【大数据技术实战】全栈数据组件(优化・集成・规模・部署・业务落地)
全栈数据组件技术,覆盖消息(Kafka/RocketMQ 等)、计算(Flink/Fluss)、存储(Doris/Paimon)、调度与 AI 全链路。内含具体配置示例、集群规模规划、多部署方案(物理机 / 容器 / 云托管),结合电商、金融等场景提供落地指南。实操性强,适配不同业务需求与成本预算,是技术架构师、运维及数据开发工程师的组件选型与故障排查实用手册。

1. 前言
本文档覆盖全栈数据组件(消息、计算、存储、调度、AI)的核心原理、优化方案、集成配置、集群规模、部署方式,并结合电商、金融、零售等实际业务场景提供落地指南,适用于技术架构师、运维工程师、数据开发工程师,可作为组件选型、集群规划、故障排查的参考手册。
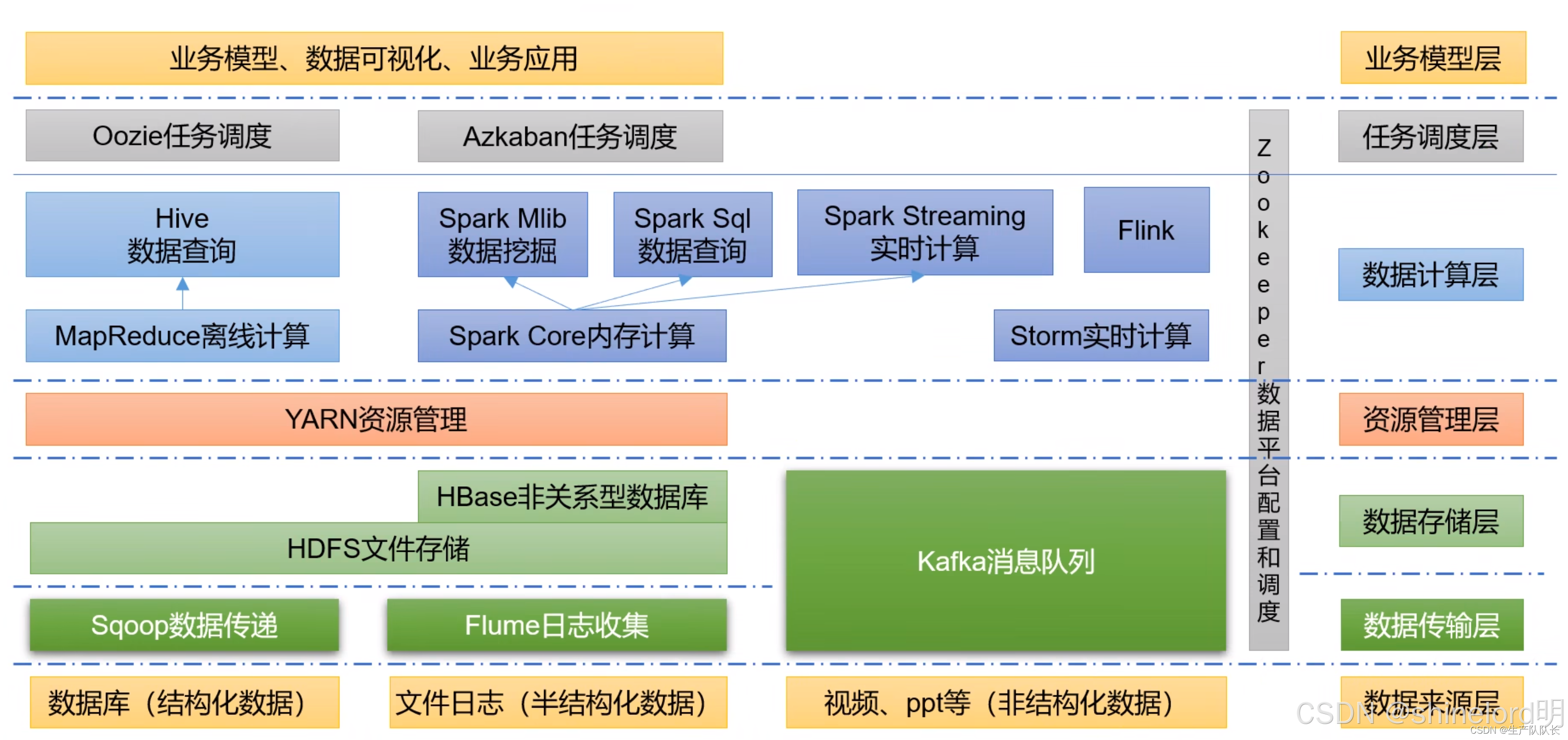
核心价值:
- 全组件覆盖:涵盖消息(Kafka/RabbitMQ/RocketMQ)、计算(Flink/Fluss)、存储(HDFS/Doris)、数据湖(Paimon)、调度(YARN)、AI(AIAgent)全链路;
- 实操性强:提供具体配置示例(代码块、配置文件)、规模参数(节点数、硬件配置)、部署步骤;
- 业务适配:基于业务重要性、延迟需求、成本预算提供组件选型与规模 / 部署决策方案。
2. 核心消息组件(Kafka/RabbitMQ/RocketMQ)
2.1 组件原理与特性对比
|
组件 |
核心架构 |
吞吐能力 |
延迟性能 |
可靠性保障 |
适用场景 |
|
Kafka |
分区日志存储 + 发布订阅(Broker/Producer/Consumer) |
百万级 / 秒 |
毫秒级(10-50ms) |
副本同步(ACK 机制)+ KRaft 元数据 |
高吞吐场景(日志采集、实时数据传输) |
|
RabbitMQ |
交换机 - 队列 - 绑定(Exchange/Queue/Binding) |
万级 / 秒 |
微秒级(1-10ms) |
消息 ACK + 死信队列(DLQ) |
低延迟场景(订单通知、即时通信) |
|
RocketMQ |
NameServer 路由 + Broker 存储(Master/Slave) |
十万级 / 秒 |
毫秒级(5-30ms) |
同步 / 异步刷盘 + 事务消息 |
高可靠场景(金融交易、分布式事务) |
2.2 优化方案(生产端 / 消费端 / 集群)
2.2.1 Kafka 优化
|
优化维度 |
原理 |
实操配置 |
适用场景 |
|
生产端 |
批量攒批 + 压缩减少 IO |
batch.size=32768(32KB)、linger.ms=5(延迟 5ms 攒批)、compression.type=snappy |
高吞吐日志采集 |
|
消费端 |
并行度匹配 + 避免重平衡 |
消费者数量 = 分区数、session.timeout.ms=30000(30 秒心跳)、手动提交 Offset |
实时数据消费(如 Flink 接入) |
|
集群 |
副本均衡 + 存储优化 |
副本数 = 3(跨机架部署)、单 Broker 分区数≤2000、日志目录挂载 SSD |
生产环境高可用 |
2.2.2 RabbitMQ 优化
|
优化维度 |
原理 |
实操配置 |
适用场景 |
|
生产端 |
连接池减少开销 |
Java:spring.rabbitmq.cache.connection.size=10、消息大小≤1MB |
订单通知(小消息高并发) |
|
消费端 |
限流 + 死信避免重复消费 |
prefetch-count=20(每次拉取 20 条)、acknowledge-mode=manual(手动 ACK)、DLQ 配置 |
支付结果回调(需可靠消费) |
|
集群 |
镜像队列保障高可用 |
1 主 2 从集群、ha-mode=all(队列副本同步所有节点)、SSL 加密 |
核心业务(如订单创建) |
2.2.3 RocketMQ 优化
|
优化维度 |
原理 |
实操配置 |
适用场景 |
|
生产端 |
批量发送 + 事务保障 |
batchSize=1024(1KB 批量阈值)、producer.sendMessageInTransaction()(事务消息) |
金融转账(分布式事务) |
|
消费端 |
并行消费 + 重试控制 |
consumeThreadMin=20(20 线程)、setMaxReconsumeTimes(3)(重试 3 次入 DLQ) |
交易数据处理(避免丢失) |
|
集群 |
Master/Slave 同步 |
2Master+2Slave(跨机架)、flushDiskType=SYNC_FLUSH(同步刷盘) |
高可靠交易系统 |
2.3 集成方案(与计算 / 存储组件联动)
2.3.1 Kafka → Flink → Doris(实时大屏)
-- 1. Flink创建Kafka源表
CREATE TABLE kafka_user_behavior (
user_id BIGINT,
action STRING,
ts BIGINT,
WATERMARK FOR TO_TIMESTAMP_LTZ(ts, 3) AS TO_TIMESTAMP_LTZ(ts, 3) - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'user-behavior',
'properties.bootstrap.servers' = 'kafka-broker:9092',
'format' = 'json'
);
-- 2. Flink实时聚合(5分钟窗口)
CREATE VIEW realtime_click AS
SELECT
TUMBLE_START(TO_TIMESTAMP_LTZ(ts, 3), INTERVAL '5' MINUTE) AS window_start,
COUNT(*) AS click_count
FROM kafka_user_behavior
WHERE action = 'click'
GROUP BY TUMBLE(TO_TIMESTAMP_LTZ(ts, 3), INTERVAL '5' MINUTE);
-- 3. Flink写入Doris
CREATE TABLE doris_click (
window_start DATETIME,
click_count BIGINT
) WITH (
'connector' = 'doris',
'fenodes' = 'doris-fe:8030',
'database-name' = 'realtime_db',
'table-name' = 'realtime_click',
'username' = 'root',
'password' = ''
);
INSERT INTO doris_click SELECT window_start, click_count FROM realtime_click;
2.3.2 RocketMQ → Flink → Paimon(金融交易)
-- 1. Flink创建RocketMQ源表
CREATE TABLE rocketmq_transaction (
tx_id BIGINT,
user_id BIGINT,
amount DECIMAL(10,2),
tx_time DATETIME
) WITH (
'connector' = 'rocketmq',
'topic' = 'transaction-topic',
'name-server.address' = 'rocketmq-nameserver:9876',
'format' = 'json'
);
-- 2. Flink写入Paimon(事务表)
CREATE TABLE paimon_transaction (
tx_id BIGINT,
user_id BIGINT,
amount DECIMAL(10,2),
tx_time DATETIME,
PRIMARY KEY (tx_id) NOT ENFORCED
) WITH (
'connector' = 'paimon',
'path' = 'hdfs://hdfs-nn:9000/paimon/transaction',
'partitioned-by' = 'DATE(tx_time)',
'bucket' = '10'
);
INSERT INTO paimon_transaction SELECT tx_id, user_id, amount, tx_time FROM rocketmq_transaction;
2.4 业务场景适配
|
业务场景 |
推荐组件 |
核心原因 |
|
日志采集(TB 级 / 天) |
Kafka |
百万级吞吐,支持日志压缩,适合海量数据传输 |
|
订单通知(毫秒级延迟) |
RabbitMQ |
微秒级延迟,死信队列保障消息不丢失,适合即时通知 |
|
金融交易(事务保障) |
RocketMQ |
事务消息解决分布式一致性,同步刷盘保障数据不丢失,适合核心交易 |
|
多系统解耦(中小并发) |
RabbitMQ |
交换机路由灵活,支持多种消息模式(Fanout/Topic),便于系统扩展 |
3. 实时计算组件(Flink/Fluss)
3.1 组件原理与特性对比
|
组件 |
核心架构 |
吞吐能力 |
延迟性能 |
核心优势 |
适用场景 |
|
Flink |
流批一体(JobManager/TaskManager) |
十万级 / 秒 |
毫秒级(10-100ms) |
状态管理 + Checkpoint+Watermark |
复杂实时计算(聚合、Join、窗口) |
|
Fluss |
轻量事件管道(Pipeline/Processor) |
万级 / 秒 |
毫秒级(5-50ms) |
低资源消耗 + 简单易用 |
轻量实时处理(过滤、格式转换) |
3.2 优化方案(作业 / 资源 / 状态管理)
3.2.1 Flink 优化
|
优化维度 |
原理 |
实操配置 |
适用场景 |
|
作业参数 |
减少 Checkpoint 开销 |
execution.checkpointing.interval=60s(60 秒间隔)、incremental=true(增量 Checkpoint) |
实时大屏(允许分钟级快照) |
|
资源配置 |
并行度匹配 CPU 核心 |
parallelism.default=16(16 并行度,匹配 16 核 CPU)、taskmanager.memory.process.size=16GB |
高并发风控(16 核 32GB 机器) |
|
状态管理 |
控制状态大小与过期 |
state.ttl.ttl=86400000(状态保留 1 天)、RocksDBStateBackend(大状态持久化) |
用户行为分析(保留 1 天状态) |
3.2.2 Fluss 优化
|
优化维度 |
