自由学习记录(110)
NVIDIA GPU架构演进与计算特性分析 摘要:本文梳理了NVIDIA GPU架构从Tesla到Ampere的演进历程,揭示了其从图形处理器向通用计算平台的转型过程。关键里程碑包括:2006年CUDA架构支持通用计算,2010年Fermi引入统一内存,2017年Volta推出专用TensorCore,2020年Ampere实现AI与图形计算的融合。GPU采用分层并行架构(SP→SM→TPC→GP
https://www.youtube.com/watch?v=kUqkOAU84bA
Ampere(2020):统一架构巅峰
-
A100 同时支持 Tensor Core、FP64、FP32、FP16 混合精度。
→ “一块芯片跑科学计算 + 深度学习 + 图形渲染”。
→ 是 NVIDIA 真正完成 GPU 平台化的时代。
Turing(2018):游戏与 AI 的融合
-
引入 RT Core(实时光线追踪)和 Tensor Core(AI 超分辨、DLSS)。
→ 游戏史上第一次在实时渲染中使用深度学习。
→ 同时兼顾图形 + AI 两条路线。
发布 DGX 系列服务器 专用 Tensor Core
Volta(2017):Tensor Core 的革命
-
增加专用 Tensor Core,单次能执行 4x4 矩阵乘。
→ 让深度学习训练速度提升 5–10 倍。
→ 同时发布 DGX 系列服务器,正式确立 “AI 计算平台” 战略。
推出 Tesla P100、GeForce GTX 1080。引入 NVLink 高速互联 Google 当年正用
Pascal(2016):深度学习时代的引爆点
-
推出 Tesla P100、GeForce GTX 1080。
-
首次引入 NVLink 高速互联。
-
Google 当年正用它训练第一版 AlphaGo。
→ Pascal 成为“AI GPU 元年”的象征。
Maxwell(2014):能效拐点
-
这是 NVIDIA 第一次以“性能/瓦”为核心设计目标。
-
让移动端(如笔记本 GPU、嵌入式 Jetson)成为可能。
→ “低功耗高并行”成为后续 GPU 设计理念。
动态并行(Dynamic Parallelism)。Kernel 可以在 GPU 内部再发 Kernel,不必回 CPU
Kepler(2012)与大规模并行革命
-
把单个 GPU 的核心数提升到千级(> 2000 CUDA cores)。
-
引入 动态并行(Dynamic Parallelism)。
→ Kernel 可以在 GPU 内部再发 Kernel,不必回 CPU。
→ 让 GPU 能在深度学习、物理仿真中完全独立执行复杂任务。
Fermi(2010):让 GPU 真正像 CPU 一样
-
引入 Cache 层级结构(L1/L2)和 Unified Address Space。
-
这意味着 GPU 可以更高效地访问内存,也能支持异常、断点调试。
→ GPU 第一次拥有“像 CPU 一样的控制流能力”,不是纯算数阵列。
CUDA 的诞生:2006–2008 的重大转折
-
GeForce 8800 (2006) 是第一块基于 Tesla 架构的 GPU,也是第一块支持 CUDA 的显卡。
-
这标志着 GPU 从“画图芯片”转型为“通用计算加速器”。
-
当时很多科研人员第一次发现——显卡不仅能渲染,还能算矩阵、模拟气候、训练神经网络。
→ 这直接催生了后来 GPU Computing 和 Deep Learning 革命。

独立执行(shared memory + cache) 在 TPC 层统一调度。
每个 SM 像一个小型并行计算节点,既能独立执行(shared memory + cache),又能在 TPC 层统一调度。
