自由学习记录(109)
摘要:视频讲解了CUDA编程模型与GPU硬件架构的关系,重点包括:1)kernel函数通过grid-block-thread三层结构实现并行计算,线程通过索引区分任务;2)block的维度结构(shape)限制为乘积≤1024,由寄存器索引宽度决定;3)GPU硬件采用SM多核架构,每个block绑定到SM执行,32线程组成warp作为调度单元;4)通过cudaMalloc/cudaMemcpy管理
https://www.youtube.com/watch?v=xwbD6fL5qC8

一个 kernel 函数调用一个 grid# block 运行同一个 kernel 代码##kernel 内部通过线程索引区分自己的任务##int x = blockIdx.x * blockDim.x + threadIdx.x;
Grid 与 Kernel 的关系
-
一个 kernel 函数 在一次调用中对应一个 grid。
-
所有 block 运行同一个 kernel 代码,但在不同数据区工作。
-
kernel 内部通过线程索引区分自己的任务:
int x = blockIdx.x * blockDim.x + threadIdx.x;
“Shape” 就是它的维度结构(Db.x, Db.y, Db.z)。(1024,1,1)#(16,16,1) #(8,8,8)#不能超过 1024#Db.x * Db.y * Db.z##Db.x * Db.y * Db.z ≤ 1024
Block 的 shape
-
“Shape” 就是它的维度结构(Db.x, Db.y, Db.z)。
-
比如:
-
(1024,1,1)→ 一维 shape -
(16,16,1)→ 二维方块 shape -
(8,8,8)→ 三维立方体 shape
-
-
但乘积不能超过 1024 →
Db.x * Db.y * Db.z ≤ 1024
这个上限由硬件寄存器索引宽度决定。
dim3 是干什么的
dim3 是 CUDA 提供的内建类型,用来描述多维配置:
dim3 Dg(4, 2, 1); // 4×2 grid,共 8 个 block dim3 Db(8, 8, 1); // 每个 block 8×8,共 64 个线程
它可以表示一维、二维或三维的结构:
-
1D → 向量
-
2D → 矩阵
-
3D → 体积
这个多维索引让线程可以自然地映射到图像、体积数据等。
一次 kernel 启动# kernel 代码#
不同 SM 上执行 ,并行单元,
grid, block, thread 的层级关系
Grid ├── Block(0) │ ├── Thread(0) │ ├── Thread(1) │ └── ... ├── Block(1) └── ...
-
Grid:一次 kernel 启动生成的所有并行工作集合。
-
Block:被 GPU 分派到不同 SM 上执行的基本并行单元。
-
Thread:执行 kernel 代码的最小单元。
上下文(Context)
-
一般含义
-
“上下文”就是程序运行时的状态集合。
-
对一个线程来说,包括:
-
寄存器中的数值
-
程序计数器(当前执行到哪一条指令)
-
局部变量地址、栈指针等。
-
-
-
在 GPU 中
-
每个线程都有独立的执行上下文(它的寄存器状态、执行位置等)。
-
当调度器在多个 warp 之间切换时,GPU 会保存旧 warp 的上下文,加载新 warp 的上下文。
-
因为寄存器都在片上,所以这种切换几乎无开销(称为“zero-overhead context switch”)。
-
一个 SM 内部主要模块如下:
| 模块 | 功能 |
|---|---|
| 执行核心(CUDA Cores) | 真正做浮点与整数运算。 |