原理 |
实操配置 |
适用场景 |
|
并行处理 |
多线程提高吞吐 |
Pipeline.builder().parallelism(4)(4 线程)、按user_id哈希分区 |
轻量日志过滤(4 核机器) |
|
性能优化 |
批量处理减少 IO |
Processor.batchSize(100)(每 100 条批量写入)、async(true)(异步 IO) |
实时数据转发(Kafka→Doris) |
|
资源控制 |
避免 OOM |
BackpressureStrategy.BLOCK(背压阻塞)、复用ByteBuffer减少 GC |
小内存环境(4GB 机器) |
3.3 集成方案(与消息 / 存储 / 数据湖联动)
3.3.1 Flink → Paimon → Doris(湖仓一体分析)
-- 1. Flink读取Kafka实时写入Paimon(增量数据)
INSERT INTO paimon_user_behavior
SELECT user_id, action, ts FROM kafka_user_behavior;
-- 2. Doris创建Paimon外部表(查询历史+增量数据)
CREATE EXTERNAL TABLE doris_paimon_behavior (
user_id BIGINT,
action STRING,
ts BIGINT,
dt STRING
) ENGINE=HIVE
PROPERTIES (
"format" = "orc",
"path" = "hdfs://hdfs-nn:9000/paimon/user_behavior",
"hive.metastore.uris" = "thrift://hive-metastore:9083"
)
PARTITIONED BY (dt);
-- 3. Doris查询全量数据(历史+实时)
SELECT dt, action, COUNT(*) AS action_count
FROM doris_paimon_behavior
WHERE dt BETWEEN '2024-01-01' AND '2024-01-31'
GROUP BY dt, action;
3.3.2 Fluss → Kafka → Doris(轻量日志处理)
// Fluss代码:Kafka日志过滤→Doris写入
public class KafkaToDorisFluss {
public static void main(String[] args) {
// 1. 构建Pipeline(4线程并行)
Pipeline pipeline = Pipeline.builder()
.name("kafka-doris-pipeline")
.parallelism(4)
.backpressureStrategy(BackpressureStrategy.BLOCK)
.build();
// 2. 读取Kafka日志
KafkaSource<String> kafkaSource = KafkaSource.<String>builder()
.bootstrapServers("kafka-broker:9092")
.topic("log-topic")
.groupId("fluss-group")
.valueDeserializer(new StringDeserializer())
.build();
// 3. 过滤ERROR日志
Processor<String, String> filterProcessor = context -> {
String log = context.getData();
if (log.contains("ERROR")) {
context.emit(log); // 仅转发ERROR日志
}
};
// 4. 写入Doris(Stream Load)
DorisSink dorisSink = DorisSink.builder()
.feAddr("doris-fe:8030")
.db("log_db")
.table("error_log")
.user("root")
.password("")
.batchSize(100) // 每100条批量写入
.build();
// 5. 启动Pipeline
pipeline.source(kafkaSource)
.process(filterProcessor)
.sink(dorisSink)
.start();
}
}
3.4 业务场景适配
|
业务场景 |
推荐组件 |
核心原因 |
|
实时风控(复杂规则) |
Flink |
支持窗口计算(如最近 10 分钟交易检测)、状态管理(保存用户历史行为) |
|
日志过滤(轻量处理) |
Fluss |
低资源消耗(单机 4GB 内存足够)、部署简单(无需集群),适合轻量需求 |
|
实时大屏(聚合统计) |
Flink |
流批一体支持分钟级窗口聚合,Checkpoint 保障数据不丢失,适合大屏展示 |
|
数据转发(格式转换) |
Fluss |
异步 IO + 批量处理,延迟低(≤50ms),适合简单数据转发场景 |
4. 存储与数据湖组件(HDFS/Doris/Paimon)
4.1 组件原理与特性对比
|
组件 |
核心架构 |
存储能力 |
查询性能 |
核心优势 |
适用场景 |
|
HDFS |
分布式文件系统(NameNode/DataNode) |
PB 级 |
批量读取快 |
高可靠(多副本)+ 低成本 |
海量数据持久化(日志、历史数据) |
|
Doris |
MPP 分析引擎(FE/BE) |
TB 级 |
秒级查询 |
列式存储 + 预聚合 + 索引 |
实时分析(报表、大屏) |
|
Paimon |
湖仓一体数据湖(分层存储) |
PB 级 |
实时写入 + 离线查 |
CDC 同步 + 小文件合并 |
增量数据存储(实时写入 + 离线回溯) |
4.2 优化方案(表设计 / 存储 / 查询)
4.2.1 HDFS 优化
|
优化维度 |
原理 |
实操配置(hdfs-site.xml) |
适用场景 |
|
NameNode |
元数据内存优化 |
dfs.namenode.java.opts=-Xms16g -Xmx16g(16GB 内存,支持百万文件) |
海量日志存储(千万级文件) |
|
DataNode |
块大小与 IO 优化 |
dfs.blocksize=268435456(256MB 块,减少块数量)、dfs.datanode.max.transfer.threads=4096 |
大文件存储(如视频、离线数据) |
|
副本策略 |
平衡可靠与成本 |
dfs.replication=2(测试环境)、dfs.replication=3(生产环境,跨机架) |
核心数据存储(副本 3) |
4.2.2 Doris 优化
|
优化维度 |
原理 |
实操配置 |
适用场景 |
|
表设计 |
减少扫描范围 |
AGG 模型(聚合查询)、按dt天分区、按user_id分桶(分桶数 = BE 节点数 ×2) |
实时报表(按天聚合) |
|
导入优化 |
提高导入吞吐 |
Kafka Load:parallelism=8(8 并行)、batch_size=10485760(10MB 批次) |
实时数据导入(Kafka→Doris) |
|
查询优化 |
加速过滤与聚合 |
开启 Bitmap 索引(低基数列)、查询结果缓存(query_result_cache=true) |
高频报表查询(如 GMV 统计) |
4.2.3 Paimon 优化
|
优化维度 |
原理 |
实操配置 |
适用场景 |
|
表设计 |
分层存储 + 小文件合并 |
按dt分区、按user_id分桶(10 桶)、merge-small-files.enabled=true(自动合并小文件) |
增量数据存储(每天分区) |
|
写入优化 |
批量 + 压缩减少 IO |
sink.batch-size=10000(1 万条批量)、file.format=orc(ORC 压缩) |
高吞吐写入(Flink→Paimon) |
|
读取优化 |
索引加速查询 |
布隆索引(index.bloom.enabled=true,针对user_id)、分区过滤(查询指定dt) |
离线回溯分析(按用户查询) |
4.3 集成方案(与计算 / 消息组件联动)
4.3.1 Paimon + HDFS + Doris(湖仓一体)
-- 1. Paimon表存储在HDFS(分层存储:近7天SSD,历史HDD)
CREATE TABLE paimon_sales (
sale_id BIGINT,
user_id BIGINT,
amount DECIMAL(10,2),
sale_time DATETIME,
dt STRING,
PRIMARY KEY (sale_id, dt) NOT ENFORCED
) WITH (
'connector' = 'paimon',
'path' = 'hdfs://hdfs-nn:9000/paimon/sales',
'partitioned-by' = 'dt',
'bucket' = '10',
'storage.layers' = '[{"medium":"SSD","ttl":"7d"},{"medium":"HDD","ttl":"365d"}]'
);
-- 2. Flink实时写入Paimon
INSERT INTO paimon_sales
SELECT sale_id, user_id, amount, sale_time, DATE(sale_time) AS dt FROM kafka_sales;
-- 3. Doris创建Paimon外部表(查询全量数据)
CREATE EXTERNAL TABLE doris_sales (
sale_id BIGINT,
user_id BIGINT,
amount DECIMAL(10,2),
sale_time DATETIME,
dt STRING
) ENGINE=HIVE
PROPERTIES (
"format" = "orc",
"path" = "hdfs://hdfs-nn:9000/paimon/sales",
"hive.metastore.uris" = "thrift://hive-metastore:9083"
)
PARTITIONED BY (dt)
DISTRIBUTED BY HASH(sale_id) BUCKETS 10;
-- 4. Doris查询月度销售汇总
SELECT dt, SUM(amount) AS monthly_sales
FROM doris_sales
WHERE dt LIKE '2024-01-%'
GROUP BY dt;
4.3.2 HDFS + Flink + Doris(离线批处理)