Geometry Controller 代表图形管线入口(几何/顶点阶段) Texture Unit + L1 是渲染阶段资源。
从几何控制器到纹理单元的垂直路径
顶部的 Geometry Controller 代表图形管线入口(几何/顶点阶段),底部的 Texture Unit + L1 是渲染阶段资源。
→ 图形管线从几何到纹理正好贯穿整个垂直层级。
→ 这显示出早期 GPU 在图形与通用计算融合前的“双重职责”:既能做渲染,又能跑计算。
一个 TPC 它可以同时发射多个指令集。含两个 SM 架构中扩展成 “每个 GPC 多个 SMX 并行”
两个 SM 并列 → “双发射”结构的雏形
一个 TPC 内含两个 SM,意味着它可以同时发射多个指令集。
→ 后来在 Fermi/Kepler 架构中扩展成 “每个 GPC 多个 SMX 并行”。
→ 这奠定了“SIMT + 多 SM 调度”的基本组织形式。
多重 Cache 层代表不同任务类型的优化
-
I-cache:指令缓存,负责存放 warp 的执行指令流。
-
C-cache:常量缓存,用于存储内核中不变的参数。
→ I-cache 优化线程调度,C-cache 减少寄存器与显存访问。
→ 这是 GPU 面向“大量线程执行同一代码”的设计哲学。
SFU(Special Function Unit)的存在说明 GPU 追求指令异构
SFU 专门处理数学函数(sin, cos, sqrt 等)。
→ 这些操作在 CPU 中是统一算术管线执行,但 GPU 为了吞吐量把它们独立出来。
→ 意味着 GPU 并不是一堆完全相同的核,而是多个异构功能模块协同。
“Shared Memory” 的位置揭示了 GPU 的核心思想
每个 SM 内部独立拥有一块 Shared Memory,被所有 SP 共享。
→ 它是比全局显存快几个数量级的“局部数据仓”。
→ CUDA 编程中“块内共享内存”的概念正对应这部分。
→ 高性能计算靠“就近计算”,不频繁访问 DRAM。
TPC(Texture Processor Cluster)
└── SMC(SM Cluster)
├── SM(Streaming Multiprocessor)
│ ├── SP(Streaming Processor)
│ ├── SFU(Special Function Unit)
│ ├── Shared Memory
│ └── I / C Cache
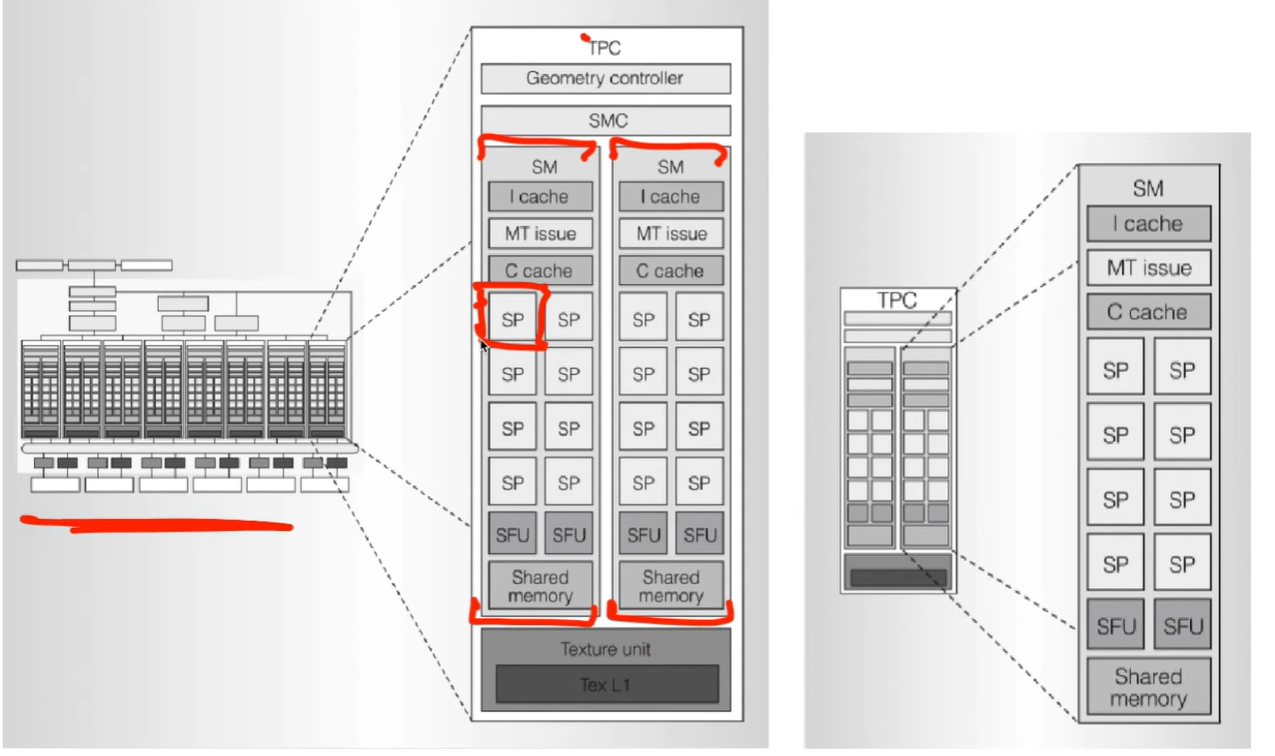
SP 是执行线程的“核心”,SM 是它们的“宿主”。
SM 框住 SP 表示“管理多个 SP 并共享寄存器、共享内存、调度单元等资源”。
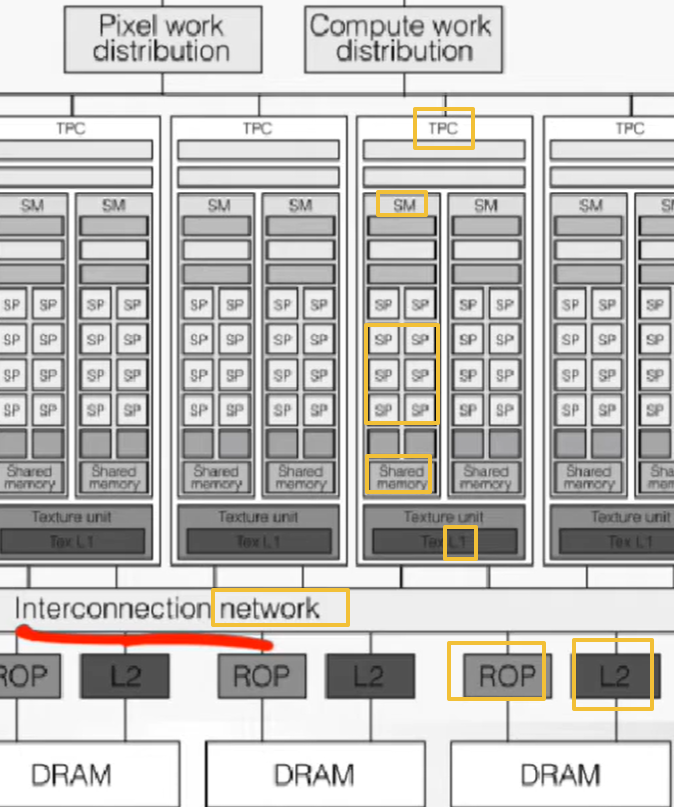
ROP 紧贴 L2 与 DRAM,说明它位于最终输出阶段。
→ 负责像素合并(blending)、深度测试(z-test)、抗锯齿等图像后处理。
→ 所以光栅化渲染完成后,结果直接写入显存(framebuffer)。
每个 SM 下方都有 Shared Memory 和 Tex L1(局部缓存)。
再往下是跨 TPC 的 L2 Cache,最终连接到 DRAM。
→ 形成三级内存体系:
SP 层 → Shared Memory → L2 → DRAM
→ CUDA 编程中常说的“内存层次优化”就是在利用这一层级减少全局访问延迟。
图中确实是 SM 框住 SP,顺序应理解为:
一个 SM(Streaming Multiprocessor)内部包含若干个 SP(Streaming Processor)。
结构层次(外层框住内层):SM ⊃ SP
逻辑组成(由小到大):SP → SM → TPC → GPC → GPU
GPU 的三个核心特征:
-
分层并行(SP→SM→TPC→GPC)