| Warp Scheduler & Dispatch Unit | 负责给 32 线程一组的 warp 发指令、切换上下文。 |
| Shared Memory / L1 Cache | Block 内线程共享的数据区。 |
| Register File | 每个线程的寄存器集合。 |
| Special Function Units (SFU) | 执行 sin、cos、sqrt 等特殊运算。 |
SM 的寄存器文件(通常 64K–256K 寄存器)要被 block 中的所有线程共享。
如果线程太多,每个线程能分到的寄存器数下降,反而导致性能下降。
Shared memory 也类似——每个 block 最多只能用约 48–100 KB。
-
每个线程需要寄存器编号和线程索引寄存器。
-
这些索引通常在硬件中以 10 位存储(2¹⁰ = 1024)。
-
所以在早期 Fermi 架构(CC 2.x)后,NVIDIA 统一将每个 block 的线程上限定为 1024。
Block 内线程共享同一个 共享内存 (shared memory) 和 寄存器池 (register file)。
GPU 内部有多个 SM,每个 SM 能同时容纳若干个 block。
block 中的线程数不是 32 的倍数时,最后一个 warp 会有部分线程空闲。
Block 与 Thread 的硬件对应关系
-
一个 Block → 绑定到一个 SM(Streaming Multiprocessor)上执行
-
GPU 内部有多个 SM,每个 SM 能同时容纳若干个 block。
-
Block 内线程共享同一个 共享内存 (shared memory) 和 寄存器池 (register file)。
-
因此 Block 的大小受限于:
-
SM 寄存器数量
-
Shared memory 大小
-
Warp 调度槽数量
-
-
-
Thread → GPU 的最小执行单元
-
每 32 个线程组成一个 warp。
-
Warp 是调度的基本单位,GPU 同时发射整个 warp,不调度单个线程。
-
当 block 中的线程数不是 32 的倍数时,最后一个 warp 会有部分线程空闲。
-
线程和 block 的限制
-
Db.x * Db.y * Db.z ≤ 1024(一个 block 最多 1024 个线程) -
不同 GPU 架构可能上限略不同,但 1024 是通用安全值。
-
Grid 的规模几乎可以任意大,只受 GPU 总线程数上限约束。
dim3 类型
-
内建三维结构类型,可指定 x、y、z 三个维度:
dim3 Dg(32, 16, 1); dim3 Db(8, 8, 1); -
这样 kernel 可以在一维、二维或三维的数据空间上自然映射。
语法结构:<<< Dg, Db >>>
-
这是 CUDA 的特殊运行时语法,用来在 CPU 端(Host) 启动 GPU 端(Device)kernel。
-
Dg:Grid 的尺寸(多少个 block) -
Db:Block 的尺寸(每个 block 里多少个线程)
CUDA 在运行时(Host Run-Time)如何指定 kernel 的执行配置——即 grid、block、thread 三层并行结构。

| 场合 | 你说“拓扑”的语气 | 含义范围 |
|---|---|---|
| 技术语境(网络、GPU、系统) | ✅ 合理、精确 | 指硬件或数据结构的连接图。例:“GPU 拓扑图”、“神经网络拓扑”。 |
| 泛学术语境(结构、模型) | ✅ 可用 | 表示系统内部关系。例:“组织拓扑”、“社会网络拓扑”。 |
| 口语泛用(非技术) | ⚠️ 慎用 | 听起来偏专业,若说“人的情感拓扑”“剧情拓扑”会带哲学味。 |
如果一个物体能通过连续变形(不撕裂、不粘合)变成另一个物体,那么它们在拓扑意义上相同。
所以:
-