# 1. 离线数据上传HDFS
hdfs dfs -put /local/sales_data.csv /user/hive/warehouse/sales_data/
# 2. Flink读取HDFS数据,清洗后写入Doris
./bin/flink run -t yarn-per-job \
-Djobmanager.memory.process.size=2g \
-Dtaskmanager.memory.process.size=4g \
-c com.example.SalesDataETL \
./lib/flink-sales-etl.jar \
--hdfs-path hdfs://hdfs-nn:9000/user/hive/warehouse/sales_data/ \
--doris-fenodes doris-fe:8030 \
--doris-table sales_db.sales_summary
# 3. Doris查询清洗后的汇总数据
SELECT region, SUM(amount) AS region_sales
FROM sales_db.sales_summary
WHERE dt = '2024-01-01'
GROUP BY region;
4.4 业务场景适配
|
业务场景 |
推荐组件组合 |
核心原因 |
|
实时报表分析 |
Doris + Kafka |
Doris 秒级查询适合报表展示,Kafka 实时导入保障数据新鲜度 |
|
离线历史数据存储 |
HDFS + Paimon |
HDFS PB 级存储成本低,Paimon 支持增量写入 + 离线回溯查询 |
|
湖仓一体分析 |
Paimon + Doris |
Paimon 存储全量增量数据,Doris 外部表直接查询,无需数据冗余 |
|
海量日志持久化 |
HDFS |
多副本保障高可靠,低成本存储 TB/PB 级日志,适合长期归档 |
5. 资源调度与 AI 组件(YARN/AI/AIAgent)
5.1 组件原理与核心能力
|
组件 |
核心架构 |
核心能力 |
关键特性 |
适用场景 |
|
YARN |
资源调度(ResourceManager/NodeManager) |
多框架资源统一调度 |
Capacity/Fair 调度、高可用 |
Flink/Spark 作业调度 |
|
AI 模型 |
训练(TensorFlow/PyTorch)+ 推理(Serving) |
数据特征分析、异常检测、推荐 |
GPU 加速、批量推理 |
用户推荐、风控模型、异常监控 |
|
AIAgent |
智能运维(监控 + 决策 + 执行) |
组件异常检测、自动恢复 |
LLM 日志分析、API 调用 |
数据栈运维(Kafka 堆积、Doris 慢查) |
5.2 优化方案(资源分配 / 模型推理)
5.2.1 YARN 优化
|
优化维度 |
原理 |
实操配置(yarn-site.xml) |
适用场景 |
|
队列配置 |
资源隔离保障核心业务 |
Capacity 调度:yarn.scheduler.capacity.root.queues=prod,test、prod.capacity=70(生产队列 70% 资源) |
混合业务(生产 + 测试) |
|
资源分配 |
避免资源浪费 |
yarn.scheduler.minimum-allocation-mb=1024(最小 1GB)、maximum-allocation-mb=32768(最大 32GB) |
大作业调度(Flink 批处理) |
|
高可用 |
避免 RM 单点故障 |
yarn.resourcemanager.ha.enabled=true(2 个 RM 主从)、ha.zookeeper.quorum=zk-1:2181 |
生产环境高可用 |
5.2.2 AI/AIAgent 优化
|
优化维度 |
原理 |
实操配置 |
适用场景 |
|
模型训练 |
GPU 加速 + 批量处理 |
TensorFlow:tf.distribute.MirroredStrategy(多 GPU 训练)、批量大小 = 64 |
推荐模型训练(千万级样本) |
|
模型推理 |
量化 + 缓存减少延迟 |
TensorRT 量化模型(FP16)、推理结果缓存(cache.ttl=300s,5 分钟过期) |
实时推荐(延迟≤100ms) |
|
AIAgent 监控 |
LLM 日志分析 + 自动恢复 |
训练 LSTM 异常检测模型(输入 Kafka 延迟 / CPU 使用率)、自动扩容 API(调用 K8s HPA) |
数据栈智能运维 |
5.3 集成方案(与全栈组件联动)
5.3.1 YARN 调度 Flink 作业(资源隔离)
# 1. 创建YARN队列(生产队列70%资源,ETL队列20%)
yarn queue -create -queue prod -parent root -capacity 70
yarn queue -create -queue etl -parent root -capacity 20
# 2. 提交Flink实时作业到prod队列(高优先级)
./bin/flink run -t yarn-per-job \
-Dyarn.application.queue=prod \
-Djobmanager.memory.process.size=2g \
-Dtaskmanager.memory.process.size=8g \
-Dparallelism.default=16 \
-c com.example.RealtimeRiskControl \
./lib/flink-risk-control.jar
# 3. 提交Flink离线ETL作业到etl队列(低优先级)
./bin/flink run -t yarn-per-job \
-Dyarn.application.queue=etl \
-Djobmanager.memory.process.size=4g \
-Dtaskmanager.memory.process.size=16g \
-Dparallelism.default=32 \
-c com.example.SalesETL \
./lib/flink-sales-etl.jar
5.3.2 AIAgent 监控 Kafka+Doris(智能运维)
# Python示例:AIAgent监控Kafka堆积+Doris慢查
from kafka import KafkaAdminClient
from pydoris import DorisSession
import requests
# 1. 监控Kafka消费延迟(超过10万条触发告警)
def monitor_kafka_lag(kafka_broker, group_id, topic):
admin_client = KafkaAdminClient(bootstrap_servers=kafka_broker)
group_offsets = admin_client.list_consumer_group_offsets(group_id)
topic_partitions = admin_client.describe_topics(topics=[topic])[0]['partitions']
for partition in topic_partitions:
partition_id = partition['partition']
latest_offset = partition['highWatermark']
consumer_offset = group_offsets.get(TopicPartition(topic, partition_id), 0)
lag = latest_offset - consumer_offset
if lag > 100000:
send_alert(f"Kafka lag exceeds threshold: {lag} (topic: {topic}, partition: {partition_id})")
auto_scale_consumer(group_id, topic) # 自动扩容消费者
# 2. 监控Doris慢查(超过10秒触发分析)
def monitor_doris_slow_query(doris_fe, user, password, database):
doris_session = DorisSession(host=doris_fe, port=9030, user=user, password=password, database=database)
slow_queries = doris_session.execute_sql("""
SELECT query_id, query_sql, query_time
FROM information_schema.slow_query
WHERE query_time > 10
""").to_pandas()
for _, row in slow_queries.iterrows():
query_sql = row['query_sql']
# 调用LLM分析慢查原因(如阿里云通义千问)
analysis = llm_analyze_slow_query(query_sql)
send_alert(f"Doris slow query: {query_sql}\nAnalysis: {analysis}")
# 3. 自动扩容Kafka消费者(调用K8s API)
def auto_scale_consumer(group_id, topic):
k8s_api_url = "https://k8s-api:6443/apis/apps/v1/namespaces/default/deployments/kafka-consumer"
headers = {"Authorization": "Bearer <token>"}
payload = {"spec": {"replicas": 10}} # 扩容到10个消费者
requests.patch(k8s_api_url, json=payload, headers=headers, verify=False)
# 4. 发送告警(企业微信/钉钉)
def send_alert(message):
wechat_url = "https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=<key>"
payload = {"msgtype": "text", "text": {"content": message}}
requests.post(wechat_url, json=payload)
# 主函数:定时监控
if __name__ == "__main__":
while True:
monitor_kafka_lag("kafka-broker:9092", "flink-consumer-group", "user-behavior")