-
异构调度(图形与计算共享硬件)
-
层次内存架构(近数据计算理念)
Interconnection Network 是 GPU 的“心脏”
底部的 interconnection network 连接所有 TPC、ROP、L2。
→ 类似 CPU 的“片上总线”,但为高并行设计。
→ 决定了不同 SM、TPC 之间如何共享数据,是性能瓶颈之一。
(例如 NVIDIA 后来采用 NVLink、NVSwitch 优化这一部分。)
ROP(Raster Operations Processor)的位置透露渲染流程顺序
ROP 紧贴 L2 与 DRAM,说明它位于最终输出阶段。
→ 负责像素合并(blending)、深度测试(z-test)、抗锯齿等图像后处理。
→ 所以光栅化渲染完成后,结果直接写入显存(framebuffer)。
共享内存与缓存的层级反映“数据就近性”
每个 SM 下方都有 Shared Memory 和 Tex L1(局部缓存)。
再往下是跨 TPC 的 L2 Cache,最终连接到 DRAM。
→ 形成三级内存体系:
SP 层 → Shared Memory → L2 → DRAM
→ CUDA 编程中常说的“内存层次优化”就是在利用这一层级减少全局访问延迟。
-
Vertex work distribution:负责顶点阶段
-
Pixel work distribution:负责像素阶段
-
Compute work distribution:负责通用计算阶段(CUDA kernel)
靠调度逻辑区分执行路径。 图形与计算任务共用底层硬件(SM、SP)
每个 TPC 都能独立运行不同的任务批次(workload),这正是 GPU 高吞吐的根本
每个 SM 内又有多个 SP(Streaming Processor)。
每个 TPC(Texture/Processor Cluster)都包含多个 SM(Streaming Multiprocessor)
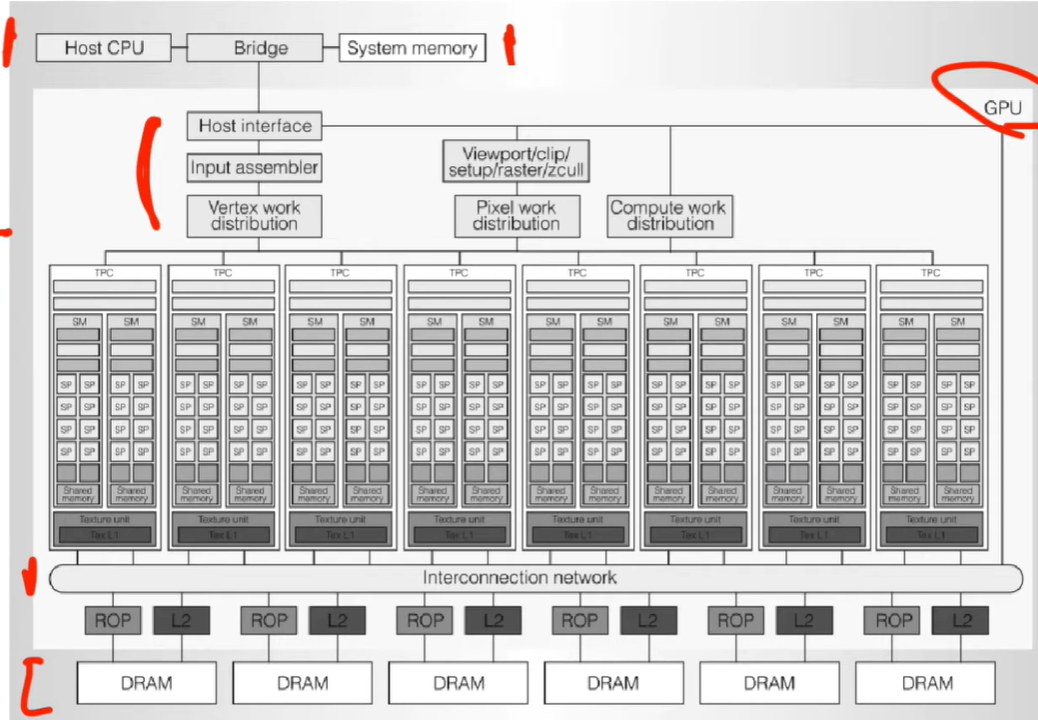
架构命名反映计算-图形双用途融合
TPC(Texture/Processor Cluster)说明早期 GPU 的计算单元仍与图形管线绑定。
后来 GPC(Graphics Processing Cluster)强化了“可并行执行图形与计算任务”的设计理念。
→ 从“图形集群”到“通用集群”的演化反映了 GPU 逐步转型为通用计算核心。
SP 与 DP 的并行性能差距
表中最后两项提醒一个关键现实:
-
SP(32-bit) 运算在消费级 GPU 中极快。
-
DP(64-bit) 通常只在专业卡(如 Tesla、A100)上高效。
→ 这是 NVIDIA 人为区分游戏显卡与科学计算显卡的重要手段之一。
“Streaming” 的含义
词根 streaming 表明数据是“连续流式”进入计算核心。
→ GPU 不是一次执行一个任务,而是不断接收指令流和数据流,批量调度执行。
→ 体现了 SIMT(Single Instruction, Multiple Threads) 模式的核心思想。
从底层到高层:SP → SM → TPC → GPC → GPU
即:多个 SP 组成一个 SM,多个 SM 组成一个 GPC。
→ GPU 的计算结构是层层嵌套的 分布式并行体系。
→ 每一层都可独立并行执行,但共享更高层资源(如寄存器、缓存)。
同缩写,不同语境
“SP” 同时代表两种完全不同的概念:
-
Streaming Processor:计算单元(执行线程的最小实体)
-
Single Precision:浮点数精度格式(32 位)
→ 这说明在 GPU 文献中,缩写必须依靠上下文判断含义。
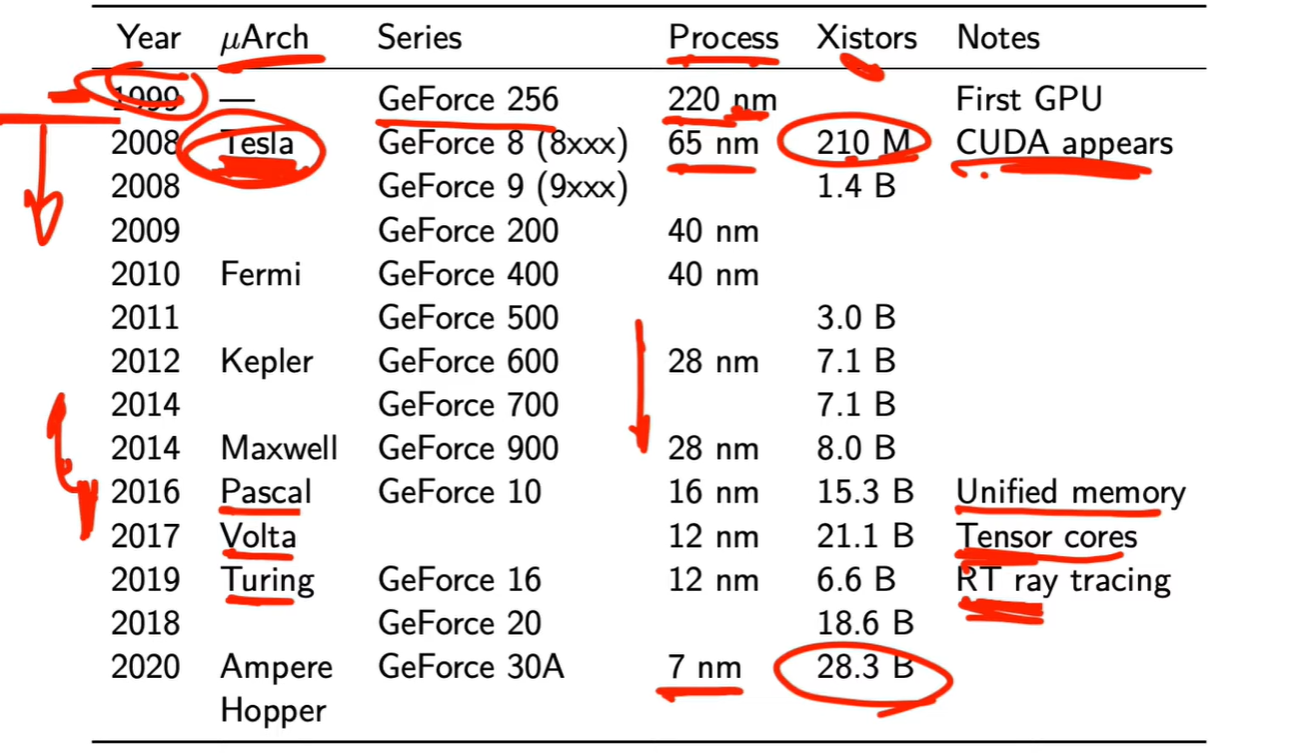
