【即插即用模块】注意力篇 | AAAI 2025 | DCTSA:自适应频率选择+时间空间双注意力,既轻量又涨点!
本文提出了一种基于离散余弦变换(DCT)的空间注意力模块DCTSA,用于增强脉冲神经网络(SNNs)的时空特征提取能力。该模块包含三个核心部分:DCT频率提取、自适应频率注意力和时空融合。通过将空间特征转换为频率分量,并结合时间注意力机制,DCTSA能够有效捕捉高频细节和动态依赖关系。实验表明,该模块在多种视觉任务中显著提升性能,尤其在需要高频特征的任务中表现突出。代码实现采用DCT滤波器和自适应
VX: shixiaodayyds,备注【即插即用】,添加即插即用模块交流群。
模块出处

Paper:FSTA-SNN:Frequency-Based Spatial-Temporal Attention Module for Spiking Neural Networks
Code:https://github.com/yukairong/FSTA-SNN
模块介绍
Discrete Cosine Transform (DCT)-based Spatial Attention(DCTSA,图(b)):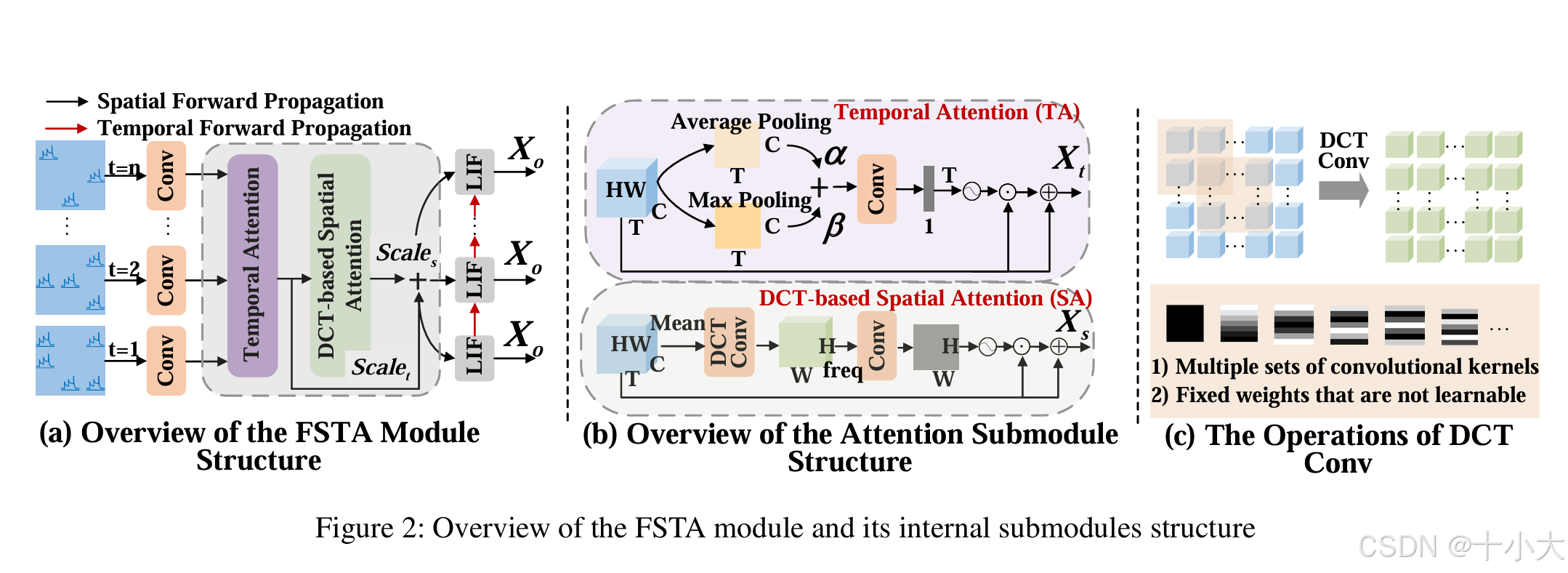
DCTSA包含DCT频率提取,自适应频率注意力,时空融合三个主要部分:
- DCT频率提取:DCT 将空间域特征转换为固定数量的频率分量(如 49=7×7),复杂度降为线性。
- 自适应频率注意力:通过FreConv模块学习频率权重,自动强化任务关键频率。
- 时空融合:时间注意力捕捉动态依赖,频率注意力捕捉空间细节,二者加权融合,适配时序视觉任务。
模块提出的动机(Motivation)
脉冲神经网络(SNNs)因其固有的能量效率而成为人工神经网络(ANNs)的一种有前途的替代方案。由于snn内峰值生成的固有稀疏性,经常忽略中间输出峰值的深入分析和优化。这种疏忽极大地限制了snn固有的能量效率,降低了它们在时空特征提取方面的优势,导致缺乏准确性和不必要的能量消耗。在这项工作中,我们从时间和空间的角度分析了snn固有的峰值特征。在空间分析方面,我们发现浅层倾向于专注于学习垂直变化,而深层逐渐学习特征的水平变化。关于时间分析,我们观察到不同时间步长的特征学习没有显着差异。这表明增加时间步长对特征学习的影响有限。基于这些分析得出的见解,我们提出了一种基于频率的时空注意 (FSTA) 模块来增强 SNN 中的特征学习。本文的DCTSA时FSTA中的一部分。