球体 🟠 与立方体 ⬛ 是拓扑等价的(都无洞)。
-
咖啡杯 ☕ 与甜甜圈 🍩 等价(都有一个洞)。
-
圆环、环面、莫比乌斯带这些“洞的个数”不同,就代表不同的拓扑类型。
用以下命令或工具查看硬件拓扑:
-
nvidia-smi topo -m(显示 GPU/CPU/NVLink 拓扑矩阵) -
nvidia-smi(查看 GPU 核心、显存、带宽) -
ncu/nvprof(性能分析器中可视化拓扑信息)
CPU ── PCIe ── GPU0 ─ NVLink ─ GPU1
在 GPU / CUDA 语境下
“硬件拓扑”主要表示:
-
GPU 内部的 计算单元层级结构(SM、warp、thread 的分布);
-
GPU 与 CPU、内存、总线之间的 物理连接关系;
-
不同设备之间的 带宽与访问路径。
“硬件拓扑(Hardware Topology)”指的是硬件各部分之间的结构布局与连接关系。
简单说,它描述了**“谁连着谁、带宽多大、层级如何”**。
-
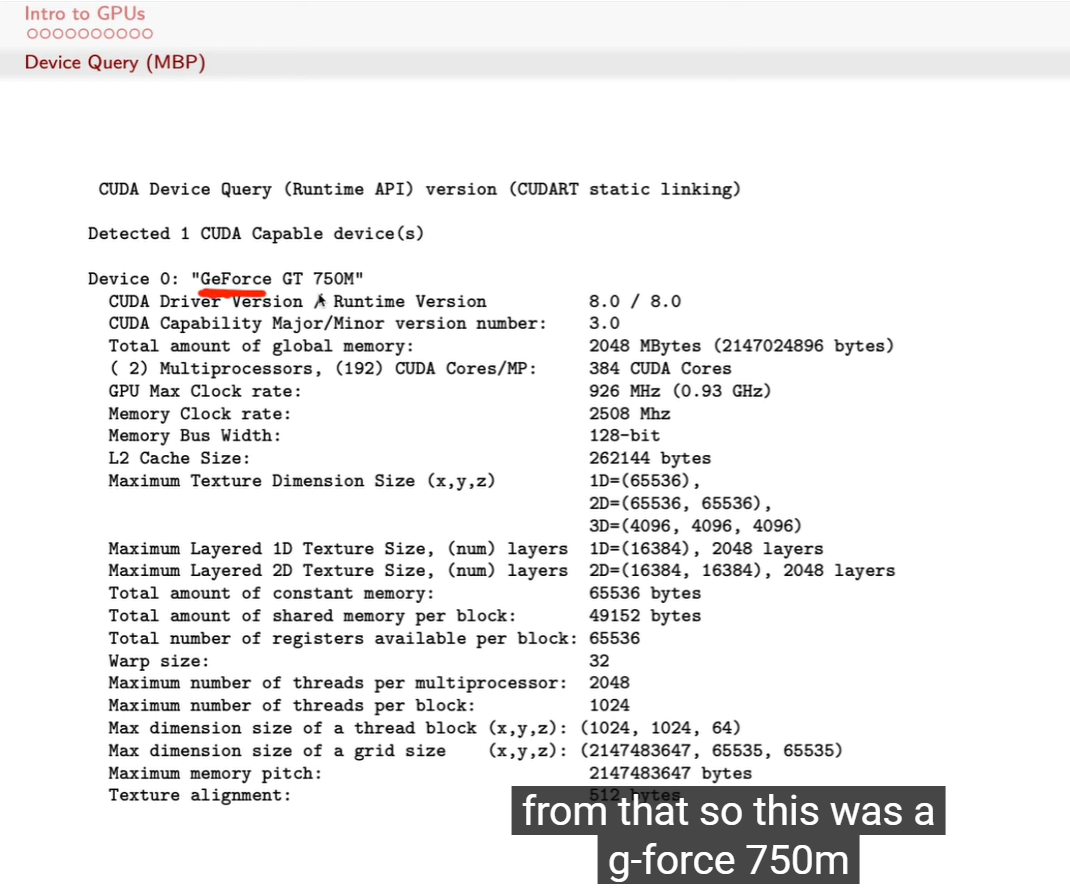
通过
deviceQuery命令读取 GPU 架构特征。 -
说明 CUDA 编程模型与硬件拓扑是一一对应的:
每个参数(线程数、shared memory、warp size)直接影响 kernel 性能和资源分配。
-
认识 GPU 的硬件规格参数
-
Device 名称:
GeForce GT 750M(说明显卡型号) -
CUDA Driver/Runtime Version:
8.0 / 8.0(说明支持的 CUDA 版本) -
Compute Capability:3.0(决定可用 CUDA 特性与指令集范围)
-
Global Memory:2 GB(GPU 可用显存大小)
-
CUDA Cores:384(并行执行单元数量)
-
Max Clock:926 MHz(GPU 主频)
-
-
理解“Compute Capability(计算能力)”的重要性
-
不同架构(Tesla、Fermi、Kepler 等)有不同 capability 编号。
-
3.0 对应 Kepler 架构(2012)。
-
这决定了是否支持特性如动态并行(Dynamic Parallelism)、统一内存等。
-
-
区分不同层次的内存结构
-
Global Memory(2GB) → 所有线程可访问。
-
Shared Memory per Block:49KB → Block 内共享,速度更快。
-
Registers per Block:65536 → 提高并行线程性能。
-
L2 Cache:262KB → 缓存全局访问。
-
-
Warp 与线程并行机制
-
Warp size:32 → 基本调度单元。
-
Threads per block:1024,Threads per SM:2048。
-
老师会强调:这决定了线程组织方式(grid → block → thread)。
-
展示 CUDA 设备查询结果(Device Query)如何反映 GPU 的硬件结构与计算能力。
| 表达 | 含义 | 位数 |
|---|---|---|
| FP32 / SP | Single Precision(单精度) | 32 位 |
| FP64 / DP | Double Precision(双精度) | 64 位 |
| FP16 / HP | Half Precision(半精度) | 16 位 |
为什么不用 “DLOPS” 而用 “FLOPS”
你说的对,从逻辑上讲既然是 double precision,写成 DLOPS(Double ops/sec)也合理。
但业界历史上沿用了“FLOPS”这个通用度量单位,区别精度时只在前面加修饰:
-
FP32 FLOPS(或 SP FLOPS)
-