GeForce 系列编号与架构的同步关系
从 GeForce 8 系列开始,每一代架构(Tesla、Fermi、Kepler、Maxwell、Pascal、Turing、Ampere)大约对应一代显卡产品编号。
→ 例如 GeForce 10 → Pascal,GeForce 20 → Turing,GeForce 30 → Ampere。
这帮助开发者快速判断显卡的技术代际与特性。
Ampere (2020):结合 Tensor Core + RT Core,成为 RTX 系列全面 AI + 图形混合架构。
Turing (2019):首次引入 RT Core,实现实时光线追踪。
Volta (2017):首次引入 Tensor Core,专为矩阵乘法优化,为 AI 推理奠基。
Pascal (2016):再次强调 Unified Memory、能效显著提升。
Fermi (2010):引入统一内存 (Unified Memory),CPU 与 GPU 间数据交互更容易。
每一代架构的技术“里程碑”
从 1999 年的 220 nm / 210 M 晶体管到 2020 年的 7 nm / 28.3 B,
→ 晶体管数增长超过 100 倍。
→ 这直接支撑了并行线程数的暴增和深度学习的发展。
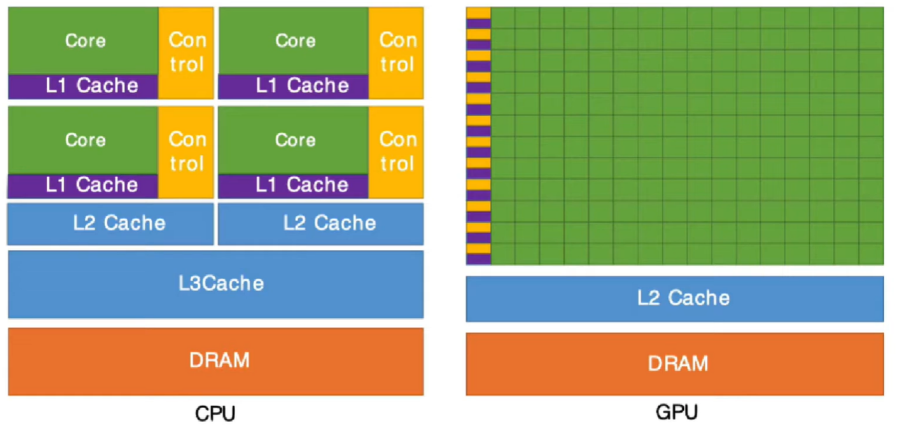
cpu
大量面积给了 Control(控制逻辑) 与多级缓存(L1、L2、L3)。
-
每个核心都能独立处理复杂任务(分支预测、系统调用、操作系统线程)。
gpu
绝大多数芯片面积都是 Core(计算单元)。
-
控制与缓存极少,L2 Cache 很薄。
-
没有分支预测、乱序执行、复杂调度。
-
数千个核心同时执行相同指令流(SIMT),适合大规模相似运算(矩阵乘法、像素计算)。
在计算机语境中,“intensive” 通常表示 对某类资源需求非常高或消耗量大。
-
CPU-intensive:大量计算、循环、数学运算,占用 CPU 时间高。
-
GPU-intensive:需要大规模并行计算或图形渲染,占用 GPU 高。
-
Memory-intensive:占用内存大,需要频繁访问大量数据。
-
I/O-intensive:主要瓶颈在磁盘、网络等输入输出操作。
一、2000–2006:GPU 仍是“图形加速器”
-
当时 GPU 只负责像素着色、顶点变换,精度要求不高,单精度浮点 (FP32) 足够。
-
游戏渲染追求速度而非数值精度,因此 FP64 单元完全没有意义。
二、2006–2010:GPGPU 概念兴起
-
研究人员开始尝试让 GPU 执行科学计算(如矩阵、流体、分子模拟)。
-
NVIDIA 推出 CUDA (2007),正式把 GPU 暴露为通用计算平台。
-
这时科学界提出需求:FP32 不够准,必须支持 FP64。
-
因此 NVIDIA 推出了 Tesla 系列,在相同架构下保留大量 FP64 单元。
三、2010–今:产品线正式分化
-
GeForce / RTX:主要面向图形、游戏、AI 推理 → 追求吞吐量 → 主要优化 FP32、FP16、Tensor Core。
-
Tesla / Quadro / A100 等:面向科学计算、AI 训练 → 追求精度 → 保留高比例 FP64。
-
同一代架构会在晶体中设计不同比例的计算单元:
-
例如 Kepler 架构 的 GeForce GTX 680(FP64:FP32 = 1:24)
-
而 Tesla K20X(同架构)则是 1:3
-
四、核心动因
| 驱动因素 | 说明 |
|---|---|
| 市场分层 | 游戏市场对 FP64 无需求,科研市场愿意为 FP64 支付高价。 |
| 功耗与面积权衡 | FP64 单元耗电、占面积多,减少它能提高游戏卡的频率与散热余量。 |