适用范围与模块效果
适用范围:适用于通用视觉领域,不止于SNN,特别是需要捕捉高频细节的任务。
模块优劣: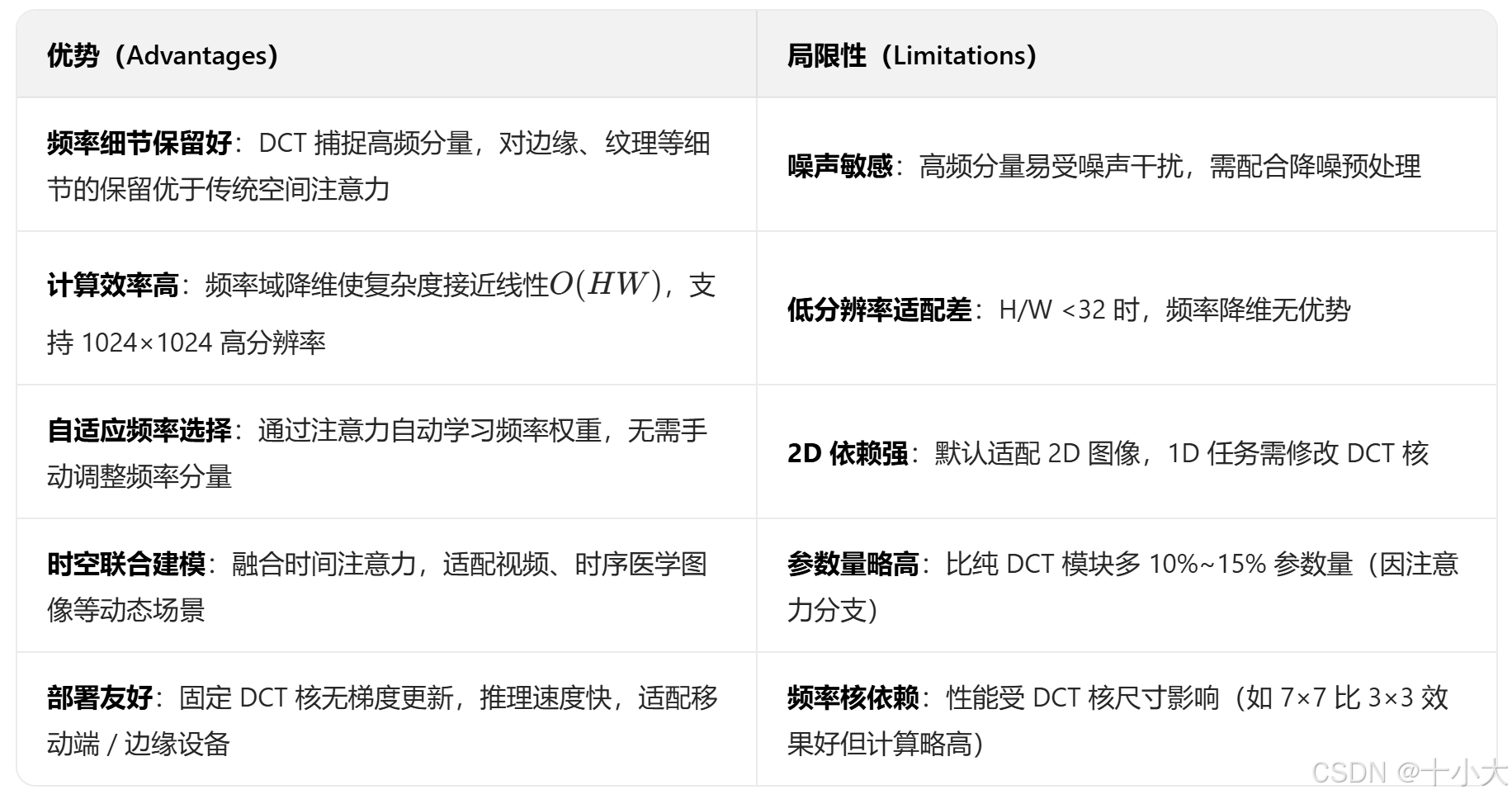
缝合位置:任意需要增强高频特征的位置。
模块效果:以DCTSA构成的网络性能SOTA,涨点明显。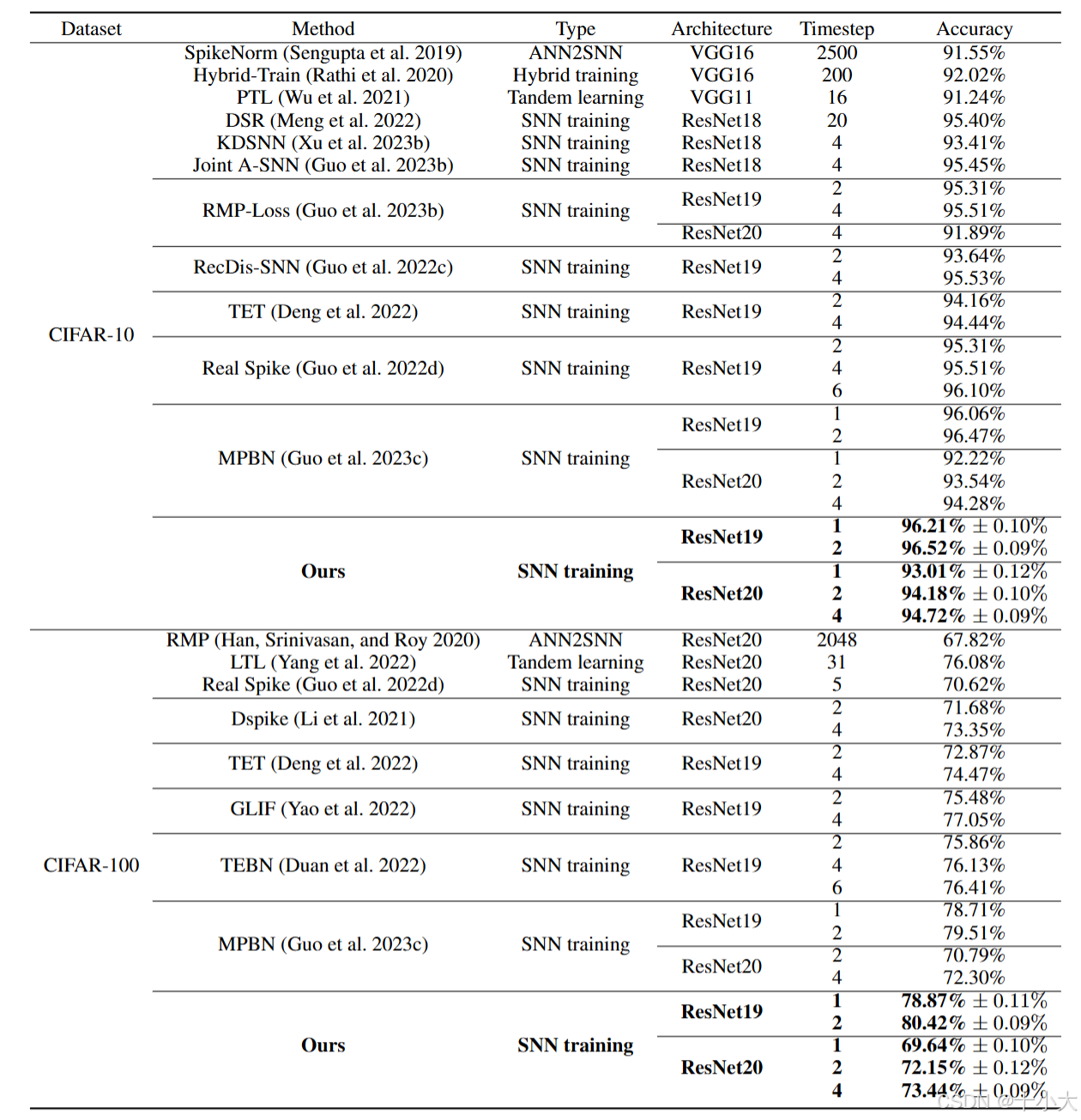
各种注意力的放置方式消融:
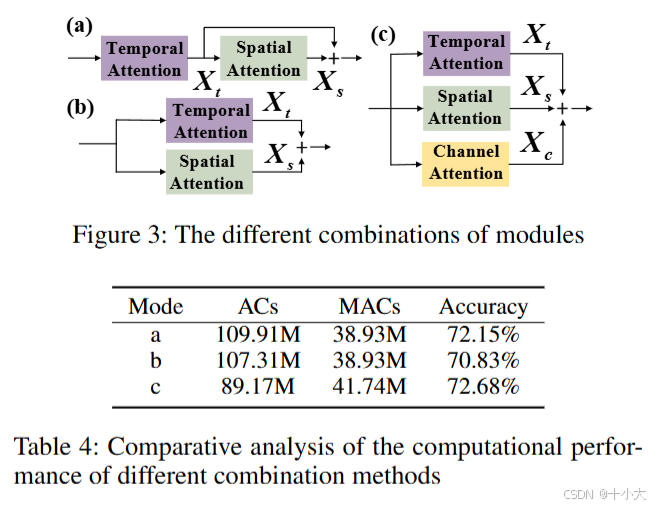
不同频率范围的性能比较:频率范围49最优。
模块代码及使用方式
代码与模块结构图对应关系: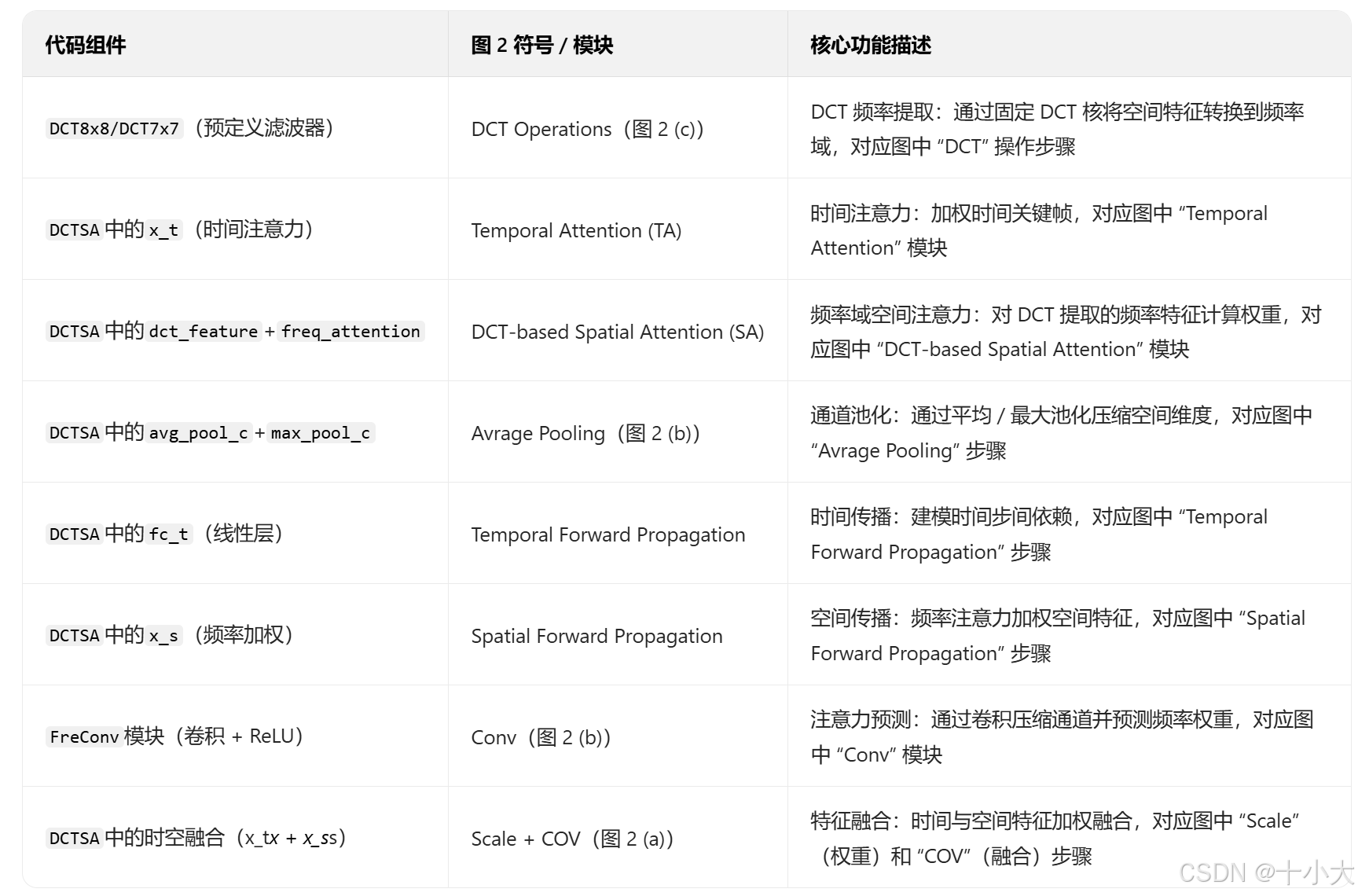
模块代码(详细注释与特征流前向传播过程中的维度变化):
import torch
import torch.nn as nn
import torch.nn.functional as F
from data.dct_filter import DCT8x8, DCT7x7, DCT3x3
from einops import rearrange
class FreConv(nn.Module):
"""
频率注意力模块:对DCT提取的频率特征进行通道压缩与权重预测
核心作用:自适应学习不同频率分量的重要性,强化关键频率特征,抑制冗余信息
"""
def __init__(self, c, reduction, k=1, p=0):
super(FreConv, self).__init__()
self.reduction = reduction # 通道压缩比(如16表示将c通道压缩为c/16)
# 注意力预测网络:根据通道数是否压缩选择单卷积或双卷积结构
if reduction == 1:
# 无压缩:单1×1卷积直接输出1通道注意力权重
self.freq_attention = nn.Sequential(
nn.Conv2d(c, 1, kernel_size=k, padding=p, bias=False),
)