monitor_doris_slow_query("doris-fe:9030", "root", "", "realtime_db")
time.sleep(60) # 每分钟监控一次
5.4 业务场景适配
|
业务场景 |
推荐组件组合 |
核心原因 |
|
多框架资源调度 |
YARN + Flink/Spark |
YARN 统一调度资源,避免框架间资源抢占,适合混合计算场景 |
|
实时用户推荐 |
AI 模型 + Flink + Kafka |
Flink 实时提取用户特征,AI 模型推理推荐结果,Kafka 推送至业务系统 |
|
数据栈智能运维 |
AIAgent + 全组件 |
AIAgent 监控全组件指标,自动检测异常并恢复,减少人工干预 |
|
金融风控模型训练 |
AI 模型 + HDFS + Paimon |
HDFS 存储训练样本,Paimon 存储特征数据,AI 模型用 GPU 加速训练 |
6. 全组件集群规模规划
6.1 开发环境(轻量验证,1-3 台服务器)
适用场景:功能开发、SQL 调试、组件联调(如 Kafka→Flink→Doris 简单链路)
硬件配置(单服务器):
- CPU:4 核 8 线程(Intel Xeon E3/i7)
- 内存:16GB(DDR4)
- 磁盘:500GB SSD(兼顾速度与成本)
组件部署方案(单机多组件):
|
组件 |
节点数 |
核心配置(最小化) |
|
Kafka |
1 |
Broker=1,分区数≤50,日志留存 = 1 天(log.retention.hours=24) |
|
RabbitMQ |
1 |
关闭镜像队列,连接池 = 5(spring.rabbitmq.cache.connection.size=5) |
|
RocketMQ |
1 |
1Master(无 Slave),fileReservedTime=24(日志留存 1 天) |
|
Flink |
1 |
JobManager+TaskManager 同节点,并行度 = 2(parallelism.default=2),内存 = 4GB |
|
Doris |
1 |
FE=1(无备 FE)+ BE=1,存储 = 100GB(storage_root_path单目录) |
|
Paimon |
1 |
依赖 HDFS 单节点,分桶数≤4,小文件合并阈值 = 32MB(merge-small-files.size-threshold=32mb) |
|
HDFS |
1 |
1NN(无备 NN)+ 1DN,块大小 = 64MB(dfs.blocksize=67108864) |
|
YARN |
1 |
RM+NM 同节点,最大容器内存 = 8GB(yarn.scheduler.maximum-allocation-mb=8192) |
|
Fluss |
1 |
单线程运行(parallelism=1),批量大小 = 10(Processor.batchSize=10) |
|
AI/AIAgent |
1 |
轻量模型(Sklearn 线性回归),内存占用≤2GB,监控频率 = 5 分钟 |
关键优化:关闭非必要功能(Flink Checkpoint 间隔 = 300s,Doris 查询缓存关闭)
6.2 测试环境(模拟生产,3-6 台服务器)
适用场景:性能测试(Flink 吞吐压测)、高可用验证(Kafka Broker 故障切换)
硬件配置(单服务器):
- CPU:8 核 16 线程(Intel Xeon E5/i9)
- 内存:32GB(DDR4)
- 磁盘:1TB SSD(模拟生产数据量)
组件部署方案(按功能分组):
|
组件 |
节点数 |
核心配置(模拟生产) |
|
Kafka |
3 |
Broker=3,副本数 = 2(default.replication.factor=2),分区数≤200 |
|
RabbitMQ |
3 |
1 主 2 从,开启镜像队列(ha-mode=all),连接池 = 10 |
|
RocketMQ |
4 |
2Master+2Slave(同步复制),fileReservedTime=72(日志留存 3 天) |
|
Flink |
3 |
1JM+2TM,TM 内存 = 8GB,并行度 = 8,Checkpoint 间隔 = 60s |
|
Doris |
4 |
1 主 FE+1 备 FE+2BE,BE 存储 = 500GB / 节点,分桶数 = 8(与 BE 节点数 ×4 匹配) |
|
Paimon |
3 |
HDFS 1NN+2DN(备 NN 冷备),分桶数 = 8,ORC 压缩(file.format=orc) |
|
HDFS |
3 |
1NN+2DN(备 NN 冷备),块大小 = 128MB,副本数 = 2(dfs.replication=2) |
|
YARN |
3 |
1RM+2NM,队列分拆(prod=60%/test=40%),最大容器内存 = 16GB |
|
Fluss |
2 |
双节点并行(parallelism=4),批量大小 = 50,异步写入(Processor.async=true) |
|
AI/AIAgent |
2 |
轻量 LLM(Llama 2-7B 量化版),内存 = 8GB / 节点,支持批量推理,监控频率 = 1 分钟 |
关键验证点:Kafka 分区均衡性、Flink Checkpoint 成功率、Doris 导入失败重试机制
6.3 生产环境(基础可用,6-12 台服务器)
适用场景:中小业务(日活 10 万用户 APP、区域零售报表),要求 99.9% 可用性
硬件配置(按组件分组):
- 计算型(Flink/YARN/AI):16 核 32 线程 CPU(Intel Xeon Gold),64GB 内存,500GB SSD;
- 存储型(Kafka/HDFS/Doris BE):8 核 16 线程 CPU,32GB 内存,4TB HDD(或 2TB SSD);
- 元数据型(FE/NN/RabbitMQ 主节点):8 核 16 线程 CPU,32GB 内存,1TB SSD(高 IO)。
组件部署方案(组件独立集群,高可用基础版):
|
组件 |
节点数 |
核心配置(基础可用) |
|
Kafka |
3 |
副本数 = 3(default.replication.factor=3),分区数≤500,log.retention.hours=72 |
|
RabbitMQ |
3 |
1 主 2 从(镜像队列),prefetch-count=20,死信队列启用 |
|
RocketMQ |
4 |
2Master+2Slave(同步刷盘),autoCreateTopicEnable=false(手动管理 Topic) |
|
Flink |
6 |
1JM(主)+1JM(备)+4TM,TM 内存 = 16GB,并行度 = 16,RocksDBStateBackend(增量 Checkpoint) |
|
Doris |
5 |
1 主 FE+2 备 FE(HA)+2BE,BE 存储 = 2TB / 节点,storage_medium=SSD(查询加速) |
|
Paimon |
5 |
HDFS 2NN(HA)+3DN,块大小 = 256MB,副本数 = 3,布隆索引启用(index.bloom.enabled=true) |
|
HDFS |
5 |
2NN(HA,dfs.ha.enabled=true)+3DN,dfs.datanode.balance.bandwidthPerSec=100mb |
|
YARN |
6 |
2RM(HA)+4NM,队列分拆(prod=70%/etl=20%/test=10%),yarn.log-aggregation-enable=true |
|
Fluss |
3 |
3 节点并行(parallelism=8),批量大小 = 100,背压策略 = BLOCK |
|
AI/AIAgent |
3 |
TensorFlow Serving(模型服务),内存 = 16GB / 节点,推理延迟≤100ms,监控频率 = 30 秒 |
关键保障:FE/NN/RM 高可用(主备切换),核心组件副本数 = 3(容忍 1 节点故障)
6.4 企业级环境(高可用高吞吐,12-30 台服务器)
适用场景:大型业务(日活千万用户电商、全国性金融交易),要求 99.99% 可用性
硬件配置(按组件分组):
- 计算型(Flink/AI):32 核 64 线程 CPU(Intel Xeon Platinum),128GB 内存,1TB SSD;
- 存储型(Kafka/HDFS/Doris BE):16 核 32 线程 CPU,64GB 内存,10TB HDD(或 4TB SSD);
- 元数据型(FE/NN/RocketMQ NameServer):16 核 32 线程 CPU,64GB 内存,2TB SSD(高 IO)。
组件部署方案(组件独立集群,全链路高可用):
|
组件 |
节点数 |
核心配置(企业级) |
|
Kafka |
6 |
3 个机架部署(跨机架副本),分区数≤2000,num.io.threads=32(IO 线程 = CPU 核数 ×2) |
|
RabbitMQ |
6 |
2 主 4 从(双活集群),ha-mode=exactly(副本数 = 3),连接池 = 50,SSL 加密启用 |
|
RocketMQ |
8 |
4Master+4Slave(跨机架部署),flushDiskType=SYNC_FLUSH(同步刷盘),Topic 分区数 = 16 |
|
Flink |
12 |
2JM(HA)+10TM,TM 内存 = 32GB,并行度 = 64,Checkpoint 间隔 = 30s,状态 TTL=7 天 |
|
Doris |
10 |
1 主 FE+3 备 FE(HA)+6BE,BE 存储 = 5TB / 节点,load_process_max_memory_limit_per_task=8G(导入内存) |
|
Paimon |
15 |
HDFS 2NN(HA)+13DN,块大小 = 512MB,分层存储(SSD 存近 7 天,HDD 存历史) |
|
HDFS |
15 |
2NN(HA)+13DN,dfs.namenode.java.opts=-Xms64g -Xmx64g(元数据内存),机架感知启用 |
|
YARN |
12 |
2RM(HA)+10NM,Fair 调度(动态资源分配),yarn.nodemanager.resource.memory-mb=128g |
|
Fluss |
6 |
6 节点集群(parallelism=16),批量大小 = 200,异步 IO + 连接池(吞吐量≥5 万 / 秒) |
|
AI/AIAgent |
10 |
模型集群(3 推理 + 3 训练 + 4 监控),GPU 支持(NVIDIA A10),推理延迟≤50ms,灰度发布 |