| 产品定价与区隔 | 人为限制 FP64 使 Tesla 与 GeForce 不竞争,维持专业卡高溢价。 |
| API 分化 | 游戏侧用 DirectX / Vulkan;科研侧用 CUDA / OpenCL / HPC 库。 |
同一块 GPU 芯片通常同时支持两种精度,只是**硬件资源分配比例不同**。 例如:某型号的 FP64 性能可能只有 FP32 的 1/24 或 1/32。出现这种设计分化的背景是 GPU 从“图形渲染专用硬件”演化为“通用计算平台” 的过程。
https://www.nvidia.com/en-gb/data-center/tesla-v100/
不是代替关系,而是并行发展
-
GeForce 系列自 2000 年代初面向消费市场。
-
Tesla 系列(2007 后)从相同架构中衍生,优化为通用计算(GPGPU)。
-
两者共享底层架构(如 Fermi、Kepler、Ampere),但驱动、散热、电源设计完全不同。
英伟达的两条产品线
| 系列 | 面向领域 | 典型型号 | 精度重点 | 驱动/生态 |
|---|---|---|---|---|
| GeForce / RTX | 消费级(游戏、创意、实时渲染) | GTX 1080、RTX 4090 | 强 FP32,弱 FP64(常被限制) | Game Ready Driver |
| Tesla / A100 / H100(现名 NVIDIA Data Center) | 数据中心、科研、AI、HPC | Tesla K40、V100、A100、H100 | 强 FP64(几乎等于 FP32 比例) | CUDA + HPC Driver |
简言之:
-
GeForce = 游戏卡,FP32 性能强,FP64 被人为阉割。
-
Tesla / A 系列 = 计算卡,FP64 性能完整,适合科学与 AI 训练。
同一块 GPU 芯片通常同时支持两种精度,只是硬件资源分配比例不同。
例如:某型号的 FP64 性能可能只有 FP32 的 1/24 或 1/32。
不是两种 GPU,而是同一种 GPU 架构在不同产品线和计算模式下的分化。
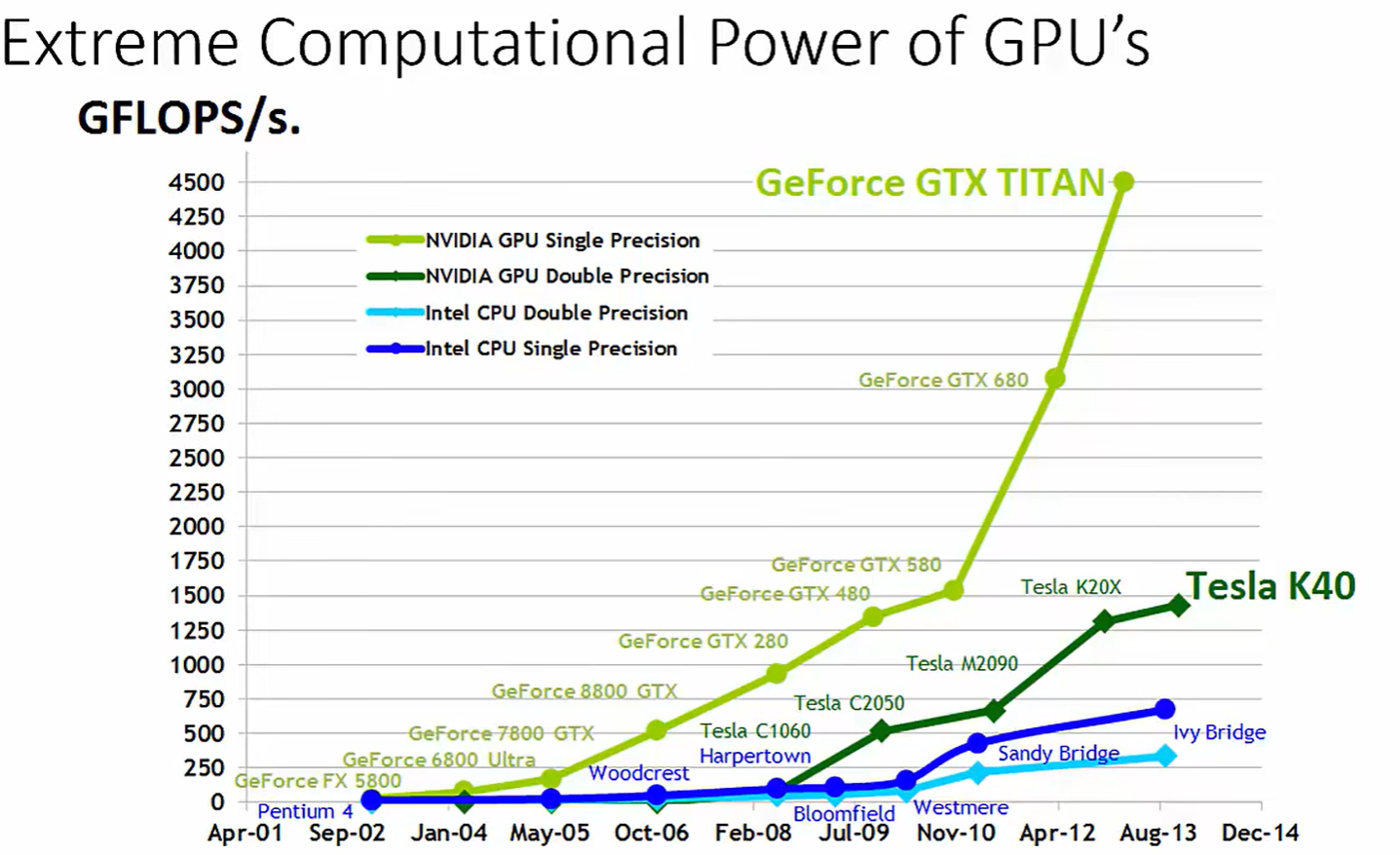
颜色含义:
浅绿色:NVIDIA GPU 单精度(FP32)性能
深绿色:NVIDIA GPU 双精度(FP64)性能
浅蓝色:Intel CPU 双精度
深蓝色:Intel CPU 单精度
从 2001 到 2014,CPU 性能增长相对平缓(几十到几百 GFLOPS)。
GPU 性能呈指数增长,从 GeForce FX 5800 到 GTX Titan、Tesla K40,单精度性能飙升至约 4 TFLOPS(=4000 GFLOPS)。
-
横轴(X 轴):时间,从 2001 年到 2014 年。
它表示的是各个硬件发布时间点,并非所有产品在同一时间存在,而是对齐到各自的发布年份。 -
纵轴(Y 轴):浮点运算能力(GFLOPS/s)。
这是“每秒能执行多少十亿次浮点运算”的指标,即 FLOPS(Floating Point Operations per Second),
通常用来衡量计算芯片的理论峰值算力。
GPU 的计算性能(以 GFLOPS/s 为单位)在过去十多年中远超 CPU,并且增长速度极快。

GPU 的高并行架构依赖于:
-
warp 为执行最小调度单位;
-
所有 warp 的 context 常驻片上;
-
warp scheduler 实现无开销切换;
-
warp 内同指令执行(SIMT),warp 间独立运行。
Block 内共享内存 + 同步 → 提供局部通信,不干扰 warp 独立调度。
Warp Divergence → 同束线程分支不同,串行执行导致效率下降。