else:
# 有压缩:卷积+ReLU+卷积,降低计算复杂度
self.freq_attention = nn.Sequential(
nn.Conv2d(c, c // reduction, kernel_size=k, bias=False, padding=p),
nn.ReLU(), # 非线性激活增强表达
nn.Conv2d(c // reduction, 1, kernel_size=k, padding=p, bias=False)
)
def forward(self, x):
"""前向传播:输入频率特征→注意力权重预测→输出权重图"""
return self.freq_attention(x)
class DCTSA(nn.Module):
"""
DCT基于空间注意力模块(DCTSA):结合时间注意力与频率域空间注意力,增强时空特征表达
核心流程:时间注意力加权→DCT频率提取→频率注意力加权→时空特征融合
"""
def __init__(self, freq_num, channel, step, reduction=1, groups=1, select_method='all'):
"""
Args:
freq_num (int): DCT频率分量数(64→8×8,49→7×7,9→3×3)
channel (int): 输入特征通道数
step (int): 时间步长(用于时间注意力)
reduction (int): 频率注意力通道压缩比
groups (int): 分组卷积组数(默认1,预留扩展)
select_method (str): DCT滤波器选择方式(all/topN/sN,如top10表示选Top10频率)
"""
super(DCTSA, self).__init__()
self.freq_num = freq_num
self.channel = channel
self.reduction = reduction
self.select_method = select_method
self.groups = groups
self.step = step
# 初始化对应尺寸的DCT滤波器(根据freq_num自动匹配8×8/7×7/3×3)
if freq_num == 64:
self.dct_filter = DCT8x8()
elif freq_num == 49:
self.dct_filter = DCT7x7()
elif freq_num == 9:
self.dct_filter = DCT3x3()
# 计算DCT卷积的padding(确保输入输出尺寸一致,padding=(滤波器尺寸-1)/2)
self.p = int((self.dct_filter.freq_range - 1) / 2)
# 根据滤波器选择方式确定频率通道数
if self.select_method == 'all':
self.dct_c = self.dct_filter.freq_num # 全选所有频率分量
elif 's' in self.select_method:
self.dct_c = 1 # 单选某一个频率分量(如s5表示选第5组滤波器)
elif 'top' in self.select_method:
self.dct_c = int(self.select_method.replace('top', '')) # 选Top-N频率分量
# 初始化频率注意力模块(输入通道数为dct_c,压缩比reduction)
self.freq_attention = FreConv(self.dct_c, reduction=reduction, k=7, p=3)
self.sigmoid = nn.Sigmoid() # 注意力权重归一化(0~1)
# 通道注意力组件:自适应平均/最大池化融合
self.avg_pool_c = nn.AdaptiveAvgPool3d((None, 1, 1)) # 时间维度保留,空间维度池化
self.max_pool_c = nn.AdaptiveMaxPool3d((None, 1, 1))
# 池化结果融合权重(可学习参数)
self.register_parameter('alpha', nn.Parameter(torch.FloatTensor([0.5]))) # 平均池化权重
self.register_parameter('beta', nn.Parameter(torch.FloatTensor([0.5]))) # 最大池化权重
