阿里云开发者 | AI Coding实践:CodeFuse + prompt 从系分到代码(下)
本章节主要描述在提示词开发与测试的过程中,总结出来的经验。部分内容可能在前面已经提到,这里做下整体总结。1.提示词调试经验:提示词调试,调2-3次效果最好,无效立刻改提示词。在使用AI生成代码时,个人使用上发现个规律:首次生成基本达不到标准,第2、3次效果最佳,再往后使用就会出现更多各种各样的骚操作,所以一般两三次的效果还是比较可观的,就可以考虑采纳了;如果效果一直不好,那就考虑改改提示词吧。2.
本文来源公众号“阿里云开发者”,仅用于学术分享,侵权删,干货满满。
原文链接:https://mp.weixin.qq.com/s/PCQOiV5PgvkvuQqRsuMB6Q

-
业务场景:后端JAVA业务代码生成。
-
AI解决方案概述:从系分出发,解析提取其中核心内容,并生成任务列表,再让AI工具结合提示词完成任务(生成代码)。
-
工具选择:IDEA CodeFuse插件 + CodeFuse IDE。
-
使用效果概述:目前已经覆盖门面层代码的生成和修改、持久层代码的生成和修改、业务逻辑层的代码生成。已经正式投产到三个项目迭代中,参与项目已经上线。在应用了AI Coding的三个项目中,编码阶段的人日投入平均减少了40%。
文章略长,分(上)、(中)和(下)三部分。
五、代码检查
在完成代码生成后,需要保证代码的质量,只靠提示词中的约束和检查只是一部分,最好还是需要一些额外的措施来进行质量及规范检查。这里主要考虑的方式是使用规则匹配代码,然后根据规则匹配代码的最终产出检查报告,然后根据检查报告反向修改代码,得到终版代码。
这部分还在实验阶段,这里只描述进展和思路。
这里主要包含三方面检查
-
静态规则校验
-
动态校验
-
技术风险
5.1静态校验
在这里,我定义了三类静态校验规则,下面围绕这三类规则简单展开。
-
应用开发规范
-
JAVA代码规范
-
信贷术语规范
5.1.1规则规范
这三类规则主要是为了检查当前生成的代码是否符合当前应用的代码风格以及架构要求,以及在一些内容定义上是否符合业务背景,其次就是因为虽然当前很多大模型已经集成了《阿里JAVA开发规范》,但是对于使用者来讲,到底集成了哪些、是否生成的代码一定符合规范、直接使用大模型的java规范进行检查是否全面,都是难解的问题,所以这里选择自己定义一些JAVA开发规则,来进行代码检查。
系统规范案例
- **rule_code**: "FACADE_PATH_DEFINE_CHECK"- **description**: "Facade接口检查,Facade接口必须位于`app/facade/src/main/java/com/xxx/userapp/facade/api/业务名称`的目录下"- **check_list**:- "检查文件路径是否符合规范"- **matching_rule**: "^app/facade/src/main/java/com/xxx/userapp/facade/api/"- **example**:- **valid**: "app/facade/src/main/java/com/xxx/userapp/facade/api/user/UserFacade.java"- **invalid**: "app/core/src/main/java/com/xxx/userapp/facade/UserFacade.java"
阿里JAVA开发规范
