【人工智能】AI入门必看:一文搞懂监督学习的核心思想
是选择用简单的线性公式(像一把尺子),还是用复杂的多项式公式(像一套精密的曲线板)?如果考得差,就得回去调整方法(比如换一个更复杂的模型,或者增加一些学习技巧)。PAC学习从数学上证明了,只要数据量足够,模型复杂度适中,我们就能学到一个好的模型。,就是把数据分成K份,轮流用其中K-1份做训练,剩下的1份做测试,最后取K次测试的平均成绩。:模型太复杂了,把数据中的噪声(偶然因素)都当成了规律来学习。
监督学习的核心思想
一、 什么是机器学习?先从“学习”说起
在正式讲监督学习之前,我们先得明白什么是“机器学习”。
一位大神Tom Mitchell给出了一个经典定义:
一个计算机程序被认为可以从经验E中学习,以完成某一类任务T,其性能由P来度量。如果它在任务T上的性能(由P度量)随着经验E的增加而提高,那么我们就说它具有学习能力。
是不是有点绕?我们把它翻译成“人话”:
- 任务:比如,识别一张图片里是猫还是狗。
- 经验:看成千上万张已经标好“这是猫”、“那是狗”的图片。
- 性能:识别的准确率。比如,100张图片里能认对多少张。
所以,机器学习就是让计算机通过“看”大量数据(经验),自动提升完成某项任务(识别猫狗)的能力(准确率)。
机器学习有很多种,我们今天的主角是监督学习,它就像我们上学时“带着答案做题”一样。
二、 监督学习:带着答案的“题海战术”
监督学习的核心思想非常简单:给机器一批带有正确答案的数据,让它从中找出规律。
这就像我们教小朋友认识水果:
- 经验(数据):你拿出一个苹果,告诉他:“这是苹果。”(输入:苹果图片,输出/标签:苹果)
- 学习:你又拿出香蕉、橙子,一遍遍地教。
- 完成任务:最后,你拿出一个他没见过的苹果,他能准确地叫出:“这是苹果!”
在这个过程中,你提供的“苹果图片”就是输入,你告诉他的“苹果”就是输出(也叫标签)。这种既有输入又有标签的数据,就是监督学习的“教材”。
监督学习主要解决两大类问题:
1. 分类:答案是“类别”
当输出是有限的类别时,就是分类问题。比如:
- 垃圾邮件识别:输入一封邮件,输出是“垃圾邮件”或“非垃圾邮件”。
- 图像识别:输入一张图片,输出是“猫”、“狗”、“汽车”等。
- 情感分析:输入一段评论,输出是“好评”或“差评”。
2. 回归:答案是“连续的数字”
当输出是一个具体的数值时,就是回归问题。比如: - 房价预测:输入房子的面积、位置、楼层等信息,输出一个具体的房价,比如“125.8万”。
- 气温预测:输入今天的日期、天气等,输出明天的最高气温,比如“28.5摄氏度”。
- 股票预测:输入公司近期的财务数据,输出明天的股价。
三、 机器学习的“学习”过程:从训练到预测
一个完整的监督学习过程,就像一个学生备考的过程:
-
划分数据集:我们把所有的“教材”(数据)分成三份:
- 训练集:大概占60%-80%。这是学生的练习册,用来学习和掌握知识。
- 验证集:大概占10%-20%。这是学生的模拟考卷,用来调整学习方法(比如发现自己哪部分没学好,回头再看看练习册)。
- 测试集:大概占10%-20%。这是最后的期末考试,完全没见过,用来检验学生的真实水平。
-
选择模型(假设空间 ℋ):你要给学生选择一套“解题方法”。是选择用简单的线性公式(像一把尺子),还是用复杂的多项式公式(像一套精密的曲线板)?这个“所有可能方法的集合”,就叫假设空间。
Hypothesis Space ℋ for Curve Fitting(曲线拟合


