【AAAI 2025】卷积与Transformer大一统!M-WSAttention让图像恢复效果焕然一新
在自监督图像去噪(SSID)领域,盲点网络(Blind-Spot Network, BSN)是一种主流架构。然而,现有BSN多基于卷积(CNN)实现,其在捕获长距离依赖方面存在固有局限。尽管Transformer在多种图像恢复任务中展现了超越CNN的潜力,但其核心的自注意力机制可能与BSN严格的“盲点约束”相冲突,导致模型直接“看到”并学习输入噪声,从而限制了其在SSID中的应用。本文系统性地分析

论文标题:Rethinking Transformer-Based Blind-Spot Network for Self-Supervised Image Denoising
论文地址:https://arxiv.org/pdf/2404.07846
01 摘要
在自监督图像去噪(SSID)领域,盲点网络(Blind-Spot Network, BSN)是一种主流架构。然而,现有BSN多基于卷积(CNN)实现,其在捕获长距离依赖方面存在固有局限。尽管Transformer在多种图像恢复任务中展现了超越CNN的潜力,但其核心的自注意力机制可能与BSN严格的“盲点约束”相冲突,导致模型直接“看到”并学习输入噪声,从而限制了其在SSID中的应用。
本文系统性地分析并重新设计了Transformer中的通道和空间自注意力机制,使其适配盲点约束。
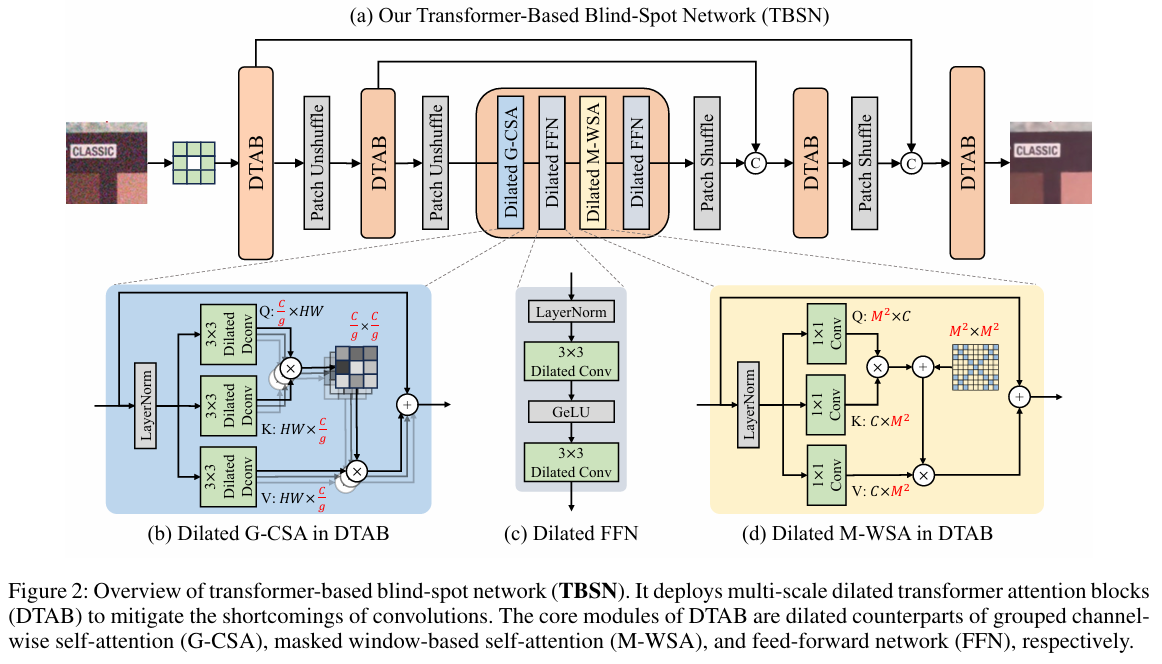
- 针对通道注意力:作者发现,在多尺度网络中,下采样操作(如Pixel Unshuffle)会将空间信息混洗(Shuffle)到通道维度。此时若进行全局通道注意力,会间接导致空间盲点信息的泄漏。为解决此问题,本文提出分组通道自注意力(Grouped Channel Self-Attention, G-CSA),通过将通道分组并独立进行组内注意力计算,有效隔绝了信息泄漏。
- 针对空间注意力:为在保持盲点约束的同时增强局部建模能力并扩大感受野,本文设计了掩膜窗口自注意力(Masked Window-based Self-Attention, M-WSA)。该机制通过在标准窗口注意力的相似度矩阵上施加一个固定的、模拟膨胀卷积采样模式的掩膜,使得每个查询(Query)只关注窗口内特定间隔位置的键(Key),从而在不“看到”中心像素的前提下,实现感受野的有效扩张。
基于上述设计,本文构建了一个名为TBSN (Transformer-Based Blind-Spot Network) 的新型去噪网络。该网络不仅具备通道注意力带来的全局感受野,也拥有窗口注意力赋予的强大局部内容拟合能力。此外,为解决BSN普遍存在的推理成本高昂的问题,本文提出了一种知识蒸馏方案,将训练好的TBSN作为教师模型,把其去噪知识蒸馏到一个轻量级U-Net学生模型(TBSN2UNet)中。实验证明,TBSN2UNet在性能几乎无损的情况下,显著降低了计算开销,提升了实用性。
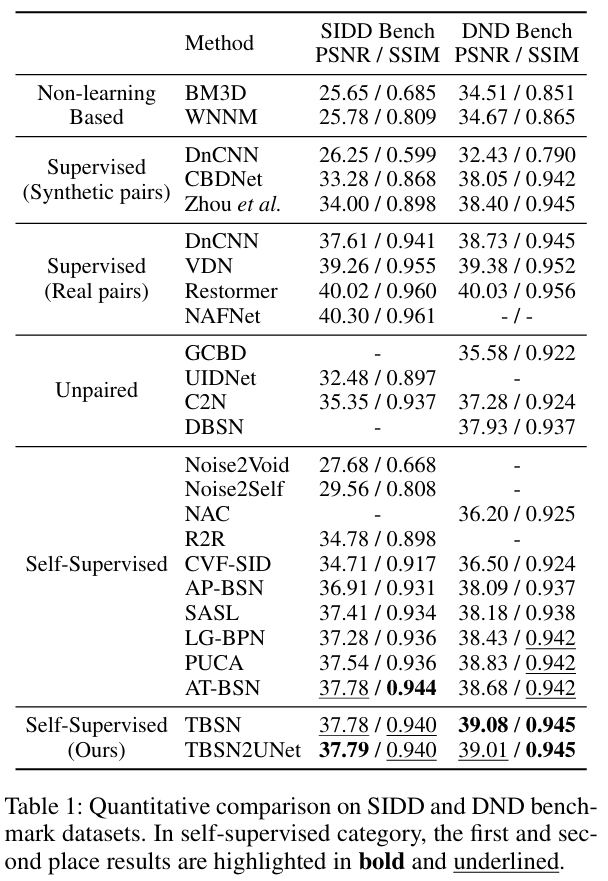
在SIDD和DND等真实世界去噪基准测试上,TBSN及其蒸馏版本均取得了当前自监督方法中最先进的性能。
02 核心创新点
1. 分组通道自注意力 (Grouped Channel Self-Attention, G-CSA)
-