Warp 遇到延迟 → Scheduler 立即换另一个 warp。
Warp 内同步执行 → 高效、SIMT。
Block、Warp、Thread 之间的层级因果
| 层级 | 谁决定 | 硬件行为 | 设计原因 |
|---|---|---|---|
| Thread | 程序员指定 | 运行 kernel 指令 | 计算最小单元 |
| Block | 程序员指定 | 分配给一个 SM | 实现局部共享与同步 |
| Warp | 硬件自动划分 | 32线程共用PC执行 | 便于SIMT指令调度 |
| Scheduler | 硬件自动管理 | 多warp切换执行 | 隐藏延迟、提升吞吐 |
每个 warp “one common instruction at a time” SIMT 执行模型(Single Instruction, Multiple Threads) Warp 的 32 线程共享同一个 Program Counter。调度器发出“一条指令” → 所有活跃线程同时执行。 线程之间不同数据,不同寄存器,
divergence 使 scheduler 失去并行性,因此效率下降。
每个 SM 有多个 warp scheduler(例如 4 个)每个 scheduler 管若干 warp warp A 等待显存(global memory)或同步时,scheduler 立即切到 warp B 所有 warp 的 context 都常驻 SM 内部寄存器文件 切换无开销 gPU 高吞吐的核心
Warp Scheduler(线程束调度器)的因果逻辑
-
每个 SM 有多个 warp scheduler(例如 4 个);
-
每个 scheduler 管若干 warp;
-
当 warp A 等待显存(global memory)或同步时,scheduler 立即切到 warp B;
-
切换无开销,因为所有 warp 的 context 都常驻 SM 内部寄存器文件。
这就是 GPU 高吞吐的核心机制。
如果像 CPU 一样等待,机器就“crawl to a halt”(停滞)。所以 GPU 必须能瞬间切换到别的 warp 去执行。就是 “context switch is free”
一个 warp 的“状态”(context)包括:
Program Counter:当前执行到哪条指令;Registers:每个线程的寄存器集合(保存局部变量);Shared Memory:block 内的共享数据区;
GPU 把这些全部放在片上(on-chip),而不是像 CPU 一样放在 DRAM 里。
切换 warp 不需要保存/恢复寄存器或程序计数器。
切换只需更新一个索引 → 真正意义上的 “zero-cost context switch”。
你无法直接指挥 warp scheduler,但可通过以下方式影响它:
-
提高活跃 warp 数(occupancy)→ 给调度器更多可选 warp;
-
减少内存延迟 → 减少 warp 被阻塞次数;
-
避免分支发散 → warp 执行时间更均匀。
warp scheduler 与 SIMT 的关系
-
warp scheduler 选定一个 warp → 发射一条指令 → 这条指令由 32 个线程同时执行。
-
它不区分线程,只管理 warp 级调度。
-
因此 GPU 的“并行核心”在实际是 warp scheduler 驱动下的批处理系统。
调度策略(各代架构差异)
| 架构 | 每个 SM 的 Warp Scheduler 数 | 策略 |
|---|---|---|
| Fermi | 2 | Round-robin(轮转) |
| Kepler | 4 | Greedy-then-oldest |
