LangChain实战入门(二):RAG实战——赋予大模型你的私有知识库
LangChain的检索模块通过将文档加载、分割并向量化存储后,根据用户查询检索最相关的文本片段,最终将其作为上下文提供给大语言模型以生成精确的答案。
让AI真正读懂你的文档,构建专属知识问答系统
开篇回顾与本期聚焦
在上一篇文章中,我们学习了LangChain的Model I/O模块(直达飞机),掌握了与模型对话的"正确姿势"。现在,我们的读书笔记生成器已经能基于模型的已有知识生成内容,但这还远远不够。
想象一下这些真实场景:
-
你想让AI帮你分析公司内部的技术文档
-
你需要从最新的行业报告中提取关键信息
-
你想基于自己的读书笔记进行深度问答
这些都需要让模型能够访问它原本不知道的信息——这就是我们今天要解决的核心问题。
在本篇中,我们将解锁LangChain最强大的能力之一:Retrieval(检索),并构建一个真正能"读懂"你私有文档的智能问答系统。
一、基础理论:RAG与Retrieval模块
1. 什么是RAG?
RAG(Retrieval-Augmented Generation,检索增强生成) 是当前最流行的大模型应用范式。它的核心思想很简单:
当用户提问时,先从你的知识库中找到最相关的信息,然后将这些信息与问题一起交给大模型,让模型基于这些"参考资料"来生成答案。
这就好比开卷考试——模型不需要把所有知识都记在脑子里,但需要知道去哪里找答案。
2. LangChain的Retrieval模块核心组件
构建一个RAG系统,需要以下几个关键组件协同工作:
a) Document Loaders(文档加载器)
-
作用:从各种来源加载文档(PDF、TXT、Word、网页等)
-
示例:
PyPDFLoader,TextLoader,WebBaseLoader
b) Text Splitters(文本分割器)
-
为什么需要分割:大模型有上下文长度限制,长文档需要切成小块
-
分割策略:按字符、按标记、按段落等,保持语义完整性
-
示例:
RecursiveCharacterTextSplitter
c) Embedding Models(嵌入模型)
-
作用:将文本转换为数值向量( embeddings)
-
原理:语义相似的文本会有相似的向量表示
-
示例:OpenAI Embeddings、本地嵌入模型
d) Vector Stores(向量数据库)
-
作用:存储文档向量,支持相似度搜索
-
工作流程:存储文档块 + 查询时找到最相似的文档块
-
示例:Chroma, FAISS, Pinecone
e) Retrievers(检索器)
-
作用:封装整个检索流程,输入问题,返回相关文档
-
类型:向量检索、关键词检索、混合检索
LangChain的检索模块通过将文档加载、分割并向量化存储后,根据用户查询检索最相关的文本片段,最终将其作为上下文提供给大语言模型以生成精确的答案。
核心提炼:文档 → 分割 → 向量化存储 → 检索 → 增强提示 → LLM生成答案。
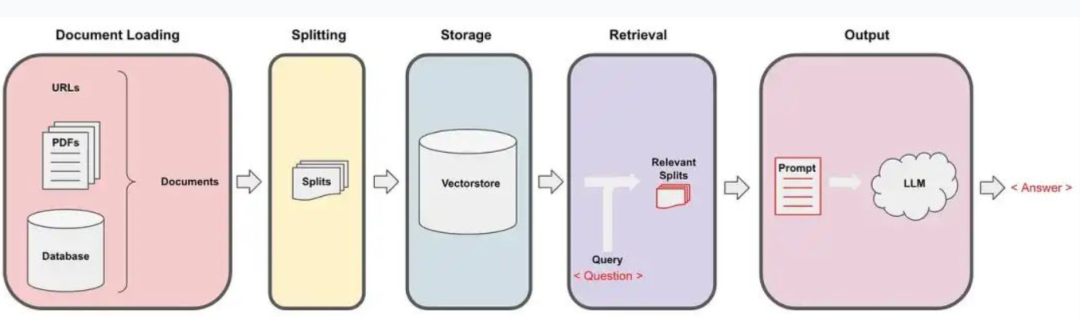
整体处理流程
二、项目实战:构建个人文档智能问答系统
现在,让我们构建一个能理解个人文档的智能问答系统。
项目目标:上传PDF或TXT文档,然后可以像与人对话一样向文档提问,获得基于文档内容的准确回答。
技术栈:LangChain Retrieval模块 + 本地向量数据库
完整代码如下:
import os
from typing import List
import requests
from langchain.prompts import ChatPromptTemplate
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import PyPDFLoader, TextLoader
# ==================== 全局配置 ====================
# 聚合平台 http://www.ufunai.cn 配置
BASE_URL = "https://api.ufunai.cn/v1"
API_KEY = "sk-xxxxx" # 替换为你的API密钥
MODEL_NAME = "gpt-4" # 指定要测试的模型名称
# 1. 自定义HTTP模型类(复用上篇代码)
class HTTPChatModel:
def __init__(self, base_url: str, api_key: str, model: str = "gpt-4"):
self.base_url = base_url
self.api_key = api_key
self.model = model
def invoke(self, messages: list) -> str:
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {self.api_key}"
}
payload = {
"model": self.model,
"messages": messages,
"temperature": 0.1, # 降低随机性,让回答更准确
"max_tokens": 800
}
try:
response = requests.post(
f"{self.base_url}/chat/completions",
headers=headers,
json=payload,
timeout=60
)
response.raise_for_status()
result = response.json()
return result["choices"][0]["message"]["content"]