问题:在U-Net等多尺度架构中,深层特征图的空间分辨率降低,而通道数剧增。下采样(如Patch Unshuffle)将局部空间邻域信息“折叠”进通道维度。此时,若像Restormer一样对所有通道进行全局自注意力计算,不同通道间的交互等价于间接实现了空间信息的交互,可能导致中心像素信息被泄露,违反盲点约束。
-
解决方案:G-CSA将输入特征的通道维度 C C C 划分为 G G G 个组,每个组包含 C g = C / G C_g = C/G Cg=C/G 个通道。注意力计算只在每个组内部独立进行,从而阻止了可能泄露空间信息的跨组通道交互。在实践中,通过控制组内通道数 C g C_g Cg 小于当前特征图的空间分辨率( H × W H \times W H×W),可以有效规避信息泄漏风险。
G-CSA的公式化表达如下,其中 ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅) 代表组内的通道注意力操作:
G-CSA ( X ) = Concat ( ϕ ( X 1 ) , ϕ ( X 2 ) , … , ϕ ( X G ) ) \text{G-CSA}(X) = \text{Concat}(\phi(X_1), \phi(X_2), \dots, \phi(X_G)) G-CSA(X)=Concat(ϕ(X1),ϕ(X2),…,ϕ(XG))
其中 X = Concat ( X 1 , X 2 , … , X G ) X = \text{Concat}(X_1, X_2, \dots, X_G) X=Concat(X1,X2,…,XG)。
2. 掩膜窗口自注意力 (Masked Window-based Self-Attention, M-WSA)
-
动机:传统的BSN依赖膨胀卷积(Dilated Convolution)来扩大感受野并维持盲点。作者旨在设计一种自注意力机制,以模拟膨胀卷积的行为,同时利用注意力机制强大的内容自适应建模能力。
-
解决方案:M-WSA在标准的窗口自注意力(Window-based Self-Attention)基础上进行修改。其核心是在计算注意力得分后,加上一个固定的二进制掩膜矩阵 M \mathbf{M} M。这个掩膜使得每个查询像素只能关注窗口内坐标差值为偶数的像素,如同膨胀率为2的膨胀卷积采样。
M-WSA的注意力计算公式如下:
Attention ( Q , K , V ) = SoftMax ( Q K T d + M ) V \text{Attention}(Q, K, V) = \text{SoftMax}(\frac{QK^T}{\sqrt{d}} + \mathbf{M})V Attention(Q,K,V)=SoftMax(dQKT+M)V
其中,掩膜矩阵 M \mathbf{M} M 的定义为:
M ( i , j ) = { 0 , if x i − x j ≡ 0 ( m o d 2 ) and y i − y j ≡ 0 ( m o d 2 ) − ∞ , otherwise \mathbf{M}(i, j) = \begin{cases} 0, & \text{if } x_i - x_j \equiv 0 \pmod{2} \text{ and } y_i - y_j \equiv 0 \pmod{2} \\ -\infty, & \text{otherwise} \end{cases} M(i,j)={0,−∞,if xi−xj≡0(mod2) and yi−yj≡0(mod2)otherwise