FP64 FLOPS(或 DP FLOPS)
-
FP16 FLOPS(或 Tensor FLOPS)
原因:
-
FLOPS 是“浮点性能”的标准物理量单位,不能随精度改变单位符号。
-
精度(FP32 / FP64)影响的是“运算类型”,不是“运算单位”。
FLOP = Floating Point Operation
Double 是浮点数的一种(FP64)。G = Giga = 10⁹,英文“billion”在美式里也代表 10⁹。所以 “6144 GFLOPS DP” ≈ 每秒 6.144 × 10¹² 次双精度浮点运算。
| 层级 | 例子 | 代表的意思 |
|---|---|---|
| ① 数据类型层(Precision) | FP32 / FP64 / DP / HP | 表示“精度种类”,即每个数占多少位。FP = Floating Point;DP = Double Precision(64bit);SP = Single Precision(32bit)。 |
| ② 性能指标层(Perf) | GFLOPS / TFLOPS / PFLOPS | 表示“每秒执行多少次浮点运算”。G = 10⁹,T = 10¹²,P = 10¹⁵;FLOPS = Floating-Point Operations per Second。 |
| ③ 表格列名层(组合层) | FP Perf (DP* GFLOP) | 表示“浮点性能,用双精度计算,单位是GFLOPS”。星号“*”仅是作者的注记符号。 |
为什么要标“双精度”
-
科学与工程计算必须用双精度:
-
涉及气候模拟、流体力学、量化金融、天体计算等领域,结果对精度极其敏感。
-
-
游戏/图形计算多数只需单精度:
-
所以早期 Tesla、Kepler 的 FP64 性能远低于 FP32,是“裁剪版”双精度。
-
-
从 Fermi 开始 NVIDIA 专门为 HPC 增强 FP64 单元,并在 Volta 引入 Tensor Core。
-
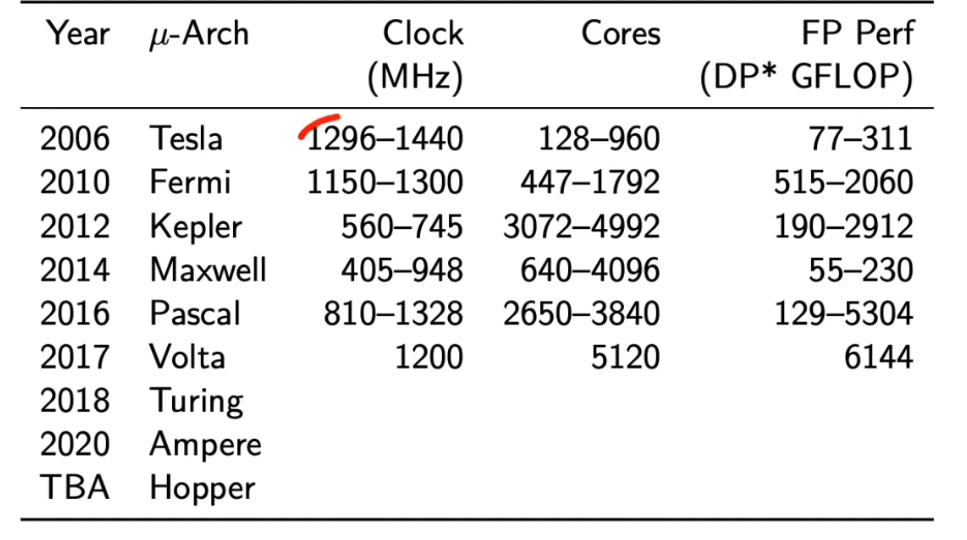
从提升频率 → 增加核心数的转变
-
Tesla 到 Fermi 时主频还接近 1.3 GHz;
-
从 Kepler 开始主频反而下降,但核心数量暴涨(几千个);
-
说明性能增长主要靠 并行规模 而非时钟速度。
→ GPU 走“多核并行”路线,而非CPU那种“高频单核”路线。
-
-
浮点性能(GFLOP)指数级提升
-
2006 Tesla:几十到几百 GFLOPS;
-
2017 Volta:超 6 TFLOPS(约提升百倍);
-
教师会指出:性能提升来自架构并行度+专用单元(Tensor Core等),而非频率提高。
-
通过频率(Clock)、核心数(Cores)、双精度性能(FP Perf)三列看出 GPU 架构演化趋势
Fermi 是 GPU 历史上第一次“类 CPU 化”的架构,确立了 SM/L1/L2 分层、warp 调度、双精度与 ECC 支持的完整通用计算体系,为后续 Kepler–Ampere 奠定基础。
Fermi 确立了此后所有 NVIDIA 架构的基准:
-
GPU 不再是“着色器阵列”,而是 并行多核计算阵列。
-
架构层面实现了 类 CPU 的缓存、调度、异常、内存保护机制。
-
标志 GPU 正式成为 通用计算设备 ( GPGPU )。
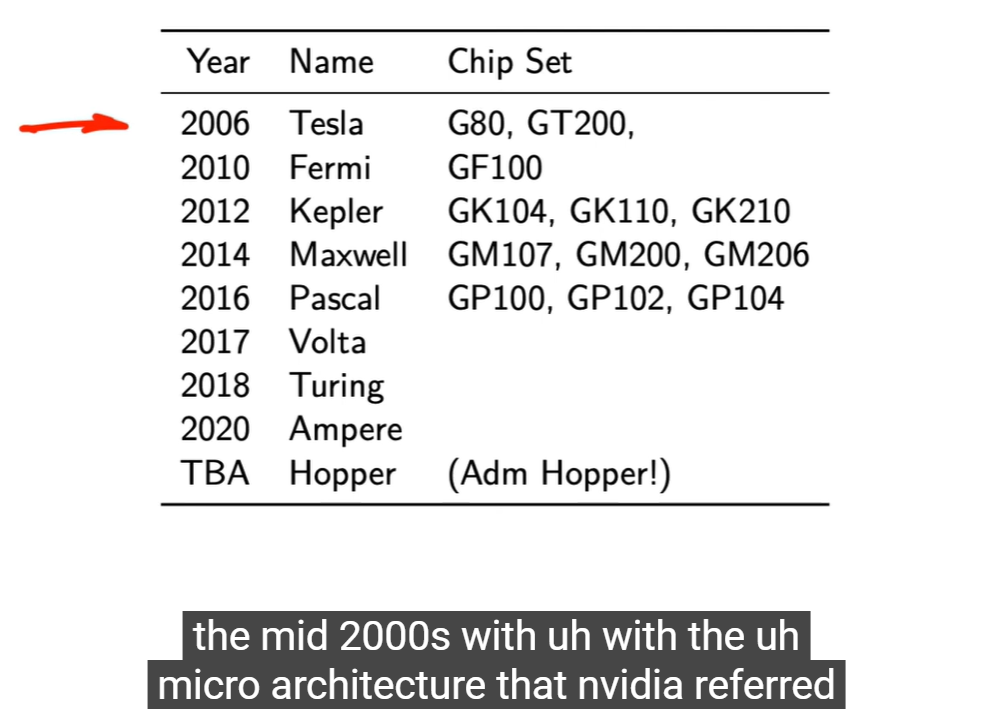
“Chip Set” 是表中用于连接架构与实际硬件的技术细节项,是次重点。
主要讲解焦点仍是“Name”这一列所代表的架构时代与计算能力演化。
老师讲解层次
-
主要焦点:架构(Name)与时代演进
-
“Tesla、Fermi、Kepler…”这些名字代表 微架构 (microarchitecture),