# 时间注意力组件:线性层建模时间依赖
self.fc_t = nn.Linear(step, step, bias=False)
# 时空特征融合权重(可学习参数)
self.register_parameter('t', nn.Parameter(torch.FloatTensor([0.6]))) # 时间特征权重
self.register_parameter('s', nn.Parameter(torch.FloatTensor([0.5]))) # 空间特征权重
def forward(self, x):
"""
前向传播流程:维度调整→通道池化融合→时间注意力→DCT频率提取→频率注意力→时空融合→输出
Args:
x (torch.Tensor): 输入特征,形状 [T, B, C, H, W](T=时间步,B=批量,C=通道,H/W=空间尺寸)
Returns:
torch.Tensor: 输出特征,形状与输入一致 [T, B, C, H, W]
"""
T, B, C, H, W = x.shape
# 维度调整:[T,B,C,H,W] → [B,T,C,H,W](适配批量优先的池化/卷积操作)
x = rearrange(x, 't b c h w -> b t c h w')
# 步骤1:通道注意力池化融合(平均+最大池化加权)
avg_map = self.avg_pool_c(x) # [B,T,C,1,1](空间维度池化为1×1)
max_map = self.max_pool_c(x)
map_add = self.alpha * avg_map + self.beta * max_map # 池化结果融合
# 步骤2:时间注意力计算(建模时间步间依赖)
# 维度调整:[B,T,C,1,1] → [B,C,T](适配线性层输入)
map_add = rearrange(map_add, 'b t c 1 1 -> b c t')
# 线性层建模时间依赖 → 维度恢复:[B,C,T] → [B,T,C]
map_fusion_t = self.fc_t(map_add).transpose(1, 2)
# 时间注意力权重归一化:[B,T,C] → [B,T](通道维度求平均)→ [B,T,1,1,1](广播适配)
t_mean_sig = self.sigmoid(torch.mean(map_fusion_t, dim=2))