except requests.exceptions.RequestException as e:
print(f"HTTP请求错误: {e}")
if hasattr(e, 'response') and e.response is not None:
print(f"响应内容: {e.response.text}")
raise
# 2. 自定义HTTP嵌入模型类
class HTTPEmbeddingModel:
def __init__(self, base_url: str, api_key: str):
self.base_url = base_url
self.api_key = api_key
def embed_documents(self, texts: List[str]) -> List[List[float]]:
"""为多个文本生成嵌入向量"""
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {self.api_key}"
}
embeddings = []
for text in texts:
payload = {
"input": text,
"model": "text-embedding-ada-002" # 或您使用的嵌入模型
}
try:
response = requests.post(
f"{self.base_url}/embeddings",
headers=headers,
json=payload,
timeout=30
)
response.raise_for_status()
result = response.json()
embeddings.append(result["data"][0]["embedding"])
except Exception as e:
print(f"生成嵌入向量失败: {e}")
raise
return embeddings
def embed_query(self, text: str) -> List[float]:
"""为单个查询文本生成嵌入向量"""
return self.embed_documents([text])[0]
# 3. 简单的内存向量存储
class SimpleVectorStore:
def __init__(self, embedding_model):
self.embedding_model = embedding_model
self.documents = []
self.embeddings = []
def add_documents(self, documents: List[str]):
"""添加文档到向量存储"""
print("正在生成文档向量...")
self.documents.extend(documents)
new_embeddings = self.embedding_model.embed_documents(documents)
self.embeddings.extend(new_embeddings)
print(f"成功添加 {len(documents)} 个文档块")
def similarity_search(self, query: str, k: int = 3) -> List[str]:
"""相似度搜索,返回最相关的k个文档"""
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
# 生成查询向量
query_embedding = self.embedding_model.embed_query(query)
query_embedding = np.array(query_embedding).reshape(1, -1)
# 计算相似度
doc_embeddings = np.array(self.embeddings)
similarities = cosine_similarity(query_embedding, doc_embeddings)[0]
# 获取最相似的文档
most_similar_indices = similarities.argsort()[-k:][::-1]
return [self.documents[i] for i in most_similar_indices]
# 4. 文档处理流程
def process_document(file_path: str) -> List[str]:
"""加载并分割文档"""
# 根据文件类型选择加载器
if file_path.lower().endswith('.pdf'):
loader = PyPDFLoader(file_path)
else:
loader = TextLoader(file_path, encoding='utf-8')
documents = loader.load()
print(f"成功加载文档,共 {len(documents)} 页")
# 分割文本
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # 每个块的大小
chunk_overlap=200, # 块之间的重叠
length_function=len,
)
chunks = text_splitter.split_documents(documents)
chunk_texts = [chunk.page_content for chunk in chunks]
print(f"文档分割完成,共 {len(chunk_texts)} 个文本块")
return chunk_texts
# 5. 初始化组件
print("初始化组件...")