| Pascal / Volta 以后 | 4 | 分组调度 + 指令级调度(Dual issue) |
策略重点:
-
公平性:让所有 warp 都能轮到机会。
-
吞吐优先:优先执行“ready warp”,最大化核心利用率。
调度器会优先选那些不在等待内存或同步的 warp。
当一个 warp:
-
访问显存(global memory)→ 需要等待几百个时钟周期;
-
被
__syncthreads()阻塞;
调度器立即切换到另一个 warp 继续执行。
这叫 warp-level multithreading。
因为上下文(寄存器状态)都在片上,
切换几乎无开销(称 zero-overhead context switch)。
每个 SM 通常包含:
-
多个 warp(几十到上百个活跃 warp)
-
对应的多个 warp scheduler(通常 2–4 个)
每个调度器每个时钟周期从可执行的 warp 中选一个,
发射它的一条指令到执行核心(CUDA Cores)。
Warp Scheduler(线程束调度器) 是 GPU SM(Streaming Multiprocessor)内部的硬件单元,
负责在同一 SM 中众多 warp 之间决定——
“下一条要执行哪一个 warp 的哪条指令”。
它是 GPU 并行执行的核心控制器。
warp 是 GPU 硬件在 block 内自动按 32 线程划分的执行单元。
你不能直接创建 warp,但可以通过设计 block 大小与控制线程行为来影响 warp 的数量、填充率与执行效率。
你能“间接控制” warp 行为的方式
虽然不能直接控制 warp,但你能通过 线程数量与排布 影响它:
-
选择 block 线程数为 32 的倍数 → 避免 warp 填充不满。
-
数据划分让相邻线程执行相似逻辑 → 减少 divergence。
-
控制 block 大小(常见为 128、256、512)来匹配 SM 的 warp 调度器数(每 SM 通常能同时管理 64–128 个 warp)。
warp 的划分规则
-
线程 ID(threadIdx.x)连续的 32 个线程组成 1 个 warp;
-
例:
-
Block 含 64 线程 → 2 个 warp;
-
Block 含 48 线程 → 2 个 warp(第二个只用到 16 个,另外 16 个位置空)。
-
所以 warp 的数量计算公式是:
warp_num = ceil(threads_per_block / 32)
-
你作为程序员不会直接创建 warp。
-
你只指定 block 的线程数,例如:
kernel<<<1, 64>>>();GPU 硬件自动把这 64 个线程分成 2 个 warp(每 warp 32 线程)。
warp = 32 threads(固定,由架构定义,Fermi 到 Ada 皆如此)
path(路径) 指的是 控制流路径(control-flow path)。
也就是程序执行时,每个线程根据条件分支 (if, for, while, switch) 选择的那条具体指令路线。
| 层级 | 调度单位 | 执行方式 | 同步方式 |
|---|---|---|---|
| Grid | 多个 Block | 独立执行 | 无法直接同步 |
| Block | 多个 Warp | SM 内共享资源 | __syncthreads() |
| Warp | 32 Threads | 一次执行一条共同指令 | 隐式同步 |
Warps execute independently
-
各 warp 之间互不依赖;SM 可以交错调度多个 warp(称作 warp-level multithreading)。
-
当一个 warp 因内存访问等待时,SM 切换到另一个 warp 执行。
-
这种“零开销上下文切换”依赖每个 warp 都有自己的 寄存器上下文。
