CVPR 即插即用 | AIGC新思路?用“知识互补”生成神级伪标签,彻底告别医学影像标注焦虑!
本文提出SKCDF框架,创新性地解决半监督医学图像分割中的伪标签噪声和类别不平衡问题。核心贡献包括:1)解耦数据流设计,分离有/无标签数据训练路径,保护解码器免受低质量伪标签影响;2)语义知识互补模块,通过跨流注意力实现特征相互增强;3)辅助平衡分割头策略,基于伯努利分布重点学习小器官特征。实验表明,该方法在Synapse数据集上Dice系数平均提升19.61%,显著提升小目标分割性能。该框架可推
1. 基本信息

-
标题: A Semantic Knowledge Complementarity based Decoupling Framework for Semi-supervised Class-imbalanced Medical Image Segmentation (一种基于语义知识互补的解耦框架,用于半监督类别不平衡的医学图像分割)
-
论文来源: https://github.com/yinguanchun/SKCDF
2. 核心创新点
-
提出数据流解耦框架:该框架分离了有标签和无标签数据的训练流,使编码器充分学习所有数据的通用特征,同时保护解码器免受低质量伪标签的负面影响。
-
设计语义知识互补模块:通过跨数据流的注意力机制,利用有标签数据指导无标签数据的伪标签生成,并用无标签数据丰富有标签数据的特征,实现知识互补。
-
开发辅助平衡分割头策略:引入额外的分割头和基于伯努利分布的平衡损失,专注于学习少数类(小器官)的特征,在不牺牲多数类性能的前提下,有效缓解类别不平衡问题。
➔➔➔➔点击查看原文,获取本文及其他精选即插即用模块集合![]() https://mp.weixin.qq.com/s/_8wmuTAAThOCnNTldesONg
https://mp.weixin.qq.com/s/_8wmuTAAThOCnNTldesONg
3. 方法详解
整体结构概述
SKCDF 框架在标准的伪标签半监督学习范式基础上进行了深度优化。其核心是一个解耦的编码器-解码器架构,包含一个共享的编码器(Encoder)、一个专用于有标签数据的解码器(Labeled Decoder)和一个专用于无标签数据的解码器(Unlabeled Decoder)。数据流被精心设计:编码器接收所有数据以学习丰富的底层特征;有标签解码器处理有标签数据并为无标签数据生成高质量伪标签;无标签解码器则在伪标签的监督下进行训练。为了促进不同数据流之间的知识交流,框架集成了“语义知识互补模块”和“辅助平衡分割头训练策略”,并通过知识蒸馏(EMA)方式传递参数,最终提升模型在类别不平衡场景下的分割性能。
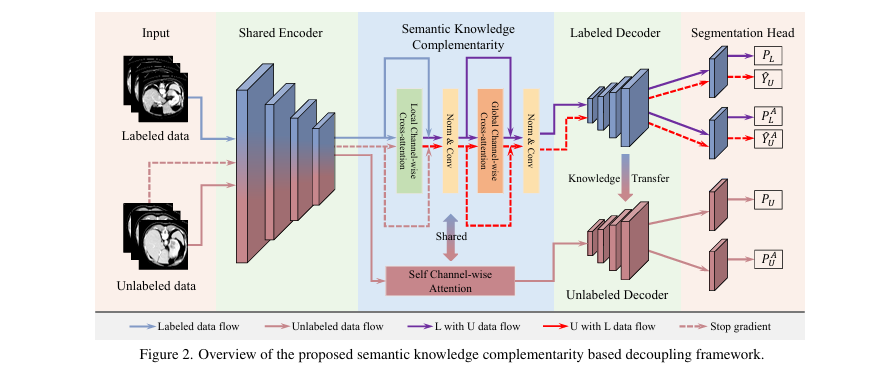
提出的基于语义知识互补的解耦框架概览
步骤分解
-
数据流解耦框架 (Data Flow Decoupling Framework)
-
动机:传统的半监督方法不加区分地用所有数据(包括带噪声伪标签的无标签数据)训练整个网络,这会严重影响解码器的分割决策能力。
- 流程:
-
共享编码器:编码器
E(·)同时在有标签数据X_L和无标签数据X_U上进行训练,以学习广泛的语义特征。 -
有标签分支:有标签数据
X_L经过E(·)和有标签解码器D_l(·)得到预测P_L,与真实标签Y_L计算监督损失L_sup。 - 无标签分支:无标签数据
X_U经过E(·),然后:-
通过有标签解码器
D_l(·)生成高质量的伪标签Ŷ_U。 -
通过无标签解码器
D_u(·)生成预测P_U。 -
计算
P_U和Ŷ_U之间的无监督损失L_unsup。
-
-
-
损失函数:总损失由监督和无监督损失加权构成。
-
知识传递:为了让无标签解码器也能受益于有标签数据训练出的精确分割能力,采用指数移动平均(EMA)策略,将有标签解码器
D_l的参数ξ_l缓慢传递给无标签解码器D_u的参数ξ_u。
-
-
语义知识互补模块 (Semantic Knowledge Complementarity Module)