每一代定义了 GPU 的计算模型、并行结构和指令集。 -
老师会用这条主线说明 CUDA 和硬件能力的共同演进。
-
-
Chip Set 栏位的作用:对应实际物理芯片代号
-
例如 Tesla → G80,Fermi → GF100。
-
它是显卡或GPU的代号(silicon code name),对了解:
-
不同显卡型号的核心差异,
-
Compute Capability(计算能力)版本,
-
架构级特性(如共享内存、寄存器数、Tensor Core 支持)
有参考意义。
-
-
-
教学中通常的比重
-
Name 列(架构):老师会重点讲。
-
Chip Set 列:用于补充说明哪个实际芯片属于哪代架构。
-
若课程偏硬件或CUDA底层开发,Chip Set会被重点解释;
若课程偏软件或并行模型,则只略提。
-
讲的是 GPU 从 Tesla 架构开始迈入通用计算时代,每一代微架构如何推动 CUDA、AI、HPC 的性能与功能演化。
2006 年是 CUDA 与 GPGPU 的开端。
此表展示的不是显卡型号,而是 微架构世代(microarchitecture generations)。
老师会把重点放在:
“Tesla 开始的可编程架构革命”,
“Fermi 到 Volta 的并行计算演化”,
“Hopper 面向 AI 计算的终极方向”。
-
Tesla → Fermi 的转变:从图形计算到通用计算的彻底分化。
-
Volta 之后的转折:AI、深度学习驱动架构演进(Tensor Core 成为核心卖点)。
-
命名规则变化:从以物理芯片代号(G80, GF100)到以科学家命名(Pascal, Volta, Turing, Hopper),体现了科学计算定位。
架构演进主线(2006–2020)
| 架构 | 年份 | 特点 |
|---|---|---|
| Tesla (G80) | 2006 | CUDA诞生,统一架构,GPU可执行通用指令。 |
| Fermi (GF100) | 2010 | 引入缓存层次结构(L1/L2),支持双精度,Compute Capability 2.x。 |
| Kepler (GK110) | 2012 | 更高能效,SMX结构,动态并行。 |
| Maxwell (GM200) | 2014 | 功耗优化,调度改进。 |
| Pascal (GP100) | 2016 | 支持 NVLink、高速HBM、FP16。 |
| Volta (GV100) | 2017 | Tensor Core 首次出现,用于深度学习矩阵乘法。 |
| Turing (TU102) | 2018 | 增加 RT Core(光线追踪)+ Tensor Core。 |
| Ampere (GA100) | 2020 | 更高效 Tensor Core,AI 推理加速。 |
| Hopper (GH100) | TBA | 面向 HPC/AI 的下一代架构。 |
转折点:2006 Tesla 架构(G80)
-
第一代支持 CUDA 的 GPU。
-
GPU 从“绘图硬件”转变为“可编程通用计算设备”。
-
引入 统一着色架构(Unified Shader Architecture),让所有核心都能执行通用运算。
-
老师极可能强调这是 GPGPU 的真正起点。
2006年起 GPU 正式进入 GPGPU(通用计算)时代,以及 NVIDIA 各代架构的技术演进路线。
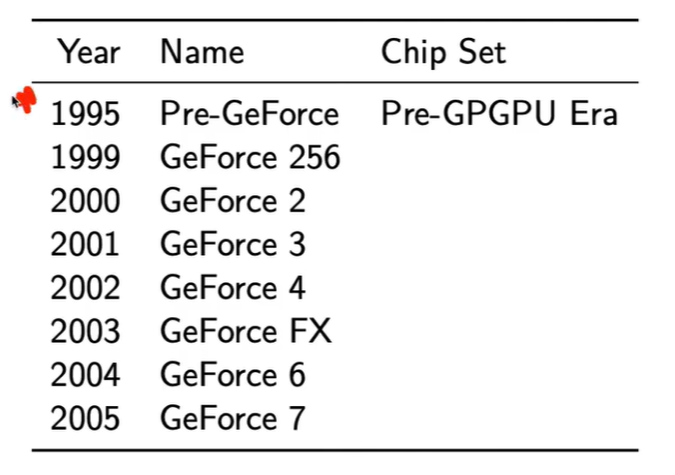
这页PPT最可能着重讲的是——GPU 从图形加速器到通用计算平台的演化起点。
一、核心讲解重点
-
时间轴:1995–2005
-
展示了从“Pre-GeForce”到“GeForce 7”的发展脉络。
-
对应的是GPGPU(General-Purpose GPU Computing)出现之前的阶段。