- **rule_code**: "NAMING_ABSTRACT_CLASS"- **description**: "抽象类命名使用Abstract或Base开头"- **check_list**:- "检查抽象类名是否以Abstract或Base开头"- **matching_rule**: "^Abstract[A-Z][a-zA-Z]+|^Base[A-Z][a-zA-Z]+"- **example**:- **valid**: "AbstractClass", "BaseClass"- **invalid**: "Class", "Abstractclass"
信贷术语规范
- **rule_code**: "NAMING_CREDIT_APPLICATION"- **description**: "授信申请字段命名应包含Credit或具体授信相关的英文术语"- **check_list**:- "检查字段注释是否包含‘授信申请’或相关中文术语"- "检查字段名是否包含Credit或具体授信相关的英文术语(如CreditApplicationID、CreditLimit等)"- **matching_rule**: "^[a-zA-Z]*Credit[a-zA-Z]*$|^[a-zA-Z]*(Application|Limit|Available|Used)[a-zA-Z]*$"- **example**:- **valid**:- "CreditApplicationID" (授信申请ID)- "AvailableCreditBalance" (可用授信余额)- **invalid**:- "Credit_Application_ID" (不符合驼峰命名)- "creditapplicationid" (未符合驼峰规则)
5.1.2应用规则库
对于这种规范如果作为提示词或者一个markdown文件放到本地,也行,但是管理上总归不太规范,所以这里选择放到KIS平台中存储,然后通过MCP Server来进行使用。
5.1.3检查结果
这里可以使用CodeFuse IDE,它集成了很多MCP Server,或者将规则放到本地都可以,在引用java文件后让其按照规则进行检查。最后可以生成一份报告,我们可以通过报告来修改检查出来的问题。
5.2动态校验
目前我们对于代码检查自测,基本用的都是单元测试和集成测试。
这里推荐使用一个工具--EvoTest来生成单测和集成测试用例,前段时间一直和其团队合作,优化使用流程。
5.3技术风险
对于生成出来的代码进行校验,其中一个校验方式就是先看其出入参数是否有问题,这里我们使用Agent编排平台做了一个契约对比Agent,用于对比我们接口调用结果和系分中的接口契约是否一致。
对于契约对比Agent的使用,首先我们在接口设计中,定义了接口契约的约束,然后将实际调用的结果JSON输入到Agent中,最终获得对比结果表格。在表格中可以输出哪些字段不符合规范或者缺失,由此来检查代码问题。
5.4总结
这里限制过多,当规则变多、以及被检查的代码量变多后,所有规则是否都被检查到、所有代码是否都被检查就很难保证,不过在初期阶段,规则范围小且对少量代码进行检查时,还是可以检查出一些问题的。
目前正常尝试使用此方式来检查代码的规范和语法是否符合要求,后面会探索更加规范的的流程,来通过检查来保证AI Coding的最终质量。
六、经验总结
本章节主要描述在提示词开发与测试的过程中,总结出来的经验。
部分内容可能在前面已经提到,这里做下整体总结。
1.提示词调试经验:提示词调试,调2-3次效果最好,无效立刻改提示词。
在使用AI生成代码时,个人使用上发现个规律:首次生成基本达不到标准,第2、3次效果最佳,再往后使用就会出现更多各种各样的骚操作,所以一般两三次的效果还是比较可观的,就可以考虑采纳了;如果效果一直不好,那就考虑改改提示词吧。