-
作用:在生成伪标签和处理有标签数据时,实现两种数据流特征的相互增强。
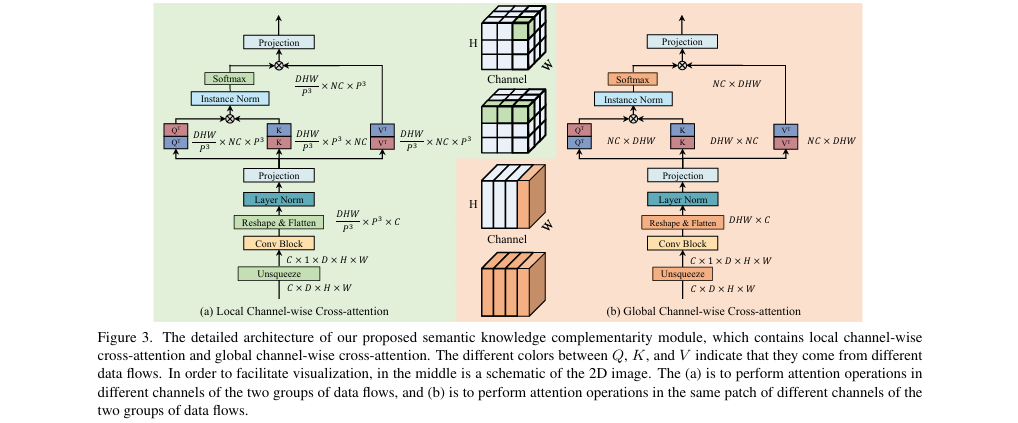
-
构成:该模块由局部和全局两种通道交叉注意力(Channel-wise Cross-attention)组成。
-
局部通道交叉注意力:将特征图划分为多个3D块(Patch),在块内计算来自有标签数据流的
Query与来自无标签数据流的Key和Value之间的注意力,反之亦然。这能捕捉局部区域的特征依赖关系。 -
全局通道交叉注意力:在整个特征图尺度上计算交叉注意力,捕捉长距离的全局依赖关系。
-
-
应用:当处理有标签数据
X_L时,其特征会与X_U的特征通过该模块进行交互,从而得到被无标签数据知识增强后的特征,再送入D_l。同理,当为X_U生成伪标签时,其特征也会被X_L的特征所引导。
- 辅助平衡分割头训练策略 (Auxiliary Balanced Segmentation Head Training Strategy, ABSH)
-
动机:在多器官分割中,小器官由于体积极小而难以学习,导致严重的类别不平衡。
- 流程:
-
在
D_l和D_u的末端分别增加一个主分割头(Main Head)和一个辅助平衡分割头(Auxiliary Balanced Head),共四个头。 -
主分割头:按常规方式计算损失。
-
辅助平衡分割头:其损失计算被一个动态生成的掩码
M所调制。该掩码基于伯努利分布生成,其概率与体素所属类别的频率成反比。 其中N_L是总像素数,N_C是某类别的像素数。这意味着,对于小器官的像素点,掩码值为1的概率更高,从而在计算损失时放大了它们的重要性。 -
平衡损失:辅助头的损失函数
L_balance会乘以这个掩码,强制模型关注少数类。
-
-
最终效果:主分割头负责整体分割性能,而辅助头专门攻克小器官分割难题。在推理时,使用经过充分训练的主分割头进行预测,从而实现了对小器官性能的提升而不损害大器官的分割精度。
-
4. 即插即用模块作用
适用场景
该框架中提出的核心思想和模块具有良好的通用性,尤其适用于以下场景:
-
半监督医学图像分割:特别是当只有少量标注数据可用时,如CT、MRI中的器官、肿瘤分割。
-
类别不平衡的分割任务:在多目标分割中,当目标(如小器官、小病灶)尺寸差异巨大时。
-
其他计算机视觉分割任务:可推广到需要利用大量无标签数据的自然图像或遥感图像分割任务中。
主要作用
-
模拟/替代能力:数据流解耦框架模拟了专家分工的模式,编码器负责“看图识特征”,解码器负责“描边定位”,有效替代了以往混合训练导致的性能瓶颈。
-
大幅降低/抑制:显著抑制了低质量伪标签对模型决策层(解码器)的负面干扰,避免了模型性能的下降。
- 增强性能/鲁棒性:
-
增强分割精度:通过知识互补和平衡学习策略,显著提升了模型对小器官和复杂结构的分割准确率(在Synapse数据集上平均Dice提升19.61%)。
-
增强模型鲁棒性:利用无标签数据丰富有标签数据的特征,使模型在面对不同个体或扫描图像时表现更稳定。
-
增强数据利用率:相比传统半监督方法,更充分、安全地利用了无标签数据蕴含的知识。
-
总结
SKCDF是一个为解决半监督学习中“伪标签噪声”和“类别不平衡”两大核心痛点而设计的“分而治之”的分割框架,它通过解耦数据流保护核心决策模块,利用知识互补提升特征质量,最终实现了对难分割小目标的精确捕捉。
➔➔➔➔点击查看原文,获取本文及其他精选即插即用模块集合![]() https://mp.weixin.qq.com/s/_8wmuTAAThOCnNTldesONg
https://mp.weixin.qq.com/s/_8wmuTAAThOCnNTldesONg

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 10
10 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)