最终将回溯得到的序列反转(从t=1t=1t=1到t=Tt=Tt=T),即为与观测序列最匹配的隐藏状态序列。
四、实例演示:简化的天气-活动HMM
通过一个简单案例直观理解算法流程,假设:
- 隐藏状态:N=2N=2N=2(1=晴天,2=雨天)。
- 观测:M=3M=3M=3(1=散步,2=购物,3=在家)。
- HMM参数:
A=[0.80.20.30.7]A = \begin{bmatrix} 0.8 & 0.2 \\ 0.3 & 0.7 \end{bmatrix}A=[0.80.30.20.7](晴天→晴天概率0.8,晴天→雨天0.2;雨天→晴天0.3,雨天→雨天0.7),
B=[0.60.30.10.10.40.5]B = \begin{bmatrix} 0.6 & 0.3 & 0.1 \\ 0.1 & 0.4 & 0.5 \end{bmatrix}B=[0.60.10.30.40.10.5](晴天→散步0.6,晴天→购物0.3,晴天→在家0.1;雨天同理),
π=[0.6,0.4]\pi = [0.6, 0.4]π=[0.6,0.4](初始晴天概率0.6,雨天0.4)。 - 观测序列:o1=1o_1=1o1=1(散步),o2=3o_2=3o2=3(在家),o3=2o_3=2o3=2(购物)(即T=3T=3T=3)。
1. 初始化(t=1t=1t=1,观测o1=1o_1=1o1=1)
δ1(1)=π1⋅B1,1=0.6×0.6=0.36\delta_1(1) = \pi_1 \cdot B_{1,1} = 0.6 \times 0.6 = 0.36δ1(1)=π1⋅B1,1=0.6×0.6=0.36
δ1(2)=π2⋅B2,1=0.4×0.1=0.04\delta_1(2) = \pi_2 \cdot B_{2,1} = 0.4 \times 0.1 = 0.04δ1(2)=π2⋅B2,1=0.4×0.1=0.04
ψ1(1)=ψ1(2)=−1\psi_1(1)=\psi_1(2)=-1ψ1(1)=ψ1(2)=−1。
2. 递推(t=2t=2t=2,观测o2=3o_2=3o2=3)
-
计算δ2(1)\delta_2(1)δ2(1)(t=2t=2t=2状态1=晴天):
遍历t=1t=1t=1的状态1和2:
δ1(1)⋅A11=0.36×0.8=0.288\delta_1(1) \cdot A_{11} = 0.36 \times 0.8 = 0.288δ1(1)⋅A11=0.36×0.8=0.288,δ1(2)⋅A21=0.04×0.3=0.012\delta_1(2) \cdot A_{21} = 0.04 \times 0.3 = 0.012δ1(2)⋅A21=0.04×0.3=0.012,
最大值为0.2880.2880.288,故δ2(1)=0.288×B1,3=0.288×0.1=0.0288\delta_2(1) = 0.288 \times B_{1,3} = 0.288 \times 0.1 = 0.0288δ2(1)=0.288×B1,3=0.288×0.1=0.0288,
ψ2(1)=argmax(0.288,0.012)=1\psi_2(1) = \arg\max(0.288, 0.012) = 1ψ2(1)=argmax(0.288,0.012)=1(前一状态为1)。 -
计算δ2(2)\delta_2(2)δ2(2)(t=2t=2t=2状态2=雨天):
遍历t=1t=1t=1的状态1和2:
δ1(1)⋅A12=0.36×0.2=0.072\delta_1(1) \cdot A_{12} = 0.36 \times 0.2 = 0.072δ1(1)⋅A12=0.36×0.2=0.072,δ1(2)⋅A22=0.04×0.7=0.028\delta_1(2) \cdot A_{22} = 0.04 \times 0.7 = 0.028δ1(2)⋅A22=0.04×0.7=0.028,
最大值为0.0720.0720.072,故δ2(2)=0.072×B2,3=0.072×0.5=0.036\delta_2(2) = 0.072 \times B_{2,3} = 0.072 \times 0.5 = 0.036δ2(2)=0.072×B2,3=0.072×0.5=0.036,
ψ2(2)=argmax(0.072,0.028)=1\psi_2(2) = \arg\max(0.072, 0.028) = 1ψ2(2)=argmax(0.072,0.028)=1(前一状态为1)。
3. 递推(t=3t=3t=3,观测o3=2o_3=2o3=2)
-
计算δ3(1)\delta_3(1)δ3(1)(t=3t=3t=3状态1=晴天):
遍历t=2t=2t=2的状态1和2:
δ2(1)⋅A11=0.0288×0.8=0.02304\delta_2(1) \cdot A_{11} = 0.0288 \times 0.8 = 0.02304δ2(1)⋅A11=0.0288×0.8=0.02304,δ2(2)⋅A21=0.036×0.3=0.0108\delta_2(2) \cdot A_{21} = 0.036 \times 0.3 = 0.0108δ2(2)⋅A21=0.036×0.3=0.0108,
最大值为0.023040.023040.02304,故δ3(1)=0.02304×B1,2=0.02304×0.3=0.006912\delta_3(1) = 0.02304 \times B_{1,2} = 0.02304 \times 0.3 = 0.006912δ3(1)=0.02304×B1,2=0.02304×0.3=0.006912,
ψ3(1)=1\psi_3(1) = 1ψ3(1)=1(前一状态为1)。 -
计算δ3(2)\delta_3(2)δ3(2)(t=3t=3t=3状态2=雨天):
遍历t=2t=2t=2的状态1和2:
δ2(1)⋅A12=0.0288×0.2=0.00576\delta_2(1) \cdot A_{12} = 0.0288 \times 0.2 = 0.00576δ2(1)⋅A12=0.0288×0.2=0.00576,δ2(2)⋅A22=0.036×0.7=0.0252\delta_2(2) \cdot A_{22} = 0.036 \times 0.7 = 0.0252δ2(2)⋅A22=0.036×0.7=0.0252,
最大值为0.02520.02520.0252,故δ3(2)=0.0252×B2,2=0.0252×0.4=0.01008\delta_3(2) = 0.0252 \times B_{2,2} = 0.0252 \times 0.4 = 0.01008δ3(2)=0.0252×B2,2=0.0252×0.4=0.01008,
ψ3(2)=2\psi_3(2) = 2ψ3(2)=2(前一状态为2)。
4. 终止与回溯
- 终止:t=3t=3t=3时,δ3(1)=0.006912\delta_3(1)=0.006912δ3(1)=0.006912,δ3(2)=0.01008\delta_3(2)=0.01008δ3(2)=0.01008,故s3∗=2s_3^* = 2s3∗=2(雨天)。
- 回溯:
s2∗=ψ3(s3∗)=ψ3(2)=2s_2^* = \psi_3(s_3^*) = \psi_3(2) = 2s2∗=ψ3(s3∗)=ψ3(2)=2(t=2t=2t=2状态2=雨天),
s1∗=ψ2(s2∗)=ψ2(2)=1s_1^* = \psi_2(s_2^*) = \psi_2(2) = 1s1∗=ψ2(s2∗)=ψ2(2)=1(t=1t=1t=1状态1=晴天)。
最终最优状态序列:s1∗=1s_1^*=1s1∗=1(晴天)→ s2∗=2s_2^*=2s2∗=2(雨天)→ s3∗=2s_3^*=2s3∗=2(雨天),与观测序列“散步→在家→购物”最匹配。
五、算法复杂度与优势
1. 时间复杂度
设观测序列长度为TTT,隐藏状态数为NNN,则:
- 递推阶段:每个时刻ttt需遍历NNN个状态,每个状态需遍历NNN个前序状态,共T×N×NT×N×NT×N×N次计算;
- 终止与回溯:仅需O(N+T)O(N + T)O(N+T)次计算。
总时间复杂度为O(T×N2)O(T×N^2)O(T×N2),远低于暴力搜索的O(NT)O(N^T)O(NT)(暴力需枚举所有NTN^TNT种状态序列),尤其适合TTT较大的场景(如雷达长脉冲序列、语音信号)。
2. 核心优势
- 高效性:动态规划剪枝非最优路径,复杂度可控;
- 最优性:基于动态规划的最优子结构,确保找到全局最优状态序列;
- 通用性:适用于所有满足HMM假设的场景,如前文“雷达字提取”中,通过Viterbi找到“真实脉冲/虚假脉冲/丢失脉冲”的最优状态序列,实现噪声环境下的信号提取。
六、在雷达脉冲分析中的应用(结合前文论文)
在前文“电子战雷达脉冲序列分析”中,Viterbi算法的作用的是从含噪声的观测脉冲序列中提取雷达字:
- 隐藏状态:雷达脉冲的“真实存在”“虚假脉冲”“脉冲丢失”(对应HMM的状态);
- 观测序列:电子支援系统(ES)接收的量化脉冲序列(0=无脉冲,1=有脉冲);
- 算法目标:通过Viterbi找到最优隐藏状态序列,区分“真实雷达脉冲”与“噪声/虚假脉冲”,进而提取雷达字(雷达不同工作状态的脉冲组),最终推断雷达的威胁等级(搜索/跟踪/导弹制导)。
这正是Viterbi算法在工程中的典型应用——利用HMM建模动态信号,通过算法抵抗噪声干扰,实现结构化信号的提取与解码。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 22
22 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)