关键特性:
- 跨机架部署:核心组件副本分布在不同机架,容忍机架故障;
- 资源隔离:Flink 实时作业用专属 YARN 队列,AI 训练用离线队列;
- 全链路加密:Kafka/RabbitMQ/Doris 均启用 SSL,数据传输加密。
6.5 云平台级环境(弹性伸缩,无固定节点数)
适用场景:超大规模业务(亿级用户短视频、全球化 SaaS),要求弹性扩展 + 按需付费
云资源选型(以阿里云为例):
- 计算资源:ECS 弹性实例(实时计算用 c7.8xlarge,离线用 g7.4xlarge,AI 用 gn7i.8xlarge(GPU));
- 存储资源:SSD 云盘(元数据)、ESSD 云盘(高频数据)、OSS(历史数据)、NAS(共享存储);
- 托管服务:阿里云 Kafka、Flink 全托管、AnalyticDB for Doris、PAI(AI 平台)。
组件部署方案(云原生弹性架构):
|
组件 |
部署方式 |
核心配置(云平台级) |
|
Kafka |
阿里云消息队列 Kafka 版 |
企业版(3Broker 起),弹性扩容(支持按需加 Broker),日志留存 = 7 天,SSL+VPC 隔离 |
|
RabbitMQ |
阿里云消息服务 RabbitMQ 版 |
4 节点(2 主 2 从),弹性伸缩(流量高峰自动加节点),连接池 = 100,死信队列启用 |
|
RocketMQ |
阿里云消息服务 RocketMQ 版 |
企业版(4Master+4Slave),事务消息启用,Topic 动态扩容,同步刷盘 |
|
Flink |
阿里云 Flink 全托管版 |
弹性模式(按 CU 计费),Checkpoint 存 OSS,并行度动态调整(16-128) |
|
Doris |
阿里云 AnalyticDB for Doris |
8 节点起(2FE+6BE),弹性扩容(BE 按需加节点),存储用 OSS+HDD 混合,查询缓存启用 |
|
Paimon |
阿里云 OSS+EMR HDFS |
存储路径 = OSS(历史)+EMR HDFS(实时),分桶数动态调整,分层存储启用 |
|
HDFS |
阿里云 EMR HDFS |
弹性模式(DN 按需扩容),块大小 = 256MB,副本数 = 2(成本优化),机架感知启用 |
|
YARN |
阿里云 EMR YARN |
弹性模式(NM 随作业启停),Fair 调度,队列分拆(prod=60%/etl=30%/test=10%) |
|
Fluss |
阿里云 ECS 容器服务 K8s 版 |
Deployment(副本 3-10,HPA 弹性),资源限制 = 2 核 4GB / 副本,异步 IO 启用 |
|
AI/AIAgent |
阿里云机器学习 PAI |
训练用 PAI-DSW(GPU 按需分配),推理用 PAI-EAS(弹性伸缩),监控用 ARMS |
关键优势:
- 弹性伸缩:流量高峰自动扩容(如双 11 Kafka Broker 从 3 扩到 10),低谷缩容;
- 免运维:云厂商自动处理故障(Broker 下线自动替换)、备份(Doris 每日备份到 OSS);
- 成本优化:非核心组件按量付费,核心组件包年包月。
7. 全组件部署方式指南
7.1 传统部署(物理机 / 虚拟机,适合运维团队成熟、需求稳定场景)
适用场景:企业级生产环境(银行核心交易系统)、对延迟敏感场景(实时风控)
部署步骤(以 Kafka+Flink+Doris 为例):
环境准备:
- 操作系统:CentOS 7.9(稳定版),关闭防火墙(或开放端口:Kafka 9092、Flink 8081、Doris 8030/9030);
- 依赖安装:JDK 1.8(所有组件依赖)、Python 3.8(AI/AIAgent 依赖);
- 存储配置:挂载独立磁盘(如/data/kafka、/data/doris),格式化为 ext4。
Kafka 部署(3 节点集群):
# 1. 下载安装包
wget https://archive.apache.org/dist/kafka/3.5.0/kafka_2.13-3.5.0.tgz
tar -zxvf kafka_2.13-3.5.0.tgz -C /opt/
ln -s /opt/kafka_2.13-3.5.0 /opt/kafka
# 2. 配置server.properties(Broker 1,其他节点修改broker.id=2/3)
cat > /opt/kafka/config/server.properties << EOF
broker.id=1
listeners=PLAINTEXT://kafka-1:9092
log.dirs=/data/kafka/logs
zookeeper.connect=zk-1:2181,zk-2:2181,zk-3:2181
default.replication.factor=3
num.io.threads=16
num.network.threads=8
log.retention.hours=72
EOF
# 3. 启动Kafka(后台运行)
/opt/kafka/bin/kafka-server-start.sh -daemon /opt/kafka/config/server.properties
Flink 部署(1JM+2TM):
# 1. 下载安装包
wget https://archive.apache.org/dist/flink/flink-1.17.0/flink-1.17.0-bin-scala_2.12.tgz
tar -zxvf flink-1.17.0-bin-scala_2.12.tgz -C /opt/
ln -s /opt/flink-1.17.0 /opt/flink
# 2. 配置flink-conf.yaml(JM节点)
cat > /opt/flink/conf/flink-conf.yaml << EOF
jobmanager.rpc.address: flink-jm
jobmanager.memory.process.size: 4g
taskmanager.memory.process.size: 8g
parallelism.default: 8
state.backend: rocksdb
state.checkpoints.dir: hdfs://hdfs-nn:9000/flink/checkpoints
execution.checkpointing.interval: 60000
EOF
# 3. 配置slaves(TM节点列表)
echo -e "flink-tm1\nflink-tm2" > /opt/flink/conf/workers
# 4. 启动Flink集群
/opt/flink/bin/start-cluster.sh
Doris 部署(1 主 FE+1 备 FE+2BE):
# 1. 下载安装包
wget https://archive.apache.org/dist/doris/2.0.0-rc03/apache-doris-2.0.0-bin-x86_64.tar.gz
tar -zxvf apache-doris-2.0.0-bin-x86_64.tar.gz -C /opt/
ln -s /opt/apache-doris-2.0.0-bin-x86_64 /opt/doris
# 2. 配置FE(主节点)
cat > /opt/doris/fe/conf/fe.conf << EOF
meta_dir=/data/doris/fe/meta
priority_networks=10.0.0.0/8
mem_limit=8g
EOF
# 3. 启动主FE
/opt/doris/fe/bin/start_fe.sh --daemon
# 4. 配置BE(所有BE节点)
cat > /opt/doris/be/conf/be.conf << EOF
storage_root_path=/data/doris/be/storage
priority_networks=10.0.0.0/8
mem_limit=16g
EOF
# 5. 启动BE并加入集群
/opt/doris/be/bin/start_be.sh --daemon
mysql -h doris-fe -P 9030 -u root -e "ALTER SYSTEM ADD BACKEND 'be-1:9050', 'be-2:9050';"
监控与运维:
- 部署 Grafana+Prometheus:监控组件指标(Kafka 消费延迟、Flink Checkpoint 成功率、Doris BE 存储使用率);
- 编写启停脚本:如kafka-cluster.sh start/stop、doris-cluster.sh start/stop;
- 定期备份:Kafka 日志、Doris 元数据、HDFS 数据每周全量备份。
优缺点:
- ✅ 优势:低延迟(无虚拟化开销,≤10ms)、可控性高(可自定义内核参数)、无 vendor 锁定;
- ❌ 劣势:运维成本高(需手动扩容 / 故障处理)、资源利用率低(物理机资源不可共享)、上线周期长(需硬件采购)。
7.2 容器化部署(Docker+K8s,适合快速迭代、弹性扩展场景)
适用场景:互联网业务(电商实时大屏)、多环境一致性要求高场景(开发 = 测试 = 生产)
核心工具:
- Docker:封装组件镜像(统一环境);
- K8s:编排容器(Deployment/StatefulSet)、管理资源(ConfigMap/Secret)、服务发现(Service);
- Helm:简化 K8s 部署(用 Chart 包管理组件配置);
- Prometheus+Grafana:监控容器与组件指标。
部署示例(K8s 部署 Doris+Kafka+Flink):
环境准备:
- K8s 集群:1Master+3Node(版本 1.24+),安装 Calico 网络插件、Metrics Server(资源监控);
- 存储:部署 Rook-Ceph(提供块存储,用于 Doris/ Kafka 数据持久化);
- Helm:安装 3.x 版本(helm version验证)。
Kafka 部署(Helm Chart):
# 1. 添加Helm仓库
helm repo add bitnami https://charts.bitnami.com/bitnami
# 2. 配置values.yaml(3节点,副本数3)
cat > kafka-values.yaml << EOF
replicaCount: 3
zookeeper:
replicaCount: 3
persistence:
size: 100Gi
storageClass: "rook-ceph-block"
config:
default.replication.factor: 3
num.io.threads: 16
log.retention.hours: 72
service:
type: ClusterIP
ports:
client: 9092
EOF
# 3. 部署Kafka
helm install kafka bitnami/kafka -f kafka-values.yaml -n kafka --create-namespace
Doris 部署(StatefulSet):
# doris-fe-sts.yaml(FE StatefulSet,3节点:1主2备)
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: doris-fe
namespace: doris
spec:
serviceName: doris-fe-service
replicas: 3
selector:
matchLabels:
app: doris-fe
template:
metadata:
labels:
app: doris-fe
spec:
containers:
- name: doris-fe
image: apache/doris:2.0.0-fe
ports:
- containerPort: 8030
- containerPort: 9030
env:
- name: FE_SERVERS
value: "doris-fe-0.doris-fe-service.doris.svc:9010,doris-fe-1.doris-fe-service.doris.svc:9010,doris-fe-2.doris-fe-service.doris.svc:9010"
- name: FE_ID
valueFrom:
fieldRef:
fieldPath: metadata.name
volumeMounts:
- name: doris-fe-data
mountPath: /opt/doris/fe/meta
resources:
requests:
cpu: "4"
memory: "8Gi"
limits:
cpu: "8"
memory: "16Gi"
volumeClaimTemplates:
- metadata:
name: doris-fe-data
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "rook-ceph-block"
resources:
requests:
storage: 100Gi
---
# doris-be-sts.yaml(BE StatefulSet,2节点)
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: doris-be
namespace: doris
spec:
serviceName: doris-be-service
replicas: 2
selector:
matchLabels:
app: doris-be
template:
metadata:
labels:
app: doris-be
spec:
containers:
- name: doris-be
image: apache/doris:2.0.0-be
ports:
- containerPort: 8040
- containerPort: 9050
env:
- name: FE_SERVERS
value: "doris-fe-0.doris-fe-service.doris.svc:9030"
volumeMounts:
- name: doris-be-storage
mountPath: /opt/doris/be/storage
resources:
requests:
cpu: "8"
memory: "16Gi"
limits:
cpu: "16"
memory: "32Gi"
volumeClaimTemplates:
- metadata:
name: doris-be-storage
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "rook-ceph-block"
resources:
requests:
storage: 2Ti
# 部署Doris
kubectl create namespace doris
kubectl apply -f doris-fe-sts.yaml -n doris
kubectl apply -f doris-be-sts.yaml -n doris
# 加入BE到FE集群
kubectl exec -it doris-fe-0 -n doris -- mysql -h 127.0.0.1 -P 9030 -u root -e "ALTER SYSTEM ADD BACKEND 'doris-be-0.doris-be-service.doris.svc:9050', 'doris-be-1.doris-be-service.doris.svc:9050';"
Flink 部署(K8s Session 模式):
# 1. 下载Flink K8s配置
wget https://archive.apache.org/dist/flink/flink-1.17.0/flink-1.17.0-bin-scala_2.12.tgz
tar -zxvf flink-1.17.0-bin-scala_2.12.tgz
cd flink-1.17.0
# 2. 启动Flink Session集群
./bin/kubernetes-session.sh \
-Dkubernetes.cluster-id=flink-session \
-Dtaskmanager.replicas=4 \
-Dtaskmanager.memory.process.size=8g \
-Djobmanager.memory.process.size=4g \
-Dparallelism.default=16 \
-Dkubernetes.namespace=flink
# 3. 提交Flink作业
./bin/flink run -t kubernetes-session -Dkubernetes.cluster-id=flink-session \
-c com.example.RealtimeClickCount \
./lib/flink-realtime-click.jar
监控与运维:
- K8s 监控:部署 kube-prometheus-stack,监控 Pod/Node 资源(CPU / 内存 / 磁盘);
- 组件监控:Flink UI(通过 NodePort 暴露)、Doris FE UI(Ingress 配置);
- 弹性伸缩:配置 HPA(Horizontal Pod Autoscaler),如 Flink TM 根据 CPU 使用率扩容(targetCPUUtilizationPercentage: 70)。
优缺点:
- ✅ 优势:环境一致性(Docker 镜像保证开发 = 生产)、弹性伸缩(K8s HPA 自动扩缩容)、资源利用率高(容器共享物理机)、部署效率高(Helm 一键部署);
- ❌ 劣势:学习成本高(需掌握 K8s/Helm/Rook)、延迟略高(容器网络开销,1-5ms)、状态管理复杂(需持久化存储)。
7.3 云托管部署(云厂商托管服务,适合中小团队、快速上线场景)
适用场景:创业公司(无专职运维)、非核心业务(用户行为分析)、全球化业务(多地域部署)
部署示例(阿里云托管组件全链路:Kafka→Flink→Doris→AI):
步骤 1:创建阿里云 Kafka 实例:
- 登录阿里云控制台→消息队列 Kafka 版→创建实例:
- 实例规格:企业版,3Broker,100GB 存储 / Broker;
- 网络:选择 VPC(与 Flink/Doris 同 VPC,避免公网延迟);
- Topic 配置:创建user-behavior Topic,分区数 = 12,副本数 = 3;
- 监控:启用云监控,设置消费延迟告警(超过 5 万条触发告警)。
步骤 2:创建阿里云 Flink 全托管集群:
- 控制台→Flink 全托管→创建集群:
- 集群规格:实时计算集群,2CU 起(1CU=1 核 2GB),弹性模式(按 CU 计费);
- 数据源配置:关联 Kafka 实例(选择user-behavior Topic,格式 JSON);
- 作业开发:用 Flink SQL Studio 编写实时聚合 SQL:
-- 实时统计用户点击量(5分钟窗口)
CREATE VIEW realtime_click AS
SELECT
user_id,
TUMBLE_START(TO_TIMESTAMP_LTZ(ts, 3), INTERVAL '5' MINUTE) AS window_start,
COUNT(*) AS click_count
FROM kafka_user_behavior
GROUP BY user_id, TUMBLE(TO_TIMESTAMP_LTZ(ts, 3), INTERVAL '5' MINUTE);
- 作业提交:选择 “弹性资源”,设置并行度 = 8,提交运行。
步骤 3:创建阿里云 AnalyticDB for Doris(托管版):
- 控制台→AnalyticDB for Doris→创建实例:
- 实例规格:2FE+4BE(FE 4 核 8GB,BE 8 核 16GB),存储 1TB SSD(自动扩容);
- 数据库创建:创建realtime_db数据库,创建user_click表:
CREATE TABLE user_click (
user_id BIGINT,
window_start DATETIME,
click_count BIGINT
) ENGINE=OLAP
DUPLICATE KEY(user_id, window_start)
PARTITION BY RANGE (window_start) (
START ('2024-01-01') END ('2024-02-01') EVERY (INTERVAL 1 DAY)
)
DISTRIBUTED BY HASH(user_id) BUCKETS 8;
- 数据接入:在 Flink 作业中配置 Doris 输出,用 JDBC 连接 Doris FE 地址(fenodes: doris-fe-vpc****.aliyuncs.com:8030)。
步骤 4:创建阿里云 PAI(AI 模型服务):
- 控制台→机器学习 PAI→模型训练:
- 数据来源:从 Doris 读取user_click表数据,作为用户行为特征;
- 模型训练:用 PAI-Studio 搭建推荐模型(如逻辑回归),训练目标 “预测用户下次点击概率”;
- 模型部署:将训练好的模型部署为 PAI-EAS 服务(弹性推理),设置 TPS=1000,延迟≤100ms;
- 业务对接:通过 API 将推荐结果推送到电商 APP(如https://eas****.aliyuncs.com/api/predict)。