chat_model = HTTPChatModel(
base_url=BASE_URL,
api_key=API_KEY,
model="gpt-4"
)
embedding_model = HTTPEmbeddingModel(
base_url=BASE_URL,
api_key=API_KEY
)
vector_store = SimpleVectorStore(embedding_model)
# 6. 构建RAG问答链
def create_rag_chain():
"""创建RAG问答链"""
template = """
你是一个专业的文档分析助手。请基于以下上下文信息回答问题。如果上下文信息中没有答案,请如实告知,不要编造信息。
上下文信息:
{context}
问题:{question}
请根据上下文信息提供准确的回答:
"""
prompt = ChatPromptTemplate.from_template(template)
def rag_chain(question: str, context: List[str]) -> str:
# 构建提示词
context_text = "\n\n".join(context)
formatted_prompt = prompt.format(context=context_text, question=question)
# 调用模型
messages = [
{"role": "system", "content": "你是一个专业、准确的文档分析助手。"},
{"role": "user", "content": formatted_prompt}
]
response = chat_model.invoke(messages)
return response
return rag_chain
# 7. 主程序
def main():
# 处理文档
file_path = "sample.pdf" # 替换为您的文档路径
if not os.path.exists(file_path):
# 如果没有文档,创建一个示例文档
with open("sample.txt", "w", encoding="utf-8") as f:
f.write("""
LangChain是一个用于开发由语言模型驱动的应用程序的框架。
它允许开发者将语言模型与外部数据源连接起来,并与之交互。
LangChain的主要价值在于:它能够将语言模型与数据源连接起来,并允许语言模型与它们的环境交互。
LangChain的核心模块包括:
1. Model I/O: 负责与语言模型交互
2. Retrieval: 用于从外部数据源检索信息
3. Agents: 允许语言模型决定采取什么行动
4. Chains: 将多个组件组合成工作流
5. Memory: 在对话之间持久化状态
6. Callbacks: 进行日志的打印、监控,以及流式传输等其他任务。
RAG(检索增强生成)是LangChain的一个重要应用场景。
它通过从知识库中检索相关信息,然后基于这些信息生成回答,从而提高了回答的准确性。
""")
file_path = "sample.txt"
print("已创建示例文档:sample.txt")
print("开始处理文档...")
chunks = process_document(file_path)
# 构建向量存储
print("构建向量数据库...")
vector_store.add_documents(chunks)
print("向量数据库构建完成!")
# 创建RAG链
rag_chain = create_rag_chain()
# 交互式问答
print("\n 文档问答系统已就绪!")
print("输入您的问题(输入'退出'结束对话)")
while True:
question = input("\n您的问题:").strip()
if question.lower() in ['退出', 'exit', 'quit']:
break
if not question:
continue
print("正在检索相关信息...")
# 检索相关文档块
relevant_docs = vector_store.similarity_search(question, k=3)
print("生成回答...")
# 基于检索到的文档生成回答
answer = rag_chain(question, relevant_docs)
print(f"\n 基于文档的回答:")
print(f"{answer}")
# 显示参考来源(可选)
print(f"\n 参考了 {len(relevant_docs)} 个文档块")
if __name__ == "__main__":
main()代码深度解析:
-
自定义HTTP嵌入模型 (
HTTPEmbeddingModel):-
通过HTTP调用嵌入模型API,将文本转换为向量
-
支持批量处理文档和单个查询
-
-
简易向量存储 (
SimpleVectorStore):-
使用内存存储文档和向量
-
基于余弦相似度实现检索功能
-
避免引入复杂的向量数据库依赖
-
文档解析及文档检索使用相同的向量模型
-
-
文档处理流水线 (
process_document):-
自动识别文档类型(PDF/TXT)
-
智能分割文本,保持语义连贯性
-
处理长文档的分块策略
-
-
RAG问答链 (
create_rag_chain):-
将检索到的文档作为上下文注入提示词
-
确保回答严格基于提供的文档内容
-
防止模型"幻觉"(编造信息)
-
运行效果演示:
初始化组件...