block 内线程同步
-
block 内的线程可通过共享内存通信、用
__syncthreads()同步。 -
warp 内的 32 线程在硬件上隐式同步。
-
但 异 warp 间的同步要靠
__syncthreads()显式实现。 -
grid 下异 block 间 不能直接同步。
-
执行模型是 SIMT(Single Instruction, Multiple Threads),近似于 SIMD。
-
如果所有线程都走同一条控制流(同样的 if/else 分支),效率最高。
-
如果控制流不同(有线程进 if,有的进 else),就会出现——
Divergence(分歧)
-
当同一 warp 中部分线程执行不同路径时,warp 不能并行这两条路径。
-
-
暂停一部分线程;
-
先执行 path A;
-
再执行 path B;
-
最后重新汇合(converge)。
-
-
所以分歧 = 串行化执行,效率下降。
SM(Streaming Multiprocessor)接到一个 Block#再划分成 warp(线程束)##线程拥有连续的 threadIdx##
SM partitions thread block(s) into warps
-
**SM(Streaming Multiprocessor)**接到一个 Block 后,不直接操作 1024 个线程,而是再划分成 warp(线程束)。
-
每个 warp = 32 个线程。
-
这些线程拥有连续的
threadIdx编号:0–31、32–63、依此类推。

GPU 并行世界的“两层三维层级空间”——一层管理调度,一层执行计算。
每个 thread 的“地址” = block 位置 × thread 位置,
这形成一个 张量积空间(tensor product space):
Grid(3D) ⊗ Block(3D) → 全局线程空间。
混成六维,编译器与硬件都无法保持这种组织
grid 下异block 不能直接通信。block 内的线程共享 memory、同步;
资源作用域不同
-
block 内的线程共享 memory、同步;
-
不同 block 不能直接通信。
-
若合成“六维”,就丢掉这种局部协作域的结构意义。
但 CUDA 的设计不是“六维空间”,而是“两层三维”
原因:
-
硬件分层映射
-
一个 SM 管理若干 block(第一层)。
-
每个 block 管理若干 thread(第二层)。
-
GPU 调度器并不把两层合并成统一索引表,而是分层调度。
-
数学上确实可以组合成六维
每个线程的唯一索引由两部分组成:
(threadIdx.x, threadIdx.y, threadIdx.z) (blockIdx.x, blockIdx.y, blockIdx.z)
总共六个维度。
如果你愿意,可以把它展开成一个“6D 坐标”,
代表这个线程在整个 GPU 启动空间中的位置。
GPU 计算不再以时间为中心(像 CPU),而以空间为中心。
这是并行计算的根哲学。
dim3 blocksPerGrid(b_x, b_y, b_z);
dim3 threadsPerBlock(t_x, t_y, t_z);
whoami<<<blocksPerGrid, threadsPerBlock>>>();
CUDA 选择三维,是在说:
“每一个线程的逻辑位置就是空间中的一个点。”
你在 3D 空间布线,GPU 在硬件上映射出几百万个点去算。
这个坐标系统是人类抽象思维与并行硬件之间的桥梁。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 10
10 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)