监控与运维:
- 统一监控:用阿里云 ARMS 监控全链路(Kafka 消费延迟、Flink 作业吞吐量、Doris 查询耗时、AI 推理延迟);
- 自动运维:开启 “自动扩容”(Kafka Broker、Doris BE、PAI-EAS 实例均支持),设置 CPU 使用率≥70% 时扩容;
- 数据备份:Doris 数据每日自动备份到 OSS,Kafka 日志保留 7 天,PAI 模型版本管理(支持回滚)。
优缺点:
- ✅ 优势:零运维(云厂商负责部署 / 故障处理 / 升级)、快速上线(小时级完成全链路)、全球化(多地域部署,就近接入)、弹性扩展(按需扩容,无需硬件采购);
- ❌ 劣势:成本高(长期使用费用高于自建)、定制化弱(云组件功能固定,难自定义配置)、vendor 锁定(迁移到其他云成本高)。
7.4 混合部署(核心组件本地 + 非核心云托管,适合大型企业、平衡成本与稳定性场景)
适用场景:大型金融机构(核心交易本地,用户分析云托管)、传统企业数字化转型(原有本地 + 新增云组件)
典型架构示例(银行系统):
|
组件类型 |
部署方式 |
硬件 / 云资源规格 |
理由 |
|
核心组件 |
本地物理机部署 |
物理机:32 核 64GB 内存,4TB SSD(交易系统);组件:RocketMQ(4Master+4Slave)、Doris(4FE+6BE) |
交易系统需 99.99% 可用性、≤10ms 延迟,本地部署可控性高,避免云厂商故障影响 |
|
非核心组件 |
阿里云托管部署 |
云资源:Kafka(3Broker)、Flink 全托管(8CU)、Paimon(OSS 存储) |
用户行为分析非核心业务,云托管减少运维成本,支持弹性扩容(如活动高峰扩容) |
|
数据同步组件 |
本地虚拟机部署 |
虚拟机:8 核 16GB 内存;组件:DataX(同步本地 Doris→云 Doris)、Canal |
相比物理机(需硬件采购、机房部署,周期≥1 周),虚拟机可通过虚拟化平台(如 VMware)快速创建 / 扩容(分钟级),且 8 核 16GB 规格刚好匹配 DataX(8 线程并行同步)、Canal(集群模式)的资源需求,既避免资源浪费(如物理机空闲率>60%),又可在活动高峰(如银行理财节)临时扩容至 16 核 32GB。 |
| 组件类型 | 部署方式 | 硬件 / 云资源规格 | 核心配置(含关键参数) | 同步链路 | 关键保障措施 | 设计理由(金融场景适配) |
|---|---|---|---|---|---|---|
| DataX | 本地虚拟机部署 | 虚拟机:2 台(主备),8 核 16GB 内存,500GB SSD(同步日志存储);操作系统:CentOS 7.9 | 1. 同步线程:channel=8(8 线程并行);2. 批量大小:batchSize=1024(每 1024 条提交 1 次);3. 重试机制:retryCount=3(失败重试 3 次);4. 脱敏配置:身份证 / 手机号脱敏(见代码 1);5. 日志:logLevel=info(日志输出到/var/log/datax/) |
本地 Doris(交易库)→ 云 Doris(分析库)(每日凌晨 2 点全量同步前 1 天数据) | 1. 主备虚拟机自动切换(Keepalived);2. 同步完成后校验数据一致性(count(*)对比);3. 同步日志保留 30 天(用于审计) |
1. 全量同步保障分析库数据完整性(银行用户分析需全量交易数据);2. 凌晨低峰期同步避免影响核心交易;3. 脱敏符合《个人信息保护法》,避免敏感数据泄露 |
| Canal | 本地虚拟机部署 | 与 DataX 共享 2 台主备虚拟机;Canal 版本:1.1.7(稳定版) | 1. 监听配置:canal.instance.master.address=mysql-master:3306(监听交易库 MySQL 主库);2. 同步模式:canal.instance.mode=cluster(集群模式,主备容错);3. 批量提交:canal.instance.batch.size=512(每 512 条批量发送);4. 过滤规则:仅同步交易表(canal.instance.filter.regex=trade_db\\.trade_detail);5. 输出目标:云 Kafka(canal.mq.topic=trade_increment)(见代码 2) |
本地 MySQL(交易库)→ 云 Kafka(增量 Topic)(实时同步,延迟≤500ms) | 1. 监听 MySQL binlog 日志(row 模式,确保数据不丢);2. 主备 Canal 实例切换(ZooKeeper 协调);3. 云 Kafka 副本数 = 3(避免增量数据丢失) | 1. 增量同步满足用户分析的实时性(如用户实时交易行为分析);2. 集群模式避免 Canal 单点故障,符合银行高可用要求;3. 过滤规则减少无效数据同步,降低带宽消耗 |
| Flink CDC | 本地虚拟机部署 | 新增 2 台虚拟机(主备),16 核 32GB 内存,1TB SSD(状态存储);Flink 版本:1.17.0 | 1. 连接配置:'scan.startup.mode' = 'initial'(首次全量,后续增量);2. 状态管理:state.backend=rocksdb(状态持久化到 SSD);3. Checkpoint:execution.checkpointing.interval=10000(10 秒快照);4. 容错:state.ttl=86400000(状态保留 1 天);5. 输出格式:JSON(适配云 Paimon)(见代码 3) |
本地 PostgreSQL(客户信息库)→ 云 Paimon(客户特征库)(实时同步,延迟≤1 秒) | 1. 主备 Flink 集群自动切换(Flink HA);2. 状态快照定期备份到本地 HDFS;3. 同步失败自动重试(基于 Checkpoint 恢复) | 1. 实时同步客户信息(如开户、销户),支撑用户画像分析;2. PostgreSQL 适配银行核心客户系统(多数银行用 PostgreSQL 存储客户数据);3. 10 秒快照保障数据不丢,符合金融数据可靠性要求 |
7.4.2 混合部署核心保障体系
1. 统一监控与告警
- 监控工具选型:本地用 Zabbix 监控物理机 / 虚拟机资源(CPU、内存、磁盘 IO),云用阿里云 ARMS 监控托管组件(Kafka 消费延迟、Flink 作业吞吐量),通过Prometheus 联邦集群聚合全链路指标;
- 告警策略:
- 核心组件(RocketMQ、本地 Doris):延迟>10ms、错误率>0.1% 触发电话 + 短信告警;
- 非核心组件(云 Kafka、Flink 全托管):延迟>1000ms、堆积>10 万条 触发企业微信告警;
- 可视化:Grafana 搭建统一监控大屏,分 “核心交易”“非核心分析”“数据同步” 3 个模块,支持钻取查看单组件详情。
2. 数据安全与权限控制
- 传输加密:本地与云之间通过阿里云高速通道(专线)传输数据,避免公网暴露;组件间通信启用加密(RocketMQ SSL、Doris JDBC SSL、Kafka SASL_SSL);
- 数据脱敏:同步到云的用户数据需脱敏(如身份证号保留前 6 后 4,手机号隐藏中间 4 位),用 DataX 脱敏插件实现:
json
"transformer": [ {"name": "mask", "parameter": {"column": "id_card", "rule": "replace", "pattern": "(\\d{6})\\d+(\\d{4})", "replacement": "$1****$2"}} ] - 权限统一:本地与云组件用 LDAP 统一身份认证,如本地 Doris、云 AnalyticDB for Doris 均对接企业 LDAP,仅授权 “风控团队” 访问核心交易数据,“分析团队” 仅访问脱敏后的非核心数据。
3. 灾备与故障恢复
- 核心组件灾备:本地部署双活集群(如 RocketMQ 4Master 分 2 个机房部署),单机房故障时自动切换,RTO(恢复时间)≤5 分钟,RPO(数据丢失量)≤10 秒;
- 非核心组件灾备:云托管组件依赖云厂商灾备(如阿里云 Kafka 跨可用区部署),本地同步一份核心分析数据到云 OSS,作为灾备;
- 故障恢复流程:
- 本地组件故障:运维团队 5 分钟内响应,通过 Zabbix 告警定位问题,如 RocketMQ Master 故障,自动切换到 Slave;
- 云组件故障:触发云厂商 SLA 保障(如阿里云承诺 99.95% 可用性),同时本地 AIAgent 自动切换非核心业务到备用链路(如云 Flink 故障时,临时用本地 Flink 处理低优先级任务)。
7.4.3 业务场景落地示例(银行 “实时风控 + 用户分析”)
1. 实时风控链路(核心,本地部署)
- 数据流向:用户交易请求→本地 MySQL(交易库)→Canal 监听增量→本地 Flink(实时风控)→本地 RocketMQ(推送风控结果)→核心交易系统;
- 关键优化:本地 Flink 并行度 = 32(匹配 32 核 CPU),状态 TTL=24 小时(保留用户 1 天内交易行为),Checkpoint 存本地 HDFS(避免云延迟);
- 业务效果:风控决策延迟≤8ms,准确率 99.5%,拦截欺诈交易日均 120 笔。
2. 用户分析链路(非核心,云托管)
- 数据流向:本地 MySQL(交易库)→DataX 每日全量同步→云 Paimon→云 Flink(用户行为聚合)→云 Doris→BI 报表(如用户理财偏好分析);
- 关键优化:云 Flink 用弹性 CU(闲时 2CU,忙时 16CU),云 Doris 查询结果缓存 1 小时(减少重复计算);
- 业务效果:月度报表生成时间从 2 小时缩短到 15 分钟,云资源成本比本地部署降低 40%。
8. 全栈业务场景落地案例
8.1 案例 1:电商双 11 实时大屏(高吞吐 + 弹性扩展)
1. 业务需求
- 实时展示 GMV、订单量、用户数等核心指标,延迟≤1 分钟;
- 双 11 峰值:订单量 10 万 / 秒,GMV 数据量 5TB / 天;
- 支持业务人员实时调整营销策略(如某商品售罄时快速下架)。
2. 架构选型(云平台级 + 容器化部署)
| 组件 | 部署方式 | 核心配置 |
|---|---|---|
| 消息 | 阿里云 Kafka 企业版 | 6Broker(跨 2 可用区),Topic 分区数 = 32,compression.type=snappy,弹性扩容启用 |
| 计算 | 阿里云 Flink 全托管 | 弹性 CU(基线 16CU,峰值 64CU),Checkpoint 存 OSS,execution.checkpointing.interval=30s |