2.被操作/读取内容结构也很重要,被操作/读取内容结构混乱,也会影响最终效果。
任务提取阶段是最容易出现问题的,因为它可能因为标题内容与系分中其他位置的文案一致,而因为文字匹配问题导致提取内容有误,需要根据标题名称在全文搜索是否出现次数过多而影响大模型的结果读取。
最好的方式是制定一个独特不重复的标题,使得内容提取时更好的锚定到目标内容。
3.模版类代码生成经验:添加代码案例提升代码准确度以及保证代码风格。
在生成门面层和持久层代码时,其实其内容大致差不多,如果通过添加约束以及各种架构文档描述来让它生成代码,个人认为会很难控制它的幻觉。所以在生成此类代码时,我建议直接添加代码案例到提示词中,说这提供代码目录让其参考,这样生成出来的代码不仅准确,且对于命名、方法抽象等代码风格都在可控范围内。
在提示词中添加案例后,门面层和持久层的生成相对问题较少,一般两次生成即可完全采纳且无问题。常见场景一般是某个复杂模型的convert有问题、JSON和复杂对象的转化偶现问题,或者忘记import包,一般简单调整即可采纳。或者在案例中重点提示此处注意事项,也能减少小问题的出现。
4.非100%采纳是否要重新生成:人工修改时间和重新生成时间的各自的对比后决策。
一些简单流程(模型赋值和组装的上下文清晰;业务逻辑执行所需外部能力在代码里已经基本都定义好了,且也不会对外部能力的返回结果做很多复杂的操作),个人测试基本没什么问题。
如果流程过于复杂,新生成的业务流程代码是否采纳,就需要人工分析‘人工修改时间和重新生成时间的各自占比’。如果生成出来的内容在我们看来已经差不多了,错误内容通过几分钟内容人工调整就可以完成、且遗漏/错误内容觉得AI通过现有内容也无法生成/修改成功,那我们就可以选择采纳了。如果不然,可以分析是大模型不行、还是提示词不行、还是流程图不够细致,从而从中修改来重新生成。
5.分步执行,将最准确的内容提供给大模型来生成结果。
一个人尽皆知的点:给Ai的描述越准确,它生成的内容越准。所以我们要做到喂给大模型的内容是最全面且准确的,当我们无法直接做到这一步时,就需要将不明确的内容转化为明确的内容,那就需要在整体流程中添加很多”增强层“,来提高最终准确性。
在业务逻辑代码生成时,一定是要依赖一段流程描述或者流程图的。让开发同学绘制流程图的时候使用伪代码属实不妥,使用白话文描述流程更加清晰直白,由此发现从流程图到代码生成中,是缺少一步的。所以要给予流程图应用内部知识,使白话文流程图转化为带有系统知识的伪代码流程图。
6.如何减少大模型推理的幻觉:定义推理范围以及推理约束,引导大模型推理方向,减少莫名其妙的yy。
在代码生成时,如果不添加约束,多数都会出现一些大模型yy的额外步骤。并且对于我们来讲大模型很黑盒,哪怕看了一些文档知道其“大概原理”,也是很难通过提示词很好的约束大模型的幻觉产生。个人推到此类幻觉都是大模型凭借自己“经验”进行“推理”产生的。
这里我的看法是,提前定义推理范围,让其在指定场景进行推理,并且告知其推理方向进行引导,从而使其的推理尽量在我们的掌控中。
在业务代码以及流程图增强中,都使用了此方法,没有让其直接根据业务术语自己去yy一些对象定义以及服务的使用,都是引导按照我们的思路去寻找答案,提高最终准确性的同时,减少幻觉。
7.点对点解决幻觉:有果必有因。
在给大模型很明确的指令以及案例参考时,大模型很容易因为某些点‘我们以为我们描述清楚了’,但是‘大模型理解的是另一个意思’而导致最终结果不好,并且此类问题很难发现问题原因。
在经过不断的和大模型交互问答‘为什么会出现这个问题?‘,以及不断修改提示词,最后发现了这个结论。就是有时候大模型理解的和我们描述的真的可能不是一个意思。所以如果频繁出现同一幻觉,或者添加约束也解决不了问题时,可能不是大模型的问题,要仔细检查自己是不是哪描述的容易歧义,然后进行修改。