( x i , y i ) (x_i, y_i) (xi,yi) 和 ( x j , y j ) (x_j, y_j) (xj,yj) 分别是Token i i i 和 j j j 在窗口内的二维坐标。当相对位移在x和y方向上均为偶数时,掩膜值为0(允许关注);否则为负无穷(禁止关注)。
M-WSA作为一个即插即用的算子,能够在不破坏盲点约束的前提下,有效替代或补充传统膨胀卷积,为网络提供更强的局部特征拟合能力和更大的感受野。
03 方法详解
1. 整体网络架构 (TBSN)
TBSN的整体架构是一个对称的U-Net编解码器,专为满足全程盲点约束而设计。
- 骨干:标准的U-Net结构。
- 盲点建立:网络第一层采用一个3×3的中心遮挡卷积(Center-masked Convolution),即卷积核中心权重为0,从而在初始阶段就建立了盲点。
- 尺度变换:下采样和上采样分别采用 Patch Unshuffle 和 Patch Shuffle(即PixelShuffle的逆/正操作)。这些操作仅重排像素而不进行计算,能完美保持盲点特性,同时将空间信息和通道信息相互转化。
- 核心模块:在U-Net的每个尺度层级,堆叠多个膨胀Transformer注意力块(Dilated Transformer Attention Block, DTAB)。
2. 膨胀Transformer注意力块 (DTAB)
DTAB是TBSN的核心构建单元,它有机地结合了G-CSA和M-WSA,并确保所有操作均满足盲点约束。一个DTAB的流程如下:Dilated G-CSA → Dilated FFN → Dilated M-WSA → Dilated FFN
其中,每个操作前后都伴随着LayerNorm和残差连接。
- Dilated G-CSA:即前述的分组通道自注意力。模块内部用于生成Q, K, V的卷积层均替换为膨胀卷积,以维持盲点。
- Dilated M-WSA:即前述的掩膜窗口自注意力。
- Dilated FFN:标准的前馈网络(Feed-Forward Network),通常由两个线性层(本文实现为1x1卷积)和激活函数(如GeLU)组成。为了维持盲点,其中的卷积层也替换为膨胀卷积。
通过G-CSA和M-WSA的交替执行,DTAB能够在一次处理中同时完成全局(通道间)和局部(空间窗口内)的信息交互与特征提炼。
3. 高效推理的知识蒸馏 (TBSN2UNet)
尽管TBSN性能强大,但其基于Transformer的复杂结构导致推理成本较高。为了实现高效部署,作者设计了一套简单的知识蒸馏方案:
-
教师模型:预训练好的、性能强大的TBSN。
-
学生模型:一个轻量级的标准U-Net架构。
-
蒸馏过程:将训练集中的噪声图像输入教师TBSN,得到高质量的去噪结果。这些结果被视为“伪真值(Pseudo Ground-Truths)”。然后,以这些伪真值作为监督信号,采用L1损失训练学生U-Net。
蒸馏损失函数如下:
L distill = ∣ ∣ sg ( TBSN ( y ) ) − U-Net ( y ) ∣ ∣ 1 \mathcal{L}_{\text{distill}} = || \text{sg}(\text{TBSN}(y)) - \text{U-Net}(y) ||_1 Ldistill=∣∣sg(TBSN(y))−U-Net(y)∣∣1
其中 y y y 是噪声图像, sg ( ⋅ ) \text{sg}(\cdot) sg(⋅) 表示停止梯度(stop-gradient)操作,确保教师模型的参数不被更新。
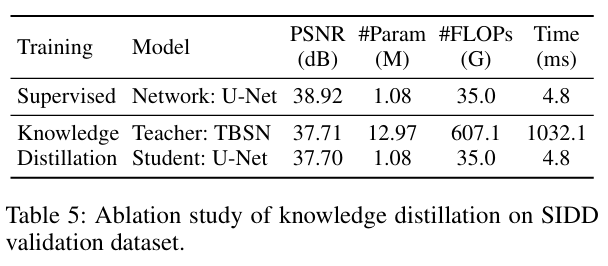