-
训练模型:学生在练习册(训练集)上做题,不断调整自己的解题方法,目标是把练习册上的题都做对。这个过程叫拟合。
-
评估与调优:学生用**模拟考卷(验证集)**来测试。如果考得好,说明学习方法不错;如果考得差,就得回去调整方法(比如换一个更复杂的模型,或者增加一些学习技巧)。
-
最终测试:用期末考试(测试集)来检验学生的最终学习成果。这次的成绩,才代表了学生真正的泛化能力——也就是处理未知问题的能力。
四、 最大的挑战:欠拟合 vs 过拟合
在训练模型时,我们最常遇到两个“坑”:欠拟合和过拟合。我们继续用学生备考的例子来理解:
1. 欠拟合:学习太“渣”
- 表现:学生在练习册上就做得一塌糊涂,期末考试自然也考不好。训练误差高,测试误差也高。
- 原因:模型太简单了,连数据中的基本规律都没学到。就像你让一个小学生去做微积分题目,他根本无从下手。
- 怎么办:换个更聪明的学生!也就是使用更复杂的模型,或者增加更多有用的特征(给学生更多参考资料)。
2. 过拟合:太会“死记硬背”
-
表现:学生把练习册上的所有题目和答案都背得滚瓜烂熟,练习册考试能拿满分。但一到期末考试,题目稍微变个样,他就懵了。训练误差极低,但测试误差很高。
-
原因:模型太复杂了,把数据中的噪声(偶然因素)都当成了规律来学习。它不是在“学习”,而是在“记忆”。
-
怎么办:
- 增加训练数据:给他做更多的练习册,让他没法全背下来,只能去学真正的规律。这是最有效但往往也是最贵的方法。
- 正则化:给学习过程加一个“紧箍咒”,惩罚那些过于复杂的模型,让它“不敢”太放飞自我。
- 特征选择:别给学生看那么多无关紧要的参考资料,只给他最核心的。
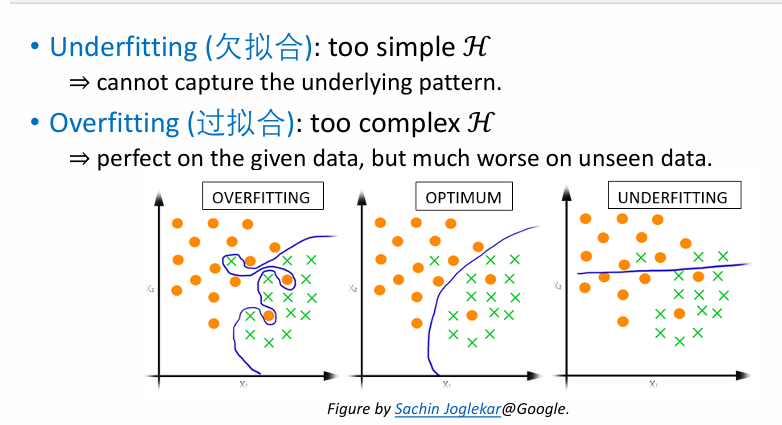
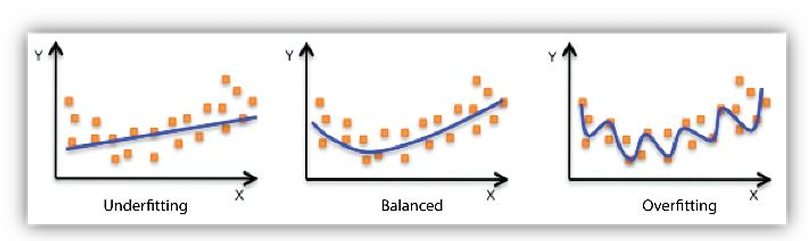
下面这张图完美地展示了这个过程:
- 左图(欠拟合):用一条直线去拟合一个曲线,显然没抓住重点。
- 中图(恰到好处):用一条平滑的曲线,既拟合了数据,又保持了良好的泛化能力。
- 右图(过拟合):用一条弯弯绕绕的曲线穿过了每一个点,把噪声都学进去了,对新数据的预测能力会很差。
五、 偏差-方差权衡:找到那个“最佳平衡点”
欠拟合和过拟合的背后,是一个深刻的权衡问题:偏差-方差权衡。
- 偏差:模型的“偏见”。高偏差意味着模型过于简单,对数据的假设太强,导致欠拟合。(就像一个固执的学生,非认为所有题都用一种方法解)。
- 方差:模型对数据的“敏感度”。高方差意味着模型过于复杂,对训练数据的微小变化都很敏感,导致过拟合。(就像一个敏感的学生,练习册上任何细节变化都会让他改变解题思路)。
我们的目标,就是找到一个偏差和方差都适中的模型,在“欠拟合”和“过拟合”之间取得最佳平衡。
六、 实用技巧:如何优化我们的模型?
当模型表现不佳时,我们可以像医生一样对症下药:
Input normalization(输入归一化)->Increasing training set size -> Regularization(正则化)-> Feature selection(特征选择)
| 问题表现 | 可能原因 | 解决方案 |
|---|---|---|
| 训练集、测试集表现都很差(高偏差,欠拟合) | 模型太简单 | 1. 换更复杂的模型 2. 增加更多特征 3. 减少正则化 |
| 训练集表现好,测试集表现差(高方差,过拟合) | 模型太复杂 | 1. 获取更多数据(首选!) 2. 使用正则化(L1, L2) 3. 进行特征选择,减少特征数量 4. 使用交叉验证,更可靠地评估模型 |
| 什么是交叉验证? |
简单说,就是“不止考一次期末试”。比如K折交叉验证,就是把数据分成K份,轮流用其中K-1份做训练,剩下的1份做测试,最后取K次测试的平均成绩。这样得到的评估结果更稳定、更可靠。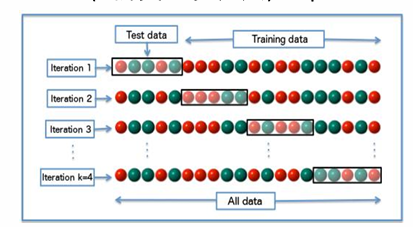
七、 理论基础:我们为什么相信机器学习?
最后,简单提一个高大上的理论——PAC学习。
Probably approximately correct (PAC) learning
它回答了一个根本问题:到底需要多少数据,我们才能有把握地认为,我们训练出的模型是“大概正确”的?


这就像问:“一个学生需要做多少道练习题,我们才能有95%的把握,他在期末考试中正确率能超过90%?”
PAC学习从数学上证明了,只要数据量足够,模型复杂度适中,我们就能学到一个好的模型。这为我们整个机器学习大厦提供了坚实的理论基石。
总结
- 监督学习就是带着答案学习,分为分类和回归。
- 学习过程包括训练、验证、测试,目标是提升泛化能力。
- 要警惕欠拟合(太简单)和过拟合(太复杂)。
- 背后是偏差-方差的权衡。
- 可以通过更多数据、正则化、特征选择等方法优化模型。
参考阅读材料:
- 《人工智能:一种现代方法》
- Hastie, Tibshirani, Friedman, The Elements of Statistical Learning
- 梯度下降优化算法

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 31
31 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)