t_mean_sig = rearrange(t_mean_sig, 'b t -> b t 1 1 1').repeat(1, 1, C, H, W)
# 时间注意力加权:原始特征 × 时间权重 + 残差(强化时间关键帧)
x_t = x * t_mean_sig + x # [B,T,C,H,W]
# 步骤3:DCT频率提取(空间域→频率域)
# 根据选择方式加载对应DCT滤波器
if self.select_method == 'all':
# 全选所有频率:[64,8,8] → [64,1,8,8] → [64,C,8,8](适配多通道卷积)
dct_weight = self.dct_filter.filter.unsqueeze(1).repeat(1, self.channel, 1, 1)
elif 's' in self.select_method:
# 单选某一频率:提取指定索引的滤波器→广播到多通道
filter_id = int(self.select_method.replace('s', ''))
dct_weight = self.dct_filter.get_filter(filter_id).unsqueeze(0).unsqueeze(0).repeat(1, self.channel, 1, 1)
elif 'top' in self.select_method:
# 选Top-N频率:根据重要性分数选前N个滤波器→广播到多通道
filter_id = self.dct_filter.get_topk(self.dct_c)
dct_weight = self.dct_filter.get_filter(filter_id).unsqueeze(1).repeat(1, self.channel, 1, 1)
# DCT卷积:时间平均特征 × DCT核 → 频率特征 [B, dct_c, H, W]
dct_feature = F.conv2d(
torch.mean(x_t, dim=1), # 时间维度求平均,聚焦空间特征 [B,C,H,W]
dct_weight,
bias=torch.zeros(self.dct_c).to(dct_weight.device), # 无偏置