-
-
关键词:Pre-GPGPU Era(通用计算之前的时代)
-
老师会说明在这段时期,GPU 仅用于图形渲染管线:顶点、光栅化、像素填充。
-
还不支持编程式并行计算,无法像今天这样执行 CUDA/OpenCL。
-
-
转折点:GeForce 256(1999)
-
通常被称为世界上第一款 GPU。
-
引入硬件级 T&L(Transform & Lighting),标志 GPU 具备可编程潜力。
-
-
到 GeForce 6 / 7(2004–2005)
-
可编程着色器架构成熟,为 CUDA(2006 发布) 铺路。
-
-
CUDA 变量用
__device__ / __constant__ / __shared__控制存储位置。 -
类或结构体则看在哪个环境被创建(CPU 或 GPU),并可用
__host__ __device__修饰成员函数以在两端通用。
类与结构体的情况
类(或 struct)可以包含 GPU 变量或函数,但要注意作用域:
-
如果类中有在 GPU 上执行的函数,需用
__device__或__host__ __device__声明:struct Vec2 { float x, y; __host__ __device__ Vec2(float _x, float _y) : x(_x), y(_y) {} __host__ __device__ float length() { return sqrtf(x*x + y*y); } }; -
但类本身实例化的位置决定了它存在哪:
-
在 CPU 代码里
Vec2 v(1,2);→ 存在主机内存。 -
在 kernel 里声明
Vec2 v(1,2);→ 存在设备内存。
-
// GPU 全局变量
__device__ int d_counter;
// GPU 常量
__constant__ float d_pi = 3.14159f;
__global__ void addKernel(float *data) {
__shared__ float local[256]; // 块内共享数组
int i = threadIdx.x;
local[i] = data[i] * d_pi;
}
这些变量都只能在 GPU 上被访问,CPU 无法直接操作。
如果 CPU 想读写这些值,需要用 cudaMemcpyToSymbol()、cudaMemcpyFromSymbol()。
变量的空间限定符
| 限定符 | 作用位置 | 生命周期 | 说明 |
|---|---|---|---|
__device__ |
GPU 全局内存 | 程序运行期间 | 声明一个设备端全局变量,可被 kernel 访问。 |
__constant__ |
GPU 常量内存 | 程序运行期间 | 声明只读常量,全线程共享,访问快。 |
__shared__ |
GPU 共享内存 | kernel 调用期间 | 声明在同一个线程块内共享的变量(速度最快)。 |
| (无限定符) | CPU 主机内存 | 程序运行期间 | 普通的主机变量,只能被 CPU 代码访问。 |
变量和类在 CUDA 里没有像函数那样用 __global__ / __device__ 去区分定义位置,但它们确实有类似的“存储空间限定符(memory space qualifiers)”,用来控制变量或对象存放的位置(主机内存或设备内存)。
CUDA 文件中确实能混写 CPU 与 GPU 代码,它们靠 __global__ / __device__ / __host__ 明确区分运行位置和调用方式。
__global__ void square(float *d_out, float *d_in) {
int idx = threadIdx.x;