已创建示例文档:sample.txt
开始处理文档...
成功加载文档,共 1 页
文档分割完成,共 1 个文本块
构建向量数据库...
正在生成文档向量...
成功添加 1 个文档块
向量数据库构建完成!
文档问答系统已就绪!
输入您的问题(输入'退出'结束对话)
您的问题:LangChain是什么, 用通俗易懂的方式给我讲一下
正在检索相关信息...
生成回答...
基于文档的回答:
LangChain是一个开发框架,专门用于创建由语言模型驱动的应用程序。简单来说,它就像是一个工具箱,帮助开发者将智能语言模型(比如聊天机器人或自动回复系统)与外部的数据源(如数据库或互联网信息)连接起来。这样,语言模型不仅可以“说话”,还能根据外部信息来“思考”和做出更加智能的回应。
LangChain的核心功能包括与语言模型的交互、从外部数据源检索信息、决定采取何种行动、将多个功能组合成一个流程、在对话中保持记忆以及执行日志打印和监控等任务。通过这些功能,LangChain能够让语言模型在提供回答时更加精准和有用。
参考了 1 个文档块
三、高级优化技巧
在实际应用中,我们可以进一步优化这个系统:
1. 混合检索策略
# 结合向量检索和关键词检索
def hybrid_search(query: str, k: int = 3):
# 向量检索
vector_results = vector_store.similarity_search(query, k=k)
# 关键词检索(简单实现)
keyword_results = []
for doc in vector_store.documents:
if any(keyword.lower() in doc.lower() for keyword in query.split()):
keyword_results.append(doc)
# 合并结果并去重
all_results = vector_results + keyword_results
return list(dict.fromkeys(all_results))[:k]实际场景可以结合其他数据库和外挂知识库的数据一起来整合检索结果!
2. 重新排序优化
在初步检索后,使用更精细的模型对结果进行重新排序,提升最相关文档的排名。
3. 元数据过滤
为文档块添加元数据(如章节、日期等),支持基于元数据的过滤检索。
高级优化技巧,大家可以拿实际场景自己去尝试!
四、总结与预告
通过本篇的学习,我们成功构建了一个完整的RAG系统,让大模型能够基于私有知识库进行智能问答。
本篇核心收获:
-
RAG范式:理解了检索增强生成的完整流程和价值
-
Retrieval模块:掌握了文档加载、分割、向量化、检索的全套工具
-
HTTP集成:学会了用纯HTTP请求构建完整的AI应用
-
实战能力:具备了构建私有知识问答系统的实际技能
生产环境建议:
-
对于正式项目,建议使用专业的向量数据库(Chroma、Pinecone等)
-
添加错误处理和重试机制,提高系统稳定性
-
考虑缓存机制,减少重复的嵌入计算
下一篇预告:现在,我们的系统已经能够"查阅资料"来回答问题。但如果我们想让AI不仅会查资料,还能主动使用工具——比如上网搜索、执行计算、操作数据库——那该怎么办?
在《LangChain实战入门(三):Agents实战——让AI成为能思考、会行动的数字员工》中,我们将探索LangChain最令人兴奋的Agents模块,打造能够自主使用工具的AI智能体!
另:需要源码的同学,请关注微信公众号(优趣AI)在留言区评论获取!!!
创作不易,码字更不易,如果觉得这篇文章对你有帮助,记得点个关注、在看或收藏,给作者一点鼓励吧~

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 28
28 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)