8.提示词与大模型交互经验:提示词大而全并非好,要尝试与大模型交互看效果;结构化提示词,避免提示词前后冲突与内容分散。
因为一些幻觉或者其他被叫做“保底回答”的原因,使得我们总是需要添加一些约束,最后变成了提示词列了几十条约束,而且还约束不住。后来通过多次和大模型的交互,可以简单的发现一些大模型自带的约束以及规则。此类规则就可以从我们的规则和约束就可以从我们的提示词中删掉了。
当内容过多时,很容易出现前后语义不一,内容分散、约束冲突等问题,反而降低效果。所以对于提示词一定要定义一套标准结构,各章节边界清晰。
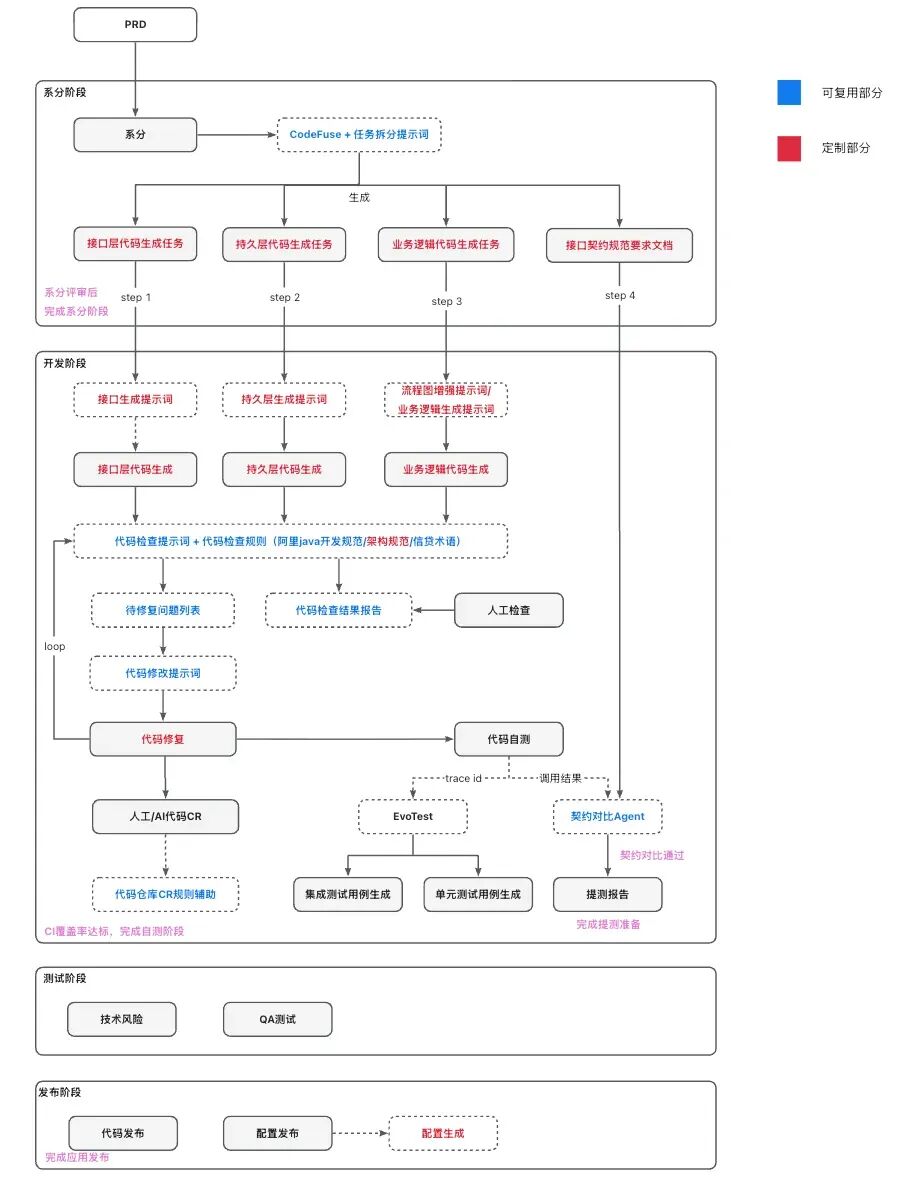
七、整体流程图
整体流程图如下:
八、实际效果
当前将内部两个应用作为AI Coding 为试点,已经在两个项目中使用以上内容,实际案例及效果如下:
-
项目一
-
生成内容:新增2个接口及2张数据表,总计生成代码约2300行左右(AI统计),占比约70%。
-
生成效果:AI生成代码总计耗时1h,无人工修改,直接采纳且通过测试,QA未提交生成内容相关的缺陷,现已上线。
-
项目二
-
生成内容:新增4个接口,总计生成代码约2800行左右(研发效能平台统计),占比约60%。
-
生成效果:预期开发8人日,实际开发4.5人日,减少45%人日。
-
项目三
-
生成内容:新增35个接口及9张DB表,生成接口定义类内容(interface、request、result、DTO)、领域模型定义、接口实现基础内容、转换类,以及持久层中从mapper、repo、service到其中DO和领域模型的转换类等能力共计生成代码30000+行。
-
生成效果:总计2人日完成全量生成门面层及持久层全量代码生成,减少机械式编码时间约80%,帮助项目快速启动。
九、后续方向
最终还是向着更流畅的串联从系分到代码这条路前进。当前AI Coding中,业务逻辑中的参数赋值、模型组装等内容还是通过引导大模型推理来生成的,目前还做不到100%采纳,可能存在部分字段赋值缺失或错误。和团队同学共同研究后,认为可以通过TDD的方式辅助AI Coding也是一个很好的方式。在生成代码后,根据系分以及已有的代码生成全链路覆盖的测试用例,并执行检查预期测试结果,然后再根据测试结果反向验证AI生成代码的结果是否准确,再将检查出来问题进行二次修改,达到最终生成结果的准确性。做到从设计-编码-执行-测试-修改的动作闭环,完成真正的自主式Java开发智能体。
对于一些其他工作,包括代码检查和配置生成,个人认为可以更好的应用MCP Server存储规范知识库来进行代码检查,以及使用工作流来进行配置生成,让其中各个步骤串联的更加顺畅,并且更多的使用外部工具来辅助流程串联及生码。
做AI生成代码最终想要达到的结果是通过系分将其中本迭代内所有的内容按照规范的流程陆续生成出来,现在因为工具和模型还没达到“最预期”内的状态,所以还需要优化提示词的同时等待工具和模型的升级。最终达到读取系分后生成所有任务,然后按照步骤陆续生成的最终结果。
对于其中提示词,考虑可以放到一些知识库的MCP Server里面。但是主要考虑两点比较容易影响结果,一方面是从知识库MCP Server中获取内容,可能因为工具原因而造成获取内容被截断。第二方面是知识库构造方式也很多,如果把不同提示词的内容因为名称相似给匹配成相关内容,会影响最终生成代码的效果。所以目前是放在本地的。
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 10
10 0
0- 0



 已为社区贡献148条内容
已为社区贡献148条内容

所有评论(0)