float f = d_in[idx];
d_out[idx] = f * f;
}
__global__ → 声明这是一个 GPU kernel。
每个 GPU 线程都会执行这段函数一次。
threadIdx.x 给出线程在线程块中的索引。
所以 64 个线程会同时计算 64 个元素的平方。
工作机制
-
.cu文件经 NVCC 编译器 处理。-
它会自动把 CPU 部分 交给常规 C++ 编译器(如
gcc)。 -
把 GPU 部分 编译成 PTX 或 SASS 代码,然后由 CUDA 驱动加载。
-
-
所以同一个
.cu文件中:-
main()在 CPU 上运行; -
square()在 GPU 上运行。
-
关键点:CUDA 函数限定符(Function Qualifiers)
| 限定符 | 运行位置 | 调用来源 | 说明 |
|---|---|---|---|
__global__ |
GPU(设备) | CPU(主机) | 核函数(kernel)。由CPU调用,在GPU上并行运行。 |
__device__ |
GPU | GPU | 普通的设备函数,只能在GPU中被其他GPU函数调用。 |
__host__ |
CPU | CPU | 普通的主机函数(默认可省略)。 |
你图中用的是 __global__,意味着 square() 是一个 kernel,由CPU端通过 <<< >>> 启动。
CUDA 的 .cu 文件里可以同时写 CPU 端代码 和 GPU 端代码,它们通过 函数限定符(function qualifiers) 来区分。

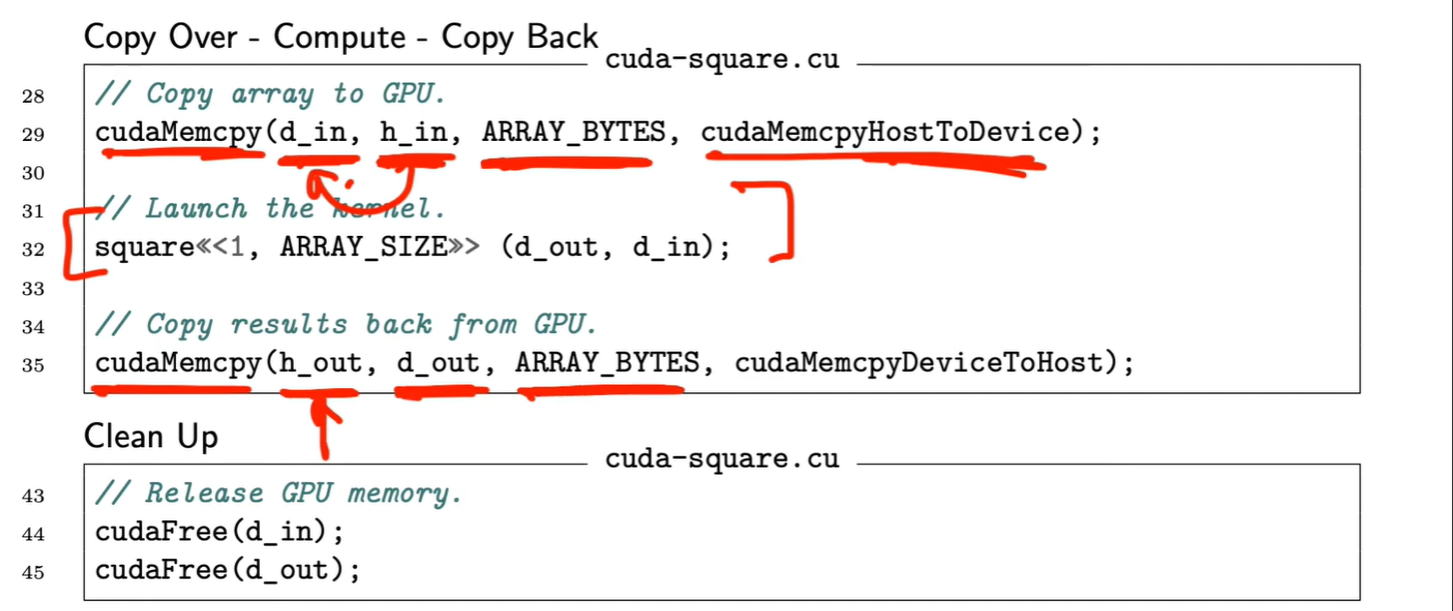
| 阶段 | 内存对象 | 操作 | 说明 |
|---|---|---|---|
| Copy Over | h_in → d_in |
cudaMemcpyHostToDevice |
CPU → GPU |
| Compute | square<<<>>>(d_out, d_in) |
GPU kernel 执行 | GPU 内部 |
| Copy Back | d_out → h_out |
cudaMemcpyDeviceToHost |
GPU → CPU |
Copy Over(主机到设备)
cudaMemcpy(d_in, h_in, ARRAY_BYTES, cudaMemcpyHostToDevice);
-
把数据从 CPU 内存 拷贝到 GPU 显存。
-
cudaMemcpyHostToDevice指定方向。 -
这一阶段是通信阶段,通常是性能瓶颈之一。
容易出错的地方
必须进行类型转换 (void**)&
-
cudaMalloc的第一个参数类型是void**,而d_in是float*。 -
如果不加
(void**)&会编译错误(类型不匹配)。 -
在 C++ 中尤其严格,因为它不允许隐式转换为
void**。
别忘记释放内存
-
GPU 的内存不会自动回收。
-
后续要调用:
cudaFree(d_in); cudaFree(d_out);
注意申请大小与元素数的对应关系
-
申请字节数必须是
元素数量 × sizeof(类型)。 -
如果写错,会导致越界访问或显存不足。
内存分配发生在 GPU 上
-
cudaMalloc运行在 CPU 上,但其效果是让 GPU 驱动在显存里开空间。 -
如果系统中有多个 GPU,需要在调用前设置设备:
cudaSetDevice(0);
float *d_in;
float *d_out;
cudaMalloc((void**)&d_in, ARRAY_BYTES);
cudaMalloc((void**)&d_out, ARRAY_BYTES);
这段代码在 GPU 上申请两块显存空间。
d_in / d_out:存储 GPU 端的输入输出数组指针。