stride=1,
padding=self.p # 保持空间尺寸一致
)
# 步骤4:频率注意力加权(强化关键频率)
dct_attn = self.freq_attention(dct_feature) # 频率注意力权重 [B,1,H,W]
# 维度调整:[B,1,H,W] → [B,T,C,H,W](广播适配时间和通道维度)
dct_attn = dct_attn.unsqueeze(1).repeat(1, T, C, 1, 1)
# 频率注意力加权:时间加权特征 × 频率权重 + 残差(强化高频/低频细节)
x_s = x_t * self.sigmoid(dct_attn) + x_t # [B,T,C,H,W]
# 步骤5:时空特征融合(时间特征×t权重 + 空间特征×s权重,平均归一化)
x = (x_t * self.t + x_s * self.s) / 2
# 维度恢复:[B,T,C,H,W] → [T,B,C,H,W](与输入维度一致)
x = rearrange(x, 'b t c h w -> t b c h w')
return x
if __name__ == '__main__':
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
# T,B,C,H,W
x = torch.randn(2, 1, 64, 256, 256).to(device)
cbsa = DCTSA(49, 64, 2, 16).to(device)
y = cbsa(x)
print("微信公众号:十小大的底层视觉工坊")
print("知乎、CSDN:十小大")
print("输入特征维度:", x.shape)
print("输出特征维度:", y.shape)
运行结果:

至此本文结束。
如果本文对你有所帮助,请点赞收藏,创作不易,感谢您的支持!
点击下方👇公众号区域,扫码关注,可免费领取一份200+即插即用模块资料!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 25
25 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)