实验结果表明,学生模型TBSN2UNet在参数量和计算量(FLOPs)远低于TBSN的情况下(与轻量CNN模型SASL相当),PSNR指标几乎没有下降,证明了该策略的有效性。
04 实验与结论
- 性能:在SIDD和DND真实噪声数据集上,TBSN无论在PSNR/SSIM等定量指标还是视觉质量上,均显著优于先前的自监督去噪方法(如AP-BSN, LG-BPN, PUCA等)。TBSN2UNet在保持极高效率的同时,性能也超越了大部分SOTA方法。
- 有效感受野:可视化分析证实,得益于G-CSA和M-WSA,TBSN相比以往的BSN方法,具有显著更大的有效感受野和更强的局部细节拟合能力。

总结:本文成功地将Transformer架构引入盲点网络,通过精心设计的G-CSA和M-WSA解决了注意力机制与盲点约束的冲突,构建了性能强大的TBSN模型。同时,提出的知识蒸馏方案有效解决了复杂模型的部署难题。这项工作为自监督图像恢复领域中Transformer的应用开辟了新的道路,并为设计兼顾性能与效率的去噪模型提供了宝贵的思路。
05 即插即用模块
import numpy as np
import torch
if __name__ == '__main__':
tbsn_psnrs = torch.zeros((1280))
unet_psnrs = torch.zeros((1280))
with open('validate/tbsn.txt', 'r') as f:
for i in range(1280):
psnr = float(f.readline())
tbsn_psnrs[i] = psnr
with open('validate/unet.txt', 'r') as f:
for i in range(1280):
psnr = float(f.readline())
unet_psnrs[i] = psnr - 0.1
print('mean: ', torch.mean(tbsn_psnrs), torch.mean(unet_psnrs))
print('std: ', torch.std(tbsn_psnrs - unet_psnrs))
a = torch.abs(tbsn_psnrs - unet_psnrs)
count = 0
for i in range(1280):
if a[i] < 0.2:
count += 1
print(count)
indices = [(8, 20), (8, 23), (9, 5), (9, 8), (11, 29), (12, 19), (35, 0-21), (36, 0-21)]
indices = [276, 279, 293, 296, 381, 403, 1120, 1121, 1122, 1123,
1124, 1125, 1126, 1127, 1128, 1129, 1130, 1131, 1132, 1133,
1134, 1135, 1136, 1137, 1138, 1139, 1140, 1141, 1152, 1153,
1154, 1155, 1156, 1157, 1158, 1159, 1160, 1161, 1162, 1163,
1164, 1165, 1166, 1167, 1168, 1169, 1170, 1171, 1172, 1173]

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 9
9 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)