cudaMalloc():CUDA 的显存分配函数,类似于 CPU 上的 malloc()。
第一个参数:指向指针的地址(即指针的指针 void**),因为函数内部需要修改该指针指向的内容。
第二个参数:申请的字节数。
然后gpu的

讲解核心
-
文件名:
cuda-square.cu-
.cu是 CUDA C 源文件扩展名。 -
表示文件中既有 CPU 端代码,也可能有 GPU kernel。
-
-
主函数结构 (main)
-
这里展示的是典型 CUDA 程序的开头部分,只涉及 CPU端的数据初始化。
-
ARRAY_SIZE:定义数组大小。 -
ARRAY_BYTES:计算总字节数,用于后续 GPU 内存分配(cudaMalloc)。
-
-
声明与初始化主机数组
-
float h_in[ARRAY_SIZE]; -
float h_out[ARRAY_SIZE]; -
h_in[i] = float(i);给输入数组初始化 0~63 的浮点值。
-
这一页PPT重点讲的是CUDA 程序的 CPU 端初始化部分,即 CUDA 计算前在主机(Host)上准备数据的阶段。

这一页讲 CUDA 的核心思想——kernel 写起来像单线程,但会被 GPU 同时运行在数以千计的线程上,每个线程凭借自己的索引处理不同数据部分。
-
Kernel 语法上像串行程序
-
每个线程都执行相同的代码段。
-
程序中没有显式的并行控制语句(如多线程同步),代码结构与普通C函数类似。
-
-
写法:好像只在一个线程上运行
-
开发者写 kernel 时就像只处理单个元素一样,例如:
__global__ void add(int *a, int *b, int *c) { int i = threadIdx.x; c[i] = a[i] + b[i]; } -
实际上,CUDA运行时会自动为每个数据元素分配一个线程执行这段代码。
-
-
实际执行:成千上万个线程同时运行
-
CPU 通过 launch 参数(<<<grid, block>>>)决定线程总数。
-
GPU 会并行调度这些线程到数百个核心上执行。
-
-
每个线程有自己的 ID(thread index)
-
通过
threadIdx/blockIdx确定它负责处理的数据部分。 -
这样同一段代码能处理不同数据,实现数据并行(Data Parallelism)。
-
这页PPT重点讲解 CUDA 核函数(kernel)的并行编程思想 —— 即“看起来像串行,实际是并行”。

老师会强调的要点
-
计算与通信权衡(computation/communication tradeoff)
-
GPU计算快,但CPU↔GPU数据传输慢。
-
要尽量减少数据往返,否则整体性能下降。
-
-
高并行度特点
-
CUDA能轻松启动上千线程。
-
线程并行执行,隐藏延迟、提高吞吐。
-
-
CPU仍是控制者,GPU只是执行者
-
CPU负责任务分配、内存管理与核函数调度。
-
-
CPU 分配 GPU 内存(cudaMalloc)
-
GPU不能直接访问主机内存,需要CPU先在GPU上开辟显存空间。
-
-
CPU 把数据拷贝到 GPU(cudaMemcpy)
-
数据从主机内存传到GPU显存,通常经过PCIe通道。
-
-
CPU 启动 GPU 内核(kernel)执行
-
GPU并行运行数千线程。
-
这里是CUDA程序的核心并行部分。
-
-
CPU 从 GPU 拷贝回结果(cudaMemcpy)
-
计算结束后,GPU结果传回CPU以供后续处理或输出。
-


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 25
25 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)