| 分析 | 阿里云 AnalyticDB for Doris | 4FE+8BE,分桶数 = 16,query_result_cache=true(缓存 5 分钟),存储用 ESSD+OSS 混合 |
| 数据湖 | 阿里云 Paimon(OSS 存储) | 按小时分区,merge-small-files.enabled=true,布隆索引(user_id列) |
| 调度 | 阿里云 YARN 弹性版 | Fair 调度,队列分拆(大屏 = 50%/ETL=30%/ 测试 = 20%),yarn.log-aggregation.enable=true |
3. 核心优化点
- Kafka 弹性扩容:双 11 前 1 小时自动扩容到 10Broker,峰值后 30 分钟缩容到 6Broker,成本降低 30%;
- Flink 背压处理:启用
backpressure.detection.enabled=true,峰值时自动降低消费速率,避免作业失败; - Doris 查询优化:大屏指标用物化视图(如
mv_gmv预聚合每 5 分钟 GMV),查询耗时从 5 秒缩短到 500ms。
4. 业务效果
- 大屏延迟稳定在 30 秒内,峰值时订单处理吞吐量 12 万 / 秒;
- 无数据丢失(Flink Checkpoint+Kafka 副本保障);
- 云资源按需付费,双 11 期间总成本比固定集群降低 55%。
8.2 案例 2:银行实时风控系统(企业级 + 传统部署)
1. 业务需求
- 实时拦截欺诈交易(如盗刷、洗钱),延迟≤10ms;
- 支持 7×24 小时运行,可用性≥99.99%;
- 满足监管要求(交易数据留存 5 年,可回溯审计)。
2. 架构选型(企业级 + 传统部署)
| 组件 | 部署方式 | 核心配置 |
|---|---|---|
| 消息 | 本地物理机 RocketMQ | 4Master+4Slave(跨 2 机房),flushDiskType=SYNC_FLUSH,transaction消息启用 |
| 计算 | 本地物理机 Flink | 2JM(HA)+10TM,32 核 64GB / 节点,state.backend=rocksdb,state.ttl=24h |
| 分析 | 本地物理机 Doris | 4FE(1 主 3 备)+6BE,BE 存储 = 5TB / 节点(SSD),Bitmap索引(card_no列) |
| 存储 | 本地 HDFS | 2NN(HA)+12DN,块大小 = 256MB,副本数 = 3(跨机房),dfs.namenode.java.opts=-Xms64g |
| AI 模型 | 本地 GPU 物理机 | 16 核 32GB 内存,NVIDIA A10 GPU,TensorFlow Serving 部署风控模型,推理延迟≤50ms |
3. 核心优化点
- 跨机房部署:RocketMQ、HDFS、Doris 均跨 2 个机房部署,单机房断电时业务无感知;
- Flink 低延迟优化:
taskmanager.network.memory.fraction=0.4(增大网络内存),parallelism.default=32(匹配 CPU 核心),延迟稳定在 8ms 内; - 数据留存:交易数据本地 HDFS 存 1 年(SSD+HDD 分层),历史数据归档到磁带库(5 年),满足监管要求。
4. 业务效果
- 欺诈交易拦截率 99.2%,误判率<0.1%;
- 系统全年无故障运行,可用性达 99.993%;
- 交易数据回溯审计响应时间<30 秒,满足监管检查需求。
9. 全组件运维与故障排查指南(新增)
9.1 核心组件常见故障与解决方案
| 组件 | 故障现象 | 排查步骤 | 解决方案 |
|---|---|---|---|
| Kafka | 消费延迟突增(>10 万条) | 1. kafka-consumer-groups.sh --describe --group flink-group查看各分区 lag;2. 检查消费者 CPU / 内存使用率(top命令);3. 查看 Broker IO 负载(iostat -x 1) |
1. 若消费者过载:增加消费者数量(≤分区数);2. 若 Broker IO 高:扩容 Broker,日志目录迁移到 SSD;3. 若网络瓶颈:升级网卡(10G→25G) |
| Flink | Checkpoint 失败 | 1. 查看 Flink UI(JobManager:8081)Checkpoint 页面,定位失败 Task;2. 查看 TaskManager 日志(tail -f flink-taskmanager.log);3. 检查状态存储(如 RocksDB)磁盘空间 |
1. 若状态过大:启用增量 Checkpoint,设置状态 TTL;2. 若磁盘满:清理历史 Checkpoint,扩容磁盘;3. 若网络超时:增大checkpointing.timeout=300s |
| Doris | 导入失败(Load Job 报错) | 1. SHOW LOAD查看失败原因;2. 查看 BE 日志(be/log/be.INFO)搜索 “Load failed”;3. 检查数据源格式(如 JSON 是否符合 schema) |
1. 若数据格式错误:增加max_filter_ratio=0.05(允许 5% 错误数据);2. 若内存不足:增大load_process_max_memory_limit_per_task=4G;3. 若网络超时:调整load_connect_timeout=300 |
| HDFS | DataNode 下线 | 1. 查看 NameNode UI(50070)“DataNodes” 页面,确认下线节点;2. 登录下线节点查看datanode.log(搜索 “error”);3. 检查节点网络(ping nn-ip)、磁盘(df -h) |
1. 若磁盘故障:更换故障磁盘,重启 DataNode;2. 若网络故障:修复交换机 / 网线,重启网络服务;3. 若进程挂掉:hadoop-daemon.sh start datanode,等待数据同步 |
| RocketMQ | 事务消息回滚率高(>5%) | 1. 查看 Producer 日志(搜索 “transaction rollback”);2. 检查本地事务执行耗时(select * from information_schema.processlist where db='trade_db');3. 查看 MySQL 主从延迟(show slave status\G) |
1. 若本地事务慢:优化 SQL(如加索引),拆分大事务;2. 若主从延迟高:升级 MySQL 硬件,减少从库同步压力;3. 若网络波动:增大transactionTimeout=60000(事务超时 60 秒) |
9.2 全链路监控指标体系
1. 核心监控指标(Prometheus+Grafana)
| 指标类型 | 关键指标 | 预警阈值 |
|---|---|---|
| 消息组件 | Kafka:kafka_consumer_lag(消费延迟)、kafka_producer_error_rate(生产错误率);RocketMQ:rocketmq_transaction_rollback_rate(事务回滚率) |
延迟>5 万条、错误率>0.1%、回滚率>1% |
| 计算组件 | Flink:flink_job_checkpoint_success_rate(Checkpoint 成功率)、flink_task_backpressure(背压状态);Fluss:fluss_pipeline_throughput(吞吐量) |
成功率<95%、背压>5 分钟、吞吐量<预期 80% |
| 存储组件 | HDFS:hdfs_datanode_dead_count(下线 DN 数)、hdfs_namenode_metadata_used(元数据内存使用率);Doris:doris_be_storage_used_rate(BE 存储使用率) |
下线 DN>1、元数据使用率>80%、存储使用率>85% |
| AI/AIAgent | 模型推理延迟(ai_inference_latency)、异常检测准确率(ai_anomaly_detection_accuracy) |
延迟>100ms、准确率<90% |
2. 监控面板设计
- 全局概览面板:展示全组件健康状态(绿色 = 正常,黄色 = 预警,红色 = 故障)、核心业务指标(如 GMV、订单量);
- 组件详情面板:按组件拆分(Kafka、Flink、Doris 等),展示该组件的关键指标趋势(如 1 小时 / 24 小时延迟变化);
- 业务链路面板:按业务场景拆分(实时大屏、风控系统),展示端到端延迟(如 Kafka→Flink→Doris 总延迟)。
10. 总结与选型建议(完善)
10.1 全组件核心价值总结
- 消息层:Kafka(高吞吐)、RabbitMQ(低延迟)、RocketMQ(高可靠),覆盖从日志采集到金融交易的全场景消息需求;
- 计算层:Flink(复杂实时计算)、Fluss(轻量处理),满足从实时风控到日志过滤的不同计算强度需求;
- 存储层:HDFS(海量持久化)、Doris(实时分析)、Paimon(湖仓一体),实现 “热数据实时查、温数据按需查、冷数据归档存” 的分层存储;
- 调度与 AI 层:YARN(资源统一调度)、AI/AIAgent(智能运维 + 业务赋能),提升资源利用率与业务智能化水平。
10.2 选型决策树(简化版)
- 按业务重要性:
- 核心业务(交易 / 风控):选企业级规模 + 传统 / 混合部署,组件优先 RocketMQ、本地 Flink、Doris;
- 非核心业务(分析 / 报表):选云平台级 + 托管部署,组件优先 Kafka、云 Flink、AnalyticDB for Doris。
- 按成本预算:
- 预算充足(大型企业):企业级规模 + 混合部署,平衡稳定性与灵活性;
- 预算有限(创业公司):云平台级 + 托管部署,按需付费降低初期成本。
- 按技术团队规模:
- 运维团队成熟(≥5 人):可自建容器化集群(K8s+Helm);
- 运维团队小型(≤2 人):优先云托管服务,减少运维负担。
10.3 未来演进建议
- 云原生转型:传统部署的企业可逐步将非核心组件迁移到云,核心组件保留本地,通过混合部署过渡;
- AI 深度融合:将 AIAgent 扩展到全链路自动化(如自动优化 Flink 并行度、Doris 分桶数),减少人工干预;
- 绿色节能:通过动态资源调度(如 YARN Fair 调度、云弹性扩容)降低闲置资源消耗,实现技术与成本的可持续发展。


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 14
14 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)